The Price Reversal Phenomenon: When Cheaper Reasoning Models End Up Costing More
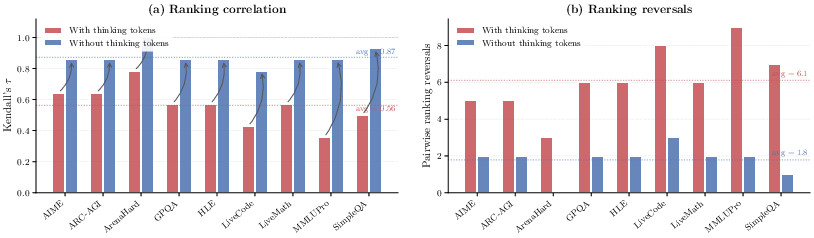
Abstract: Developers and consumers increasingly choose reasoning LLMs (RLMs) based on their listed API prices. However, how accurately do these prices reflect actual inference costs? We conduct the first systematic study of this question, evaluating 8 frontier RLMs across 9 diverse tasks covering competition math, science QA, code generation, and multi-domain reasoning. We uncover the pricing reversal phenomenon: in 21.8% of model-pair comparisons, the model with a lower listed price actually incurs a higher total cost, with reversal magnitude reaching up to 28x. For example, Gemini 3 Flash's listed price is 78% cheaper than GPT-5.2's, yet its actual cost across all tasks is 22% higher. We trace the root cause to vast heterogeneity in thinking token consumption: on the same query, one model may use 900% more thinking tokens than another. In fact, removing thinking token costs reduces ranking reversals by 70% and raises the rank correlation (Kendall's $τ$ ) between price and cost rankings from 0.563 to 0.873. We further show that per-query cost prediction is fundamentally difficult: repeated runs of the same query yield thinking token variation up to 9.7x, establishing an irreducible noise floor for any predictor. Our findings demonstrate that listed API pricing is an unreliable proxy for actual cost, calling for cost-aware model selection and transparent per-request cost monitoring.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “The Price Reversal Phenomenon: When Cheaper Reasoning Models End Up Costing More”
1) What this paper is about (overview)
This paper asks a simple question: when you pick an AI model because its price per “token” looks cheap, will you actually spend less money? The authors tested eight advanced reasoning AI models on nine kinds of tasks and found a surprising result: the model that looks cheaper on the price list often ends up costing more in real use. They call this the “price reversal” phenomenon.
2) The main questions the authors wanted to answer
The researchers focused on three easy-to-understand questions:
- Do the prices listed by AI providers (the “per-token” fees) match what people really pay when they use the models?
- If there’s a mismatch, what causes it?
- Can we predict how much a single AI request will cost before we send it?
3) How they studied it (methods in everyday language)
To make the study fair and clear, the authors built a “cost audit” that works like a careful budget tracker.
- How AI pricing works: Using these models is like paying for a taxi by distance. AI companies charge per “token,” which is like tiny pieces of words. You pay for:
- input tokens (your prompt or question)
- output tokens (the model’s response)
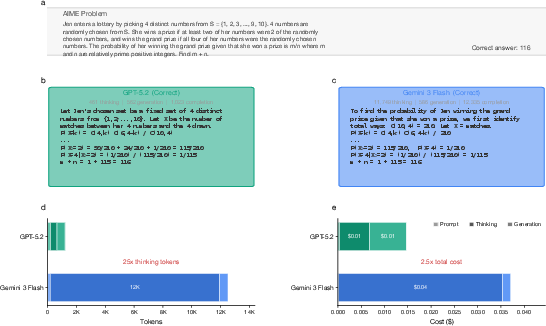
- A hidden extra: “thinking tokens.” Modern reasoning models often generate “invisible” tokens while they think through a problem (like a student’s scratch paper). You don’t see these tokens in the final answer, but you still pay for them. The paper shows these thinking tokens can be huge—and very different from model to model.
- What they tested: They ran the same sets of problems—like math competition questions (AIME), science and general knowledge quizzes (GPQA, MMLUPro), coding tasks (LiveCodeBench), and more—through 8 popular reasoning models.
- How they measured cost: For each model and task, they calculated: cost = (price per input token × number of input tokens) + (price per output token × number of output tokens)
- Finding the cause: They broke costs into three pieces—prompt tokens, thinking tokens, and final answer tokens. Then they did an “ablation” test: imagine setting the price of thinking tokens to $0 to see how rankings change. If the cost rankings suddenly line up with the listed prices, it means thinking tokens were the culprit.
