DFM-VLA: Iterative Action Refinement for Robot Manipulation via Discrete Flow Matching
Abstract: Vision--Language--Action (VLA) models that encode actions using a discrete tokenization scheme are increasingly adopted for robotic manipulation, but existing decoding paradigms remain fundamentally limited. Whether actions are decoded sequentially by autoregressive VLAs or in parallel by discrete diffusion VLAs, once a token is generated, it is typically fixed and cannot be revised in subsequent iterations, so early token errors cannot be effectively corrected later. We propose DFM-VLA, a discrete flow matching VLA for iterative refinement of action tokens. DFM-VLA~models a token-level probability velocity field that dynamically updates the full action sequence across refinement iterations. We investigate two ways to construct the velocity field: an auxiliary velocity-head formulation and an action-embedding-guided formulation. Our framework further adopts a two-stage decoding strategy with an iterative refinement stage followed by deterministic validation for stable convergence. Extensive experiments on CALVIN, LIBERO, and real-world manipulation tasks show that DFM-VLA consistently outperforms strong autoregressive, discrete diffusion, and continuous diffusion baselines in manipulation performance while retaining high inference efficiency. In particular, DFM-VLA achieves an average success length of 4.44 on CALVIN and an average success rate of 95.7\% on LIBERO, highlighting the value of action refinement via discrete flow matching for robotic manipulation. Our project is available \url{https://chris1220313648.github.io/DFM-VLA/}

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for robots to decide what to do, called DFM‑VLA. It helps a robot make a plan of actions (like “move arm up,” “open gripper,” “turn left”) and, importantly, lets the robot fix mistakes in that plan as it goes. Think of it like writing a paragraph and being able to edit any word on each pass, not just the newest word you wrote. This leads to better, more reliable robot behavior—especially for tasks with many steps.
What questions are the researchers trying to answer?
Here are the main questions they explore:
- Can we avoid a common problem in current robot models where early mistakes can’t be fixed later?
- Is there a better way to generate a whole sequence of robot actions that allows continuous correction and refinement?
- Which design works best for guiding these corrections?
- Does this new approach actually help on standard robot tests and in the real world, and can it do so efficiently (i.e., quickly)?
How did they do it? (Methods in simple terms)
To follow the paper’s ideas, it helps to know a few simple concepts:
- Actions as “tokens”: Instead of dealing with continuous numbers, the robot’s actions are broken into small, discrete pieces called tokens—similar to how words build a sentence. A whole action plan is a sequence of tokens.
- The problem with existing methods:
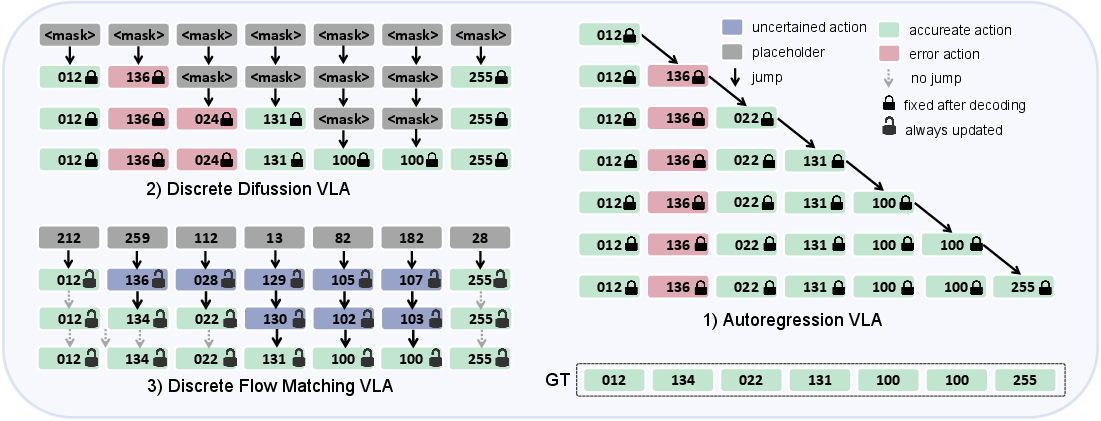
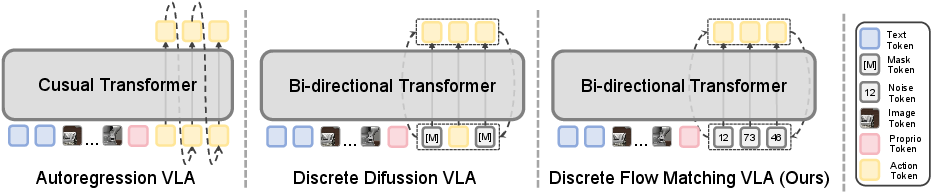
- Autoregressive (AR): Generates tokens one by one (left to right). Once a token is written, it’s basically locked in. If an early token was wrong, the model can’t go back and fix it easily.
