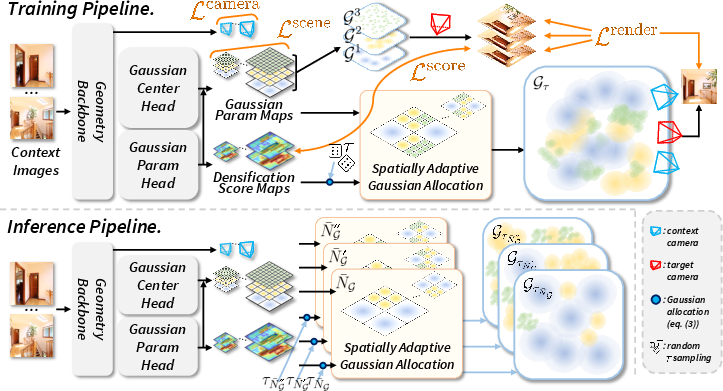
F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
Abstract: Feed-forward 3D Gaussian Splatting methods enable single-pass reconstruction and real-time rendering. However, they typically adopt rigid pixel-to-Gaussian or voxel-to-Gaussian pipelines that uniformly allocate Gaussians, leading to redundant Gaussians across views. Moreover, they lack an effective mechanism to control the total number of Gaussians while maintaining reconstruction fidelity. To address these limitations, we present F4Splat, which performs Feed-Forward predictive densification for Feed-Forward 3D Gaussian Splatting, introducing a densification-score-guided allocation strategy that adaptively distributes Gaussians according to spatial complexity and multi-view overlap. Our model predicts per-region densification scores to estimate the required Gaussian density and allows explicit control over the final Gaussian budget without retraining. This spatially adaptive allocation reduces redundancy in simple regions and minimizes duplicate Gaussians across overlapping views, producing compact yet high-quality 3D representations. Extensive experiments demonstrate that our model achieves superior novel-view synthesis performance compared to prior uncalibrated feed-forward methods, while using significantly fewer Gaussians.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper shows a faster, smarter way to rebuild a 3D scene from a few photos and then render it from new viewpoints in real time. It uses a technique called 3D Gaussian Splatting, which you can imagine as painting a 3D scene with lots of tiny, fuzzy dots (Gaussians). The new method, called F4Splat, learns where to place more dots in detailed parts of the scene and fewer dots in simple parts, so it can keep quality high while using fewer dots overall. It also lets you choose how many dots to use, like setting a “quality vs. speed” slider, without retraining the model.
What the researchers wanted to find out
- Can we quickly build a high-quality 3D model from a few photos, even when we don’t know the cameras’ exact settings?
- Can we decide how many dots (Gaussians) to use and spread them out smartly—more where the scene is complex, fewer where it’s simple?
- Can we avoid wasting dots by placing duplicates on the same parts of the scene seen by overlapping photos?
How the method works (in plain language)
First, a quick idea of 3D Gaussian Splatting:
- Think of the 3D scene as a cloud of tiny soft balls (Gaussians). When you “look” at the scene from a camera, these balls are “splatted” onto the image to create the picture you see. More balls in a tricky area (like leaves or flowers) can capture finer details; fewer balls are enough for flat, blank areas (like a blue sky).
What’s the problem with older fast methods?
- Many older “feed-forward” systems place dots uniformly—often one dot per image pixel or one dot per 3D grid cell. That’s simple but wasteful. You end up putting too many dots on plain walls and not enough on detailed areas. It also leads to duplicates when multiple photos cover the same spot.
The key idea in F4Splat:
- The model predicts a “densification score” map that says how many extra dots a region needs. High score → add more dots; low score → keep it light.
- It works across multiple scales, like viewing the scene in coarse chunks and then in finer grids. Using a simple threshold (a chosen score cut-off), the model picks which scale to use for each region, ensuring you don’t double-count spots across scales.
- You can set a target “budget” (the total number of dots you want). The system automatically adjusts the threshold to meet that budget while focusing dots where they help most.