- Can we predict per-query costs? They tried simple predictors:
- A “mean” guess (always predict the average)
- A small linear model using prompt length
- A K-nearest-neighbors model using the query’s meaning (embeddings) to find similar past questions and guess the cost
- They also repeated the exact same question multiple times to see how much the cost randomly changes run to run.
4) What they discovered (main results and why they matter)
Here are the key findings, presented briefly:
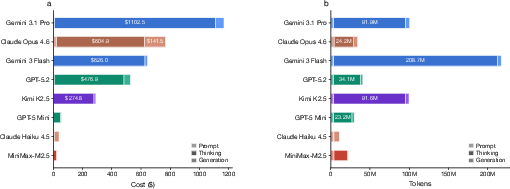
- Price reversal is real and common
- In about 1 out of 5 model comparisons (21.8%), the model that looked cheaper on the price list actually cost more to use on real tasks.
- Sometimes the reversal was huge—up to 28× more expensive.
- The big driver is “thinking tokens”
- Thinking tokens often made up most of the model’s output and total cost.
- Different models “think” very differently on the exact same question—one might use 500 thinking tokens while another uses over 10,000.
- When the researchers set thinking token cost to zero in their analysis, most price reversals disappeared and the cost rankings matched the listed prices much better.
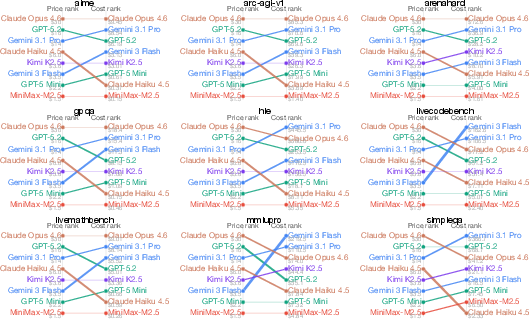
- Task type matters a lot
- A model that is cheap on one task can be expensive on another. There is no single “cheapest” model for everything.
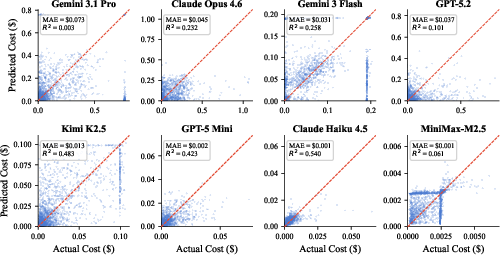
- It’s hard to predict the cost of a single question
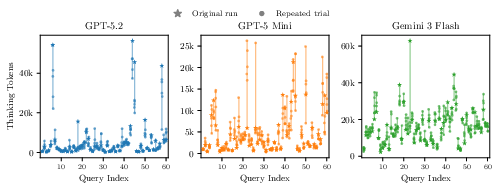
- Even when asking the same model the exact same question multiple times, the amount of thinking (and cost) could change a lot—sometimes by up to 9.7×.
- This randomness creates a “noise floor,” meaning even very smart prediction methods can’t perfectly guess per-question costs.
Why this matters: If you pick a model just because its posted price looks low, you could get a nasty surprise on your bill—especially for reasoning-heavy tasks where thinking tokens dominate.
5) What this means going forward (implications)
- For AI users and developers: Don’t choose models only by the advertised per-token price. Test models on your real tasks and track the full cost (including thinking tokens). Use cost monitoring per request, especially for reasoning tasks.
- For AI providers: Show clearer cost breakdowns (e.g., how many thinking tokens were used) and offer better tools to estimate the total cost before users run big workloads.
- For researchers: Treat cost as a first-class metric (not just accuracy). It’s important to design methods that select models based on real, workload-specific costs. Predicting per-query costs for reasoning models remains an open and challenging problem.
In short: The “cheapest” AI model on paper isn’t always the cheapest in practice—because hidden “thinking” can rack up the bill. To avoid surprises, measure real costs on your own tasks and push for more transparent pricing and reporting.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased so future researchers can act on it.
- Lack of accuracy-cost analysis: the study does not relate actual cost to task performance, leaving open whether “costlier” models (via thinking tokens) also deliver higher accuracy, and how reversals change under a fixed-accuracy metric (e.g., cost-of-pass or $$/correct).
- No evaluation of cost-quality-efficiency trade-offs: latency and throughput are not measured alongside cost, obscuring practical trade-offs (e.g., longer “thinking” may increase both cost and latency).