- Discrete diffusion (DD): Updates many tokens in parallel, but still mostly fixes only certain “blanked” spots. Once a token is “filled in,” it often stays stuck. Both suffer from “irreversible commitment,” meaning early mistakes can stick around and mess up later steps.
- The new idea: Discrete Flow Matching (DFM) for actions
- Imagine the action sequence as being written on a whiteboard you can erase and rewrite anywhere. At each pass, the model looks at the whole plan and decides which tokens should change and how likely they should change.
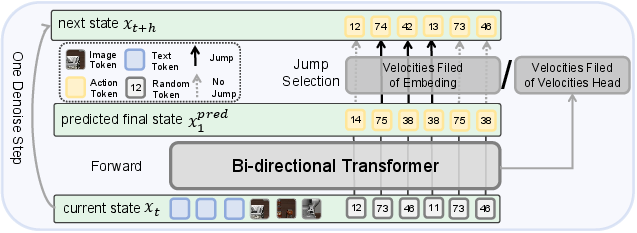
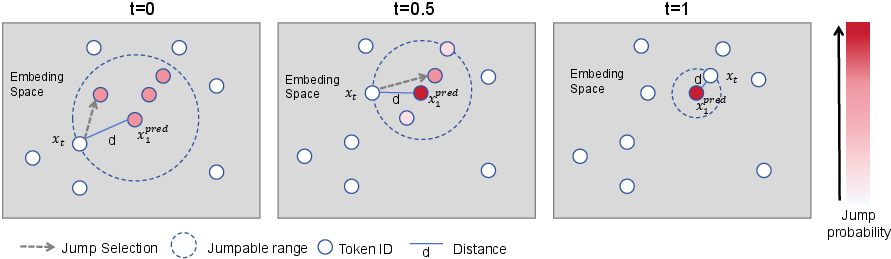
- The model learns a “probability velocity field.” In everyday language, that’s like a set of tiny arrows at each token telling it which way to move toward a better choice and how fast. With each step, the whole plan gets gently pushed toward a better version.
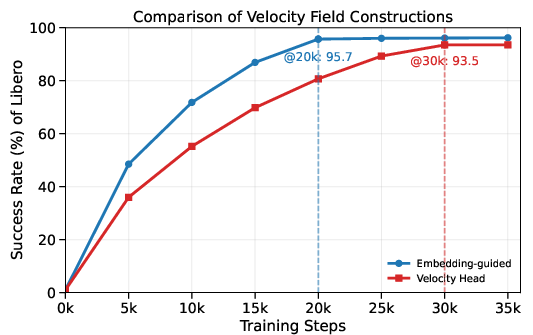
- Two ways to guide how tokens change: 1) Extra “velocity head”: The model has an extra output that directly predicts how each token should change. 2) Embedding‑guided velocity: Each token has a learned “position” in a meaning space. The model uses distances in that space to push tokens toward the right answer. If a candidate token is “closer” to the correct one, it gets preferred. This creates a smooth, sensible path from rough guesses to the final, correct actions.
- Two-stage decoding (how the robot makes its final plan): 1) Iterative refinement: The model repeatedly updates any token it’s unsure about. It can correct earlier mistakes at any time during this stage. 2) Deterministic validation: In the last few steps, it switches to a stable, greedy mode (always picking the best current guess) to lock in a clean, consistent final plan.
- Making it efficient:
- They reuse internal caches (stored computations) when possible, especially for the parts that don’t change much across steps (like the instruction and images). That speeds things up without hurting quality.