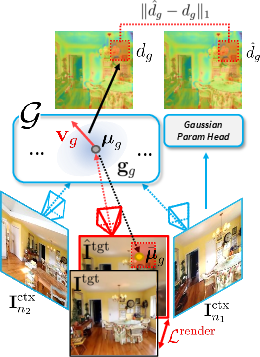
How does it learn these scores?
- During training, the model renders images and measures its mistakes. It looks at where adding or adjusting dots would have reduced the error most—basically, “where did I mess up the picture?” Those places get higher densification scores.
- Over time, the model learns to predict these scores directly from the input photos, so at test time it doesn’t need to compute mistakes first—it already knows where detail is needed.
Handling unknown cameras (uncalibrated):
- The system also learns to estimate the cameras’ positions and settings from the photos themselves. It aligns predicted camera views with the training data so the whole process is stable.
In short, the steps are:
- Read a few input photos (without known camera settings).
- Predict camera parameters, dot positions, dot colors, and, importantly, a densification score per region.
- Given your chosen dot budget, pick the right scale per region using the score and a threshold, placing more dots in complex areas and fewer in simple or overlapping areas.
- Render the scene from new viewpoints in real time.
Main results and why they matter
- Better quality with fewer dots: Compared to previous “uncalibrated” fast methods, F4Splat produces sharper, more accurate new views while using far fewer dots overall. In many tests it reached similar or better quality while using only about 10–30% of the dots others needed.
- Flexible “quality vs. speed” without retraining: You can change the dot budget on the fly, and the model redistributes dots intelligently. No need to train a new model for each setting.
- Works across datasets and view counts: It performs well both on the dataset it was trained on and on unseen data, and it handles different numbers of input photos (like 2, 8, 16, or 24).
- Fewer duplicates across views: Because it considers overlapping photos, it avoids placing multiple dots on the same spot, making the 3D model more compact.
Why this is important:
- Fewer dots mean faster rendering and less memory, which is great for real-time apps like AR/VR, robotics, and 3D mapping on devices with limited power.
What this could lead to
- Practical, real-time 3D capture from just a few photos on everyday devices, even when camera settings aren’t known.
- Adjustable quality settings for different needs: quick previews with smaller budgets, or detailed renders with larger budgets—all using the same model.
- A general idea—“learn to densify where it matters”—that could help other 3D methods become smarter and more efficient.
Overall, F4Splat shows that predicting where detail is needed lets you build compact 3D scenes that still look great, saving time and computation without sacrificing quality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper and could guide future research:
- Dataset and domain coverage
- Generalization beyond RE10K and ACID is untested (e.g., indoor scans like ScanNet, large-scale outdoor scenes like Tanks & Temples, varied lighting/materials, consumer smartphone data with noise/motion blur/exposure changes).
- Robustness to out-of-distribution content (textureless regions, repetitive patterns, transparent/reflective surfaces, extreme lighting) is not evaluated.
- Camera modeling and uncalibrated robustness
- Sensitivity to camera estimation errors (intrinsics/poses) is not analyzed; the approach assumes a pinhole model with focal-length adjustment but does not model lens distortion or rolling shutter.
- The Sim(3)-based alignment of target views relies on two nearest context views; stability under poor nearest-view selection, small baselines, or large baselines is unknown.
- No study of performance under degenerate configurations (narrow baselines, little parallax, or partial view overlap).
- Densification score design and supervision
- The densification score is supervised by rendering-loss gradients (AbsGS-inspired); its correlation with true fidelity gains across scenes/viewpoints is assumed rather than deeply validated.
- Alternative or complementary signals (e.g., uncertainty estimates, visibility/occlusion reasoning, geometry curvature, radiance/appearance gradients) are not explored.
- The score is trained with ground-truth novel views; self-supervised or weakly supervised training without GT novel views is not investigated.
- Thresholding, budget matching, and differentiability
- Allocation uses hard thresholding over multi-scale scores; non-differentiability may limit end-to-end optimization. Soft/continuous, differentiable budget-aware gating is not studied.