- Limited workload scope: results are based on nine single-turn benchmarks; real-world scenarios such as multi-turn dialogs, tool/function calling, RAG pipelines, agents with planning/act loops, and long-context document workflows are not evaluated.
- Multimodal/vision costs insufficiently characterized: tasks like ARC-AGI are included but the paper does not detail how image/audio tokens and modality-specific pricing interact with thinking tokens in cost reversals.
- Provider/tokenizer heterogeneity unaddressed: cross-provider tokenization differences, system prompt wrappers, and hidden pre-/post-processing could affect token counts; the methodology does not isolate or normalize these factors.
- Ambiguity in “thinking token” identification: the paper decomposes prompt, thinking, and generation tokens but does not fully specify how “thinking” tokens are detected across providers that hide or differently instrument internal reasoning—replication and standardization remain open.
- Configuration comparability: “reasoning-specific configurations” are enabled per model, but the criteria for “full reasoning capability” and cross-model equivalence (e.g., effort knobs, max output/think token caps) are not formalized, risking confounds.
- Unexplored control knobs for cost: the study does not test practical levers (e.g., max_tokens, reasoning budget/effort settings, “be concise” prompts, structured step limits, stop sequences) that could reduce thinking tokens and assess the cost–accuracy impact.
- Missing analysis of query features that drive thinking-token usage: beyond a KNN baseline, there is no taxonomy of query attributes (difficulty, ambiguity, compositionality) that predict large thinking-token consumption or high variance.
- Narrow prediction baselines: only mean, prompt-length LR, and embedding KNN are tried; richer predictors (e.g., difficulty estimators, shallow “probe” runs, early-token signals, learning-to-route/bandit policies, Bayesian models predicting a cost distribution) remain unexplored.
- Prediction target limited to point estimates: the paper highlights irreducible variance but does not model per-query cost as a distribution (e.g., predictive intervals or CV estimates), which is essential for budget-aware planning.
- Repeated-run variance studied on a single dataset: stochasticity experiments (six runs) are confined to AIME; it is unknown whether within-query CV and max/min ratios generalize across tasks, domains, and other models/providers.
- Small number of repeated trials: only six runs per query-model pair are used to characterize variance; larger samples and formal statistical tests (e.g., variance components, bootstrapped CIs) are needed for robust conclusions.
- Temporal drift not quantified: providers frequently update models and pricing; apart from running on different days for AIME, the study does not measure how thinking-token usage and reversal rates drift over time.
- Alternative pricing schemes not considered: enterprise discounts, regional pricing, per-second/compute billing, bundled “reasoning” quotas, or different rates for “thinking” vs “answer” tokens could alter reversal dynamics; these were not evaluated.
- Cache and repeated-content pricing ignored: some providers offer caching credits or discounts for repeated prompts; the impact on reversal rates and total spend is unknown.
- Safety and guardrail overheads unmeasured: moderation/safety layers may add hidden tokens or calls; their contribution to thinking-token volume and costs is not isolated.
- No investigation of mechanisms causing token heterogeneity: architectural/training factors (e.g., RL for reasoning, deliberate modules) that lead to longer thinking chains are not analyzed; causal drivers remain a black box.
- Lack of guidance for provider transparency standards: the paper calls for per-request cost breakdowns but does not propose concrete, auditable API schemas (e.g., standardized counters for prompt/think/final tokens, per-stage timing) or validation protocols.
- No study of early-exit or adaptive stopping: strategies that terminate thinking once confidence thresholds are met (or escalate only when needed) are not examined for their potential to curb costs while maintaining quality.
- Single-run cost measurements elsewhere: aside from the AIME variance test, most results use one run per query; given the demonstrated stochasticity, aggregate cost estimates may be sensitive to sample noise.
- External validity across more models/settings: only 8 frontier RLMs are examined; open-source/self-hosted models, smaller non-reasoning LLMs, and diverse providers may exhibit different reversal and variance profiles.
- Interaction with retrieval and tool outputs: the effect of retrieved context length, tool-call arguments, and tool response verbosity on thinking tokens and reversals remains unexplored.
- Token limits and truncation policies: how providers’ max token limits, truncation, or forced summarization under pressure influence cost and ranking reversals is not analyzed.
- Mixed-modality and streaming behaviors: the cost implications of streaming generation, partial results, or incremental reasoning are not studied but could materially change billed tokens and user-perceived efficiency.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now, based on the paper’s findings that listed API prices are an unreliable proxy for actual costs due to heterogeneous and variable “thinking token” consumption.
