- The paper introduces a formal framework for computational arbitrage by optimizing inference budget allocation across heterogeneous AI models.
- Empirical analysis on software issue resolution shows that cascaded querying achieves up to 40% profit margins and significant cost reductions.
- The study highlights how distillation amplifies arbitrage potential, disrupting provider revenues and generalizing to domains like theorem proving.
Computational Arbitrage and Market Efficiency in AI Model Markets
This work introduces a rigorous framework for computational arbitrage in AI model marketplaces where multiple providers with heterogeneous models—differing in cost and performance—compete to solve verifiable tasks under consumer-defined budgets. The core contribution is the formalization of arbitrage as the process by which a market participant sources model generations from a cascade of providers, optimizing the allocation of inference budget to undercut prevailing market prices for a target utility level, without incurring model development risk.
Given a set of providers offering model APIs, each described by a cost–performance tradeoff curve Cp(u) for performance level u under query distribution D, the arbitrageur defines a policy q which constructs a cascade—allocating a portion of the budget to each provider sequentially and stopping at the first provider producing a verifiable solution. Arbitrage is realized when Cq(u)<CP(u), capturing the profit margin Πq(u)=CP(u)−Cq(u). Notably, the strategy is risk-free in expectation and entails no up-front investment—paralleling classical arbitrage in financial systems.
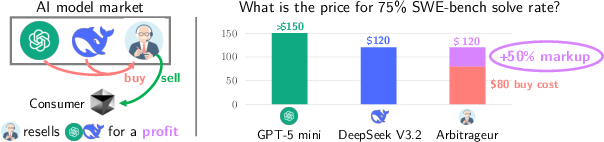
Figure 1: Illustration of a three-entity model market, highlighting the structural opportunity for arbitrage via cost-effective cascading between GPT-5 mini and DeepSeek v3.2 to achieve a SWE-bench solve rate at a substantially reduced cost.
Empirical Case Study: Software Issue Resolution
The primary empirical investigation is carried out on the SWE-bench Verified benchmark, wherein models are tasked with automated GitHub issue resolution—an application with robust automatic verification. The study focuses on GPT-5 mini and DeepSeek v3.2, both advanced code models with distinct pricing and performance profiles. Through repeated sampling, per-query inference budgets are dynamically allocated. The optimal arbitrage policy is a cascade: GPT-5 mini is queried up to a cost cap of \$0.08 per issue for easier problems, escalating to DeepSeek for more challenging instances within an overall cap of \$1.
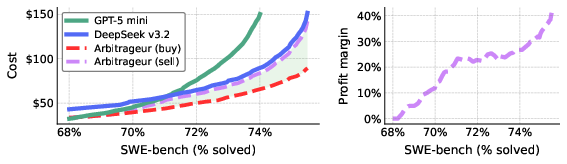
Figure 2: Cost-performance frontier on SWE-bench, demonstrating that arbitrageurs (red curve) achieve substantial cost reductions for solve rates above 68%, outperforming either model individually.
The cascade enables the arbitrageur to source outputs for a given performance level (e.g., 75% solve rate) at \$80, compared to \$150 and \$120 for GPT-5 mini and DeepSeek alone. This translates to up to 40% net profit margins, and these arbitrage policies are straightforward to optimize and implement.
Market Dynamics: Competition, Segmentation, and Provider Revenues
In markets where multiple arbitrageurs operate, classic Bertrand competition manifests: arbitrageurs iteratively undercut each other's prices, driving market prices down to their marginal cost and annihilating profit opportunities. This endgame is substantiated in simulation (Figure 3), confirming theoretical microeconomic predictions.
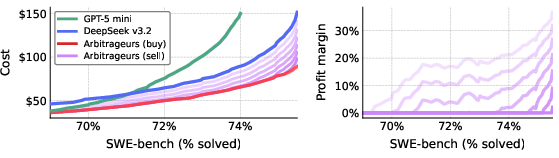
Figure 3: Competitive dynamics between two arbitrageurs, leading to price competition and eventual dissipation of arbitrage-derived profits.
Crucially, arbitrage eliminates market segmentation by redistributing demand: where markets were previously partitioned by performance (one provider serving each segment), arbitrage enables both cost- and performance-efficient models to monetize across all tiers. Providers’ marginal revenues are sharply reduced, with the lost surplus shifting to arbitrageur profits or being passed directly to consumers via lower prices (Figure 4). Importantly, smaller, cheaper models can earn revenue at the performance frontier due to their cost advantage in cascaded configurations.
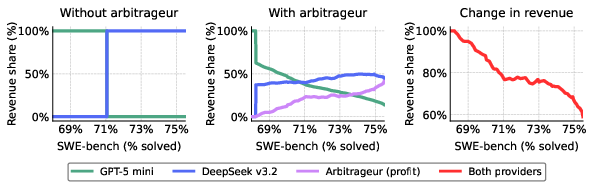
Figure 4: Market segmentation and revenue redistribution—arbitrageurs flatten segmentation, spreading revenue across providers while reducing overall provider margins.
Robustness, Scalability, and Multi-Model Markets
The practical viability of arbitrage is examined regarding search costs (for learning appropriate policies) and robustness to query distribution shifts. Extremely modest investments (as low as \$10 in search queries) suffice to fit arbitrage policies that remain profitable even under non-stationary query distributions (Figure 5).