- The budget-matching algorithm is relegated to supplementary material; exactness guarantees are relaxed (only a small bound on mismatch per Eq. (4)), and the computational/robustness trade-offs are not analyzed.
- Sensitivity of reconstruction quality to the threshold τ and to the densification-score loss weight is not systematically studied.
- Multi-scale design choices
- The number of scales is fixed (L=3); the effect of more/fewer scales on control granularity, fidelity, and compute has not been examined.
- Behavior when user-specified budgets lie near or beyond the min/max Gaussian bounds is unclear (e.g., very low budgets or extremely high budgets approaching H×W per view).
- Cross-view redundancy handling
- Redundancy reduction across overlapping views is implicit via predicted scores; no explicit 3D clustering, cross-view non-maximum suppression, or merging/fusion is performed or evaluated.
- Sensitivity of redundancy avoidance to pose inaccuracies and view overlap patterns is not quantified.
- Geometry quality and evaluation metrics
- Evaluation focuses on image-space metrics (LPIPS/SSIM/PSNR); there is no evaluation of 3D geometry quality (depth error, completeness, normal consistency) or analysis of floaters/artifacts.
- The trade-off between compactness and geometric accuracy (e.g., surface quality, topology) remains unquantified.
- Runtime, scalability, and resource usage
- Inference/training runtime and memory footprints, and the end-to-end speedup from reduced Gaussian counts, are not reported.
- Scalability to large scenes with millions of Gaussians, streaming/tiling strategies, and memory management for multi-scale maps are not discussed.
- The compute cost of the geometry backbone (VGGT-based) and densification modules at inference is not detailed; mobile/edge deployment feasibility is unknown.
- Dynamic or time-varying scenes
- The method targets static scenes; extensions to dynamic content (temporal consistency, motion-aware densification, per-frame budget allocation) are not explored.
- Appearance modeling and materials
- Interaction between Gaussian counts and spherical harmonics order/appearance complexity is not analyzed; scenes with complex BRDFs (specular, glossy, translucent) are not systematically evaluated.
- Densification is derived from positional gradients; potential benefits of integrating color/opacity gradients or material-aware cues are untested.
- Robustness and failure modes
- Failure cases are not reported (e.g., very sparse views, severe occlusions, highly reflective/transparent environments, heavy noise).
- The reliance on scene-scale regularization for stability suggests potential fragility; its sensitivity and alternatives (e.g., scale priors, metric scale cues) are not assessed.
- Resolution and input variability
- Coupling between input image resolution, multi-scale map resolutions, and Gaussian counts is not analyzed; behavior under varying input resolutions or aspect ratios is unknown.
- Performance with single-view input and extremely sparse inputs (beyond the tested two-view setting) is not reported.
- Integration with (limited) test-time optimization
- Potential gains from combining feed-forward densification with a small, budget-aware iterative refinement (e.g., a few ADC steps) are not explored.
- Fairness and ablative attribution
- The contribution of the geometry backbone versus the proposed allocation strategy is not isolated via strong ablations (e.g., swapping backbones, training without the score module).
- Retraining baselines under identical backbones or training conditions to control for priors is limited; a broader fairness analysis is absent.
- Practical deployment considerations
- Real-world constraints (sensor noise, photometric calibration, exposure/color differences, motion blur) and preprocessing needs are not discussed.
- User-facing controls: mapping desired quality targets to budgets or τ (e.g., automatic budget selection to meet a target LPIPS/PSNR) is not provided.
These gaps suggest concrete next steps: evaluate on broader datasets and real captures; analyze runtime/memory; design differentiable budget allocation; incorporate uncertainty/visibility/geometry cues into the score; add explicit cross-view fusion; measure geometry quality; test robustness to camera/model errors and distortions; extend to dynamic scenes; and explore hybrid feed-forward + lightweight refinement.
Practical Applications
Overview
F4Splat introduces feed-forward, budget-controllable 3D Gaussian Splatting (3DGS) from sparse, uncalibrated images. Its key innovations—predictive densification via learned densification scores, spatially adaptive allocation across multi-scales, and explicit Gaussian-count control without retraining—enable compact, high-fidelity 3D reconstructions with real-time rendering. Below are actionable applications that leverage these findings across sectors, with feasibility notes.
