How are AI agents used? Evidence from 177,000 MCP tools
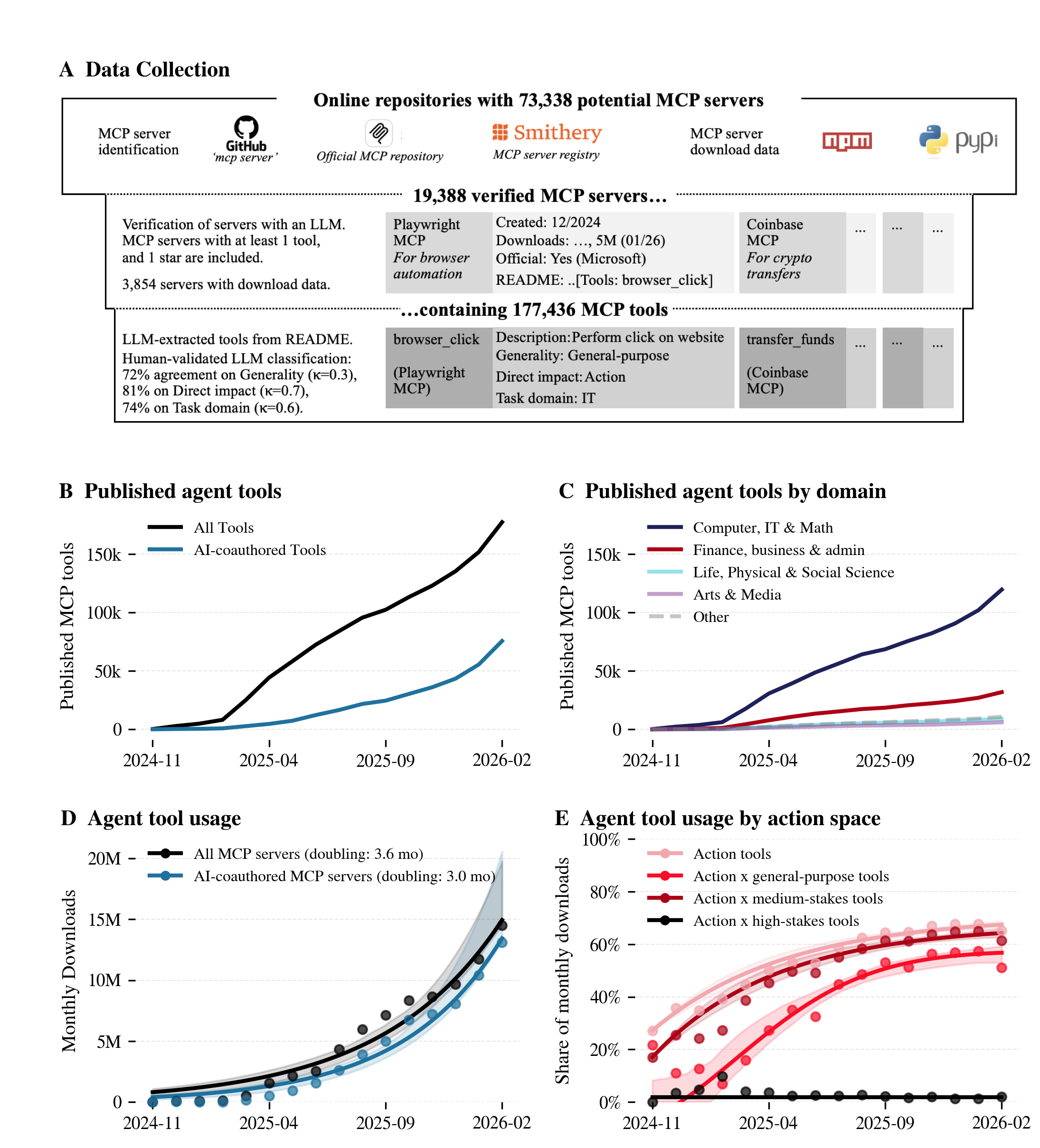
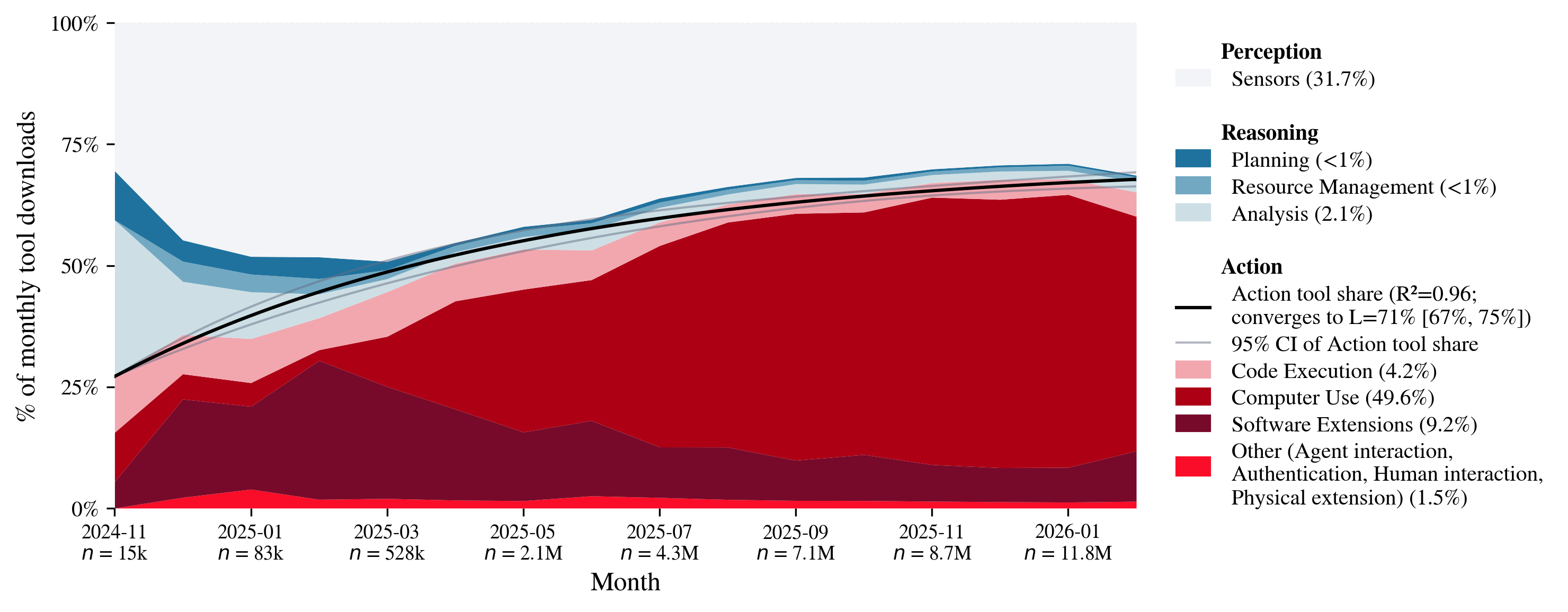
Abstract: Today's AI agents are built on LLMs equipped with tools to access and modify external environments, such as corporate file systems, API-accessible platforms and websites. AI agents offer the promise of automating computer-based tasks across the economy. However, developers, researchers and governments lack an understanding of how AI agents are currently being used, and for what kinds of (consequential) tasks. To address this gap, we evaluated 177,436 agent tools created from 11/2024 to 02/2026 by monitoring public Model Context Protocol (MCP) server repositories, the current predominant standard for agent tools. We categorise tools according to their direct impact: perception tools to access and read data, reasoning tools to analyse data or concepts, and action tools to directly modify external environments, like file editing, sending emails or steering drones in the physical world. We use O*NET mapping to identify each tool's task domain and consequentiality. Software development accounts for 67% of all agent tools, and 90% of MCP server downloads. Notably, the share of 'action' tools rose from 27% to 65% of total usage over the 16-month period sampled. While most action tools support medium-stakes tasks like editing files, there are action tools for higher-stakes tasks like financial transactions. Using agentic financial transactions as an example, we demonstrate how governments and regulators can use this monitoring method to extend oversight beyond model outputs to the tool layer to monitor risks of agent deployment.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in a nutshell)
This paper looks at how today’s “AI agents” are being used in the real world. An AI agent is like a smart helper built on top of a chatbot that can not only talk, but also use tools to read data, browse the web, edit files, send emails, or even move money. The authors studied 177,000+ of these tools to see what jobs they do, how often people install them, and how risky their actions might be.
