ReLi3D: Relightable Multi-view 3D Reconstruction with Disentangled Illumination
Abstract: Reconstructing 3D assets from images has long required separate pipelines for geometry reconstruction, material estimation, and illumination recovery, each with distinct limitations and computational overhead. We present ReLi3D, the first unified end-to-end pipeline that simultaneously reconstructs complete 3D geometry, spatially-varying physically-based materials, and environment illumination from sparse multi-view images in under one second. Our key insight is that multi-view constraints can dramatically improve material and illumination disentanglement, a problem that remains fundamentally ill-posed for single-image methods. Key to our approach is the fusion of the multi-view input via a transformer cross-conditioning architecture, followed by a novel unified two-path prediction strategy. The first path predicts the object's structure and appearance, while the second path predicts the environment illumination from image background or object reflections. This, combined with a differentiable Monte Carlo multiple importance sampling renderer, creates an optimal illumination disentanglement training pipeline. In addition, with our mixed domain training protocol, which combines synthetic PBR datasets with real-world RGB captures, we establish generalizable results in geometry, material accuracy, and illumination quality. By unifying previously separate reconstruction tasks into a single feed-forward pass, we enable near-instantaneous generation of complete, relightable 3D assets. Project Page: https://reli3d.jdihlmann.com/







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1) What is this paper about?
This paper introduces ReLi3D, a fast computer system that can turn a few photos of an object into a complete, realistic 3D model in under one second. The 3D model includes:
- the object’s shape (a mesh),
- detailed, physically-based surface materials (like color, shininess/roughness, and metalness), and
- the surrounding light in the scene (an HDR “environment map” that captures where the lights are and how bright they are).
The big idea is to use several views of the same object to figure out what belongs to the object itself (its true material) and what comes from lighting, which is usually very hard to separate from just one image.
2) What questions are the researchers asking?
The paper focuses on a few simple questions:
- Can we reliably tell what an object is made of (its true surface properties) versus how it’s lit, using a few photos from different angles?
- Can we do all the steps—shape, materials, and lighting—together in one fast pass, instead of using separate, slow pipelines?
- Can a single system work well on both “perfect” synthetic data and messy, real-world photos?
- Can we estimate the scene’s lighting even if we don’t always see the background directly (for example, when it’s cropped out), by reading clues from reflections and shading on the object?
3) How did they do it? (Methods in everyday language)
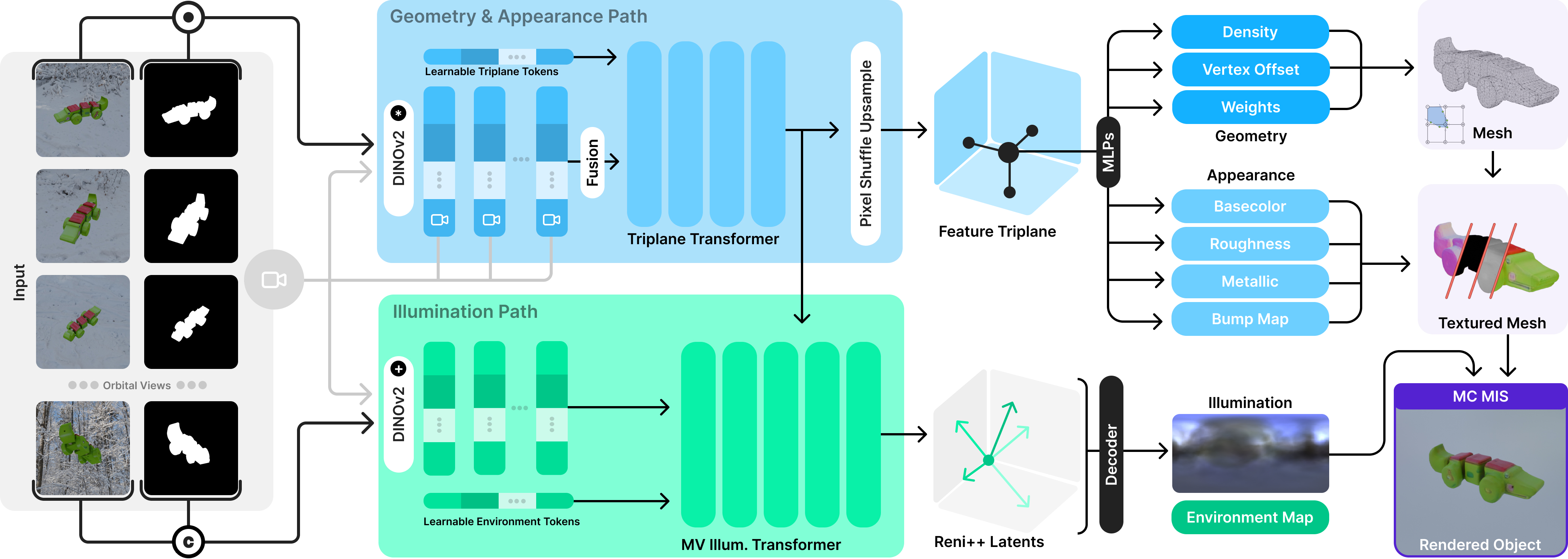
Think of the system like a two-track brain that first fuses information from multiple photos, then splits into two specialized paths that help each other.
