Reinforced Attention Learning
Abstract: Post-training with Reinforcement Learning (RL) has substantially improved reasoning in LLMs via test-time scaling. However, extending this paradigm to Multimodal LLMs (MLLMs) through verbose rationales yields limited gains for perception and can even degrade performance. We propose Reinforced Attention Learning (RAL), a policy-gradient framework that directly optimizes internal attention distributions rather than output token sequences. By shifting optimization from what to generate to where to attend, RAL promotes effective information allocation and improved grounding in complex multimodal inputs. Experiments across diverse image and video benchmarks show consistent gains over GRPO and other baselines. We further introduce On-Policy Attention Distillation, demonstrating that transferring latent attention behaviors yields stronger cross-modal alignment than standard knowledge distillation. Our results position attention policies as a principled and general alternative for multimodal post-training.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Reinforced Attention Learning”
Overview
This paper is about teaching AI models that understand both text and visuals (images and videos) to pay better attention to the most important parts of what they see. Instead of only training the model to produce the right words, the authors train it to focus on the right places in a picture or video while it thinks. They call this approach Reinforced Attention Learning (RAL). The main idea is: don’t just train the model on what to say; train it on where to look.
Key questions the paper asks
- How can we help multimodal AI (that works with text + images/videos) find the most relevant visual details to answer questions correctly?
- Is making the model write long “explanations” before the answer (called chain-of-thought) actually helpful for visual tasks?
- Can we use reinforcement learning (a training method that rewards good behavior) to improve the model’s internal focus, not just its final words?
- Can a smaller “student” model learn better by copying a larger “teacher” model’s attention patterns (i.e., where the teacher looks), not just its outputs?
Methods and approach (with simple analogies)
Think of the model’s “attention” like a spotlight in a dark room. If the spotlight shines on the right objects or moments, the model will understand the scene better and answer correctly.
Here’s what the authors did:
- They treat attention as a “policy” (a plan of action): Instead of rewarding only the final words the model produces, they reward the way the model distributes its spotlight over the visual and textual context. In everyday terms, when the model focuses on the right places and gets the answer right, it gets points; if it focuses on the wrong places and gets the answer wrong, it loses points.
- Reinforcement learning on attention: Traditional reinforcement learning for language tweaks the probability of the next word. RAL tweaks the attention weights—the internal “where to look” choices—during the model’s thinking process. If a certain attention pattern led to a good answer, the model is nudged to keep that pattern. If it led to a bad answer, the model is nudged away from it.
- Combining both worlds: They do a mix—still train the model’s word choices a bit (so it remains fluent), but put significant emphasis on attention optimization (so it stays grounded in the visuals).
- On-policy attention distillation: Imagine a teacher model and a student model. Instead of only copying the teacher’s final answers, the student also tries to copy where the teacher was looking at each step. This helps the student learn the teacher’s internal habits for finding the right evidence. “On-policy” means the student practices using its own generated steps, and the teacher guides it along those steps.
How they tested the idea:
- Models: They used a standard multimodal model (Qwen-2.5-VL-7B) as the base and a bigger version (Qwen-2.5-VL-32B) as the teacher.
- Training steps: First, supervised fine-tuning (learning from examples). Then reinforcement learning with simple rewards: correct answers and properly formatted responses.
- Benchmarks: Many image and video question-answering tests, including very long videos and high-resolution images that require spotting fine details or tracking events over time.