The big questions the paper asks
- How are AI agents being used across different kinds of work (like coding, finance, admin)?
- Where in the world are these tools being used most?
- Are agents mostly “looking” at information, “thinking,” or actually “doing” things?
- Are agents working in tightly limited spaces (like one specific website) or broad, open spaces (like controlling a full web browser or a computer)?
- How much are AI agents themselves helping to build new tools for other AI agents?
How the researchers studied this (explained simply)
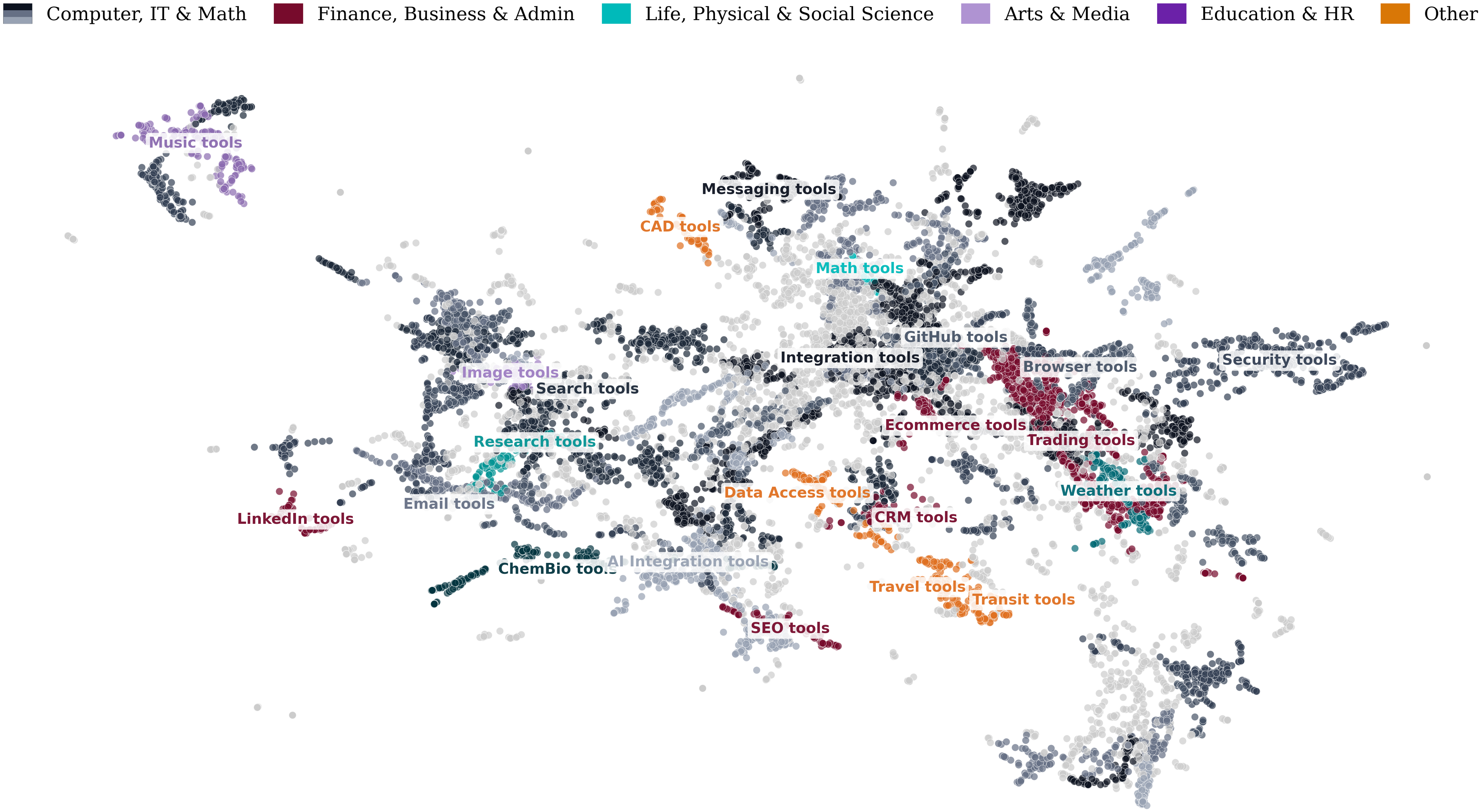
Think of AI tools like apps or plugins that an AI agent can use. Many of these tools follow a standard called MCP (Model Context Protocol), and they’re shared publicly in places like GitHub and package stores (PyPI for Python and NPM for JavaScript).
Here’s what the researchers did:
- Collected tools: They found 19,000+ MCP “servers” (packages that contain tools) and identified 177,436 distinct tools published between Nov 2024 and Feb 2026.
- Sorted tools by what they let agents do:
- Perception: “See” or read data (like searching or loading files)
- Reasoning: Analyze or transform data (like summarizing or checking logic)
- Action: Make changes in the world (like editing files, sending emails, or moving money)
- Checked how general each tool is:
- Narrow/constrained tools are like a key that opens one door (e.g., “send a payment on this one website”).
- General/unconstrained tools are like a master key (e.g., “control a web browser” or “click around a computer”).
- Mapped tools to job tasks: They used O*NET (a big database of jobs and what people do in them) to label each tool’s “task domain” (e.g., software, finance, admin) and estimate how “high-stakes” a tool’s actions could be (how big the impact of decisions usually is in that kind of job).
- Measured popularity: For 3,854 servers (containing ~42,500 tools), they tallied monthly downloads from PyPI and NPM. A download is like an installation—good for measuring interest, but it doesn’t guarantee the tool was actually used afterward.
- Looked at geography: For a subset of Python packages, they used IP-based download data to see which countries were installing the tools.
- Checked who wrote the tools: They looked for signs that AI coding assistants helped write the server (AI co-authorship).
Note: Downloads measure installation, not actual tool calls. Also, public registries skew toward developer tools, so results show trends, not exact real-world counts.
What they found (and why it matters)
- Software development dominates right now
- About 67% of all tools—and about 90% of installations—are for coding and IT tasks.
- Why it matters: Agents are already very active in programming tasks, which can speed up software work—but it also opens the door for coding mistakes at scale if not supervised.