Immediate Applications
The following can be deployed with current 3DGS toolchains and standard GPUs, leveraging F4Splat’s released methodology.
- Bold: Mobile AR scene capture with a “quality–speed” slider
- Sectors: Consumer AR/VR, Mobile software
- What: On-device or app-based 3D scene capture from a handful of photos; users choose a Gaussian budget to trade off quality vs. speed/battery.
- Tools/workflows: Mobile SDK integrating F4Splat inference + 3DGS viewer; budget slider in UI; offline processing for privacy.
- Assumptions/dependencies: Static scenes; sufficient view overlap; model weights ported to mobile accelerators; DINOv2/VGGT components adapted for on-device inference or small cloud calls.
- Bold: Real estate or hospitality—fast virtual tours from sparse photos
- Sectors: Real estate, Travel/hospitality marketing
- What: Generate compact, high-quality walkthroughs from agents’ phone images; budgets adjusted for page load and bandwidth.
- Tools/workflows: Web pipeline with server-side F4Splat → streamed 3DGS assets (LOD policies per device); CMS integration.
- Assumptions/dependencies: Interiors similar to RE10K domain; privacy/consent; glare/reflective surfaces may degrade quality.
- Bold: E-commerce product 3D showcases from minimal captures
- Sectors: Retail, Marketplaces
- What: Turn a small set of product photos into interactive 3D with budget-aware rendering to fit mobile web constraints.
- Tools/workflows: Photo booth → F4Splat API → embeddable viewer with adaptive Gaussian budgets per device/network.
- Assumptions/dependencies: Controlled lighting preferred; small complex textures benefit from densification but need adequate views.
- Bold: Game/VFX previsualization and location scouting
- Sectors: Media/VFX, Gaming
- What: Rapid environment blocking from set/location stills; adjustable budgets for previz vs. final reference.
- Tools/workflows: DCC plugins (Blender/Unreal/Unity) with F4Splat export/import; pipeline nodes to switch budget presets.
- Assumptions/dependencies: Static scenes; engine support for 3DGS viewers or conversion to meshes/point clouds if needed.
- Bold: Robotics/drone mapping—compact recon for limited compute
- Sectors: Robotics, Drones, Industrial inspection
- What: Create compact models from sparse snapshots for navigation/inspection, tuned to onboard compute or link budget.
- Tools/workflows: Edge module performing feed-forward reconstruction; adaptive budgets for energy or bandwidth constraints.
- Assumptions/dependencies: Primarily static scenes; reliable capture overlap; robustness to motion blur and exposure variations.
- Bold: Web 3D streaming with budget-adaptive level of detail (LOD)
- Sectors: Web platforms, Content delivery
- What: Dynamically reduce Gaussian count for low-bandwidth clients while preserving fine details in complex regions.
- Tools/workflows: CDN serving multiple budget variants or server-side thresholding; client device profiling to pick τ thresholds.
- Assumptions/dependencies: 3DGS rendering support in browser or via WebGPU; latency acceptable for server-side thresholding.
- Bold: Cultural heritage digitization in low-resource settings
- Sectors: Museums, Non-profits, Education
- What: Capture artifacts/sites with few images; minimal storage and compute via compact representations.
- Tools/workflows: Field kits with handheld cameras; offline F4Splat processing; archival with budget tiers.
- Assumptions/dependencies: Outdoor lighting variability; policy/permissions for site capture; bias to trained domains.
- Bold: Construction progress documentation from sparse captures
- Sectors: AEC (Architecture, Engineering, Construction)
- What: Periodic sparse photo capture → compact 3D for site review and reporting; budgets scaled for quick sharing.
- Tools/workflows: Site camera app; cloud job queue; integration with BIM viewers or 3DGS overlays.
- Assumptions/dependencies: Dynamic scenes may reduce fidelity; safety/privacy protocols for on-site imaging.
