Computation and sampling for Schubert specializations
Abstract: We present computational results on principal specializations $\mathfrak{S}w(1n)$ of Schubert polynomials, which count reduced pipe dreams and reduced bumpless pipe dreams (RBPD). We find the first counterexample, at $n=17$, to the Merzon-Smirnov conjecture (arXiv:1410.6857) that the maximum of $\mathfrak{S}_w(1n)$ over $S_n$ is attained at a layered permutation. The simulations suggest that $\lim{n \to \infty} \log(\max_{w\in S_n}\mathfrak{S}w(1n))/n2$ equals the maximal layered permutations' constant from Morales-Pak-Panova (arXiv:1805.04341). We also explore the random permutation drawn from the distribution proportional to $\mathfrak{S}_w(1n)$, revealing permuton-like asymptotics similar to those for Grothendieck polynomials by Morales-Panova-Petrov-Yeliussizov (arXiv:2407.21653). We implement and compare three recurrences for $\mathfrak{S}_w(1n)$: the descent formula (Macdonald), transition formula (Lascoux--Schutzenberger), and cotransition formula (Knutson). For sampling uniformly random RBPDs (whose count is $\sum{w\in S_n} \mathfrak{S}_w(1n)$), we show that reducedness breaks the sublattice property of the ASM lattice, preventing monotone CFTP and causing false coalescence. We develop an efficient MCMC sampler with macroscopic "droop" updates for connectivity and fast mixing. Our code computes $\mathfrak{S}_w(1n)$ up to $n\sim 20$ and samples random RBPDs up to $n\sim 60$ on a personal computer ($n\sim 100$ on a cluster).



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
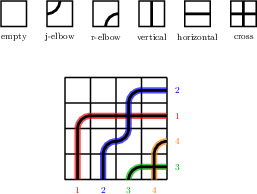
Imagine a square grid filled with “pipes” that travel from the bottom and left edges to the top and right edges, using simple tiles that either turn or go straight. The pipes aren’t allowed to cross each other more than once. Each finished grid that follows these rules is a valid puzzle, called a reduced bumpless pipe dream (RBPD). For every way of matching the inputs to the outputs (that matching is a permutation), you can ask: how many valid puzzles lead to that matching?
This paper studies those counts. In math terms, they are special values of Schubert polynomials, written as S_w(1n). The authors:
- Build fast algorithms to compute these counts.
- Create a way to generate (sample) random valid puzzles fairly.
- Disprove a popular guess about which permutations give the biggest counts.
- Explore what a “typical” random puzzle and its permutation look like when the grid gets very large.
The main questions they ask
- Which permutations w give the biggest number of valid puzzles (the biggest S_w(1n))?
- Can we compute S_w(1n) quickly for medium-to-large n (like n around 20)?
- What does a “typical” permutation look like if we pick an RBPD uniformly at random?
- Can we sample these RBPDs exactly and efficiently?
How they approached the problem (in everyday terms)
To count puzzles fast, they used three “recipes” (recurrence formulas) that break a hard count into easier ones:
- Descent formula (Macdonald): Think of stepping down by undoing one “move” at a time, averaging over certain choices.
- Transition formula (Lascoux–Schützenberger): Switch a key pair in the permutation and add up simpler pieces; only addition is used (no division), which is good for exact results.
- Cotransition formula (Knutson): Move “upward” toward the most scrambled permutation by adding together counts from “neighbors”; again, it uses only addition.
They then coded and compared these methods to see which is fastest in practice.
For sampling random puzzles, they tried a classic exact method (CFTP, Coupling From The Past) that works well on related models of arrow grids (alternating sign matrices). But it fails here because the “no two pipes cross twice” rule is a global rule that breaks the nice lattice structure needed for CFTP to work. So they designed a custom Markov chain Monte Carlo (MCMC) sampler instead, with special big “droop” moves that rearrange many tiles at once. These big moves make sure any valid puzzle can be reached and help the chain mix quickly.