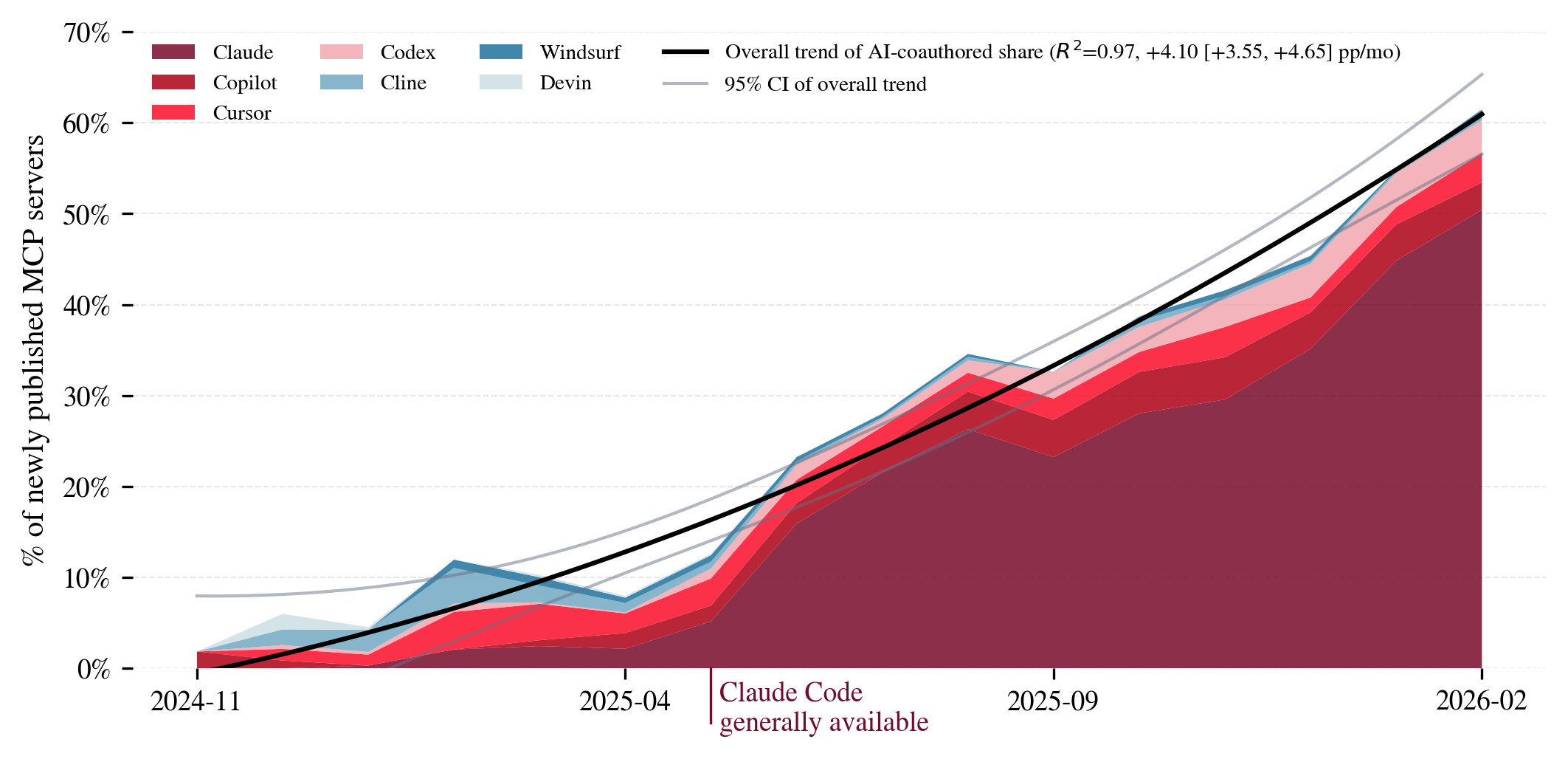
- More agents are taking direct actions—not just reading or thinking
- The share of “action” tools in use grew from 27% to 65% over 16 months.
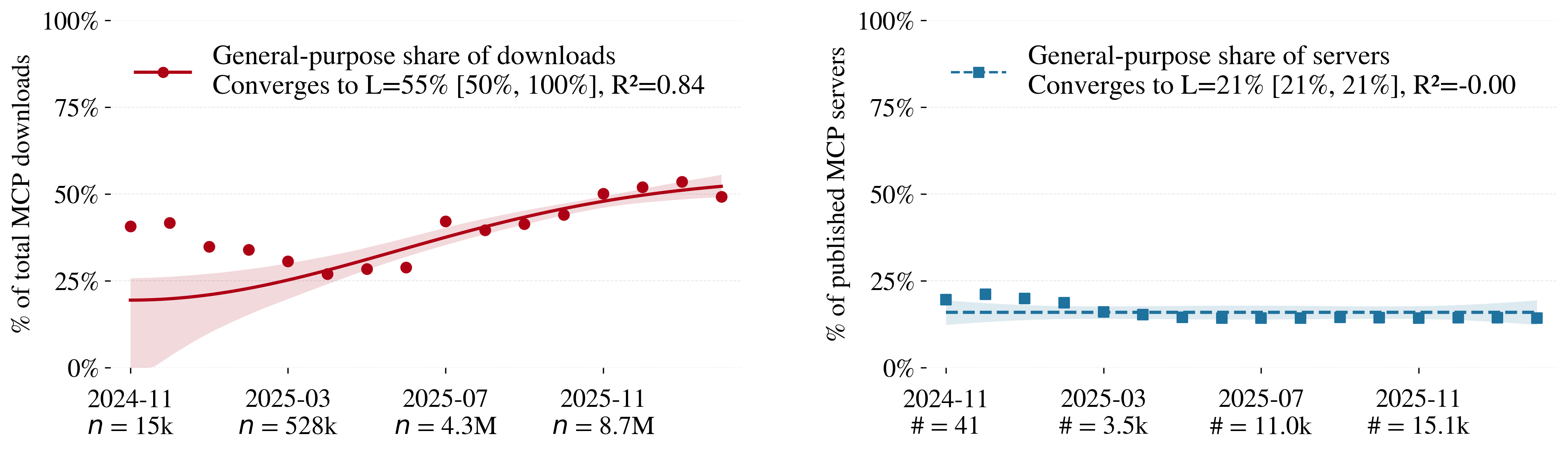
- General-purpose tools (like “control a browser” or “use a computer mouse”) are growing fast.
- Why it matters: When agents can act, not just advise, they can help more—but they can also make bigger mistakes or be misused if something goes wrong.