Main findings and why they matter
What they found:
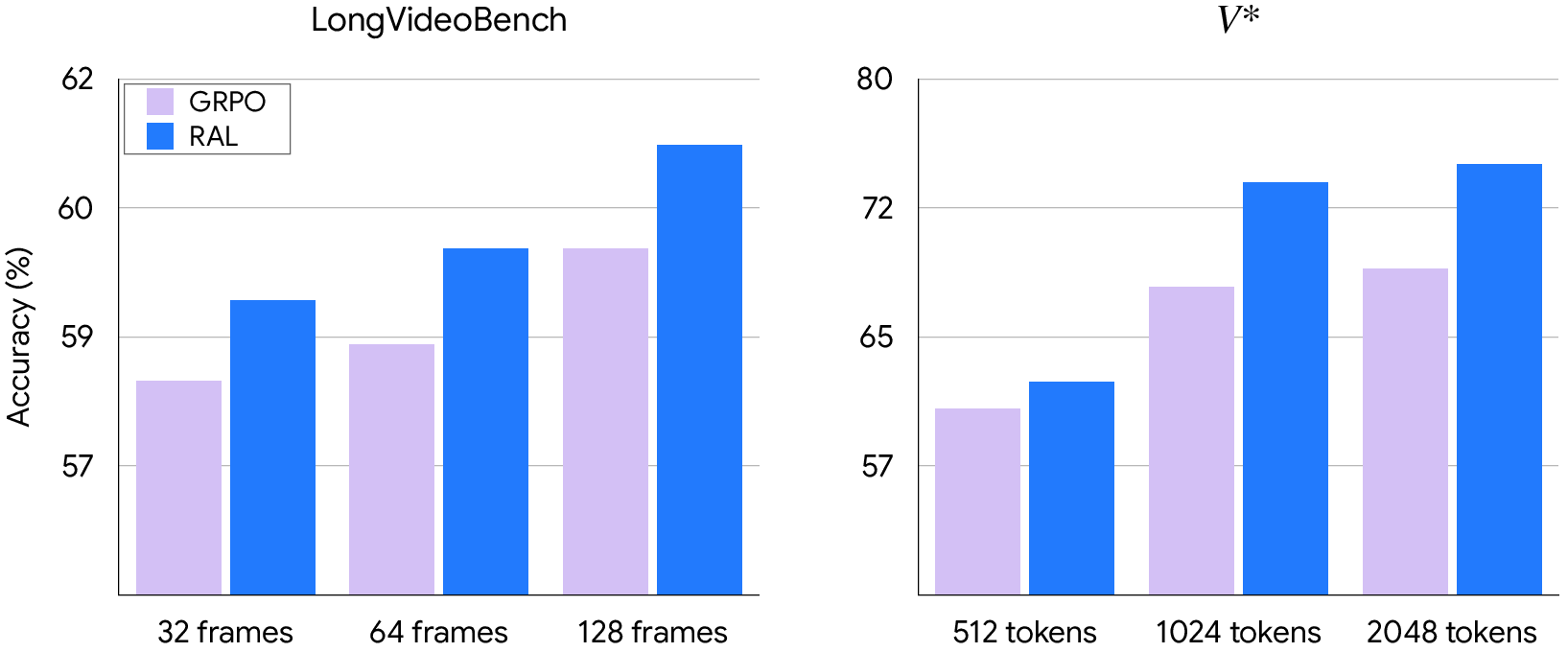
- RAL consistently improved performance across many image and video benchmarks compared to a popular baseline called GRPO (a reinforcement learning method focused on word outputs).
- It helped most on tasks where careful visual focus is essential: fine-grained image details, charts, real-world photos, and long videos requiring temporal reasoning.
- Attention distillation (student copying teacher’s “where to look”) beat standard distillation (copying only final word probabilities) on most tests. In other words, teaching “how to focus” transfers deeper understanding than teaching “what to say.”
- Even when they removed the model’s explicit “thinking text” (no long explanations), optimizing attention still improved results. This suggests that for visual tasks, training the model’s internal focus can matter more than making it generate lengthy reasoning.
Why it matters:
- It shows that optimizing the model’s internal process (where to focus) can be more powerful and stable than only optimizing the final output (what to say).
- It reduces problems like “visual hallucinations” (making up details that aren’t there) by grounding the model in actual evidence.
- It scales well: as images get higher resolution or videos get longer, attention-focused training keeps helping.
What this could mean in the future
- Better multimodal AI: Models that answer visual questions more reliably—useful for assisting people with visual impairments, analyzing scientific charts, understanding complex scenes, or reviewing long videos.
- More efficient training: By shaping the model’s internal attention, developers may get consistent gains without needing to rely on long, verbose explanations that can distract from perception.
