- The paper introduces NEO, a unified framework that interleaves language and semantic identifiers to generate valid catalog references across diverse entity types.
- It employs a three-stage pipeline to discretize embeddings into SIDs, align them with LLM representations, and tune on multi-task discovery tasks for improved performance.
- The paper demonstrates significant improvements over state-of-the-art baselines in recommendation and retrieval metrics without relying on external tool calls.
Unified Catalog-Grounded Generative Language Modeling via NEO
Motivation and Problem Setting
Scaling LLMs to operate directly on massive, heterogeneous item catalogs in personalized recommendation and retrieval remains an open problem. Existing practice divides search and recommendation into separate system stacks, introducing duplicated model development and operational fragmentation. Unifying these modalities in a single LLM would enable streamlined, end-to-end discovery experiences, yet technical barriers persist: LLMs must generate unambiguous item references, support mixed typed-entity catalogs (e.g., audiobooks, podcasts, artists), handle multi-task instructions, and retain low-latency, production-grade inference. Tool-augmented retriever pipelines partially address output grounding but at the cost of increased orchestration and degraded end-to-end training.
The paper proposes a language-steerable, catalog-grounded framework, NEO, which extends decoder-only LLMs so they can interleave language and valid catalog references within the same generation sequence, over multiple item types and tasks, without external tool calls or architectural changes.
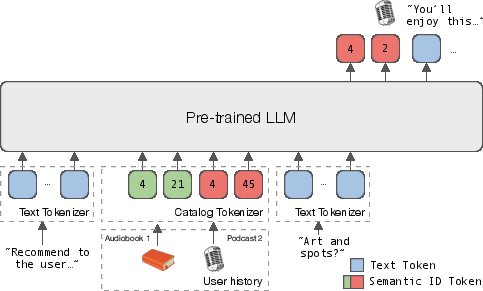
Figure 1: NEO adapts pre-trained LLMs to speak multi-item-type catalogs (e.g., audiobooks and podcasts) through semantic identifiers (SIDs), and to output both text and SIDs.
NEO: Model, Interface, and Training Pipeline
NEO represents entities using discrete, semantically-structured identifiers termed SIDs. For each item, the SID is a short sequence of discrete tokens, learned to preserve semantic structure and addressability, and used interchangeably with free-form text within the model interface. This enables natural control over the modality (text/SID/mixed) and supports all catalog-typed outputs required in industrial search and recommendation scenarios.
To integrate this dual-modality interface, NEO employs a multi-stage alignment and tuning recipe:

Figure 2: The NEO pipeline: Stage 1 constructs semantic representations (SIDs) for catalog entities, Stage 2 aligns SIDs and text in the model’s embedding space, and Stage 3 induces multi-task instruction following for discovery tasks.
- Stage 1 (Semantic Foundation): Discretizes catalog item embeddings using residual quantization to construct SIDs that encode semantic structure and type information.
- Stage 2 (Domain Grounding): Aligns SID tokens to the LLM embedding space via bidirectional objectives (SID-to-text, text-to-SID, SID-to-type), while freezing the backbone LLM. This treats SIDs as a foreign discrete modality akin to procedures used in MLLMs.
- Stage 3 (Capability Induction): Employs supervised instruction tuning, unfreezing the backbone, training on a broad suite of discovery tasks—recommendation, text-based retrieval, explanation (recsplanation), and user profiling—using mixed-format input-output sequences. Natural-language instructions explicitly steer the model towards target tasks and output types.
During inference, prefix-trie–constrained decoding ensures that generated SIDs always map to valid catalog items, guaranteeing item output validity despite the combinatorial SID vocabulary. This approach maintains the standard LLM next-token objective, without modifying attention structure or decoding primitives.
Empirical Analysis and Numerical Results
NEO is evaluated at scale, using interaction logs from a streaming catalog with >10M items across heterogeneous types and ~15M users. The experimental pipeline includes competitive baselines built on production GNNs plus two-tower architectures for recommendation, and dense semantic retrievers for search.
Key numerical findings:
- Recommendation (HR@10/NDCG@10): NEO achieves relative performance improvements of 36–58% (HR@10) and 46–97% (NDCG@10) across audiobooks, shows, and episodes compared to state-of-the-art baselines.