- Multi-view fusion with a “transformer”: A transformer (a smart pattern-finding model used in modern AI) looks at all the input photos and “summarizes” what stays the same across views. This cross-view agreement is the key: if the same spot looks different in two pictures, the system can tell whether that’s because of material or lighting.
- A shared 3D “triplane” representation: Imagine three transparent sheets crossing each other (like the x-y, y-z, and z-x planes). The model stores features on these three sheets. Any point in 3D can be described by reading the features at its projections onto the sheets and combining them. This gives a compact, fast way to represent 3D details.
- Two-path prediction:
- base color (what the object really looks like without lighting),
- roughness (how smooth or matte it is),
- metalness (how metallic it is), and
- tiny bumps (normal maps) for fine detail.
- 2) Illumination Path:
- In parallel, the system predicts the scene’s lighting as an HDR environment. It uses a compact lighting code (called RENI++)—like a short recipe that can be decoded into a full 360° light map. It learns from two kinds of clues:
- Background pixels, when visible, show the actual environment.
- Reflections and shading on the object reveal lights even when the background is hidden.
- Training with a differentiable, physics-based renderer: To teach the system, they use a physically correct “light simulator” that renders images from the predicted shape, materials, and lighting—and then compares these to the real photos. Because this renderer is differentiable, the system can adjust its predictions to better match reality. “Monte Carlo” sampling here means the renderer estimates light by trying many random light paths; “Multiple Importance Sampling” is a smart way to combine different sampling strategies to reduce noise and make training stable.
- Mixed-domain training:
- Synthetic data with full ground-truth materials and lighting, and
- Real-world photos where only the images are known.
- This mix helps it work well on real objects, not just perfect synthetic ones. During training, they sometimes hide the background on purpose, so the model also learns to read lighting from reflections.
4) What did they find, and why is it important?
Main results:
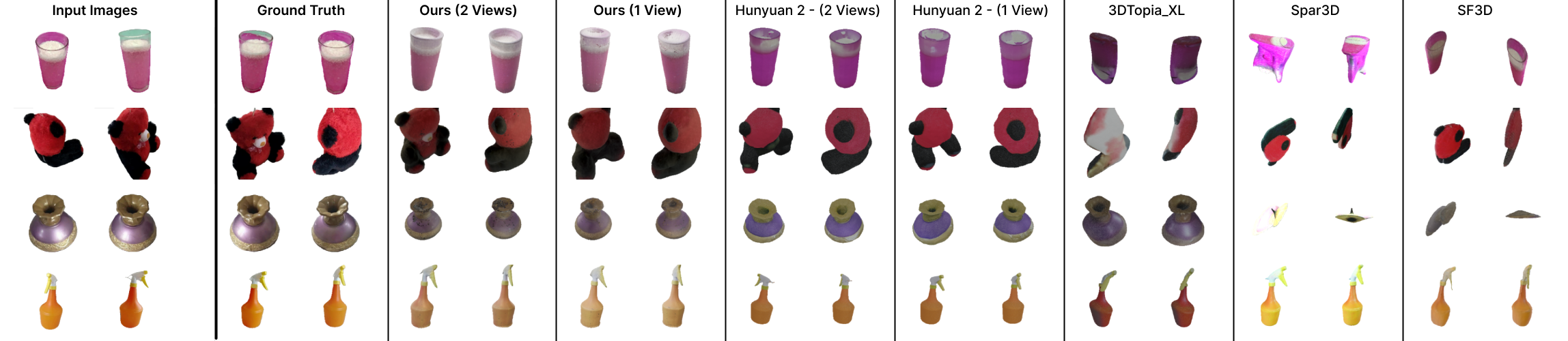
- Fast and unified: ReLi3D produces a full 3D mesh, detailed materials, and an HDR environment in about 0.3 seconds—much faster than many existing methods.