What they found and why it matters
- First counterexample to a known conjecture: For years, it was believed (and checked for small sizes) that the biggest count S_w(1n) happens for “layered” permutations—ones built from blocks that go down within the block. The authors proved this isn’t always true: at n = 17 they found a specific non-layered permutation whose count beats the best layered one by about 7%, and another beating it by about 15.6%. They also checked all permutations up to n = 13 and confirmed the conjecture holds there; it first fails at n = 17.
- Same long-term growth as layered (based on evidence): Even though layered permutations don’t always win, the largest possible count seems to grow at the same exponential rate as the layered case when n is very large. In symbols, the limit of (1/n2) log(max S_w(1n)) appears to match the layered value. This suggests the layered family captures the right “constant” for growth, even if they miss the exact maximizers at some sizes.
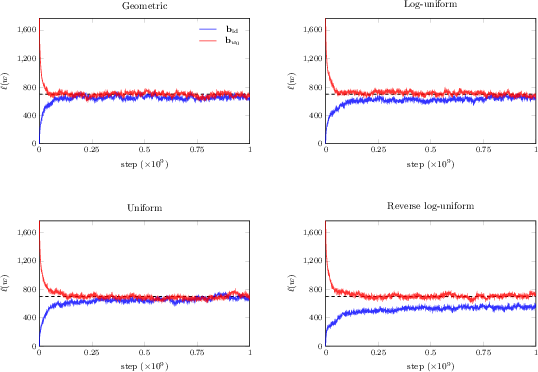
- Fast counting in practice:
- For typical random permutations (from their sampler), the cotransition formula is fastest.
- For permutations near the identity (very orderly), the descent formula is fastest.
- The transition formula is competitive, especially as n grows, and is good for exact arithmetic.
- Powerful sampling: Their MCMC with droop moves can sample uniform RBPDs up to around n ≈ 60 on a laptop and n ≈ 100 on a computing cluster. This unlocks large-scale experiments.
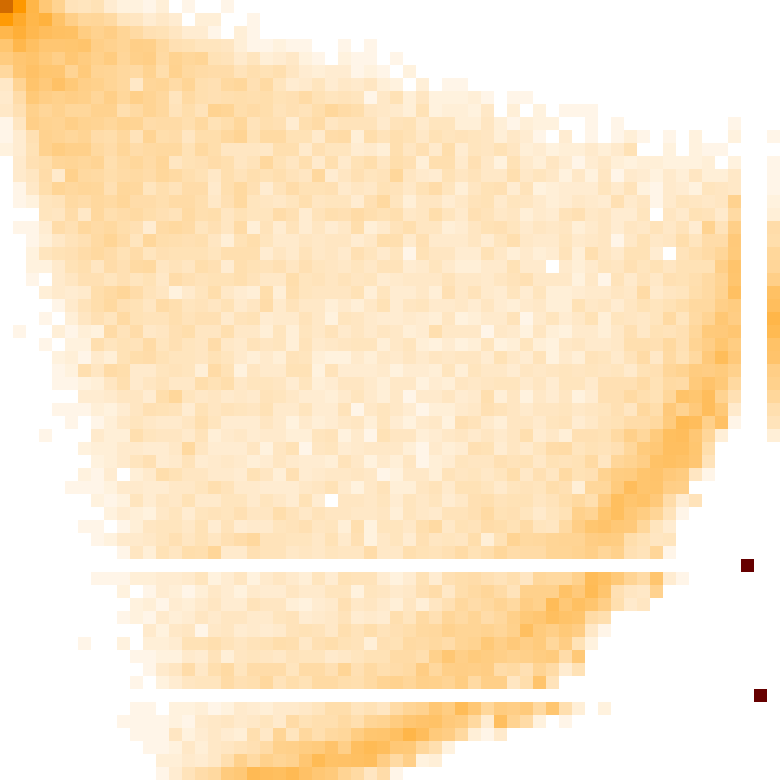
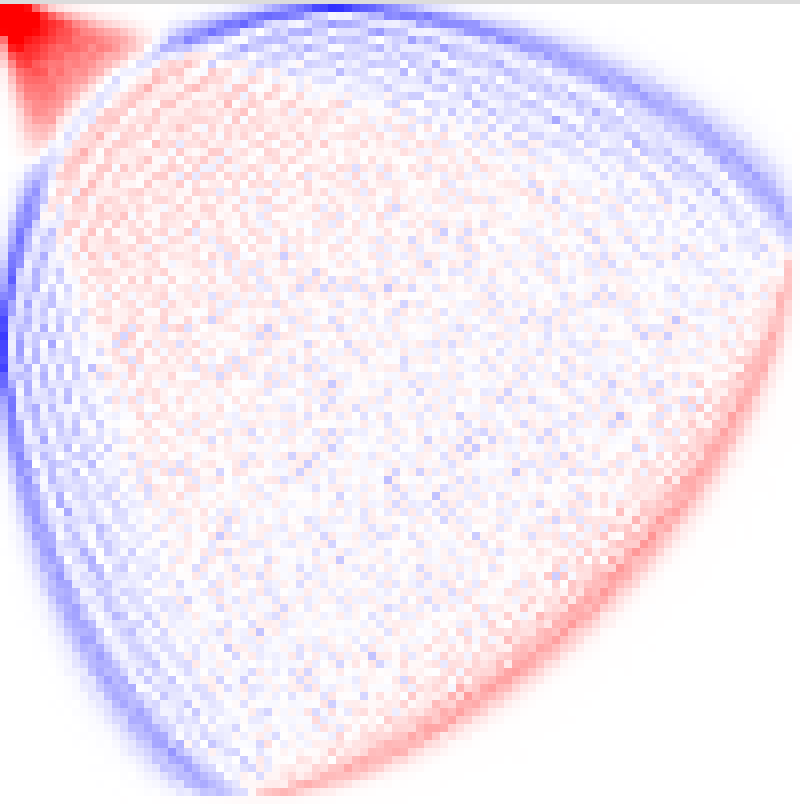
- Typical shape and “permuton”: If you plot a permutation as dots in a square, a huge random permutation often looks like a blurry shape with a certain density. That limiting “fuzzy picture” is called a permuton. Their simulations show a clear, stable picture for RBPDs that looks very similar to the one recently proved for a related model (Grothendieck polynomials), although here it remains a conjecture. They also see “limit shapes” and boundary curves (sometimes called arctic curves) in the tile patterns—frozen regions near corners and a liquid region in the middle.
Why this is important and what could come next