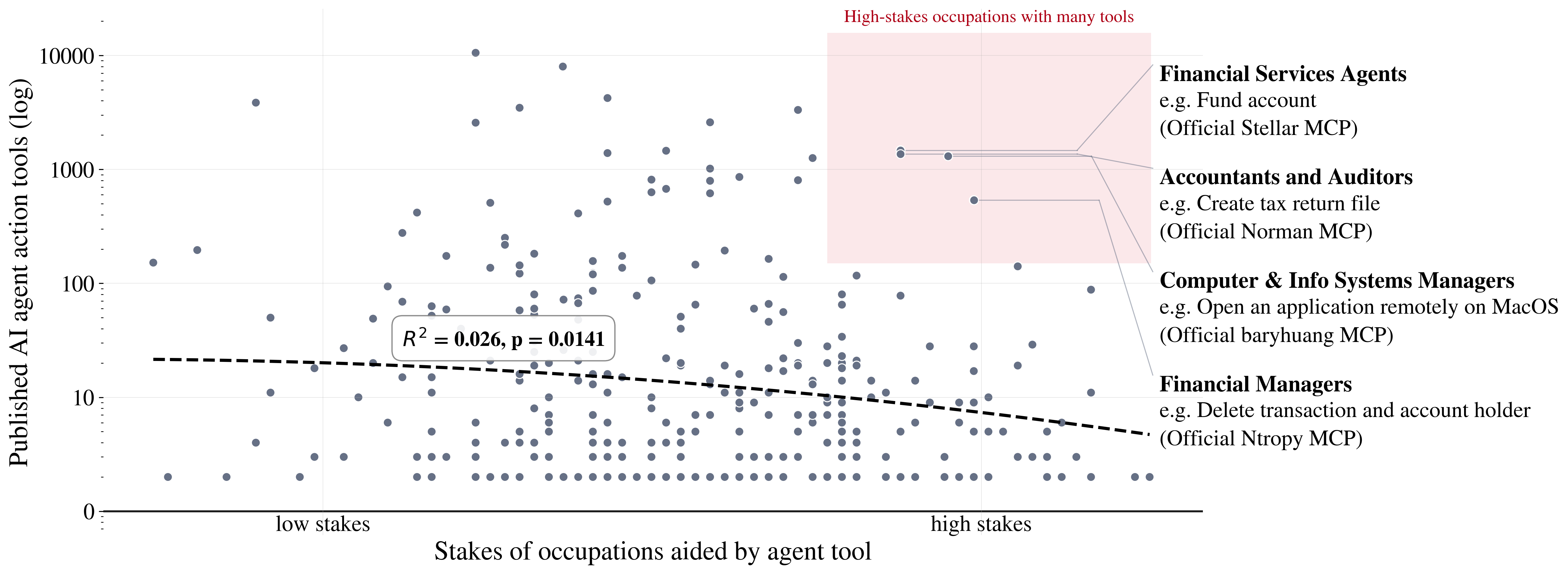
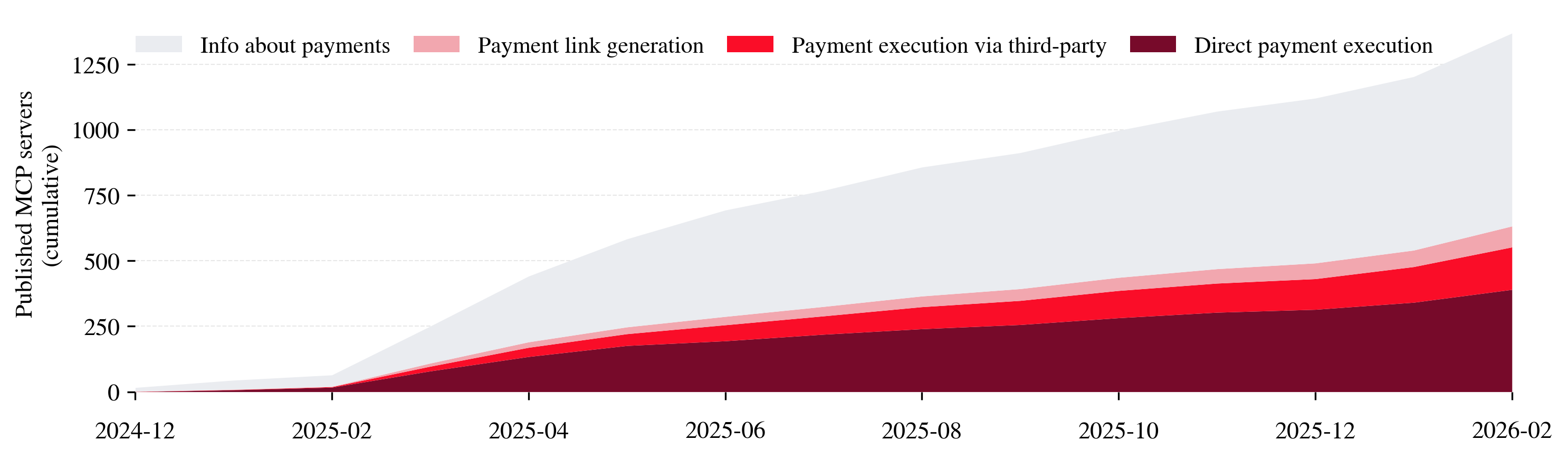
- Most action tools are medium-stakes, but some are high-stakes—especially in finance
- Many action tools handle tasks like editing files (medium-stakes).
- A growing group of tools can move money or execute trades (higher-stakes).
- Why it matters: Transactions and similar actions can have immediate, irreversible consequences. That raises the need for careful monitoring and controls.
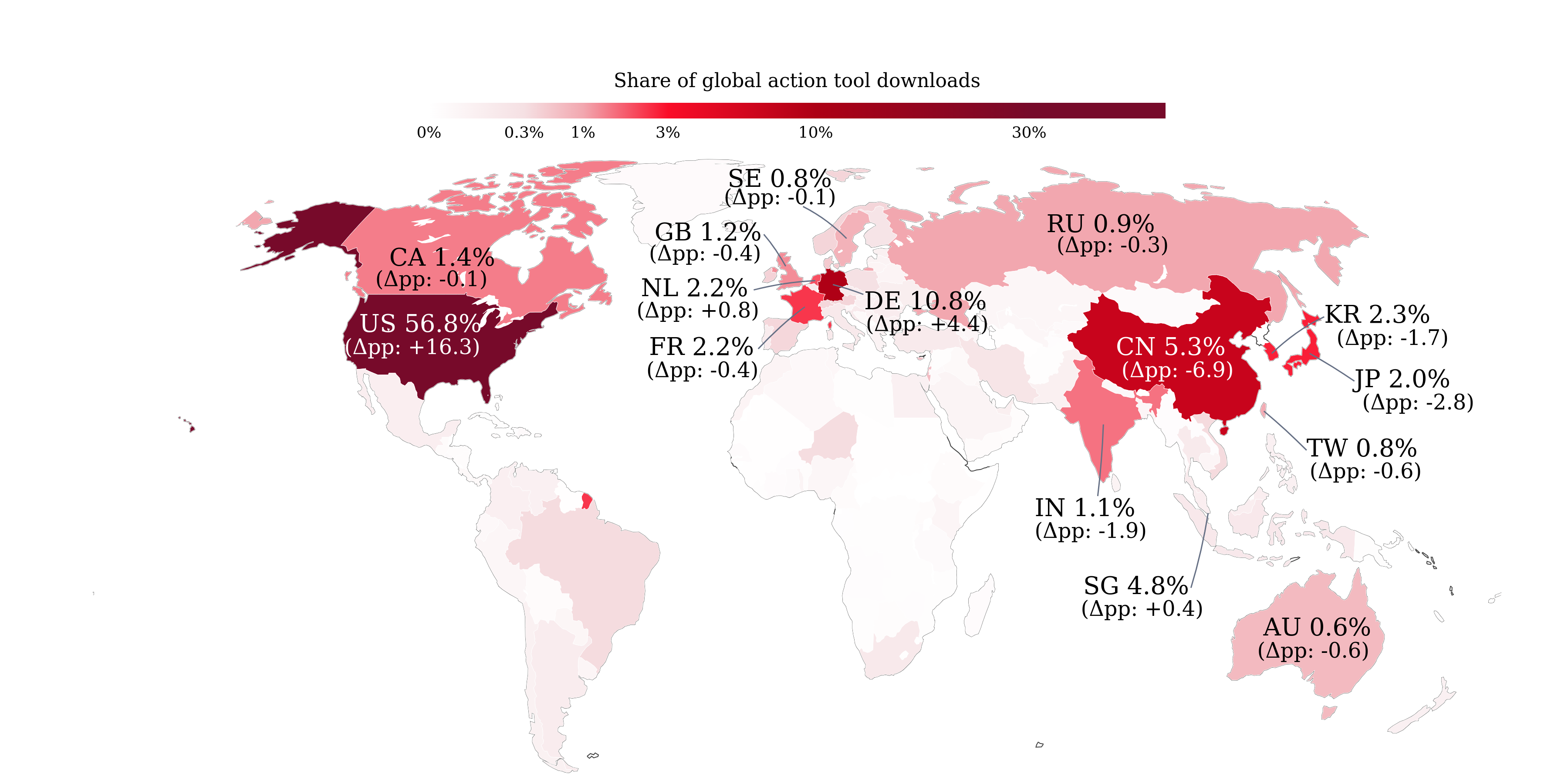
- Where these tools are used
- About half of observed installations (on the Python side) come from the United States, ~20% from Western Europe, and ~5% from China (for the period with available data).