- New research directions: If attention can be trained as a policy, other internal parts of AI models (like how different expert modules are chosen, or how visual and text features are fused) might also be trained this way. This could lead to AI that is more grounded, trustworthy, and robust in complex real-world tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, written to guide concrete follow-up research.
- Attention as a proxy for grounding: The method assumes attention weights faithfully reflect information use, but provides no causal validation that higher attention to visual tokens drives correctness. Evaluate with counterfactual interventions (e.g., masking high-attention regions) and ground-truth grounding datasets (e.g., pointing/segmentation supervision).
- Last-layer, head-averaged attention only: Optimizing only the final layer’s head-averaged attention may miss critical multi-layer/head-specific behaviors. Compare (i) layer-wise supervision, (ii) head-wise alignment, and (iii) cross-attention-only policies to determine which internal structures most influence multimodal grounding.
- Modality-aware attention treatment: The approach does not differentiate attention to visual vs textual tokens. Introduce modality-partitioned attention policies and test whether explicitly prioritizing cross-modal attention (or penalizing self-text loops) yields larger perception gains.
- Freezing the visual encoder and projector: Visual components remain frozen, potentially limiting perceptual improvements. Ablate unfreezing schedules (partial or full), joint attention-and-vision optimization, and assess whether attention-policy gradients can guide vision feature refinement.
- Reward design brittleness (exact match + formatting): The 0/1 exact-match reward is insensitive to synonyms, minor formatting, or partial correctness. Develop and test graded rewards (string similarity, VQA consensus, programmatic logic checks, calibrated extractive evaluators) and analyze how reward shape interacts with attention-policy updates.
- Ambiguity in “old” attention policy and trust region: It’s unclear how the “old” attention policy is instantiated/buffered and whether any trust-region/clipping is applied to attention divergence. Provide algorithmic details and test stability with/without attention-level clipping or adaptive bounds.
- Risk of degenerate attention patterns: Advantage-weighted JSD on attention could incentivize overly peaky or diffuse distributions. Add attention-entropy regularization or sparsity constraints and measure their impact on stability, calibration, and performance.
- Hyperparameter sensitivity and schedules: The paper lists ranges for
λ_attn/γ_attnbut lacks systematic sensitivity analyses or annealing strategies. Perform grid/bayesian searches and schedule studies to characterize robustness and typical operating regimes. - Lack of theoretical guarantees: There is no analysis of convergence, policy improvement, or variance properties when the policy is defined over latent attention rather than actions. Develop theoretical or empirical diagnostics (e.g., monotonic improvement curves, Fisher information analyses) to de-risk deployment.
- Missing comparisons to alternative structural objectives: No baselines with representation-level regularizers (e.g., hidden-state MSE, attention entropy, contrastive alignment) or to “attention-only PPO” variants. Add direct comparisons to isolate the unique contribution of attention-policy optimization.
- Pure attention-only optimization not isolated: RAL-zero removes rationales but still optimizes tokens. Test a “token-free” variant (i.e., set token-level RL weight to zero) to quantify the stand-alone impact of attention-policy updates.
- Teacher–student alignment details in distillation: The paper does not specify how differing tokenization, head counts, or sequence lengths are reconciled during attention distillation. Provide alignment procedures and ablate whether head- or modality-aware matching improves transfer.
- Compute and scalability costs of attention supervision: Training requires 8×H100 for ~120 hours; the overhead of extracting/storing attention for both student and teacher is not quantified. Report wall-clock overheads, memory footprints, and investigate low-cost approximations (e.g., sampling subsets of layers/heads or low-rank attention summaries).
- Generalization beyond Qwen-2.5-VL-7B/32B and VQA: Experiments are limited to one backbone and mostly VQA-style tasks. Evaluate across diverse MLLM families (e.g., LLaVA, InternVL, Gemini-like) and tasks (captioning, referring expressions, OCR-heavy tasks, grounding with pixel-level labels) to assess generality.
- Language-only and cross-domain side effects: Optimizing attention for multimodal grounding may harm pure language tasks or long-form reasoning. Benchmark on text-only tasks (MMLU, GSM8K) and measure any trade-offs.