- Bridges algebra, combinatorics, and physics: Schubert polynomials arise in geometry (studying flag varieties), while RBPDs connect to models from statistical physics (the six-vertex model). Understanding counts and typical shapes helps both communities.
- New algorithms and computational power: The carefully engineered counting and sampling methods let researchers explore sizes that were out of reach, guiding new conjectures and testing old ones.
- Refined understanding of maxima: Disproving the “layered always wins” guess reshapes how we search for extreme behavior—and hints that the overall growth constant still matches layered behavior, which is a subtle and interesting twist.
- Future directions:
- Prove the permuton and limit-shape conjectures rigorously for RBPDs (hard because the “no double crossings” rule creates long-range interactions).
- Narrow the exact value of the long-term growth rate and show the limit exists.
- Design even faster samplers and counters, or find structural clues that explain which permutations are near-optimal and why.
Overall, the paper combines clever math, efficient coding, and large-scale experiments to answer long-standing questions, correct a widely believed claim, and chart a roadmap for understanding these intricate pipe-based puzzles at massive scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances computation and sampling for principal specializations of Schubert polynomials and reports counterexamples to a long-standing conjecture, but it leaves several concrete directions unresolved. The following list distills what remains missing or uncertain and where focused work could move the field forward:
- Asymptotic maximum (Stanley’s question): existence of the limit L = lim_{n→∞} (1/n2) log_2 max_{w∈S_n} 𝛶_w, and rigorous determination of its value.
- Equality of constants: whether L coincides with the layered-permutation constant from Morales–Pak–Panova (~0.290…), as suggested by simulations despite non-layered counterexamples at n ≥ 17.
- Maximizer structure: characterization of permutations achieving max_{w} 𝛶_w for large n (beyond layered), including:
- Whether maximizers remain “close” to optimal layered permutations (e.g., bounded adjacent transposition distance) for all large n.
- Whether there is a canonical family of maximizers (e.g., parametrized block structures or pattern-classes) emerging asymptotically.