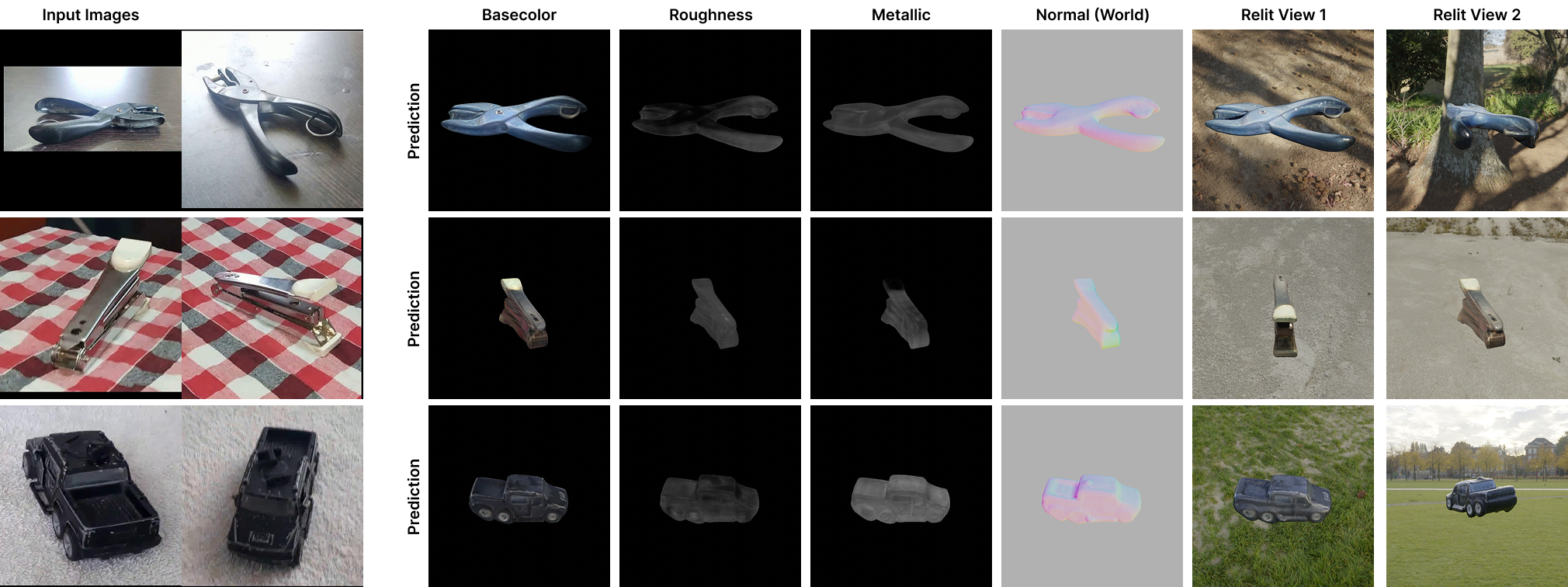
- Better material-light separation: Using multiple views significantly improves “disentanglement”—telling what the object truly looks like versus what the lights are doing. This leads to more accurate base color, roughness, and metalness maps.
- Strong relighting: When the reconstructed object is placed under new lighting, it still looks correct and realistic. That means the materials are physically plausible, not just “baked-in” from the original photos.