What did they find, and why is it important?
The researchers tested DFM‑VLA on popular robot benchmarks and on real robot tasks:
- CALVIN (long, multi-step tasks): DFM‑VLA got an average “success length” of 4.44 out of 5 steps—better than strong baselines. This means it completed longer chains of tasks in a row without failing.
- LIBERO (varied skills and generalization): DFM‑VLA achieved a 95.7% average success rate, outperforming several well-known methods. It did especially well on object-related tasks and long, multi-stage tasks.
- Real-world tasks: On three physical tasks (like lifting a pot with two arms and placing objects in containers), DFM‑VLA achieved the highest average success rate (70.8%) compared to other methods, showing it’s not just a lab trick—it works with real robots.
- Speed: Thanks to parallel refinement and smart caching, DFM‑VLA runs faster than traditional left‑to‑right models while keeping high quality.
- Robustness: It worked well across different settings and training sizes. It also handled changes to its timing schedule and the split between “refine” and “validate” steps without big drops in performance.
Why this matters: Robots often perform long sequences where a small early mistake can ruin everything. DFM‑VLA’s ability to correct errors anywhere in the sequence helps prevent error snowballing, leading to more reliable, safer robot behavior.
What’s the bigger impact?
- More reliable robots: Being able to fix earlier mistakes during planning makes robots better at long, tricky tasks—like cooking steps, assembling parts, or tidying rooms.
- Better use of existing models: It fits neatly with modern vision‑and‑LLMs by representing actions as tokens, so it can benefit from large-scale training while still being fast at test time.
- Broad potential: The idea of “refine everything, anytime” isn’t just for robots. It could help any system that builds sequences—like predicting text, code, or even video—become more accurate and flexible.
In short, DFM‑VLA is like giving robots a smarter eraser and a better sense of direction while they write their plans. That simple ability—to keep improving the whole plan with each pass—makes a big difference. The project page is listed in the paper if you want to explore demos and details.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what the paper leaves uncertain or unexplored, phrased to guide concrete follow-up research:
- Convergence guarantees of the two-stage decoding: no theoretical analysis of stability or convergence for the CTMC Euler discretization followed by greedy validation (dependence on step size h, total steps T, schedule β_t, and evolving x̂₁ across iterations).
- Sensitivity and learning of the action-distance metric d(·,·): the embedding-guided velocity relies on distances in the action token embedding space, but the choice/learning/calibration of this metric is not validated; it is unclear how different embeddings, vocabulary structures, or physically informed metrics (e.g., kinematic distances, collision costs) affect performance.
- Independence assumption in token updates: the CTMC treats token updates independently, potentially ignoring cross-token dependencies (e.g., coupling across action dimensions or time within a chunk); methods for coupled or structured velocity fields are not explored.
- Fixed-length action chunks and lack of edit operations: only replacement is used; insertion/deletion for variable-length plans, early termination, or adaptive chunking are not supported or evaluated.
- Initialization of refinement: refinement starts from uniformly random tokens; the impact of warm-starts (e.g., from AR/DD proposals, previous control cycle actions, or heuristic seeds) on latency and quality is not studied.
- Refinement budget vs performance: results are mainly with T=16 steps; there is no systematic step-performance curve, adaptive stopping criterion, or task-dependent scheduling beyond a small T_fine/T_val ablation.
- Joint perception–action refinement: the method refines only action tokens; whether jointly refining visual VQ tokens (or latent percepts) with actions improves robustness to perception errors/occlusions is untested.
- Safety and constraint handling: no mechanism to enforce joint limits, collision avoidance, or other safety constraints within the velocity field or validation stage; evaluation under disturbances, actuation delays, or sensor noise is missing.
- Breadth of real-world evaluation: real-world tests cover three table-top tasks; performance on contact-rich insertion, deformable manipulation, non-prehensile actions, mobile manipulation, and other robot platforms remains unknown.
- Real-time deployability: latency is profiled on H100 GPUs; there is no assessment on edge hardware, control-loop frequencies, jitter, or end-to-end cycle time on the robot.