- Why it matters: Adoption starts where developer ecosystems are strongest. This hints at where agent-driven changes to work might appear first.
- AI is helping build more of these tools
- The researchers found signs of AI assistance in 28% of servers (36% of tools).
- Among new servers, AI co-authorship grew from 6% (Jan 2025) to 62% (Feb 2026), with Claude Code as the main helper mentioned.
- Why it matters: If AI can rapidly build tools for other AIs, the number of agent capabilities can grow very fast, making oversight harder.
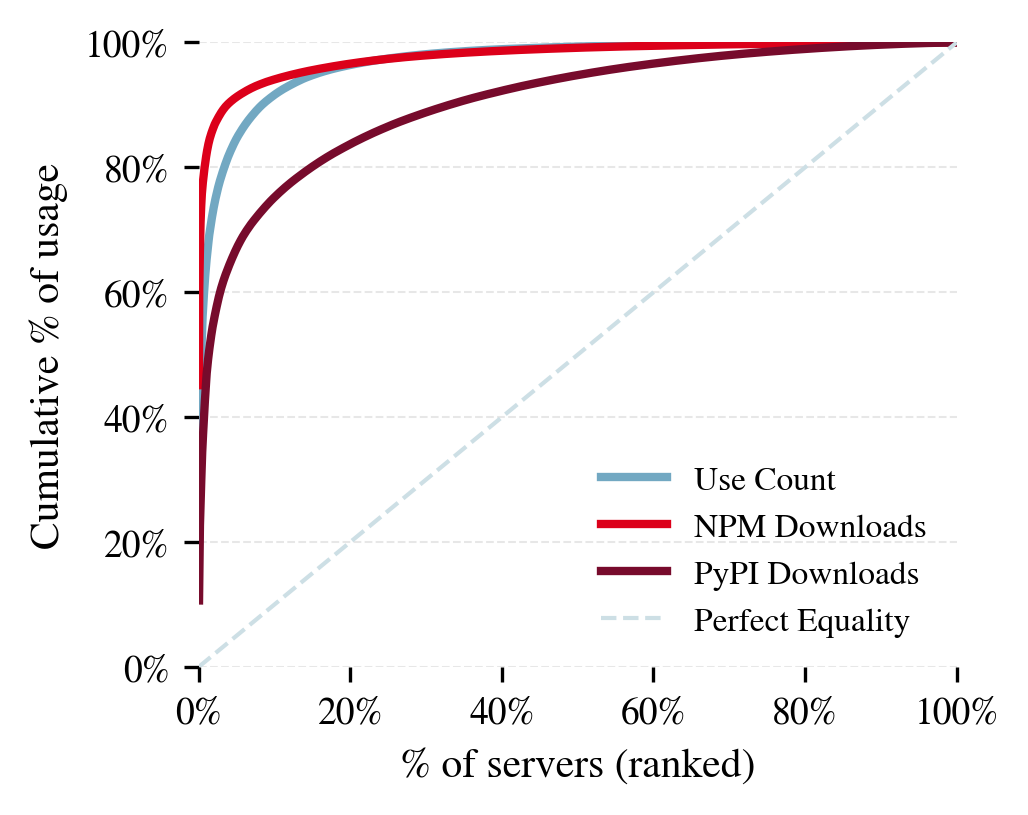
- Official tools are fewer but very popular
- “Official” servers (from companies like Google, PayPal, or GitHub) make up a small fraction of tools but a large share of downloads.
- Why it matters: When big providers ship tools, many users install them—these tools can quickly shape what agents do at scale.
Why this is important beyond the numbers
- Bigger “action space”: The more agents can do (especially with general-purpose action tools), the more helpful they can be—but also the larger the risk if something is misused or misconfigured.
- Real risks to watch:
- Misuse (e.g., cyberattacks or fraud if agents can send money or emails)
- Mistakes and misalignment (e.g., deleting a database, sending the wrong transaction)
- Structural risks (e.g., many agents doing the same thing at once, which could strain systems or create cascades, like “agent bank runs”)
- Early-warning system: Tracking public tool releases and downloads can give governments and companies a heads-up on what kinds of agent actions are about to become common. The paper shows a concrete example: monitoring agent-powered financial transactions to help regulators prepare.
Simple takeaway
AI agents are quickly moving from “smart chat” to “smart action.” Most of their tools today help with coding, but tools that let agents act—especially in broad, open environments—are spreading fast. A growing number of tools touch higher-stakes areas like finance. And AI is increasingly helping to build the very tools agents use. Watching these tools closely is a practical way for developers, companies, and regulators to understand where agent powers—and risks—are heading, and to put sensible guardrails in place before problems scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances understanding of MCP-based agent tools, but it also leaves several concrete gaps and questions for future work:
- Representativeness of MCP: Quantify how representative MCP tools are relative to the broader agent tool ecosystem (e.g., OpenAI Actions, Google AI Studio, vendor-specific connectors, LangChain/AutoGen tool abstractions, proprietary enterprise connectors), and assess whether findings generalize beyond MCP.
- Coverage of private/enterprise deployments: Measure the prevalence and characteristics of agent tools used in private registries, internal enterprise catalogs, and hosted environments that do not appear on GitHub/Smithery, and compare their action/impact profiles to public MCP tools.
- Runtime execution vs. downloads: Replace or validate download counts (PyPI/NPM) with actual runtime tool-call telemetry (e.g., invocation counts, success/failure rates, call chains) to more accurately characterize real-world agent actions.
- CI/mirroring inflation in downloads: Disentangle human-driven installations from automated CI/CD, mirrors, or dependency-driven downloads to reduce bias in usage proxies.
- NPM geography blind spot: Address the absence of geographic splits for NPM (and for the PyPI period after Oct 2025) to avoid US/EU skew in the geographic usage conclusions.
- Cloud-region vs. user-location bias: Correct for the fact that IP-based geolocation of downloads may reflect cloud build regions rather than end-user or deployment geographies.
- Temporal granularity and versioning: Track longitudinal changes of individual servers (versions, added/removed tools, permissions changes) rather than snapshotting two dates, to capture dynamics of capability hardening or expansion.