- Accurate environment lighting: Even with just one or a few views, the system can estimate the direction and color of main light sources. With background visible, it can directly read the environment; without background, it infers lighting from reflections.
- Competitive geometry: While the main focus is materials and lighting, the shape reconstructions are still strong and comparable to top methods.
Why this matters:
- Getting materials and lighting right is crucial if you want to reuse the 3D model in a new scene, change the lighting, or use it in movies/games/AR. ReLi3D makes this fast and practical.
5) What’s the bigger impact?
- For creators and studios: Faster, one-click creation of “production-ready” 3D assets from casual photos could shorten workflows in games, film, e-commerce, and AR/VR.
- For robotics and design: Robots and design tools that need realistic object models can benefit from quick, physically accurate reconstructions.
- For research: The “multi-view + two-path + physics-based training” recipe shows a promising way to solve other tricky “what’s material vs. what’s lighting” problems.
- Open science: The authors plan to release code and pretrained models, helping others build on this work.
In short, ReLi3D shows that with just a few photos, we can quickly make a realistic 3D object that looks right under any light. That’s a big step toward easy, everyday 3D creation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research:
- Dependence on accurate inputs:
- Assumes known, accurate camera poses and object masks; robustness to pose/mask errors, lens distortion, or intrinsics miscalibration is not quantified and no joint pose–reconstruction is attempted.
- Sensitivity to inter-view exposure and white-balance differences in real captures is not evaluated or modeled.
- Material modeling limitations:
- Constrained to Disney metallic–roughness with normal maps; lacks support for anisotropy, clearcoat, specular tint, subsurface scattering, thin/transmissive dielectrics (glass), and layered/complex BSDFs.
- No handling of transparent/participating media (e.g., glass, liquids, fog), leaving disentanglement under refraction/transmission unaddressed.
- Illumination modeling and RENI++ prior:
- Lighting is represented solely as a global HDR environment; local/area lights and emissive objects are not modeled or decomposed.
- Failure cases occur for out-of-domain lighting (e.g., multiple strong sources); it remains open how to extend beyond RENI++ (e.g., hybrid env+procedural/directional/area lights, spherical Gaussian mixtures).
- Absolute exposure/scale ambiguity between albedo and HDR intensity in real images is not explicitly resolved or calibrated.
- Renderer and training details:
- The differentiable MC+MIS renderer lacks disclosed bounce depth, sample counts, and variance control; the impact of single- vs multi-bounce transport on material learning is unclear.
- Potential gradient bias/variance trade-offs (e.g., reparameterization, edge handling) are not analyzed; comparisons to alternative differentiable renderers are missing.
- Stochastic background masking strategy (rates, mask-quality sensitivity) lacks ablation; its effects under imperfect masks are unclear.
- Multi-view fusion and disentanglement ablations:
- No ablation isolating the contribution of hero-view selection, latent mixing, and the two-path design to disentanglement quality.
- Sensitivity to view layout (baselines, coverage patterns), minimal number of views for reliable separation, and capture planning strategies remain unexplored.
- Resolution, assets, and production readiness:
- Triplane resolution (3×40×384×384) and ~4.5k-vertex meshes limit high-frequency geometry and texture detail; scalable upsampling/refinement or UDIM/tiling strategies are not provided.
- UV unwrapping quality (seams, distortion, texel density) and its impact on material fidelity is not evaluated.
- No pathway for high-res detail synthesis (e.g., super-resolution/diffusion refinement) integrated with the disentangled outputs.
- Evaluation coverage and metrics:
- Quantitative evaluation of HDR environment estimation (e.g., sun direction error, angular power distribution, dynamic range) is absent; only qualitative results are shown.
- Real-world material metrics beyond basecolor (roughness/metallic) are not assessed due to missing ground truth; alternative validation protocols are not proposed.
- The effect of ICP alignment on comparative fairness is not fully addressed; canonicalization consistency across methods remains an open evaluation issue.
- Generalization and domain gaps:
- Mixed-domain training choices (ratios, curricula) lack systematic study; the role of each data source in generalization is not ablated.