- Action tokenization choices: only FAST+BPE (vocab=1024) is used; the effects of vocabulary size, alternative discretizations (e.g., VQ-action codes), and their impact on refinement quality, smoothness, or control chattering are not explored.
- Action chunk length and receding horizon: the chunk length and replanning frequency are not reported or ablated; how chunk size interacts with refinement steps and latency is unclear.
- Training objective design: training uses cross-entropy on x₁; alternatives (e.g., reward-aware losses, cost-to-go shaping, consistency distillation, or RL fine-tuning) and their impact on refinement dynamics are unexplored.
- Predictive calibration and uncertainty: the sampling of x̂₁ depends on model probabilities; calibration quality, uncertainty estimation, and confidence-based selective refinement or early stopping are not analyzed.
- Out-of-distribution (OOD) generalization: no evaluation under OOD instructions, objects, viewpoints, or backgrounds; domain shift and sim-to-real transfer without fine-tuning are not addressed.
- Multimodal reasoning integration: although outperforming some CoT-based baselines, the method does not investigate combining textual/spatial reasoning tokens with DFM-driven action refinement.
- Apples-to-apples comparison with continuous control: comparisons include RDT but may differ in backbone/tokenization; controlled studies where only the decoding paradigm changes are missing.
- Hybrid velocity modeling: combining the kinetic-optimal (embedding-guided) velocity with a learnable residual or head-based component is not tested; conditions where one dominates the other remain unclear.
- Adaptive KV caching parameters: the cosine-similarity threshold and its effect on accuracy/latency trade-offs are not examined; guidelines for setting cache-update policies are absent.
- Schedule design: only light ablations on c and α are provided; learnable or per-token schedules, task-conditioned scheduling, or adaptive β_t are not investigated.
- Oscillation and reversibility analysis: although the velocity is monotone w.r.t. a fixed target, the target x̂₁ changes across steps; no empirical analysis of token flip-flop/oscillation or damping mechanisms is given.
- Compute/memory footprint: training/inference memory usage and energy costs relative to AR/DD are not reported, hindering deployment planning.
- Dependence on pretraining: the model is initialized from pretrained robotic video checkpoints; performance when trained from scratch and the degree of reliance on pretraining are unknown.
- Multi-robot coordination: beyond limited bimanual tests, extensions to multi-agent settings with joint velocity fields, hand-offs, and coordination constraints remain unexplored.
- Failure-mode analysis: there is no systematic taxonomy of errors (e.g., which tokens most often require correction, where corrections fail), making it hard to target improvements.
- Reproducibility scope: while a project page is provided, full release details (code, checkpoints, exact configs) and reproducibility across hardware/software stacks are not specified.
Practical Applications
Below we distill practical, real-world applications enabled by DFM-VLA’s iterative action refinement via discrete flow matching, two-stage decoding (refinement + deterministic validation), and efficient inference (adaptive KV caching). We group use cases by time horizon and indicate sectors, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
- Robotics—Manufacturing and Assembly: drop-in action “refiner” to cut error cascades in long-horizon tasks (e.g., kitting, fastener insertion, small-part assembly).
- Tools/workflows: DFM-VLA ROS2 node that wraps existing VLA controllers; deterministic validation stage as a safety gate; adaptive KV-cached inference for cycle-time budgets; BPE/FAST-based action tokenizers and retraining scripts.
- Assumptions/dependencies: sufficient task demonstrations or prior checkpoints; action discreteness captures task precision; controller frequency and inference latency budgets are met; integration with robot PLC/ROS stack and safety interlocks.
- Robotics—Logistics/Warehousing: more reliable bin-picking, packing, and parcel sortation under variable object poses and long sequences.
- Tools/workflows: retrainable “iterative refiner” head for existing AR or diffusion VLAs; small-data fine-tuning (benefits shown even at 10% data) to adapt to SKU sets and bins.
- Assumptions/dependencies: labeled trajectories per SKU class; stable camera rigs (overhead + wrist); gripper/end-effector suited to items; conveyor timing constraints.
- Robotics—Food Service and Hospitality: consistent multi-step routines (e.g., assembling bowls/sandwiches, placing items into cookware; bimanual tasks like pot lifting demonstrated).