- Stability of properties such as w(1)=1 for maximizers and whether analogous fixed-point constraints extend (e.g., w(k)=k for small fixed k).
- Sharper asymptotic bounds: improvement of the current 0.29–0.37 bracketing using new combinatorial or six-vertex/ASM-based techniques adapted to the reducedness constraint.
- Second-order asymptotics: determination of lower-order terms in log max_{w} 𝛶_w (e.g., n2 leading term plus n log n or n terms), and concentration or fluctuations around the maximal value.
- Abundance and growth of counterexamples: systematic census of non-layered maximizers/counter-maximizers for 17 ≤ n ≤ 30+, and asymptotic rate at which layered optimality fails (threshold n*, density of examples, size of improvements over layered).
- Typical-permutation limit (Schubert permuton): rigorous derivation of the limiting permuton for permutations drawn with probabilities proportional to 𝛶_w, including:
- Proof of existence/uniqueness of the limit.
- Identification (analytic form) of the limiting permuton and verification that it matches or differs from the Grothendieck case.
- Quantification of deviations and large deviations from the limit permuton.
- RBPD limit shape and arctic curves: rigorous determination of the macroscopic limit shape and arctic boundary for uniformly random reduced bumpless pipe dreams (as conjectured), including PDE/variational principle characterization and boundary conditions.
- Integrability barriers: development of techniques to handle the nonlocal “each pair of pipes crosses at most once” constraint (e.g., colored vertex interpretations with many colors), or approximation schemes that preserve enough structure to prove limit shapes/permutons.
- Exact sampling obstacles: design of exact samplers despite failure of monotone CFTP, including:
- Alternative partial orders or bounding processes restoring monotonicity or enabling sandwiching arguments.
- Nonmonotone CFTP variants or dominance-coupling frameworks tailored to RBPDs with reducedness.
- MCMC guarantees: theoretical analysis of the proposed macroscopic “droop”-augmented MCMC sampler:
- Formal proof of irreducibility and aperiodicity under the specified move set for all n.
- Mixing time bounds (e.g., polynomial in n), spectral gap estimates, or coupling arguments.
- Sensitivity to move-size schedules and finite-size scaling of autocorrelation times.
- State-space connectivity via local moves: minimal local (or mesoscopic) generating move sets for the RBPD space and precise characterization of connectivity/diameter under these moves.
- Complexity of exact evaluation: computational complexity classification of computing 𝛶_w for arbitrary w (e.g., #P-hardness), and identification of tractable subclasses beyond layered permutations.
- Broader exact formulas: discovery of closed-form or product-type formulas for 𝛶_w in new families (e.g., pattern-avoidance classes, layered-with-perturbations, separable permutations), to enable optimization or asymptotic analysis.
- Algorithmic improvements:
- Faster evaluation beyond recurrences (descent/transition/cotransition), e.g., dynamic programming over inversion sets, polytope volume or lattice-point methods, or deterministic approximate counters with provable error.
- Enhanced Bruhat-cover generation and pruning strategies for cotransition BFS; meet-in-the-middle and bidirectional search with tighter memory.
- Parallel/distributed implementations (GPU/FPGA, external-memory sort-reduce) that push exhaustive max searches to n > 13.
- Numerical reliability: floating-point stability and certified rounding for large values of 𝛶_w (where doubles lose integer accuracy), including compensated summation, mixed-precision strategies, or specialized rational/integer kernels that retain speed.
- Distribution of 𝛶_w over S_n: rigorous results on typical scale (mean, variance) of 𝛶_w for uniform w, tail bounds, and large deviations; comparison with layered and RBPD-weighted distributions.
- Total RBPD count: asymptotics of the total number of reduced bumpless pipe dreams ∑_{w∈S_n} 𝛶_w, including exponential growth rate and subleading terms; comparison to ASM counts and identification of the impact of reducedness.
- Relationship to Grothendieck model: precise mathematical relationship between Schubert and Grothendieck “typical” objects:
- Whether their permutons/arctic curves coincide or how they differ.
- Interpolation or deformation schemes connecting the two models, and transfer of integrable techniques where possible.