- Robustness to real-world artifacts (motion blur, noise, compression, rolling shutter) is claimed qualitatively but not quantified.
- Handling of scenes with multi-object interactions, occlusions, and mutual illumination (scene-level inverse rendering) is not addressed; the method assumes isolated, masked objects.
- Edge cases and failure modes:
- Highly specular or mirror-like objects, extreme gloss, and reflective ambiguities are not analyzed in depth.
- Contact shadows and object–support interactions are not modeled (no shadow-catcher or ground-plane), risking baked-in shadows into albedo.
- Deterministic, single-shot predictions lack uncertainty estimates; there is no mechanism to communicate confidence or suggest additional views.
- Practical deployment:
- Inference time is reported on an H100; performance, memory footprint, and throughput on consumer GPUs or mobile hardware are not provided.
- Export fidelity of decoded RENI++ environments to standard equirectangular HDR formats is not validated (e.g., intensity calibration, DR limits).
- Pipeline for unposed, in-the-wild captures (joint pose, masks, exposure) is not integrated, leaving an open path to a fully self-contained system.
- Future extensions:
- Joint estimation of camera poses, geometry, materials, and lighting from unposed images remains open.
- Extending to dynamic or deformable objects, non-rigid materials (cloth, hair), and temporal consistency is unexplored.
- Alternative lighting representations (e.g., spherical Gaussians, neural light fields) and hybrid light decomposition could broaden illumination coverage and reduce dependence on a single prior.
Practical Applications
Immediate Applications
The following applications can be deployed with current capabilities (given the paper’s released code/weights and typical GPU inference), and map directly to existing workflows and tools.
- Bold: Scan-to-Relightable Asset for VFX, Games, and XR
- Sector: Media/entertainment, software, gaming, AR/VR
- Tools/products/workflow: Blender/Unreal/Unity plug-in that ingests 4–8 smartphone photos, computes poses (e.g., COLMAP, ARKit), runs ReLi3D to output mesh + svBRDF (albedo/roughness/metallic/normal) + HDR environment; exports GLTF/GLB/USD for immediate relighting and lookdev
- Assumptions/dependencies: Requires posed, masked images (auto-masking can be integrated); GPU for sub-second inference (timings reported on H100; consumer GPUs may be slower); limited texture/geometry resolution due to triplane size; translucency/SSS/aniso not modeled; occasional baked-in lighting under out-of-domain illuminations
- Bold: E-commerce Product Digitization with Consistent Relighting
- Sector: Retail/e-commerce, advertising/marketing
- Tools/products/workflow: Web service or Shopify plug-in that converts sparse product photos into standardized 3D PBR assets; generates consistent renders across brand-approved HDRIs; interactive 3D viewers on product pages using glTF 2.0 PBR
- Assumptions/dependencies: Basic turntable or controlled capture helps; accurate masks; privacy review if releasing inferred HDRIs (environment maps can reveal location); PBR fidelity best for opaque/metallic–roughness materials
- Bold: On-set HDR Capture via Object Reflections
- Sector: Film/TV, photography, advertising
- Tools/products/workflow: Set tool that infers HDR environment from partial backgrounds and object reflections when gray-ball/bracketed captures aren’t available; export HDRI to match CG lighting to plates
- Assumptions/dependencies: Inference benefits from specular cues; out-of-domain lighting (many bright sources) can degrade accuracy; ensure camera pose estimates
- Bold: Robotics Simulation Asset Ingestion with Physical Materials
- Sector: Robotics, industrial simulation
- Tools/products/workflow: Pipeline to scan real objects into sim (Isaac Sim, Unity, Unreal) with svBRDF for more realistic visual+sensor responses; roughness/metallic proxy features can inform grasp planning heuristics and domain randomization