- Dominance of a few packages: Test whether trends (e.g., action tools rising from 27% to 65% of usage) are driven by a small number of highly popular general-purpose tools (e.g., browser or desktop-control MCPs) via sensitivity analyses.
- Tool-call context and chaining: Observe multi-step tool chains and cross-tool compositions (e.g., browse → extract → trade) to better assess real action spaces and sequence-level stakes.
- Autonomy and goal complexity in the wild: Develop and apply observable proxies for agent autonomy (e.g., default permissions, max steps before human approval, retry limits) and goal complexity (e.g., planning depth, memory use) in deployed agents, not just tool availability.
- Guardrails and permission models: Measure the prevalence and effectiveness of runtime guardrails (e.g., consent prompts, scopes, sandboxing, rate limits, test vs. production modes) that mediate risks of action tools.
- Generality classification fidelity: Refine the “constrained vs. unconstrained environment” classification to account for partial capabilities (read-only vs. write, limited domain-specific actions, sandboxed code execution), and validate against runtime behaviors.
- Action/perception/reasoning ambiguity: Address multi-functional tools (e.g., browser tools that read and click) with a principled multi-label or hierarchical impact taxonomy and assess how ambiguities affect aggregate trends.
- O*NET task/occupation mapping limits: Evaluate how well O*NET captures novel or rapidly evolving domains (e.g., DeFi protocols, LLM ops, drone/robotics orchestration), and extend the taxonomy or create a supplemental mapping for emerging agent tasks.
- Consequentiality proxy validity: Validate the use of occupation-level “impact of decisions” scores as a proxy for tool-level stakes, given that many tools operate under scoped permissions or in staging environments where consequences differ.
- High-stakes identification precision: Develop task-specific criteria for “high-stakes” (e.g., irreversible transfers, privileged access changes, safety-critical configurations) instead of relying solely on occupation-level stakes.
- Incident linkage: Link tool usage to observed incidents (misuse, misalignment, security failures) to test whether growth in specific tool classes correlates with real-world harm.
- Sector/critical-entity exposure: Identify the types of organizations (e.g., banks, hospitals, critical infrastructure) adopting action tools and quantify their exposure to correlated failures or systemic risks.
- Structural/cascading risk measurement: Move beyond qualitative risk narratives to measurable indicators of systemic coupling (e.g., concentration of dependencies on few LLMs/tools, synchronized agent actions, cross-institutional correlations).
- Non-English/China ecosystems: Expand data collection to Chinese-language platforms and non-Western registries to avoid Western platform bias and to understand global differences in tool types and stakes.
- AI co-authorship detection robustness: Detail and validate the AI-assistance detection methodology (e.g., commit metadata, code style analysis, tool-generated files), quantify false positives/negatives, and assess shifts in disclosure practices over time.
- Timing bias in AI authorship: Correct for assigning downloads to “AI-coauthored” only after first detected evidence, which may undercount earlier AI assistance and bias growth estimates.
- Duplicate and derivative tools: Detect and account for forks, wrappers, and duplicates to prevent multiple counting of substantively identical capabilities across repositories.
- Security posture of tools: Systematically audit tool implementations for common vulnerabilities (e.g., injection, insecure defaults, token handling) and track the prevalence of secure-by-default templates/generators.
- Physical-world action tools: Quantify the prevalence and usage of tools that interface with physical systems (e.g., drones, IoT, industrial control) and characterize their permissioning and safeguards.
- Cross-ecosystem interoperability: Study how agents bridge MCP with non-MCP tools (e.g., through orchestration frameworks), and whether cross-protocol composition increases action space or bypasses guardrails.
- Workforce and task substitution: Distinguish between developer experimentation and sustained production deployments to better estimate substitution/complementarity effects on specific occupations.
- Governance and oversight pathways: Operationalize the proposed “tool-layer monitoring” into actionable regulatory dashboards (e.g., standard metrics, reporting formats, thresholds for supervisory alerts) and test these with agencies.
- Benchmarking action space: Define and validate standardized, comparable metrics for “action space size” that integrate tool capabilities, autonomy settings, guardrails, and real call frequencies.
- Public data reproducibility: Fully release the dataset and code (including classification prompts, models, and labels) to support independent replication and robustness checks.
- Ethical/privacy safeguards: Specify data governance for telemetry (if collected in future work), including privacy-preserving aggregation, differential privacy, or secure enclaves for regulator access.
- Outcome validation in financial tools: For the financial-transaction case study, instrument monitoring to capture actual agent-initiated transaction rates, reversals, fraud flags, and loss magnitudes across platforms.
- Sensitivity to threshold choices: Report how results change with alternative star thresholds, tool-count cutoffs, alternative “high-stakes” score thresholds, and different clustering parameters in BERTopic/HDBSCAN.
- Human validation depth: Increase human validation beyond the highest-level task domain to include mid-level tasks and direct impact/general vs. constrained labels, and quantify inter-annotator agreement there.
- Post-2026 trend continuity: Extend the panel beyond Feb 2026 to test whether the rise in general-purpose action tools persists and whether growth rates stabilize across geographies and sectors.
Practical Applications
Immediate Applications
Below are practical, deployable uses based on the paper’s findings and methods. Each item notes relevant sectors and key dependencies.
- Bold: Tool-layer risk monitoring dashboards for regulators
- Use the paper’s MCP-based monitoring method to map, classify, and track agent tools (perception/reasoning/action; narrow vs. general; O*NET stakes), with alerts for growth in high-stakes action tools (e.g., financial transactions).
- Sectors: policy/regulators (finance, healthcare, critical infrastructure), cybersecurity
- Tools/workflows: Continuous scraping of GitHub/registries (e.g., Smithery), PyPI/NPM download telemetry, O*NET mapping, stakes scoring, geo-split reports
- Dependencies: MCP’s continued predominance; coverage gaps for private registries; downloads ≠ actual execution; classification accuracy of LLM/O*NET mapping
- Bold: Enterprise agent-tool inventory and guardrails
- Enumerate MCP servers installed across org environments and classify their action space; restrict or sandbox general-purpose action tools (e.g., browser/desktop control) and require approvals for high-stakes actions.
- Sectors: enterprise IT, software, finance, healthcare
- Tools/workflows: Package manifest scanners (PyPI/NPM), MCP proxy with policy engine, allowlists/denylists, step limits
- Dependencies: Ability to observe tool installs/calls; reliable classification; user adoption of permission policies
- Bold: Prioritized red teaming of high-risk tools
- Focus security testing on general-purpose action tools and fast-growing high-stakes domains (e.g., finance) to probe prompt-injection resilience and irreversible-action pathways.
- Sectors: cybersecurity, fintech, SaaS
- Tools/workflows: Automated test harnesses for tool calls, injection corpora, rollback/transaction simulators
- Dependencies: Safe test environments and API tokens; organizational buy-in to prioritize tool-layer testing
- Bold: Vendor due diligence and “official server” preference
- Use the paper’s evidence that “official” MCP servers account for a large share of downloads to bias procurement toward supported, vetted tool sources where feasible.
- Sectors: procurement, compliance, enterprise IT
- Tools/workflows: Supplier vetting checklists, source-verification gates in CI/CD
- Dependencies: “Official” status is not a perfect proxy for safety; still requires review
- Bold: Geo-informed GTM and compliance for tool providers
- Align support, hosting, and compliance with usage hotspots (e.g., US ~50%, Western Europe ~20%); tailor documentation and SLAs accordingly.