- Structural statistics of maximizers and typicals: systematic study (and, ultimately, proof) of limiting profiles of inversion density, descent sets, and permutation patterns for both maximizing and RBPD-typical permutations.
- Decomposition/normal forms: factorization strategies to reduce effective n (beyond stripping trailing fixed points), e.g., block decompositions, pattern decompositions, or symmetries that lead to faster evaluation and search.
These gaps span asymptotics, rigorous probabilistic limits, exact/approximate sampling, algorithmic performance, and structural characterization. They suggest concrete analytical targets (limits, constants, curves), algorithmic deliverables (exact sampler, faster evaluators, complexity results), and empirical programs (censuses and scaling analyses) that can be pursued in parallel.
Practical Applications
Immediate Applications
The following applications can be put to use now with modest engineering effort, based on the paper’s implemented algorithms, negative sampling result, and simulation workflows.
- Software: fast libraries for Schubert principal specializations
- Sector: software/dev tools; academia (algebraic combinatorics, algebraic geometry)
- What: package the descent, transition, and cotransition evaluators (with packed permutation representations, BFS sort–reduce evaluation, and exact vs. floating-point backends) as a C++/Julia/Python library with a stable API.
- Tools/products/workflows:
- schubert_eval: a library and CLI for computing Upsilon_w with pluggable arithmetic (double/GMP) and strategies (descent/transition/cotransition), automatic stripping of trailing fixed points, and strategy hints based on permutation features.
- SageMath/OSCAR plugins exposing principal specializations and layered permutation utilities.
- Assumptions/dependencies: GMP for exact arithmetic; correctness of the recurrence implementations; compute RAM scales with n and strategy; floating-point precision beyond 253 loses integer exactness.
- MCMC sampler for uniformly random reduced bumpless pipe dreams (RBPDs)
- Sector: academia (probability, statistical mechanics), software/dev tools
- What: use the macroscopic “droop”–augmented MCMC sampler to generate unbiased samples from RBPDs up to n≈60 on laptops and n≈100 on clusters.
- Tools/products/workflows:
- rbpd_sampler: a CLI/library to generate samples, estimate statistics (e.g., empirical permutons), and export tilings and permutations for analysis.
- Data pipelines to produce permuton heatmaps and arctic curve visualizations from batches of samples.
- Assumptions/dependencies: irreducibility and good mixing empirically supported but not proven; performance depends on “droop” move tuning; cluster environments accelerate throughput.
- Practical guidance: when monotone CFTP fails for constrained lattice models
- Sector: academia (stochastic processes, statistical physics), software/dev tools
- What: the proof that reducedness breaks the sublattice property (and thus standard monotone CFTP) provides a diagnostic checklist for perfect sampling attempts in models with global constraints.
- Tools/products/workflows:
- A “model vetting” guide: test for sublattice closure before deploying monotone CFTP.
- Template code demonstrating false coalescence in RBPDs and how to pivot to MCMC.
- Assumptions/dependencies: extrapolation to other models requires verifying whether constraints break the lattice/monotonicity structure.
- Computational workflows for exhaustive or targeted searches in S_n
- Sector: academia (combinatorics), HPC/research computing
- What: level-by-level BFS sort–reduce from both ends (identity and w₀) to find max Upsilon_w up to n=13; targeted neighborhoods around structured families (e.g., layered) to find counterexamples at larger n.
- Tools/products/workflows:
- “Meet-in-the-middle” two-threaded BFS with dynamic meeting detection; hard memory caps; 64-bit/128-bit packed permutation keys.
- Heuristic search around layered permutations guided by small edit distance (Cayley distance) and recurrence value gradients.
- Assumptions/dependencies: memory-bound; scaling beyond n≈13 for exhaustive search requires large RAM or distributed sort–reduce; counterexample discovery depends on search heuristics.
- Educational/visualization tools for permutations, pipe dreams, and six-vertex models
- Sector: education; outreach
- What: interactive web demos that visualize Rothe diagrams, RBPD tilings, height functions, and the correspondence to permutations; sliders for n, layered block sizes, and sampling playback.
- Tools/products/workflows:
- WebGL/Canvas visualizer that streams samples from rbpd_sampler and overlays empirical permuton densities.