- Assumptions/dependencies: Geometry is mid-res (few thousand vertices); friction must be calibrated—roughness/metallic are not direct friction coefficients; requires pose estimation and masks
- Bold: Cultural Heritage and Museum Object Capture (Rapid PBR)
- Sector: Culture/heritage, education
- Tools/products/workflow: Field workflow to capture artifacts with sparse images and obtain faithful materials for digital exhibits and relightable archives
- Assumptions/dependencies: Non-invasive capture only; challenging materials (glossy varnishes, gemstones, translucency) may be imperfect; robust masking needed; verify licensing for public distribution
- Bold: Surface Finish QA Pre-screening (Material Consistency Checks)
- Sector: Manufacturing/QA
- Tools/products/workflow: Station that scans parts and flags deviations in basecolor/roughness spatial maps vs. references (e.g., paint orange peel, coating nonuniformity) under varying lighting
- Assumptions/dependencies: Not metrology-grade; relies on good pose estimates and masks; environment prior coverage matters (best in controlled booths)
- Bold: Virtual Staging and AR Commerce
- Sector: Real estate, furniture/consumer goods, AR marketing
- Tools/products/workflow: Rapid creation of relightable furniture/objects for AR try-on; environment estimation helps match lighting when compositing into rooms
- Assumptions/dependencies: On-device performance may require cloud inference; single-view is possible but multi-view improves fidelity
- Bold: Education and Research Bootstrapping for Inverse Rendering
- Sector: Academia/education
- Tools/products/workflow: Course labs/demos on svBRDF and illumination disentanglement; dataset bootstrapping for material analysis; ablation studies of multi-view constraints
- Assumptions/dependencies: Access to GPUs; reliance on RENI++ lighting prior; content licenses for released datasets
- Bold: Photo Retouching/Lookdev Assist
- Sector: Creative tools
- Tools/products/workflow: Adobe Substance/Blender add-on that extracts PBR textures + HDRI from product shots to speed lookdev, material tweaking, and consistent relighting across campaigns
- Assumptions/dependencies: Requires good masks; performance tied to GPU; limitations on exotic BRDFs
- Bold: Low-Latency API for 3D Asset Generation
- Sector: Software/SaaS
- Tools/products/workflow: REST/gRPC service that takes N views + camera poses, returns mesh + svBRDF + HDRI; integrates with DCCs via Python/C++ SDKs
- Assumptions/dependencies: Pose estimation (server-side SfM or client ARKit), segmentation, privacy controls for environment maps
Long-Term Applications
These opportunities are plausible but require further R&D, scaling, or ecosystem integration (e.g., higher-res triplanes, broader lighting priors, mobile acceleration).
- Bold: Real-time Mobile 3D Scanning with On-device Relightable Output
- Sector: Consumer apps, AR/VR
- Tools/products/workflow: Smartphone camera app producing instant PBR assets and HDR environment; integrates with social/marketplace platforms
- Assumptions/dependencies: Model compression and mobile NPUs; robust pose/mask estimation on-device; improved high-frequency details
- Bold: Full-Scene Inverse Rendering from Sparse Views
- Sector: AEC, robotics, VFX
- Tools/products/workflow: Room-scale reconstruction with per-surface svBRDF and coherent scene illumination (not just object-centric); used for virtual production, lighting design, and AR occlusion
- Assumptions/dependencies: Scaling multi-view fusion beyond objects; handling interreflections/shadows across large scenes; broader lighting/material priors
- Bold: Online Material–Lighting Reasoning for Robotic Manipulation
- Sector: Robotics
- Tools/products/workflow: On-robot inference that estimates materials and environment in real time to adapt grasp strategies (slip risk, glare avoidance), exposure control, and sensor fusion
- Assumptions/dependencies: Edge inference acceleration; tighter linkage from svBRDF to mechanics (friction/adhesion); robust performance under motion blur and partial views