- Sectors: software vendors, platforms
- Tools/workflows: Geo analytics from PyPI (where available), regional mirrors/CDNs
- Dependencies: PyPI geography is partial and skewed toward Western developers; NPM lacks geo splits; demand may differ outside developer pilots
- Bold: Dev-tools roadmap focus based on demand concentration
- Prioritize software development and IT tools (67% of tools; ~90% of usage) to capture near-term ROI, while exploring adjacent admin/finance use cases.
- Sectors: developer tools, platform ecosystems
- Tools/workflows: Product analytics tied to MCP download trends, targeted partner integrations
- Dependencies: Continued dominance of dev tooling demand; possible shift toward enterprise workflows
- Bold: Finance-specific guardrails for agentic transactions
- Wrap transaction tools (e.g., crypto, payments) with dual approval, rate limits, whitelists, and anomaly detection before enabling agent autonomy.
- Sectors: banking, fintech, treasury operations
- Tools/workflows: MCP wrappers enforcing policies, segregation of duties, on-chain monitoring
- Dependencies: API hooks for enforcement; business acceptance of added friction
- Bold: Tool-layer audit logging integrated with SIEM
- Capture and normalize agent tool-call metadata (tool type, stakes, generality, domain, geo) for auditability and incident response.
- Sectors: enterprise IT/SecOps, regulated industries
- Tools/workflows: MCP proxies/loggers, SIEM connectors, retention policies
- Dependencies: Observability into local and remotely hosted tools; privacy considerations
- Bold: AI co-authorship governance in code and tools
- Introduce AI provenance tagging and additional code review for AI-assisted MCP servers (36% of tools AI-assisted; rising trend).
- Sectors: software engineering, compliance
- Tools/workflows: Git hooks, commit heuristics, LLM provenance detectors, mandatory human-in-the-loop review
- Dependencies: Imperfect detection accuracy; developer workflow changes
- Bold: Training curricula on agent action space and safe configuration
- Educate operators on perception/reasoning/action classes and constrained vs. unconstrained environments; adopt safe defaults (short step limits, permissions-on-ask).
- Sectors: enterprise L&D, higher education
- Tools/workflows: Internal courses, labs with MCP sandboxes, checklists
- Dependencies: Up-to-date taxonomy; instructor expertise; role-based tailoring
- Bold: Early-warning indicators for financial authorities
- Monitor download spikes and new releases in transaction-related MCP tools to anticipate waves of agentic finance adoption or misuse.
- Sectors: central banks, market regulators, AML units
- Tools/workflows: Threshold-based alerts, change-point detection, join with SARs/incident feeds
- Dependencies: Download signals correlate only loosely with deployment; need corroborating data
- Bold: Academic replication and comparative studies
- Use the dataset and pipeline (BERTopic + O*NET mapping) to study adoption trends, domain shifts, and geography; compare with platform-level logs where possible.
- Sectors: academia, policy research
- Tools/workflows: Reproducible pipelines, crosswalks to SOC/O*NET, benchmarking across platforms
- Dependencies: Continued access to data; validation with human coders
- Bold: Open-source registry curation and risk labeling
- Community-maintained lists flagging high-stakes/general-purpose action tools; add badges for stakes level, generality, and author provenance.
- Sectors: OSS communities, developer ecosystems
- Tools/workflows: Contribution guidelines, automated checks, registry UI updates
- Dependencies: Maintainer capacity; consistent criteria; risk of stigma without nuance
- Bold: Consumer guidance for personal agent setups
- Recommend default-off for general-purpose action tools (desktop/browser control), explicit approvals for irreversible actions (emails, transfers), and transparent logs.
- Sectors: daily life, prosumers
- Tools/workflows: Setup wizards with guardrails, permission prompts, activity journals
- Dependencies: Agent UI support; user willingness to manage permissions
Long-Term Applications
The following applications require further development, standardization, or policy action.
- Bold: Registration/attestation regimes for high-stakes action tools
- Mandate disclosure, safety attestations, and contact points for MCP tools enabling high-stakes actions (e.g., finance/healthcare operations).
- Sectors: policy/regulation
- Tools/workflows: Public registries, due diligence templates, audit trails
- Dependencies: Legislation/regulatory authority; international harmonization; burden on SMEs
- Bold: Standardized capability/permission labeling at the tool layer
- Industry-wide schema to label each tool’s direct impact, generality, domain, stakes, and required approvals; machine-readable for policy engines.
- Sectors: standards bodies, software vendors, registries
- Tools/workflows: Capability manifests (e.g., JSON schemas), conformance tests
- Dependencies: Broad vendor adoption; versioning and compatibility across ecosystems
- Bold: Cross-platform telemetry consortium for tool-layer safety
- Privacy-preserving sharing of aggregate tool-call statistics, incidents, and abuse patterns across registries, platforms, and regulators.
- Sectors: cloud providers, AI platforms, regulators
- Tools/workflows: Differential privacy or federated analytics, secure enclaves, legal MOUs
- Dependencies: Trust frameworks, GDPR/CCPA compliance, incentive alignment
- Bold: Systemic risk monitors and circuit breakers for agent actions
- Real-time detection of correlated agent actions (e.g., automated withdrawals, mass web automation) and coordinated throttling or kill-switches.
- Sectors: finance, utilities, public sector digital services
- Tools/workflows: Streaming analytics keyed to tool classes, rate-limiters, escrowed overrides
- Dependencies: Cross-entity coordination; acceptable false positive rates; governance
- Bold: Insurance and actuarial models for agent action risk
- Underwrite agent deployments based on tool-layer risk scores (stakes/generality) and controls; premium discounts for safer configurations.
- Sectors: insurance, finance, enterprise risk
- Tools/workflows: Actuarial models tied to incident/loss data, control attestations
- Dependencies: Sufficient loss history; standardized reporting; moral hazard management
- Bold: Safety-rated marketplaces for MCP servers
- Marketplaces offering risk-scored tools (stakes, generality, provenance, vulnerability history) and curated “safe-by-default” bundles.
- Sectors: software marketplaces, enterprise IT
- Tools/workflows: Automated scanning, third-party audits, reputation systems
- Dependencies: Consensus on scoring; avoiding perverse incentives; liability clarity
- Bold: Oversight for agent-to-agent tool creation and provenance
- Provenance tagging, sandboxing, and mandatory human approval flows for AI-generated tools to prevent uncontrolled expansion of the action space.
- Sectors: software engineering, platform governance
- Tools/workflows: SBOMs with AI-provenance fields, sandbox runners, approval workflows
- Dependencies: Reliable AI authorship detection; developer adoption
- Bold: Labor market impact monitoring informed by tool adoption
- Use O*NET mapping to forecast displacement/complementarity effects as action tools spread from IT to other domains; guide retraining policies.
- Sectors: policy, academia, workforce development
- Tools/workflows: Longitudinal adoption metrics, task-level exposure modeling
- Dependencies: Linking tool adoption to outcomes; microdata access; evaluation frameworks
- Bold: Honeypot MCP servers for misuse intelligence
- Deploy instrumented high-interest tools to detect attack vectors and behaviors (e.g., credential harvesting patterns, automated abuse flows).