- Cost-aware model selection and procurement workflows
- Description: Replace price-per-token comparisons with short, workload-specific cost audits to compute actual cost and “cost-of-pass” (cost to achieve a correct answer) before committing to a model.
- Sectors:
- Software (code-gen, QA), Education (tutoring, grading), Healthcare (clinical documentation, triage), Finance (analyst assistants, compliance Q&A), Customer support (agent copilots).
- Tools/workflows:
- Use the paper’s released code/data to run pilot batches on representative queries; calculate total spend, cost-of-pass, and variance across models.
- Add a procurement checklist requiring per-workload cost auditing and price-reversal risk assessment before vendor selection.
- Assumptions/dependencies:
- Access to representative queries and the target API(s).
- Some providers must expose token usage; if thinking-token breakdown is not available, log billed tokens and infer practical cost outcomes via pilot runs.
- LLM FinOps/LLMOps monitoring with per-request cost tracking
- Description: Introduce per-request cost logging, token accounting, and alerting to detect price reversals and cost spikes from thinking tokens.
- Sectors:
- Any LLM-in-production environment (SaaS, internal tooling, dev platforms).
- Tools/workflows:
- Dashboards that track: total cost, tokens/request, variance (CV), and per-task cost-of-pass; budget alerts for abnormal spending.
- Anomaly detection on per-query cost variance and drift across releases or provider updates.
- Assumptions/dependencies:
- Observability hooks for token counts and cost from the API provider.
- Data governance for logging prompts/outputs (privacy compliance).
- Cost-aware model routing and cascading
- Description: Route queries to simpler/cheaper models first; escalate to a reasoning model only when needed, using cost signals and cost-of-pass metrics to decide escalation.
- Sectors:
- Customer support, Software engineering, Search/QA portals, Internal knowledge assistants.
- Tools/workflows:
- Gatekeeping policies based on difficulty heuristics and historical cost-of-pass; early-exit cascades to stop once acceptable quality is reached.
- Assumptions/dependencies:
- Basic quality routing signals; minimal per-request cost visibility.
- If mid-flight token streaming is not available, set small prompt templates and shorter first-stage attempts to bound costs.
- Prompting and agent design to curb excessive thinking tokens (when acceptable)
- Description: For tasks that do not require extended reasoning, use concise-response prompting, limit agent loop iterations, and disable or shorten chain-of-thought-like behaviors (if policy and UX permit).
- Sectors:
- Customer support, Productivity assistants, Simple transformations (summarization, drafting).
- Tools/workflows:
- Agent loop guards (max steps), timeouts, concise-instruction prompts, reduced tool-calls for simple tasks.
- Assumptions/dependencies:
- Quality trade-offs are acceptable; provider policies allow such controls; teams verify no leakage of hidden reasoning in outputs.
- Budget planning and pricing of AI products using cost-of-pass
- Description: Set subscription tiers and per-user quotas using workload-specific cost-of-pass rather than listed prices; include variance buffers based on observed CV.
- Sectors:
- SaaS with LLM features, EdTech platforms, Productivity tools.
- Tools/workflows:
- Periodic cost re-baselining using sample queries; reserve budget to cover within-query cost variability (e.g., 20–40% buffer).
- Assumptions/dependencies:
- Stable workloads; willingness to periodically recalibrate due to provider/model changes.
- A/B cost-quality evaluations in academic and enterprise studies
- Description: Report accuracy alongside actual spend and cost-of-pass in papers, benchmarks, and internal studies; replicate across tasks to expose price reversals.
- Sectors:
- Academia, R&D labs, Enterprise AI centers of excellence.
- Tools/workflows:
- Include cost-of-pass, pairwise reversal rate, and Kendall’s τ between price and actual cost in standard evaluation tables.
- Assumptions/dependencies:
- Consistent logging of costs and tokens; ability to run small replication batches.
- ESG and sustainability estimation via token-based compute proxies
- Description: Approximate energy/emissions using token-volume proxies; identify models whose “thinking” inflates compute/emissions relative to alternatives.
- Sectors:
- Enterprises with sustainability reporting mandates, Public sector.
- Tools/workflows:
- Emissions calculators that convert observed token volumes to estimated kWh/CO₂e; dashboards for per-workflow emissions.
- Assumptions/dependencies:
- Availability of defensible token→compute/emissions conversion factors; acceptance of proxy-based estimates.
Long-Term Applications
The paper highlights structural gaps (e.g., hidden thinking tokens, high variance) that motivate longer-horizon innovations in platforms, standards, and policy.