- Hallucination and faithfulness metrics: While gains imply better grounding, there is no direct evaluation on hallucination benchmarks (e.g., POPE variants) or human audits of evidence use. Add targeted hallucination tests and human-in-the-loop validation.
- Robustness and distribution shift: The paper lacks evaluations under adversarial, OOD, or noisy conditions (e.g., occlusion, blur, compression, distractors, shuffled frames beyond Video-R1’s temporal reward). Stress-test robustness and analyze how attention policies adapt.
- Attention visualization and qualitative analysis: No qualitative evidence (e.g., overlays on salient regions) is shown to substantiate the “where to focus” claim. Provide visualizations and error analyses linking attention patterns to successes/failures.
- Divergence choice and alternatives: Only JSD is used for attention alignment; effects of KL, Wasserstein, cosine, or Earth Mover’s on stability and performance remain unknown. Ablate divergence choices and their numerical conditioning.
- Credit assignment across time in long videos: The method applies per-token attention divergence but does not explore temporal credit assignment (e.g., which frames/timesteps matter). Investigate temporal weighting schemes and frame-level attribution to reduce variance in long contexts.
- Interaction with token-level RL (interference vs synergy): The combined objective’s interference patterns are not analyzed. Study gradient alignment between token and attention losses, and explore dynamic weighting or conflict resolution strategies.
- Attention extraction fidelity: The approach patches “eager attention” and averages heads; it’s unknown whether this faithfully captures inference-time attention in optimized kernels. Validate that training-time attention mirrors deployment-time behavior with and without kernel fusions.
- Modality and token granularity: Visual tokens are patch-level; no exploration of different granularities (e.g., region proposals, object queries) or adaptive token pruning guided by attention policies. Test whether attention-guided token pruning improves efficiency without hurting accuracy.
- Safety/fairness implications: Shaping attention might amplify biases in where the model “looks.” Conduct bias audits across demographics/domains and evaluate whether attention-policy training exacerbates or mitigates spurious correlations.
- Data provenance and contamination checks: Training on Video-R1 while evaluating broadly can risk overlap; the paper does not discuss de-duplication or contamination. Provide overlap analyses and ensure clean splits.
- Extension to other internal policies: The conclusion mentions MoE routing and fusion as future directions but provides no concrete experiments. Prototype attention-policy analogs for MoE gating or cross-modal fusion weights and benchmark their effects.
- Practical deployment impacts: The paper doesn’t report inference-time costs, latency, or memory changes post-training. Measure any changes in decoding speed, cache behavior, and memory usage in real-world settings.
- Failure cases and negative results: Some benchmarks show marginal or no gains (e.g., VideoMMMU). Provide case studies and probe task characteristics where RAL underperforms to inform when/where to apply it.
- Reproducibility details: Important training details (e.g., seeds, exact batch sizes, number of updates, code for attention extraction) are missing. Release code/configs and report multiple-seed means/variances to assess stability.
Practical Applications
Practical Applications of Reinforced Attention Learning (RAL)
Below we translate the paper’s findings into concrete applications across sectors, indicating what can be deployed now versus what likely requires further R&D. Each item notes relevant sectors, potential tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
These can be prototyped or deployed with today’s MLLM stacks (open or internal), given access to model internals for training and standard RLHF infrastructure.