- Classroom-ready notebooks illustrating descent/transition/cotransition recurrences and their performance trade-offs.
- Assumptions/dependencies: basic GPU/WebGL rendering; packaged binaries for sampler to avoid heavy local compiles.
- Benchmark datasets and tasks for code assistants and verification tooling
- Sector: software/dev tools; ML for code; research computing
- What: use exact-arithmetic runs as ground truth to test correctness and numerical stability of algorithmic implementations and AI-generated code.
- Tools/products/workflows:
- A curated suite of permutations (layered optima, random RBPD-typical, near-identity, and hard instances) with expected Upsilon_w and timing targets under different backends.
- Assumptions/dependencies: clear licensing of data/code; stable hardware baselines for timing comparability.
- Cross-domain algorithmic patterns: packed-state DP and sort–reduce aggregation
- Sector: software/infra; operations research; bioinformatics; graph algorithms
- What: adapt packed encoding and BFS sort–reduce evaluation for other state-space dynamic programs over graded posets (e.g., certain DAG DP’s, constrained scheduling states).
- Tools/products/workflows:
- A reusable “sort–reduce engine” that emits child states, sorts by key, and reduces sums/products with pluggable semirings (integers/rationals/GF(p)).
- Assumptions/dependencies: state-space must admit level decomposition and associative aggregation; external sort may be needed for very large state volumes.
- Research computing policy and practice: reproducibility and resource planning
- Sector: research IT/policy
- What: provide actionable guidance on RAM capping, level-by-level persistence, exact vs. floating-point modes, and containerized cluster execution for large combinatorial experiments.
- Tools/products/workflows:
- Reference container images (GMP-enabled), CI scripts that run small exact checks alongside faster approximate runs; job arrays for sampling at scale.
- Assumptions/dependencies: institutional cluster availability; software stack standardization.
Long-Term Applications
These directions are feasible but require further theoretical progress, scaling, or method generalization.
- Perfect sampling under global constraints via new couplings or auxiliary chains
- Sector: academia (probability, statistical physics), software/dev tools
- What: design exact samplers for RBPD-like models that circumvent the lack of monotonicity (e.g., bounding chains with certified sandwiched constraints, partial orders on enriched states, or Fill’s algorithm variants).
- Potential products: a general-purpose “constrained perfect sampling” framework with model checkers for lattice closure and automated fallback to exact methods where possible.
- Assumptions/dependencies: new theory on couplings for non-sublattice subsets; proofs of correctness and finite expected running time.
- Analytic limit theorems for Schubert permutations and RBPD limit shapes
- Sector: academia (integrable probability, combinatorics)
- What: rigorous derivation of the conjectured Schubert permuton and arctic curves; extension of integrable methods beyond nonlocal constraints or development of asymptotic variational principles tailored to “single-crossing” interactions.
- Potential products: asymptotic toolkits (symbolic/numeric) for variational problems on constrained tilings; code to compute limit shapes for parameterized boundary data.
- Assumptions/dependencies: breakthroughs in handling long-range interactions in vertex/tiling models.
- Heuristic maximization at larger n with verifiable certificates
- Sector: academia; software/dev tools; ML for math
- What: combine heuristic search (e.g., FunSearch/RL/ILP relaxations) with fast recurrence verification and certificate logging to propose and confirm new maximizers beyond n≈20.
- Potential products: a “propose–verify” platform that explores neighborhoods in permutation space using learned policies and emits verifiable Upsilon_w proof logs.
- Assumptions/dependencies: reliable generalization of heuristics; scalable verification; robust certificate formats.
- Generalized MCMC accelerators for large constrained combinatorial spaces
- Sector: software/dev tools; operations research; EDA/VLSI; computational physics
- What: abstract “droop”/macro-move design patterns to other models (e.g., constrained matchings, floorplans, routing with nonlocal constraints) to achieve faster mixing and better exploration.
- Potential products: a library of macro-move generators with automatic connectivity tests and empirical spectral-gap diagnostics; plug-ins for OR solvers to warm-start from diverse feasible samples.