- Provider APIs with cost transparency and control
- Description: Expose per-request breakdown (prompt/thinking/final generation), preflight cost estimates, and a “thinking budget” knob (caps/SLAs on thinking tokens and cost variance).
- Sectors:
- All LLM API providers; enterprises negotiating SLAs.
- Tools/products:
- Cost estimation endpoints; server-enforced cost caps with graceful degradation (e.g., compress thoughts or return best-so-far).
- Assumptions/dependencies:
- Provider willingness to surface internal metering; mechanisms to bound or compress reasoning without severe accuracy loss.
- Industry standards and certifications for cost transparency
- Description: Standardize reporting on cost-of-pass, price-reversal rates, and variance metrics; certify providers/models on cost predictability.
- Sectors:
- Standards bodies, industry consortia, cloud marketplaces.
- Tools/products:
- “Cost Transparency Label” akin to energy labels; marketplace filters and leaderboards by cost-of-pass.
- Assumptions/dependencies:
- Cross-provider agreement on definitions and telemetry; independent auditors.
- Variance-aware routing and orchestration frameworks
- Description: Routers that factor in irreducible per-query cost variance, use robust estimators, and adapt in real time to observed token usage.
- Sectors:
- Multi-LLM platforms, Agent frameworks, Contact center platforms.
- Tools/products:
- Real-time token metering; “kill-switch” when predicted/observed cost exceeds a cap; risk-aware objective functions balancing accuracy, latency, and cost variance.
- Assumptions/dependencies:
- Streaming token counts and partial-cost visibility; policy-compliant early termination.
- New pricing models tied to outcomes rather than tokens
- Description: Shift from unit token pricing to outcome-based billing (e.g., pay-for-correctness, bundled attempts, flat per-task pricing).
- Sectors:
- Healthcare documentation, Legal/Finance QA, Education assessment.
- Tools/products:
- “Cost-of-pass contracts” and SLAs for specified tasks; bundled retries to manage stochasticity.
- Assumptions/dependencies:
- Reliable task scoring; agreement on correctness metrics; fraud/abuse safeguards.
- Training and inference methods that minimize thinking tokens
- Description: Model/algorithmic advances to reduce unnecessary internal reasoning tokens while preserving accuracy; test-time controls that compress “thoughts.”
- Sectors:
- Model labs, Edge/cloud inference providers.
- Tools/products:
- RL or distillation objectives penalizing excess thinking; thought-compression modules; deterministic or semi-deterministic reasoning modes to lower variance.
- Assumptions/dependencies:
- Maintaining performance under reduced thinking; evaluation protocols to guard against quality regressions.
- Regulatory and consumer-protection policy
- Description: Require disclosure of hidden cost components (thinking tokens), clear pre-use cost ranges, and warnings for high variance; mandate per-request cost breakdown in invoices.
- Sectors:
- Public sector, Consumer AI products, Enterprise procurement.
- Tools/products:
- Billing transparency rules; standardized invoices with token-type line items; mandated opt-in caps for consumers.
- Assumptions/dependencies:
- Policy consensus; enforcement mechanisms; international harmonization.
- Insurance and financial hedging for LLM cost volatility
- Description: Financial products that hedge unexpected spend due to cost variance or model updates; budget overrun protection.
- Sectors:
- Enterprises with large LLM spend; FinOps platforms.
- Tools/products:
- Spend-variance insurance; alerts tied to hedging triggers in cost dashboards.
- Assumptions/dependencies:
- Historical variance data; actuarial models for tail-risk pricing.
- CI/CD “cost gates” and research reproducibility practices
- Description: Add cost-of-pass checks to deployment pipelines; in academia, require reporting of cost and variance alongside accuracy for reproducibility and fair comparisons.
- Sectors:
- Software (DevOps/MLOps), Academia, Benchmarking orgs.
- Tools/products:
- Budget thresholds in CI; reproducible cost harnesses; shared benchmark suites with cost annotations.
- Assumptions/dependencies:
- Stable test harnesses; allowances for provider drift and periodic re-baselining.
These applications collectively operationalize the paper’s central insight: listed token prices are insufficient for budgeting or selection. Real-world deployments should measure and manage actual spend, account for thinking-token heterogeneity, and design systems and policies that are robust to substantial per-query cost variance.