- RAL as a plug-in to existing RLHF/RLVR post-training for MLLMs
- Sectors: software/AI platforms, foundation model providers
- Tools/workflows: integrate the JSD-based attention divergence term into GRPO/PPO pipelines; extract last-layer attention via eager attention; tune λ_attn/γ_attn; retain existing verifiable rewards (format/correctness)
- Assumptions/dependencies: access to model attention weights/logits during training; sufficient compute (e.g., 8×H100-scale as in the paper); verifiable tasks for reward shaping; stable APIs for patching attention
- Video analytics and long-context assistants with stronger temporal grounding
- Sectors: security/surveillance, sports analytics, media indexing, contact center QA, compliance review
- Products: “smart timeline Q&A” for long videos; event localization and causal explanation; better retrieval-augmented video search
- Assumptions/dependencies: availability of domain video datasets; reward verifiers (e.g., correctness vs. ground truth or programmatic checks); privacy policies for video content
- Accessibility assistants with improved visual grounding (e.g., for blind/low-vision users)
- Sectors: healthcare/accessibility, mobile assistants
- Products: phone-based VQA that better grounds answers in images (e.g., VizWiz-like scenarios); on-device or near-device deployment via attention-distilled students
- Assumptions/dependencies: teacher–student pipeline for on-policy attention distillation; small student models (e.g., 7B) meeting latency constraints; robust image pre-processing
- Chart/document comprehension for BI, finance, and education
- Sectors: finance, enterprise BI, education/edtech, office productivity
- Products: chart QA copilots; spreadsheet/chart tutors; meeting assistants that “read” slides and dashboards; RPA for reporting
- Assumptions/dependencies: chart/document datasets for SFT/RL; verifiable answers (numeric/text spans); integration with enterprise data governance
- E-commerce and retail visual QA and catalog quality control
- Sectors: retail/e-commerce, marketplaces
- Products: visual attribute verification (e.g., color/pattern/size); customer Q&A from product images; compliance checks for listings
- Assumptions/dependencies: product image corpora with labels/answers; reward signals based on human rules/heuristics; careful handling of edge cases and class imbalance
- Robotics and manufacturing perception with latency-sensitive inference (RAL-zero variant)
- Sectors: robotics, manufacturing, logistics
- Products: low-latency visual grounding for pick-and-place verification, defect detection, and line monitoring; improved attention to salient cues without verbose reasoning
- Assumptions/dependencies: edge-capable student models via attention distillation; controlled camera/sensor setups; task-specific verifiers for reward signals
- Content integrity and moderation via temporal order sensitivity
- Sectors: trust & safety, media forensics, platform integrity
- Products: detectors for frame order anomalies, splice/shuffle manipulations; better grounding for incident triage in user-generated content
- Assumptions/dependencies: curated manipulation datasets; clear evaluation metrics for temporal coherence; policy alignment for automated moderation
- Model compression with on-policy attention distillation
- Sectors: AI infrastructure, edge AI, enterprise deployment
- Tools/workflows: add attention-JSD alignment in on-policy distillation to preserve grounding behavior when downsizing; combine with standard GKD on logits
- Assumptions/dependencies: access to both teacher and student attention; student-generated trajectories; consistent data/rollout pipelines to avoid exposure bias
- Interpretability and debugging via attention policy inspection
- Sectors: AI research, MLOps, assurance/audit
- Tools/workflows: log and visualize attention policies during RL post-training; compare teacher–student attention alignment; triage failure cases where attention diverges from evidence
- Assumptions/dependencies: reliable attention extraction and storage; understanding of attention–faithfulness limitations; privacy policies for logging internal states
- Evaluation and provenance: attention-based “evidence use” checks
- Sectors: policy/compliance, regulated industries (finance, legal)
- Products: internal dashboards that show where the model “looked” when answering; auditors can confirm attention covers cited evidence (e.g., chart regions)
- Assumptions/dependencies: agreement that last-layer attention approximates evidence use; standardized attention logging interfaces; secure retention of internal traces
Long-Term Applications
These require additional research, data, tooling, or ecosystem support (e.g., vendor APIs exposing internals) before reliable, large-scale deployment.
