- The paper introduces a novel forward-process RL algorithm that fine-tunes distilled autoregressive video models without the need for full reverse trajectory unrolling.
- It leverages a memory-efficient streaming rollout with a rolling window and selective multi-reward optimization to enhance video quality and motion consistency.
- Experimental results demonstrate significant improvements in perceptual metrics and temporal stability across both short-video and long-video generation scenarios.
Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
Introduction and Motivation
Distilled autoregressive (AR) video diffusion models enable streaming, low-latency video generation, but their outputs often fail to fully align with human aesthetic, motion, and semantic preferences due to the constraints of distillation objectives. Existing post-training RL pipelines either require expensive re-distillation cycles or rely on memory-intensive, solver-coupled reverse-process optimization, both of which erode the efficiency and scalability gains of AR streaming architectures.
Astrolabe proposes a fundamentally new memory-efficient online RL framework specifically designed for aligning distilled AR video models with human visual preferences, without the need for expensive trajectory storage or solver-specific backward unrolling. The method leverages a forward-process fine-tuning scheme informed by negative-aware optimization, applies long-horizon scalable training via streaming rollouts, and adopts multi-reward and uncertainty-aware regularization to mitigate reward hacking and preserve global video quality.
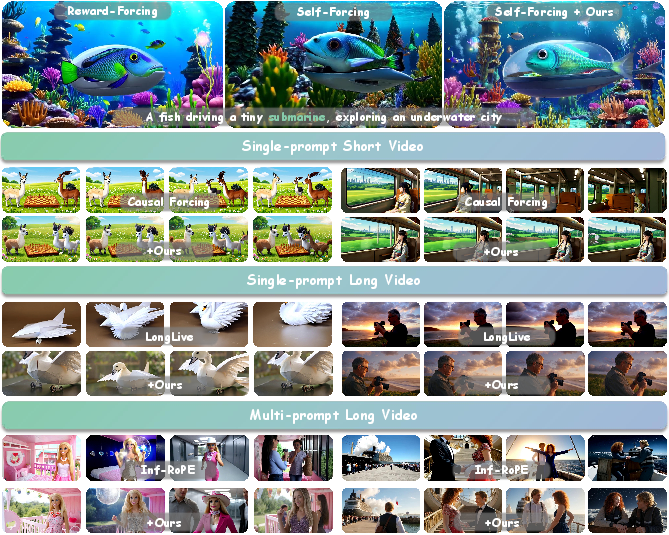
Figure 1: Astrolabe efficiently aligns distilled streaming video models with human preferences without re-distillation, mitigating artifacts and improving temporal consistency across varied settings and baseline methods.
Methodology
Forward-Process RL and Trajectory-Free Alignment
Astrolabe's core innovation is the direct fine-tuning of AR video models via a forward-process RL algorithm inspired by negative-aware fine-tuning for diffusion models. Rather than unrolling full reverse-process trajectories, the approach contrasts positive and negative score samples at inference endpoints—establishing the policy improvement direction solely from clean samples. The loss aggregates guidance from both positive (high-reward) and negative (low-reward) generations, removing the dependency on solver-specific likelihoods and yielding strong computational efficiency.
Memory-Efficient Streaming Rollout
To enable scalable long-duration video optimization, Astrolabe introduces a streaming group-wise rollout scheme based on a rolling KV cache. Only a fixed window of the most recent frames ("rolling window") and a small global context set ("frame sink") are cached, holding memory requirements constant regardless of video length. Parallel candidate clips are generated from each window to collect reward feedback efficiently for RL optimization.
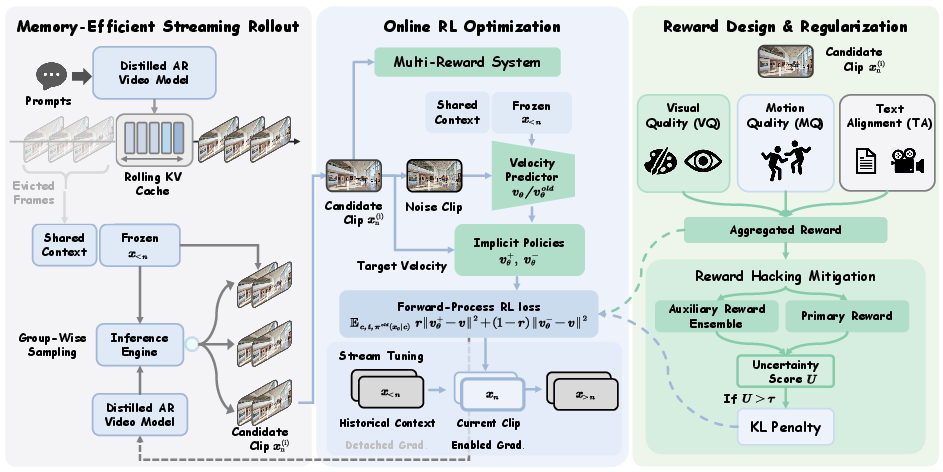
Figure 2: Overview of Astrolabe, highlighting the group-wise streaming rollout, clip-level forward-process RL, Streaming Long Tuning, and selective multi-reward regularization pipeline.