- Text-based Retrieval: NEO surpasses the dense retriever by +26–47% (HR@10), with greater gains (+40%) for fine-grained entities (episodes), and achieves extreme improvements (+185%, +243%) on challenging, multi-step search sessions.
- Multi-task Training: Joint tuning with text-based retrieval and recsplanations yields positive cross-task transfer without trade-off, even as task diversity increases.
- User Understanding and Recsplanations: LLM-as-a-judge (GPT-4o-mini) scoring places NEO’s text generations at 3.5–4.7/5 across coverage, groundedness, and faithfulness for both user interest profiles and recommendations-with-explanation tasks.
- Language Steerability: The model reliably follows instructions to control target entity type and output variety with >0.9 success rate, with strong compliance even under constrained decoding.
Key Design Findings and Ablations
The study elucidates several strong and, in some cases, non-obvious empirical claims:
- Semantically-structured SIDs vs Atomic IDs: Replacing SIDs with randomly permuted atomic IDs degrades recall by 51–59%, confirming that semantic structure is essential for generalization and efficient tool-free generation at catalog scale.
- Continuous vs Discrete Alignment: Integrating SIDs via the domain-alignment stage (rather than via continuous pretraining or direct fine-tuning) optimizes item grounding without catastrophic forgetting of language skills—NEO retains 15x higher general linguistic competence (MMLU-Redux 0.46 vs CPT 0.03).
- Content vs Collaborative Signals for SIDs: SIDs constructed from content-based embeddings outperform those from collaborative filtering vectors, which exhibit temporal instability and type-mismatch in large, fast-changing catalogs.
- Constrained Decoding Overhead: Trie-constrained decoding is strictly necessary only for a small fraction of outputs, with marginal latency overhead (<5%), but guarantees catalog-valid generation; unconstrained sampling drops top-K hit rates by up to 32%.
- Framework Generality: The staged NEO pipeline is agnostic to the LLM backbone (validated on Qwen and Llama 3.2).
Theoretical Implications and Relation to Prior Work
NEO consolidates advances in semantic tokenization, multimodal alignment, and language grounding, but is distinct in achieving all of: (a) tool-free generation of typed and catalog-valid item outputs; (b) language-steerable task and output control; (c) support for multi-modal input/output interleaving at industrial scale. Prior art—discrete token recommenders, retrieval-augmented LLMs, and MLLMs—offer partial solutions (e.g., single-type SIDs, task-specific pipelines, or tool invocation), but none address all requirements jointly.
The study systematically refutes the efficacy of atomic IDs at scale, shows empirical instability in collaborative signal-based SIDs, and demonstrates that naive SID integration via continuous pretraining or parameter re-initialization compromises either backbone language retention or task performance.
Practical and Future Implications
The proposed approach offers a path towards deploying LLM-based discovery stacks that unify search, recommendation, and multi-type reasoning into a single, end-to-end-optimized model. Practically, the result is simplified maintenance, enhanced sample-efficiency (stronger metrics with less training data), reduction in system latency, and native support for interleaved mixed-modality dialogs. The design principles—semantic tokenization, staged alignment, language-steerable multi-task instruction—are broadly transferable to other domains where large, heterogeneous, and dynamic entity sets must be represented within generative models.
Theoretically, NEO suggests new lines of research into discrete modality expansion (e.g., for e-commerce, education, or code retrieval), as well as studies into the limits of language retention under staged alignment and large-vocabulary extension. Automatically balancing content-based and collaborative embedding signals for SID construction and exploring parameter-efficient adaptation (LoRA, adapters) are promising directions. Future work should investigate zero-shot generalization to novel entity types and dynamic expansion of catalog-grounded modalities.
Conclusion
NEO provides a unified, language-steerable, catalog-grounded framework that closes the gap between LLMs and large-scale personalized discovery tasks. The staged alignment pipeline, use of semantically-structured SIDs, and validation of tool-free, mixed-modality generation at scale offer actionable principles for future system design and research on adaptable, domain-integrative LLMs. The results potentially generalize to broader applications in entity-centric generative reasoning and open new perspectives on LLM deployment in high-cardinality industrial contexts.