- Bold: Research baselines and ablation studies on adaptive allocation
- Sectors: Academia, R&D labs
- What: Use densification-score-guided allocation as a controllable baseline to study resource allocation vs. quality.
- Tools/workflows: Open-source training scripts; benchmarks on NVS metrics + Gaussian count; reproducible τ sweeps.
- Assumptions/dependencies: Access to training data (RE10K/ACID or equivalent); H200/A100 class compute for training; consumer GPUs suffice for inference.
- Bold: Cost-tiered 3D reconstruction APIs
- Sectors: Cloud services, Developer platforms
- What: Offer API endpoints where developers specify Gaussian budgets to meet cost/performance SLAs.
- Tools/workflows: Serverless functions for F4Splat inference; automatic thresholding for target counts; usage-based billing.
- Assumptions/dependencies: Monitoring of quality vs. budget; domain generalization; API security and content governance.
- Bold: Virtual backgrounds/telepresence backdrops from quick captures
- Sectors: Collaboration tools, Conferencing
- What: Users capture rooms with a few photos; compact 3D backdrops render in real time during calls.
- Tools/workflows: Desktop/mobile app plugin; budget presets based on CPU/GPU availability.
- Assumptions/dependencies: Static scenes; conference app integration; privacy controls.
Long-Term Applications
These require further research, engineering, or broader ecosystem support (e.g., standards, hardware).
- Bold: Real-time on-device AR glasses reconstruction with dynamic budgets
- Sectors: Wearables, AR
- What: Live 3D recon tuned to battery/thermals by adapting Gaussian counts on the fly.
- Dependencies: Efficient backbones on low-power NPUs; streaming 3DGS on MicroOLED displays; low-latency camera pipelines.
- Bold: Active capture guidance driven by densification scores
- Sectors: Consumer capture, Robotics
- What: Guide users/robots where to move next to reduce high-score (underrepresented) regions.
- Dependencies: Turning densification scores into capture policies; UX cues; real-time pose feedback.
- Bold: 3DGS-based SLAM with predictive densification
- Sectors: Robotics, Autonomous systems
- What: Integrate feed-forward densification into SLAM to allocate primitives online in complex/uncertain areas.
- Dependencies: Handling loop closures; dynamic scene modeling; joint optimization of geometry and tracking.
- Bold: Autonomous driving environment modeling from sparse camera rigs
- Sectors: Automotive
- What: Rapid recon for planning/simulation with budget aware quality along the route-of-interest.
- Dependencies: Robustness to motion, dynamic actors, lighting; regulatory validation; fleet-scale deployment.
- Bold: City/building-scale digital twins and XR streaming
- Sectors: Smart cities, AEC, XR
- What: Budget-aware streaming of large areas with densification focused on high-interest or complex zones.
- Dependencies: Hierarchical tiling, standards for 3DGS streaming, server-side orchestration and edge caching.
- Bold: Edge–cloud collaborative rendering with budget negotiation
- Sectors: Cloud gaming/XR, Networks
- What: Clients request scene segments at budgeted Gaussian counts based on bandwidth/latency.
- Dependencies: Protocols for budget signaling; adaptive transcoding; QoE metrics tied to Gaussian budgets.
- Bold: Medical/industrial endoscopy and borescope 3D recon
- Sectors: Healthcare, Manufacturing
- What: Reconstruct internal structures from sparse views with compact models for quick inspection.
- Dependencies: Domain adaptation to specular/low-light scenes; validation and regulatory approvals in healthcare.
- Bold: Forensics and security—scene recon from limited photos
- Sectors: Public safety, Insurance
- What: Build shareable, compact 3D reconstructions from sparse evidence photos.
- Dependencies: Chain-of-custody workflows; uncertainty quantification; legal admissibility.
- Bold: Generative 3D content pipelines with budget-aware densification
- Sectors: Media creation, Design tools
- What: Combine generative priors with predictive densification to synthesize compact 3D assets with controllable detail.
- Dependencies: Training on large multi-view datasets; integration with diffusion/NeRF-3DGS hybrids.