- Cross-modal, multi-sensor agents with attention policy control
- Sectors: autonomous systems, IoT, AR/VR
- Products: agents that integrate video, audio, depth, and other sensors with attention-optimized fusion; real-time assistants that attend to salient multimodal cues
- Assumptions/dependencies: architectures that expose and align attention across modalities; robust reward functions beyond text QA; latency-aware training/inference
- Healthcare diagnostics (e.g., radiology, endoscopy) with evidence-grounded QA
- Sectors: healthcare/medical imaging
- Products: assistant that highlights critical regions linked to findings; QA tools that reduce hallucination and improve explainability
- Assumptions/dependencies: clinical-grade datasets and labels; rigorous validation and regulatory approval; domain-specific reward models and privacy-preserving training
- Autonomous driving and driver monitoring with temporally grounded perception
- Sectors: automotive, mobility, insurance
- Products: video understanding modules that attend to causal cues in traffic scenes; driver state/event QA for incident analysis
- Assumptions/dependencies: integration with perception stacks; safety certification; coverage of rare/long-tail events; strong simulation-based verifiers
- Attention-level safety and governance controls
- Sectors: policy/regulation, enterprise risk
- Products: policies that constrain attention to cited sources (evidence coverage thresholds); audits requiring “attention provenance” for high-stakes outputs
- Assumptions/dependencies: community consensus about attention faithfulness; standardized “attention policy” APIs; legal/ethical frameworks to interpret internal traces
- Hardware–software co-design for attention supervision and control
- Sectors: semiconductor, AI accelerators, edge devices
- Products: kernels or accelerators exposing attention hooks/gradients for training-time supervision and lightweight inference-time constraints
- Assumptions/dependencies: vendor support in frameworks/runtimes; performance trade-offs accepted by customers; security considerations for exposing internals
- Reward models that evaluate attention patterns (not just outputs)
- Sectors: AI research, model alignment
- Products: attention-aware RMs that score evidence use, spatial/temporal localization, or region coverage; hybrid metrics combining token correctness and attention behavior
- Assumptions/dependencies: large-scale data with attention-level annotations or proxy labels; robust correlation between attention signals and ground-truth evidence use
- Dataset curation and active learning guided by attention coverage
- Sectors: MLOps, data platforms
- Products: tools that flag samples where attention misses critical regions; auto-suggest data augmentations or labeling priorities to fix grounding gaps
- Assumptions/dependencies: reliable attention–evidence alignment; integration with labeling platforms; scalable attention logging/analytics
- Real-time AR/VR assistants with RAL-zero and distilled students
- Sectors: AR/VR, consumer electronics, gaming
- Products: on-device visual tutors, scene understanding overlays; latency-critical helpers that avoid verbose CoT while maintaining grounding
- Assumptions/dependencies: efficient streaming attention; low-power student models; superior heat dissipation and memory bandwidth on devices
- Standardized “Attention Policy API” for cross-model interoperability
- Sectors: model providers, open-source ecosystems
- Products: a common interface to read/align attention policies during fine-tuning and distillation; plug-and-play attention distillation between vendors
- Assumptions/dependencies: broad vendor adoption; agreement on layers/heads and normalization; privacy and IP concerns addressed
- Extending RAL to control other internal mechanisms (e.g., MoE routing, cross-attention fusion)
- Sectors: AI research, efficiency engineering
- Products: policy gradients shaping expert selection or fusion gates; improved robustness and efficiency via internal credit assignment
- Assumptions/dependencies: reliable training signals for non-attention components; new divergences and stability strategies; architecture support beyond Transformers
In both categories, the central dependency is access to internal attention distributions during training (and optionally for auditing). Where models are closed-box or do not expose stable attention interfaces, vendors or open-source alternatives are needed. Additionally, while RAL improves grounding and perception benchmarks, attention faithfulness remains an assumption; applications that treat attention as “provenance” should pair it with complementary evidence (e.g., saliency, region citations, retrieval logs) and task-specific validation.
Glossary
- Actor-Critic Framework: A reinforcement learning architecture where an actor proposes actions and a critic estimates their value to guide updates. "However, PPO’s actor-critic framework is memory-intensive due to the auxiliary critic model."
- Advantage (A_t): A measure of how much better an action is compared to a baseline, used to weight policy updates in RL. "where denotes the advantage estimate."