Multi-Reward Objective and Selective Regularization
To counter mode collapse and reward hacking, Astrolabe employs an aggregated reward covering three axes: visual quality (HPSv3), motion consistency (VideoAlign on grayscale), and text alignment (VideoAlign RGB). Optimization uses normalized per-group rewards and advantage signals, and regularization is stabilized through an uncertainty-aware selective KL penalty. Only candidate generations with high reward model rank disagreement incur explicit KL penalties, allowing the policy to explore but preserving a trust region around reliable, consensus-validated outputs. The RL reference policy is dynamically updated when policy drift is detected or over fixed intervals.


Figure 3: Ablation showing that single-reward optimization induces quality collapse; multi-reward design balances aesthetics and motion. Interpolation parameter β=1.0 achieves best trade-off for quality.
Experimental Evaluation
Short-Video Single-Prompt Generation
Astrolabe demonstrates consistent improvements in both perceptual and quantitative metrics (HPSv3, MQ, overall VBench scores) across a range of distilled AR baselines (Self-Forcing, LongLive, Causal Forcing), surpassing traditional AR, distilled, and diffusion-based video generators. Integration does not compromise inference speed.

Figure 4: Astrolabe produces sharper textures and superior motion coherence in short video, single-prompt generation compared to other baselines.
Long-Video and Multi-Prompt Generation
The streaming rollout and local-window RL optimization in Astrolabe allow distilled models—some originally trained only for short sequences—to scale effectively to long-form and multi-prompt settings. Astrolabe maintains or substantially enhances both global spatial quality and long-term temporal consistency, with significant boosts in CLIP alignment scores and motion metrics across open VBench-Long and MovieGenBench scenarios.

Figure 5: Astrolabe sustains visual details and stability in long video sequences, successfully extrapolating short-video alignment gains to long horizons.

Figure 6: Astrolabe-enhanced models achieve improved aesthetics and detail during complex multi-prompt narrative transitions.
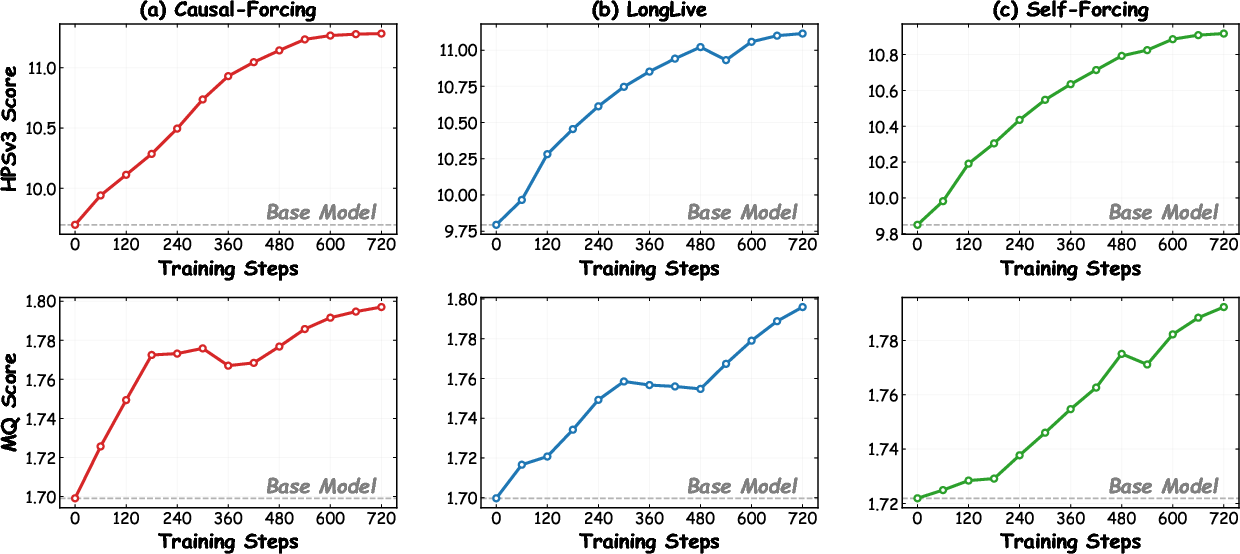
Figure 7: Performance improvements are consistent across diverse model architectures, with HPSv3 and MQ scores robustly elevated versus baseline checkpoints.
Ablation and Analysis
Comprehensive ablations validate the necessity of each key algorithmic component:
- Group-wise streaming and local detachment yield a 2× reduction in memory versus full sequence backprop, while improving HPSv3/MQ.
- Multi-reward combination is critical; single-axis rewards (e.g., VQ only) reliably trigger collapse (e.g., static frames), whereas the aggregate prevents overfitting and reward hacking.
- Selective KL regularization outperforms uniform or absent constraints, adaptively stabilizing optimization and enabling safe exploration.