- Bold: Standards for 3DGS compression and streaming with “Gaussian budgets”
- Sectors: Standards bodies (e.g., MPEG), CDNs
- What: Define interoperable profiles for budget levels, rate control, and quality metrics (LPIPS/PSNR-bound).
- Dependencies: Industry consensus; objective metrics alignment; tooling for conformance tests.
- Bold: Low-carbon 3D content pipelines for ESG reporting
- Sectors: Enterprise IT, Sustainability
- What: Use compact 3DGS to reduce compute and bandwidth; report savings tied to Gaussian counts.
- Dependencies: Auditable energy models; policy alignment; integration with sustainability dashboards.
- Bold: Education—lab kits for learning resource-allocation in 3D vision
- Sectors: Academia
- What: Courses where students experiment with τ and budgets to study efficiency–quality trade-offs.
- Dependencies: Stable teaching datasets; simplified runtimes and visualization tools.
Cross-Cutting Assumptions and Dependencies
- Scene characteristics: Best suited to largely static scenes with adequate multi-view overlap; dynamic or highly reflective/translucent content may degrade recon quality.
- Domain generalization: Trained on RE10K/ACID; performance may drop on out-of-domain data (industrial, medical, outdoor extremes) without fine-tuning.
- Hardware/software: Real-time rendering requires a 3DGS rasterizer; training uses high-end GPUs, but inference is much lighter; mobile deployment may need model distillation/acceleration.
- Camera inputs: Uncalibrated inputs are supported, but reliable pose estimation from the backbone is assumed; extreme pose errors reduce quality.
- Privacy and IP: Easy 3D capture raises consent and ownership concerns for spaces and objects; compliance and on-device options recommended.
- Toolchain integration: Adoption is smoother where 3DGS viewers are available (or converters to meshes/point clouds exist); plugin development for DCC/game engines is beneficial.
- Quality controls: Threshold τ and budget matching must be tuned to application KPIs (LPIPS/PSNR/SSIM vs. latency/memory); automated policies advised.
By pairing feed-forward predictive densification with explicit Gaussian budget control, F4Splat enables deployable, resource-aware 3D reconstruction workflows today and lays groundwork for adaptive, large-scale 3D applications across devices and networks.
Glossary
- 3D Gaussian Splatting (3DGS): A 3D scene representation that models scenes as sets of Gaussian primitives and renders them efficiently. "3DGS represents scenes using an explicit set of 3D Gaussian primitives, enabling high-fidelity 3D reconstruction and real-time novel-view rendering."
- Adaptive Density Control (ADC): An optimization strategy that dynamically adds or removes Gaussians to better allocate model capacity across a scene. "It incorporates adaptive density control (ADC), which periodically adds or removes Gaussians during optimization."
- Budget-Matching Algorithm: A procedure to select Gaussians so the final count matches a user-specified target. "The budget-matching algorithm is provided in the supplementary materials."
- Camera Tokens: Learnable tokens representing camera information within a transformer-based backbone. "The resulting image tokens are concatenated with learnable camera tokens and register tokens ."
- Camera-to-World Pose: The transformation that maps camera coordinates to world coordinates. "is the camera-to-world pose."
- DINOv2: A pretrained vision transformer used for feature extraction from images. "Each input image is processed by a pretrained DINOv2 encoder"
- Differentiable Rasterization: A rendering approach where rasterization is made differentiable to enable gradient-based optimization. "rendering them through differentiable rasterization, enabling real-time rendering and faster optimization."
- DPT-based Decoder: A decoder architecture (based on Dense Prediction Transformer) used to produce multi-scale maps for Gaussians and scores. "We modify a DPT-based decoder"
- Feed-Forward 3DGS: A paradigm where 3D Gaussian representations are predicted in a single forward pass without per-scene optimization. "Feed-forward 3D Gaussian Splatting methods enable single-pass reconstruction and real-time rendering."
- Feed-Forward Predictive Densification: Learning to predict where and how densely to place Gaussians in a single pass, rather than iteratively. "which performs Feed-Forward predictive densification for Feed-Forward 3D Gaussian Splatting"
- Gaussian Budget: A user-specified target for the total number of Gaussians to allocate in the scene representation. "under different target Gaussian budgets."