Glossary
- Ablated cost: The computed cost after removing or altering specific components to study their impact. Example: "we compute the ablated cost as $c^{\text{abl}_m(q) = p_{i,m} \cdot n_{i,m}(q) + p_{o,m} \cdot (n_{o,m}(q) - n_{t,m}(q))$"
- Ablation study: An experimental method where parts of a system are removed to assess their effect on outcomes. Example: "we conduct an ablation study: we set the cost of thinking tokens to zero for all models"
- Chain-of-thought reasoning: A technique where models generate intermediate reasoning steps before final answers to improve performance on complex tasks. Example: "Recent advances in LLMs have introduced chain-of-thought reasoning as a core capability."
- Coefficient of variation (CV): A normalized measure of dispersion (standard deviation divided by the mean), used to assess variability. Example: "With a within-query CV of 0.29, even a perfect predictor would face average prediction errors of at least 29% purely from the model's internal randomness."
- Cost auditing framework: A structured method to measure and analyze actual costs under defined settings. Example: "we need a cost auditing framework, which includes (i) the RLM APIs and tasks, and (ii) how to formalize the actual cost."
- Cost-of-pass: A metric capturing the total expense required to obtain a correct answer from a model. Example: "holistic metrics like the 'cost-of-pass'~#1{erol2025cost}, measuring the actual financial expense required to obtain a correct answer."
- Embedding (query embeddings): Vector representations of inputs (e.g., queries) capturing semantic information for downstream tasks. Example: "a KNN baseline trained on query embeddings achieves poor accuracy on high-variance models"
- Empirical risk: The expected loss over observed data that a predictor aims to minimize. Example: "that minimizes the expected empirical risk $\mathbb{E}_{(q, c) \sim \mathcal{D} [\mathcal{L}(\hat{c}_m(q), c)]$"
- Input tokens: The tokenized units of the prompt sent to the model, often billed separately. Example: "a price/million output tokens denoted by , and a price/million input tokens denoted by ."
- Irreducible noise floor: Unavoidable variability in measurements that cannot be eliminated by better modeling or prediction. Example: "establishing an irreducible noise floor for any predictor."
- K-nearest neighbors (KNN): A non-parametric method that predicts outputs based on the closest examples in feature space. Example: "a KNN baseline trained on query embeddings achieves poor accuracy on high-variance models"
- Kendall's τ: A rank correlation coefficient measuring the agreement between two orderings. Example: "raises the rank correlation (Kendall's ) between price and cost rankings from 0.563 to 0.873."
- KV-cache optimization: Techniques to reuse key-value states in transformer models to speed up inference. Example: "KV-cache optimization~#1{pope2023efficiently} and quantization~#1{dettmers2022gpt3} reduce memory and compute requirements at serving time."
- Pay-as-you-go pricing: A billing model where users are charged per request or per unit consumed rather than a flat rate. Example: "The frontier RLMs usually use a pay-as-you-go pricing mechanism."
- Pricing reversal phenomenon: Cases where a model with a lower listed price ends up costing more in practice. Example: "We uncover the pricing reversal phenomenon: in 21.8\% of model-pair comparisons, the model with a lower listed price actually incurs a higher total cost"
- Prompt tokens: Tokens representing the input prompt provided to the model for processing. Example: "the cost is the sum of the two prices weighted by the number of prompt tokens and output tokens."
- Quantization: Reducing numerical precision (e.g., 16-bit to 8-bit) in model computations to save memory and compute. Example: "KV-cache optimization~#1{pope2023efficiently} and quantization~#1{dettmers2022gpt3} reduce memory and compute requirements at serving time."
- Rank correlation: A statistical measure of the similarity between two rankings. Example: "raises the rank correlation (Kendall's ) between price and cost rankings from 0.563 to 0.873."
- Reasoning LLMs (RLMs): LLMs designed to perform extended internal reasoning during inference. Example: "There has been an arms race in the AI industry to offer reasoning LLMs (RLMs) with affordable API pricing"
- Speculative decoding: An inference acceleration technique using a draft model to propose tokens that a larger model verifies. Example: "Speculative decoding~#1{leviathan2023fast,chen2023accelerating} uses a smaller draft model to accelerate generation."
- Stratified split: A data split method that preserves the distribution of categories (e.g., datasets) across train/test sets. Example: "using an 80/20 train/test split stratified by dataset"
- Thinking tokens: Internal, often invisible tokens generated during a model’s reasoning process that may be billed as output. Example: "RLMs produce both visible response tokens and invisible thinking tokens"
- Top-p: Also called nucleus sampling; a decoding method that samples from the smallest set of tokens whose cumulative probability exceeds p. Example: "Standard generation parameters (e.g., temperature, top-) are explicitly set"
Collections
Sign up for free to add this paper to one or more collections.