- The removal of DiffusionNFT's adaptive scaling is mandatory; with few-step distilled ARs, it causes norm explosion and policy collapse.
- The parameter β (default 1.0) is important for calibrating implicit guidance; lower values yield suboptimal trade-offs in visual and motion metrics.
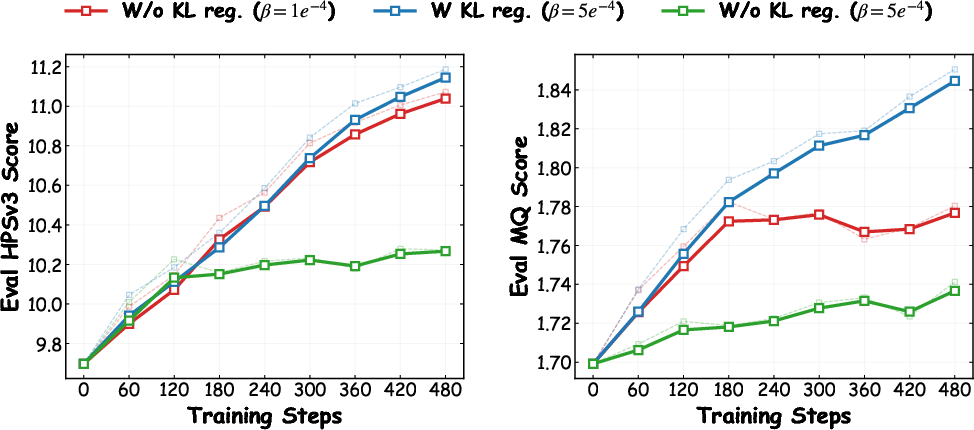
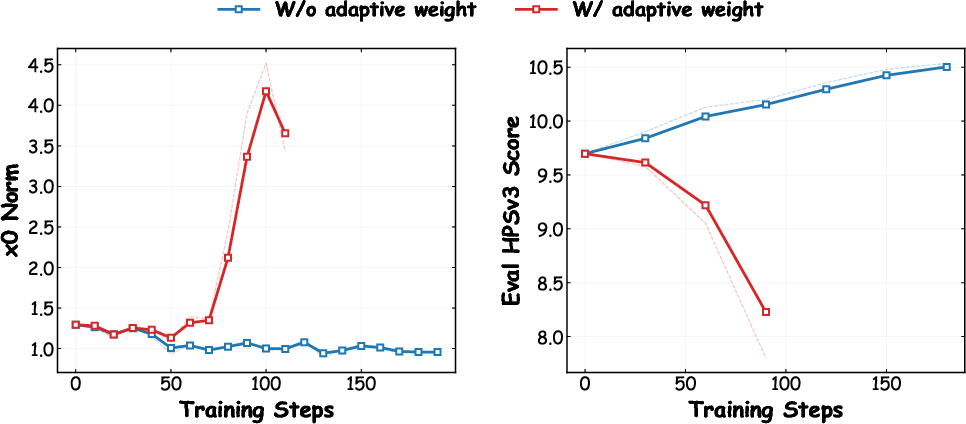
Figure 8: KL penalty ablation confirms that selective regularization is essential for stabilization; uniform KL constrains learning and omitting KL leads to early collapse.
Theoretical Implications and Broader Impact
Astrolabe establishes that forward-process RL can be extended to efficient, real-time AR video models while sidestepping the memory and complexity bottlenecks of reverse-process trajectories. The method exposes that fine-grained, segment-level RL updates, conditioned on rolling context, suffice for robust global alignment. The selective KL approach provides formal guarantees on reward lower bounds in risk regions without globally stifling policy exploration.
Practical implications are substantial: Astrolabe resolves the key challenge of aligning distilled AR models to human visual preferences at scale—without expensive re-distillation or slow backprop through full sequences. By optimizing only local segments and leveraging adaptive regularization, the approach is directly applicable to long-horizon, interactive, and multi-prompt video generation tasks. The framework generalizes across model architectures and can potentially be adapted to other streaming modality generators.
Limitations and Future Directions
Astrolabe's reliance on the quality and dimensionality of open-source reward models is a limiting factor; deficiencies in long-horizon physics or multi-entity reasoning remain unaddressed. Moreover, as a post-training RL method, it cannot induce fundamental capabilities absent in the distilled base model, only shift the generation distribution within the model's existing capacity.
Future work should focus on developing more robust, physics-aware reward models, improving long-horizon semantic evaluation, and exploring integration with world-model simulators and closed-loop control. Astrolabe's mechanisms could be extended to other sequential generation domains requiring real-time, memory-constrained RL alignment.
Conclusion
Astrolabe introduces a policy-alignment framework that enables robust, scalable RL fine-tuning of distilled AR video generators. Its trajectory-free forward-process optimization, streaming rollout design, and selective multi-reward regularization provide strong empirical and theoretical results, advancing the state of memory-efficient human preference alignment in real-time generative models (2603.17051).