- Gaussian Primitive: A basic element of the 3DGS representation characterized by position, shape, appearance, and opacity. "3DGS represents scenes using an explicit set of 3D Gaussian primitives"
- Homodirectional View-Space Positional Gradient: A gradient signal (in image coordinates) indicating how moving a Gaussian affects rendering loss, used to guide densification. "homodirectional target view-space positional gradient of the Gaussian"
- Indicator Function: A function that outputs 1 if a condition is met and 0 otherwise, used in allocation masks. "is an indicator function that outputs $1$ when the condition is satisfied"
- Intrinsic Matrix: The camera matrix containing focal lengths and principal point parameters. "is the intrinsic matrix"
- LPIPS: A perceptual similarity metric used to evaluate image quality by comparing deep features. "We evaluate the performance of novel view synthesis using three standard metrics: LPIPS, SSIM, and PSNR."
- Multi-View Overlap: Regions observed by multiple input views where redundant Gaussians can occur if not handled. "according to spatial complexity and multi-view overlap."
- Nearest-Neighbor Upsampling: A simple upsampling method used to expand masks across scales without interpolation. "denotes the nearest-neighbor upsampling with a scaling factor of "
- NeRF: A neural rendering method that represents scenes with a volumetric MLP and renders via volumetric integration. "NeRF established a dominant paradigm for neural scene representation"
- Novel View Synthesis: Rendering new views of a scene from unobserved camera positions. "We evaluate the performance of novel view synthesis using three standard metrics: LPIPS, SSIM, and PSNR."
- Pixel-to-Gaussian Pipeline: A mapping that assigns one Gaussian per image pixel, fixing the Gaussian count to image resolution. "Most works~... adopt a pixel-to-Gaussian pipeline, which assigns Gaussians at the pixel level."
- Pose-Free Setting: A setup where camera poses are not provided but some intrinsic calibration may be known or estimated. "Recent works~... relax this assumption by moving to pose-free settings."
- PSNR: Peak Signal-to-Noise Ratio, an image quality metric measuring reconstruction fidelity. "We evaluate the performance of novel view synthesis using three standard metrics: LPIPS, SSIM, and PSNR."
- Quaternion: A four-parameter representation for 3D rotation used to orient Gaussian primitives. "rotation in quaternion"
- Register Tokens: Learnable tokens used to coordinate or register information across views in the transformer backbone. "The resulting image tokens are concatenated with learnable camera tokens and register tokens ."
- RGB Shortcut: A direct connection that injects RGB information into the decoder to aid parameter prediction. "an RGB shortcut~\cite{ye2024nopo} is utilized before the level-specific layers."
- Scene-Scale Regularization: A loss that normalizes the average scene scale to stabilize training in uncalibrated settings. "We further introduce a scene-scale regularization loss $\mathcal{L}^{\text{scene}$"
- Similarity Transformation (Sim(3)): A transformation including rotation, translation, and uniform scaling used to align coordinate frames. "We estimate a similarity transformation matrix "
- Spherical Harmonics (SH): A basis for representing view-dependent color on the surface of a sphere for each Gaussian. "and spherical harmonics (SH) ${\mathbf{h}_g \in \mathbb{R}^\nu$."
- SSIM: Structural Similarity Index, an image metric assessing structural fidelity. "We evaluate the performance of novel view synthesis using three standard metrics: LPIPS, SSIM, and PSNR."
- Uncalibrated Setting: A scenario where neither camera poses nor intrinsics are provided at test time. "uncalibrated methods that take only images as input without camera poses or intrinsics"
- VGGT: A transformer-based geometric backbone architecture used for camera and geometry estimation. "we adopt a geometric backbone following the structure of VGGT"
- Voxel-to-Gaussian Pipeline: A mapping that assigns one Gaussian per voxel, allowing count control by voxel size but often uniformly in space. "AnySplat~... employs a voxel-to-Gaussian pipeline"
Collections
Sign up for free to add this paper to one or more collections.