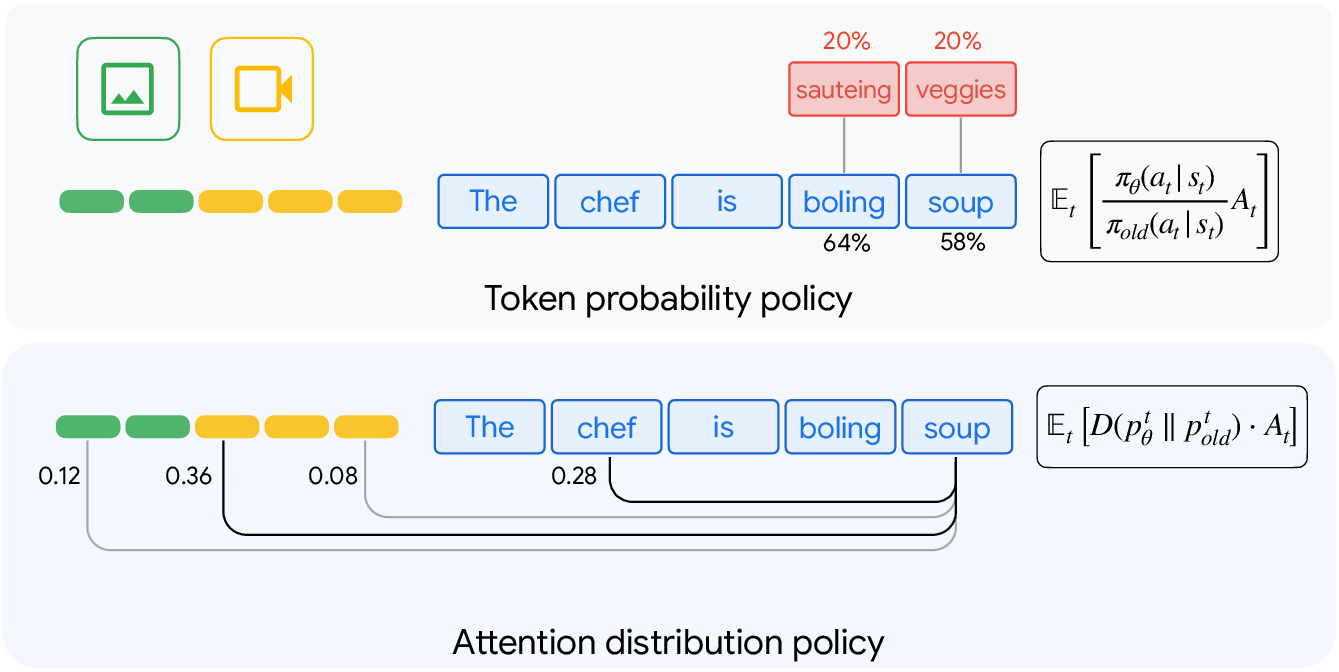
- Attention Policy: Treating the model’s internal attention distribution as a decision policy that can be optimized for rewards. "Our results position attention policies as a principled and general alternative for multimodal post-training."
- Causal Attention Distribution Policy: The normalized distribution of attention from a generated token to all preceding tokens, respecting causal order. "we define the causal Attention Distribution Policy as the distribution over all preceding positions:"
- Chain-of-Thought (CoT): A training and inference technique that elicits step-by-step reasoning in LLMs. "post-training has emerged as a critical technology for eliciting long-form Chain-of-Thought (CoT) reasoning."
- Cross-Modal Alignment: Consistent and meaningful correspondence between different modalities (e.g., vision and language) within a model. "yields stronger cross-modal alignment than standard knowledge distillation."
- Direct Preference Optimization (DPO): A learning method that directly optimizes a model to prefer outputs aligned with demonstrated preferences, without an explicit reward model. "Recent methods adapt RLHF, RLVR, or Direct Preference Optimization (DPO) to improve visual grounding and reduce hallucinations"
- Exposure Bias: A mismatch between training and inference distributions caused by training on teacher-forced sequences rather than the model’s own outputs. "on-policy distillation mitigates exposure bias"
- Group Relative Policy Optimization (GRPO): An RL method that replaces a critic with group-averaged rewards to compute relative advantages, reducing memory costs. "Group Relative Policy Optimization (GRPO) addresses this by replacing the critic with group-averaged reward estimates."