- Sectors: cybersecurity, law enforcement
- Tools/workflows: Legal/ethical approvals, telemetry pipelines, disclosure processes
- Dependencies: Jurisdictional constraints; risk of entrapment claims; safe operation
- Bold: Safe-by-default agent runtime standards
- Baseline autonomy constraints (step limits, human-in-the-loop for high-stakes), default permission prompts, and auditable decision logs.
- Sectors: standards bodies, agent vendors, enterprises
- Tools/workflows: Reference configurations, certification programs
- Dependencies: Industry alignment; balancing usability vs. safety
- Bold: OS- and browser-level controls for automated interactions
- Native rate-limiting, attribution, and permission systems for agents controlling desktops/browsers to mitigate spam and service overloads.
- Sectors: OS vendors, browser vendors, public service portals
- Tools/workflows: Capability APIs, per-application quotas, transparency indicators
- Dependencies: Platform engineering; ecosystem buy-in; UX design
- Bold: Export control/compliance screening for distribution of certain tools
- Assess whether specific high-stakes action tools warrant distribution controls (e.g., to sanctioned jurisdictions or entities).
- Sectors: policy, compliance
- Tools/workflows: Risk classification lists, export screening integration
- Dependencies: International agreements; avoiding stifling legitimate innovation
Key assumptions and dependencies across applications
- The MCP ecosystem remains a leading interface for agents; private/proprietary tool ecosystems may limit visibility.
- PyPI/NPM downloads proxy interest better than they proxy production execution; supplement with platform/runtime telemetry where possible.
- O*NET-based stakes mapping is an informative proxy but does not capture all contextual risk (e.g., compensating controls, organizational maturity).
- LLM-based classification introduces error; periodic human validation and benchmarked prompts/models are advisable.
- Geographic splits (currently available primarily for PyPI) are incomplete and developer-skewed; interpret cautiously.
Glossary
- Action space: The set of possible actions an AI agent can take, determined by the tools it has access to. "The action space of an AI agent describes the set of actions it can take in the world."
- Action tools: Tools that let agents directly modify external environments (e.g., edit files, send emails). "Agents need perception tools to access and read data, reasoning tools to analyse data or concepts, and action tools to directly modify external environments, like file editing, sending emails or steering drones in the physical world."
- Agent bank runs: A hypothesized systemic risk where many agents make automated withdrawals simultaneously, straining liquidity. "Simultaneous use of high-stakes banking tools for automated withdrawals by financial agents could precipitate liquidity crises akin to `agent bank runs'."
- Alignment failure: A failure where a model’s learned objectives diverge from intended goals, causing harmful behavior across dependent agents. "an alignment failure in a widely-deployed model propagates to every agent built on it"
- Attack surface: The collection of points where an agent can be manipulated or attacked, shaped by its accessible tools. "The attack surface of an AI agent is defined by its action space"
- Autonomy: An agent’s ability to carry out tasks without ongoing human direction or control. "Autonomy is the ability of an AI agent to fulfil tasks without external direction or controls"
- BERTopic: A topic modeling framework that combines embeddings with clustering to identify coherent topics. "The bottom-up approach uses a standard topic modelling pipeline BERTopic"
- Bootstrap confidence intervals: Uncertainty estimates derived via resampling from observed data. "Shading shows 95% bootstrap confidence intervals."
- Context window: The maximum span of tokens an LLM can condition on at once, influencing planning and memory. "An agent's goal complexity depends on the size of its context window"
- Crosswalks: Mapping tables used to align different classification systems (e.g., O*NET tasks to SOC occupations). "using existing crosswalks from O*NET bottom-level tasks to the Standard Occupational Classification (SOC)"
- Dual-use: Tools that can serve both beneficial and harmful purposes depending on use context. "General-purpose, dual-use tools for executing code have been exploited for cyber espionage in 2025"
- Ecological validity: The degree to which a measure reflects real-world conditions and use. "To assess ecological validity of download counts, we use Smithery use count data"
- Exponential fits: Modeling data with an exponential function to capture growth dynamics (e.g., doubling times). "Lines show exponential fits (Nov~2024--Feb~2026). Legend reports the doubling time ."
- Fleiss' kappa: A statistic for measuring agreement among multiple raters on categorical labels. "κ is Fleiss' kappa across 14 expert validators"
- General-purpose tools: Tools that enable interaction with broad, open-ended environments (e.g., browsers, code execution). "General-purpose tools grant agents access to unconstrained environments"
- HDBSCAN: A density-based clustering algorithm used for discovering clusters of varying densities. "we use HDBSCAN (min_cluster_size=0.3% of dataset size, min_samples=30% of min_cluster_size, cluster_selection_epsilon=0.02)"
- MCP server: A program that exposes capabilities and environments to agents via the Model Context Protocol. "An MCP server is a lightweight program that exposes capabilities and external environments to AI agents via a standardised protocol"
- Misalignment: The risk that an agent’s actions diverge from user intentions or values. "Mistake and misalignment risks occur when AI agents take erroneous or unintended actions."
- Model Context Protocol (MCP): An open protocol for integrating external tools and environments with AI agents. "by monitoring public Model Context Protocol (MCP) server repositories, the current predominant standard for agent tools"
- Node Package Manager (NPM): A software registry used to distribute and install JavaScript packages (including MCP servers). "we tracked monthly download statistics (2024-11 to 2026-02) for the subset of MCP servers hosted on the Node Package Manager (NPM) and Python Package Index (PyPI) registries"
- O*NET: A U.S. Department of Labor taxonomy of tasks and occupations used for mapping domains and stakes. "We use O*NET mapping to identify each tool's task domain and consequentiality."
- Perception tools: Tools that allow agents to access and read data from external sources. "Agents need perception tools to access and read data"
- Prompt injections: Adversarial instructions embedded in content to manipulate an agent’s behavior. "manipulative instructions (`prompt injections')"
- Python Package Index (PyPI): A software registry for Python packages, used to distribute MCP servers. "we tracked monthly download statistics (2024-11 to 2026-02) for the subset of MCP servers hosted on the Node Package Manager (NPM) and Python Package Index (PyPI) registries"
- Recursive self-improvement: A process where agents improve their own capabilities by creating or enhancing tools. "These structural risks may be compounded by recursive self-improvement"
- Sentence transformer: A neural embedding model that encodes text into vector representations for clustering or retrieval. "We use a pre-trained sentence transformer (Stella-400M) to embed each MCP server's title, description, and readme summary into 1024-dimensional vectors."
- Standard Occupational Classification (SOC): A system for classifying occupations used to aggregate task mappings. "using existing crosswalks from O*NET bottom-level tasks to the Standard Occupational Classification (SOC)"
- Tool generality: The extent to which a tool targets narrow, constrained environments versus broad, unconstrained ones. "Tool generality describes whether the tool enables interaction with narrow, constrained or general, unconstrained environments."
- Topic coherence: A metric indicating how semantically consistent the terms within a topic are. "a high topic coherence within clusters of 50%"
- UMAP: A dimensionality-reduction algorithm used to project high-dimensional embeddings into lower dimensions. "We then apply UMAP dimensionality reduction, resulting in 5-dimensional vectors."
- Weighted least squares (WLS) fits: A regression method that weights observations to address heteroskedasticity or varying certainty. "Lines show WLS fits: asymptotic convergence for action and medium-stakes (95% error-propagation CI), and poly-convergence for general-purpose and high-stakes (95% bootstrap CI)."
Collections
Sign up for free to add this paper to one or more collections.