- Assumptions/dependencies: problem-specific proofs of ergodicity; automated tuning (adaptive MCMC) without breaking stationarity guarantees.
- Data-driven model discovery from RBPD and permutation ensembles
- Sector: data science/ML; academia
- What: use large RBPD/permutation datasets to learn effective low-dimensional descriptors (e.g., learned permuton families), anomaly detection for “exceptionally large” Upsilon_w instances, and surrogate models for rapid screening.
- Potential products: trained density models over permutations with constraint-awareness; fast predictors for recurrence outputs with calibrated uncertainty.
- Assumptions/dependencies: availability of high-quality labeled data (exact counts for smaller n, sampled summaries for larger n); careful validation to avoid extrapolation errors.
- Transfer to physics: constrained six-vertex–type models with long-range interactions
- Sector: physics/materials; computational chemistry
- What: adapt RBPD samplers and asymptotic insights to study phase boundaries and limit shapes in variants of square-ice with global constraints (e.g., defects or color constraints).
- Potential products: simulation packages for domain-wall models with nonlocal interactions; tools to compare arctic curves and finite-size effects.
- Assumptions/dependencies: precise mapping from application-specific constraints to RBPD-like rules; calibration against experimental/known integrable cases.
- High-performance exact enumeration frameworks
- Sector: HPC/research computing; software/dev tools
- What: scale the sort–reduce BFS paradigm to distributed settings (external sorting, partitioned key spaces, lossless compression of packed states) to reach larger n for exhaustive levels or partial enumerations.
- Potential products: a distributed “enumeration fabric” with streaming reducers and memory-safe checkpoints; cloud-native services for on-demand combinatorial counting.
- Assumptions/dependencies: robust distributed sorting; failure tolerance and checkpointing; cost-effective cloud/HPC access.
- Curriculum and assessment modules in advanced combinatorics and probability
- Sector: education
- What: full course modules combining theory (Schubert polynomials, Bruhat order) with hands-on computation and sampling, culminating in student-led experiments on limit shapes and conjecture testing.
- Potential products: open courseware units with automated graders for recurrence implementations and sampler diagnostics; capstone projects.
- Assumptions/dependencies: sustained maintenance of teaching code; access to modest compute for student cohorts.
Notes on feasibility and dependencies
- Numerical stability: double precision becomes unreliable once counts exceed 253; exact arithmetic (e.g., GMP) is preferred for certification.
- Memory and time: exhaustive search scales poorly in n; sort–reduce and packed encodings mitigate but do not eliminate growth; distributed execution or careful pruning is needed at larger n.
- Sampler validity: the MCMC’s stationary distribution is uniform by construction, but practical mixing-time guarantees remain empirical; diagnostics and multiple-chain checks are recommended.
- Model transfer: applying these methods to other constrained models demands verification of key properties (e.g., connectivity under macro moves, presence/absence of lattice structure, feasibility of recurrence analogs).
- Reproducibility: containerized builds and exact-arithmetic “gold” runs are essential for scientific reliability, especially when using AI-assisted coding or heuristic search components.