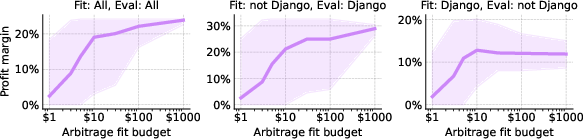
Figure 5: Profitability of arbitrage as a function of search budget and robustness to shifts in the query distribution.
The framework generalizes to larger model markets. With the addition of four competitive providers, the prevalence and profitability of arbitrage expand: arbitrage opportunities emerge for solve rates as low as 42%, with profit margins up to 58% (Figure 6). Market segmentation fades, and revenues are more broadly shared among participating providers meeting niche cost-performance regimes.
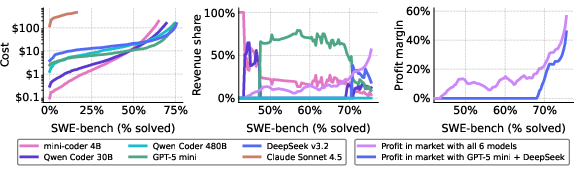
Figure 6: Arbitrage opportunities proliferate in a six-provider market, yielding higher profits and a more uniform revenue distribution among competitive providers.
Distillation as a Catalyst for Arbitrage
Distillation is shown to directly amplify arbitrage potential by lowering inference costs for student models without entirely matching teacher performance. Empirically, scaling the distillation dataset for Qwen 3 1.7B models improves cost-performance monotonically, with profitability in arbitrage increasing log-linearly with distillation size. Students Pareto-dominate teachers for pass@k at lower inference budgets.
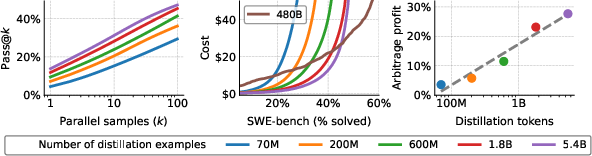
Figure 7: Effect of distillation scale—more data leads to student models enabling greater arbitrage profitability when paired with a teacher.
Increasing student model size (e.g., mini-coder 4B) further crowds out the teacher from the arbitrage cascade. In a three-way market (mini-coder 4B, Qwen Coder 30B, GPT-5 mini), the student model essentially cannibalizes nearly all of the teacher’s revenue at relevant market segments, demonstrating distillation’s disruptive economic effect (Figure 8).
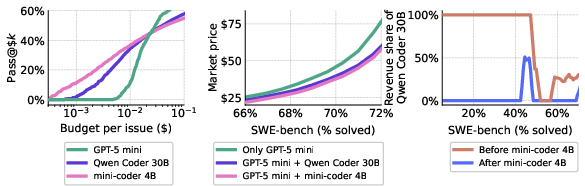
Figure 8: Entry of a well-distilled, efficient student model decimates the teacher’s revenue share in the arbitrage-driven market.
Extension to Theorem Proving and Generalization
The arbitrage paradigm is validated in formal mathematics, using Lean 4 theorem proving on MiniF2F and NuminaMath-LEAN. Cascaded policies over the Kimina Prover family yield over 60% profit margin (Figure 9), and distillation experiments confirm that scaling the number of synthetic training trajectories for a student model robustly increases arbitrage profitability (Figure 10).
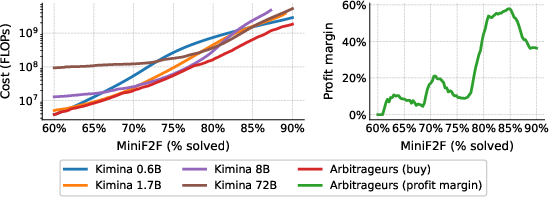
Figure 9: Arbitrage in formal theorem proving market—arbitrageur achieves markedly higher profit margins by recombining model inference budgets.
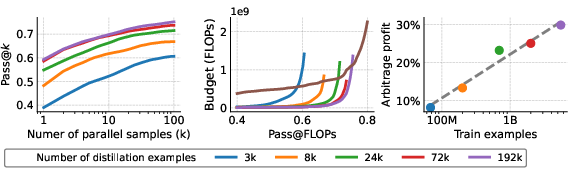
Figure 10: Scaling distillation for Lean theorem proving transfers to increased arbitrage profit, confirming generalizability beyond code generation.
Implications and Directions
The study establishes that computational arbitrage is an inherent feature of fragmented AI model markets for verifiable tasks. Arbitrage increases market efficiency by compressing cost–performance spreads, lowers consumer prices, and enables smaller models to monetize by virtue of their efficiency—even when they do not lead on headline metrics. However, it also reduces incumbent providers’ revenue and may incentivize further model disintermediation via distillation or strategic gating.
The economic consequences are substantial:
- Distillation produces arbitrage, eroding teacher model revenues and intensifying competition at both the infrastructure and ecosystem layers.
- Widespread arbitrage drives prices to marginal cost, with efficiency and consumer benefit at the expense of model provider margins.
- Verification, model interface standardization, and information symmetry are prerequisites for arbitrage-based efficiency gains.
- The potential emergence of oligopolistic intermediaries (arbitrageurs) and increased provider concentration if market information is costly or verification imperfect.
Conclusion
This work provides a robust formal and empirical analysis of computational arbitrage in AI model markets. The findings delineate both the disruptive and stabilizing economic forces at play, highlight arbitrage as a mechanism for reducing segmentation and enabling competition, and expose the interplay with distillation and model scaling. These results set a foundation for further investigation into pricing, market structure, and the impact of arbitrage on the future development and deployment of AI systems.
(2603.22404)