- Importance Sampling: A technique to reweight samples from one distribution to estimate expectations under another, used in off-policy RL objectives. "Modern off-policy algorithms like PPO and GRPO utilize a surrogate objective based on importance sampling:"
- Jensen–Shannon Divergence (JSD): A symmetric, bounded divergence measure between probability distributions, often used for stable training. "such as Jensen-Shannon Divergence (JSD)."
- Knowledge Distillation (KD): Transferring knowledge from a larger teacher model to a smaller student by matching softened output distributions. "Knowledge Distillation (KD) transfers knowledge from a high-capacity teacher to a student by matching softened output distributions rather than hard labels"
- Kullback–Leibler Divergence (KL): A measure of how one probability distribution diverges from a reference distribution, used for aligning model outputs. "represents the reverse Kullback-Leibler divergence between the output distributions"
- Latent Policy Space: An internal, implicit decision space (e.g., attention weights) treated as a policy that can be optimized. "constitutes an alternative, latent policy space."
- Mixture-of-Experts (MoE) Routing: A mechanism that routes inputs to different expert subnetworks, enabling specialized computation within a larger model. "such as MoE routing or cross-modal fusion"
- Modality Bias: A tendency of multimodal models to over-rely on one modality (e.g., text) or superficial cues, harming grounding. "A persistent issue is modality bias, where the model over-relies on linguistic priors or, conversely, overfits to superficial visual cues"
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple modalities such as text, images, and video. "To extend these gains to multimodal LLMs (MLLMs), recent studies have attempted to incorporate “thinking processes” into Visual Question Answering (VQA) tasks."
- Multimodal Projector: A component that maps visual features into the language embedding space to condition generation. "the visual encoder and multimodal projector are kept frozen"
- On-Policy Attention Distillation: A distillation approach that aligns a student’s attention distributions with a teacher’s on the student’s own trajectories. "We further introduce On-Policy Attention Distillation"
- On-Policy Distillation: Distillation where the student generates outputs under its own policy and receives teacher supervision along those trajectories. "More recent work has explored on-policy distillation"
- Policy-Gradient Methods: RL techniques that directly optimize the parameters of a stochastic policy using gradients of expected returns. "These policy gradient methods refine the next-token distribution to maximize expected rewards."
- Proximal Policy Optimization (PPO): A popular RL algorithm that performs clipped policy updates to ensure stable training. "relied heavily on Proximal Policy Optimization (PPO)"
- Reward Hacking: When a model exploits imperfections in the reward signal to increase rewards without improving true task performance or reasoning. "leading to ``reward hacking'' of the linguistic structure rather than the underlying logic."
- RL with Verifiable Rewards (RLVR): RL setups where rewards are derived from verifiable signals (e.g., programmatic checks) to guide learning. "leading to the domain of RL with Verifiable Rewards (RLVR)."
- RLHF (Reinforcement Learning from Human Feedback): Aligning models with human preferences via a reward model trained on human judgments and subsequent RL. "The traditional RLHF pipeline involves Supervised Fine-Tuning (SFT), training a Reward Model (RM) to mimic human preferences, and optimizing the policy via Reinforcement Learning (RL)"
- Softmax Jacobian: The matrix of partial derivatives of the softmax output with respect to its logits, used for backpropagation through distributions. "Using the softmax Jacobian"
- Temporal Coherence Reward: An auxiliary reward encouraging consistency with correct temporal ordering in video-based tasks. "incorporates a temporal coherence reward."
- Transformer Attention Mechanism: The component of Transformers that computes weighted context over tokens, enabling selective focus during sequence processing. "This process is governed by the Transformer’s attention mechanism"
- Visual Grounding: The ability to link textual references to the correct visual evidence within images or videos. "enabling direct reinforcement of visual grounding rather than indirect supervision through textual outputs."
- Visual Hallucination: Model outputs that describe visual content not present in the input, indicating poor grounding. "Extending post-training to multimodal LLMs (MLLMs) introduces challenges beyond text-only alignment, including visual hallucination and robust cross-modal grounding"
Collections
Sign up for free to add this paper to one or more collections.