- Bold: Automated Warehouse/Inventory Digitization
- Sector: Logistics/retail
- Tools/products/workflow: Conveyor or turntable systems that produce PBR 3D twins of SKUs for catalogs, AR try-on, and damage detection
- Assumptions/dependencies: Industrialized pose/mask pipelines; throughput optimization; compliance/privacy for environment capture
- Bold: Material Library Mining from the Wild
- Sector: Design, materials research, graphics
- Tools/products/workflow: Large-scale capture to learn robust, lighting-invariant material priors; build curated svBRDF libraries for rendering and design tools
- Assumptions/dependencies: Diverse and annotated datasets; handling anisotropy, SSS, translucency; standardized evaluation protocols
- Bold: Forensics and Insurance—Evidence-grade 3D with Lighting Provenance
- Sector: Public safety, insurance/finance
- Tools/products/workflow: Capture damaged objects with disentangled materials/illumination to improve claims assessment and scene analysis
- Assumptions/dependencies: Chain-of-custody standards; calibrated capture kits; validated accuracy metrics and certification
- Bold: Sustainable Content Pipelines (Fewer Reshoots)
- Sector: Media/advertising, sustainability
- Tools/products/workflow: Replace repeated reshoots with relighting of accurate PBR assets; estimate HDRI from on-location captures and reuse across campaigns
- Assumptions/dependencies: Stakeholder acceptance; high-res textures; governance over environment-map privacy
- Bold: Policy and Standards for 3D Product Assets
- Sector: Policy/standards, e-commerce
- Tools/products/workflow: Draft standards requiring PBR-compliant assets and optional HDR metadata for consistent cross-platform rendering; digital product passport extensions to include 3D with material fidelity
- Assumptions/dependencies: Industry consortia (e.g., Khronos/glTF, USD) participation; privacy guidelines for environment data; IP rights for scanned products
- Bold: Scene Illumination Analytics for Architecture and Energy
- Sector: AEC, energy efficiency
- Tools/products/workflow: Use environment estimation to analyze day-lighting patterns and inform lighting retrofits and fixture placement
- Assumptions/dependencies: Transition from object-centric to scene-centric lighting estimation; validated correlation to lux measurements
- Bold: High-fidelity Reverse Engineering and 3D Printing Prep
- Sector: Manufacturing/R&D
- Tools/products/workflow: Hybrid pipelines where fast ReLi3D proxies guide targeted high-res scans; combine with CAD fitting and texture baking for production-ready replicas
- Assumptions/dependencies: Upscaling geometry and UVs; integration with metrology-grade scanning when required
Cross-cutting assumptions and dependencies
- Posed, masked inputs: Robust camera intrinsics/extrinsics and segmentation are critical. Production pipelines typically integrate SfM (COLMAP) or ARKit/ARCore; auto-masking can be coupled with SAM/Segment-Anything-class models.
- Hardware considerations: Reported 0.3 s inference is on an H100; expect longer runtimes on consumer GPUs or mobile. Real-time on mobile requires model compression/acceleration.
- Lighting prior coverage: RENI++ latent space may miss certain multi-source/atypical illuminations; retraining or alternative lighting priors could broaden coverage.
- Material model limits: Disney metallic–roughness without explicit SSS, anisotropy, or transmission reduces fidelity for fabrics, skin, hair, glass, and gems.
- Resolution constraints: Triplane resolution caps texture/geometry detail; higher-res triplanes or super-resolution modules may be needed for hero assets.
- Privacy/IP: Inferred HDR environments can reveal capture locations; policies and redaction tools may be needed. Ensure rights to scan products and redistribute assets.
- Data/domain bias: Mixed-domain training helps, but category/appearance biases can persist; additional domain-specific fine-tuning may be required.