Glossary
- Alternating sign matrix (ASM): A square matrix with entries in {-1, 0, 1} where each row and column sums to 1 and nonzero entries alternate in sign; these are in bijection with six-vertex configurations with DWBC. "in bijection with alternating sign matrices"
- Arctic curves: The macroscopic boundaries separating frozen and disordered regions in random tilings or vertex models. "arctic curves of uniformly random reduced bumpless pipe dreams"
- Bruhat cover: The immediate covering relation in the Bruhat order on permutations, typically realized by swapping two entries with no intermediate values between them. "A permutation covers in Bruhat order if and only if"
- Bruhat order: A partial order on permutations defined by containment of inversion sets or, equivalently, by transitive closure of Bruhat covers. "in Bruhat order"
- Bumpless pipe dream (BPD): A tiling of an grid with six tile types encoding nonintersecting paths, equivalent to six-vertex configurations when reducedness is not enforced. "Bumpless pipe dreams are tilings of an square grid with six types of tiles"
- Cayley distance: The minimum number of transpositions needed to transform one permutation into another. "within Cayley distance~$4$"
- Cotransition formula: A recurrence relation (due to Knutson) that computes Schubert principal specializations by summing over certain Bruhat covers, increasing permutation length at each step. "The cotransition formula of Knutson"
- Coupling From The Past (CFTP): An exact sampling technique for Markov chains using monotone coupling to obtain perfectly coupled samples from the stationary distribution. "the standard monotone Coupling From The Past (CFTP)"
- Descent formula: A recurrence (due to Macdonald) expressing a Schubert principal specialization as a weighted sum over descents, decreasing permutation length at each step. "the descent formula of Macdonald"
- Distributive lattice: A lattice where meet and join distribute over each other; the ASM poset under the height-function order is an example. "ASMs form a distributive lattice"
- Domain wall boundary conditions: A specific boundary setup for the six-vertex model fixing orientations on the boundary edges. "with domain wall boundary conditions"
- Double Schubert polynomials: A two-parameter family depending on variable sets and that generalize Schubert polynomials. "to get double Schubert polynomials"
- Flag variety: The space of all complete flags in a vector space; its cohomology/homology is encoded by Schubert classes/polynomials. "flag varieties"
- Grothendieck polynomials: K-theoretic analogues of Schubert polynomials that enumerate (non-reduced) BPDs with weights; they admit related asymptotic questions. "analogous problem for Grothendieck polynomials"
- Height function: An integer-valued function on dual-lattice vertices whose level lines correspond to the paths in a six-vertex/BPD configuration and induce a partial order. "The height function "
- Homology: An algebraic-topological invariant; Schubert polynomials form a basis for the (co)homology of flag varieties. "the homology of flag varieties"
- Integrable probability: A field studying exactly solvable stochastic models using algebraic/combinatorial methods. "integrable probability techniques"
- Layered permutation: A permutation formed by concatenating consecutive decreasing blocks (layers), e.g., 32165487. "a layered permutation"
- Limit shape: The deterministic macroscopic profile emerging from a large random combinatorial model (e.g., RBPDs) under scaling limits. "limit shapes for the RBPD"
- Markov chain Monte Carlo (MCMC): A class of randomized algorithms that sample from complex distributions by simulating a Markov chain with the desired stationary distribution. "Markov chain Monte Carlo (MCMC)"
- Permuton: A probability measure on the unit square with uniform marginals describing scaling limits of permutations. "permuton-like asymptotic behavior"
- Principal specialization: Evaluation of a multivariate polynomial by setting all variables equal to 1; here . "principal specializations of the Schubert polynomials "
- Reduced bumpless pipe dream (RBPD): A bumpless pipe dream satisfying the reducedness constraint that any two pipes cross at most once. "reduced bumpless pipe dreams (RBPD)"
- Reduced pipe dream (RC-graph): A staircase-shaped tiling with crossing and elbow tiles where each pair of pipes crosses at most once; equivalent to RC-graphs. "reduced pipe dreams (also called RC-graphs)"
- Reducedness (reduced condition): The global constraint in pipe-dream models that each pair of pipes crosses at most once. "the reduced condition"
- Rothe BPD: The canonical RBPD obtained from a permutation by taking its Rothe diagram and interpreting deleted boxes as empty tiles with corresponding pipes. "called the Rothe BPD."
- Rothe diagram: A set of boxes associated to a permutation defined by positions strictly northwest of its permutation matrix dots. "The Rothe diagram of is"
- Schubert polynomials: A polynomial basis indexed by permutations representing Schubert classes; fundamental in algebraic combinatorics and geometry. "Schubert polynomials "
- Six-vertex (square ice) model: An exactly solvable lattice model with six allowed vertex types on the square grid; BPDs without reducedness correspond to its configurations. "six-vertex (square ice) model"
- Transition formula: A recurrence (due to Lascoux–Schützenberger, with refinements) relating Schubert evaluations for a permutation to those of nearby permutations via specific transpositions. "the transition formula of Lascoux--Sch\"utzenberger"
- TASEP (Totally Asymmetric Simple Exclusion Process): A paradigmatic interacting particle system used in integrable probability and asymptotic analyses. "coming from TASEP in~\cite{GrothendieckShenanigans2024}"
Collections
Sign up for free to add this paper to one or more collections.