Glossary
- Albedo: The base color of a material that reflects light diffusely, independent of illumination direction or intensity. "albedo reconstruction achieves 25.00 dB PSNR"
- Antithetic sampling: A variance-reduction technique in Monte Carlo methods that draws paired, negatively correlated samples to stabilize estimates. "antithetic sampling … helps stabilize the training"
- Bidirectional reflectance distribution function (BRDF): A function describing how light is reflected at a surface, mapping incoming to outgoing directions. "bidirectional reflectance distribution function (BRDF)"
- Cross-attention: An attention mechanism where a set of query tokens attends to a separate set of memory/context tokens. "update with cross-attention to "
- Cross-conditioning transformer: A transformer architecture that fuses information across different input streams (e.g., multiple views) by conditioning one token stream on another. "a shared cross-conditioning transformer"
- DINOv2: A self-supervised vision transformer used to encode images into feature tokens for downstream tasks. "encodes input images with DINOv2"
- DMTet: A differentiable isosurface extraction framework (Differentiable Marching Tetrahedra) used to decode neural features into meshes. "decoded into geometry via DMTet"
- Environment map: A directional function representing incoming light from all directions, used to light scenes. "environment map "
- Flexicubes: A flexible isosurface extraction method enabling high-quality, gradient-based mesh optimization. "Geometry is extracted using Flexicubes"
- Gaussian splats: A scene representation that renders 3D scenes via projected Gaussian primitives for efficient differentiable rendering. "Gaussian splats"
- HDR environment: A high dynamic range illumination representation capturing bright light sources and wide intensity ranges for realistic lighting. "a coherent HDR environment"
- Hero view: The designated primary input view whose tokens drive the query stream during cross-view fusion. "We designate one view as the hero view"
- Illumination disentanglement: The separation of lighting effects from intrinsic material properties so each can be estimated independently. "illumination disentanglement"
- Inverse rendering: Estimating shape, materials, and lighting from images by inverting the rendering process. "Inverse rendering estimates shape, appearance, and environment lighting"
- Iterative Closest Point (ICP) alignment: An algorithm that rigidly aligns two shapes by iteratively matching closest points. "rigid ICP alignment"
- Latent mixing: Combining learnable latent tokens with cross-view tokens to form a compact, expressive memory for attention. "we employ latent mixing"
- Mask-aware tokens: Transformer tokens that jointly encode an image and its foreground mask to reason about object/background separation. "mask-aware tokens"
- Metallic-roughness representation: A material parameterization (Disney principled) using base color, roughness, and metallic values to model surface reflectance. "metallic-roughness representation"
- Monte Carlo (MC) renderer: A renderer that uses stochastic sampling to numerically integrate light transport; in this work, it is differentiable. "A differentiable physically-based … Monte Carlo (MC) renderer"
- Multiple Importance Sampling (MIS): A technique that combines multiple sampling strategies to reduce variance in Monte Carlo integration. "Multiple Importance Sampling (MIS)"
- NeRF: Neural Radiance Fields, a neural scene representation that models view-dependent radiance and density for photorealistic rendering. "NeRF"
- Normal bump maps: Texture maps that perturb surface normals to encode high-frequency detail without changing geometry. "normal bump maps encode high-frequency surface perturbations"
- Pixel-shuffle upsampling: A neural upsampling operation (depth-to-space) used to increase spatial resolution of feature maps. "we use pixel-shuffle upsampling"
- Positional encoding: A mapping that embeds directions or coordinates into a higher-dimensional space to capture high-frequency variation. "positional encoding"
- Physically Based Rendering (PBR): A rendering approach that models light–material interaction using physically grounded parameters and equations. "Physically Based Rendering (PBR)"
- RENI++: A learned compact illumination prior that decodes latent codes into realistic environment maps with high-frequency detail. "RENI++ latent code"
- Relighting: Rendering a reconstructed object under novel illumination to test material–lighting separation. "Relighting performance"
- Score Distillation Sampling: An optimization approach that leverages diffusion model score gradients to guide 3D generation from 2D priors. "Score Distillation Sampling methods"
- Spatially varying BRDF (svBRDF): A BRDF whose parameters vary across the surface, enabling multi-material, detailed appearance. "spatially varying BRDF (svBRDF)"
- Spherical Gaussians: A basis for approximating functions on the sphere using Gaussian lobes; often used to model lighting. "spherical Gaussians"
- Spherical harmonics: A set of orthonormal basis functions on the sphere commonly used to represent low-frequency lighting. "spherical harmonics"
- Triplane representation: A 3D encoding using three orthogonal 2D feature planes from which per-point features are sampled. "triplane representations"
- Two-stream interleaved transformer: A transformer that alternates updates between a query stream and a memory stream via self- and cross-attention blocks. "two-stream interleaved transformer"
- UV unwrapping: The process of mapping a 3D surface to 2D texture coordinates for material parameter baking. "UV unwrapping"
- VNDF sampling: Sampling from the Visible Normal Distribution Function in microfacet models (e.g., GGX) for physically plausible specular directions. "VNDF sampling"
Collections
Sign up for free to add this paper to one or more collections.