- Tools/workflows: bimanual policy with two-stage decoding for stable final steps; recipe/step-by-step instruction to action pipeline; kitchen-safe action vocabularies.
- Assumptions/dependencies: food-safe hardware; reliable object detection; sanitation and safety compliance; tolerance for discrete control granularity.
- Robotics—Retail and Facilities: shelf-stocking, tidying, and “put-and-take” tasks in back-of-house operations where early mistakes often cascade.
- Tools/workflows: shelf layout–conditioned policies; deterministic validation at final steps to ensure correct slot placement; logging of token refinements for QA.
- Assumptions/dependencies: updated planograms; robust perception of SKUs and slots; human-robot safety protocols.
- Lab Automation/Pharma: robust long-horizon manipulation (tube handling, plate transfers, cap/decap) with fewer user interventions.
- Tools/workflows: tokenization of micro-actions (e.g., approach, aspirate, dispense, move-to-slot) and iterative refinement to correct missteps; audit trail of refinement for GLP/GMP documentation.
- Assumptions/dependencies: calibrated pipetting end-effectors; low-latency control; validated action vocab for critical steps; cleanroom compliance.
- Education and Academic Research: strong baseline for long-horizon VLA research and courses; replicable benchmarks (CALVIN, LIBERO) with code from the project page.
- Tools/workflows: plug-in decoders (velocity head vs. embedding-guided); schedulers (β(t)) and two-stage decoding ablations; velocity-field visualizer for teaching/diagnostics.
- Assumptions/dependencies: access to GPUs; dataset licenses; familiarity with action tokenizers (e.g., FAST) and VQ visual tokenizers.
- Edge/On-Prem Deployment: lower-latency manipulation on embedded GPUs through adaptive KV caching without sacrificing success rates.
- Tools/workflows: “DFM-VLA Lite” inference engine with cosine-similarity–based KV reuse; fixed instruction/vision caches and adaptive action-side cache updates.
- Assumptions/dependencies: compatible hardware accelerators; profiling to match line-rate constraints; thermal/energy limits.
- Safety and Quality Assurance in Industrial Settings: deterministic validation stage reduces nondeterminism at convergence, aiding auditability and reproducibility.
- Tools/workflows: “last-N-steps greedy” policy toggle; per-token change logs and success counters; pass/fail reports for regulated lines.
- Assumptions/dependencies: acceptance criteria defined by quality teams; trace logging and secure storage.
- Startups/SMEs With Limited Data: improved manipulation performance in low-data regimes (noted gains at 10% data on CALVIN), enabling viable pilots with modest collection budgets.
- Tools/workflows: few-shot fine-tuning pipelines; data-efficient schedulers (tuning c, α) and two-stage allocations; quick A/B testing vs. AR/DD baselines.
- Assumptions/dependencies: access to small but representative demos; careful domain randomization; simple action vocabularies to start.
Long-Term Applications
- General-Purpose Home Robots: robust household tasks (loading dishwashers, folding laundry, tidying) with strong resistance to early-action errors and long-horizon drift.
- Potential products: vision–language home assistant with voice-instruction to action; configurable “deterministic finalization” profiles for safety around people.
- Assumptions/dependencies: broader, diverse household datasets; reliable perception in clutter; cost-effective hardware; extensive safety validation.
- Healthcare—Assistive and Hospital Robots: patient-care support (fetch-and-carry, supply restocking) and instrument handling with reliable long-horizon control.
- Potential products: ward logistics assistant; instrument-set preparation assistant that uses refinement to avoid irreversible mistakes.
- Assumptions/dependencies: stringent regulatory clearance; sterility and safety constraints; high-fidelity action tokens for delicate operations.
- Healthcare—Surgical Robotics Research: tokenized primitives for suturing or tool passing with iterative correction (research prototyping, not clinical deployment).
- Potential workflows: simulation-to-phantom training; deterministic validation for final sub-steps; velocity-field safety monitors that halt on abnormal transitions.
- Assumptions/dependencies: extremely precise action vocabularies; sub-millimeter control; rigorous clinical trials and oversight.
- Construction and Field Robotics: tool use (screwing, wiring), structured assembly, and maintenance where early errors often invalidate later steps.
- Potential products: mobile manipulator “task agents” with iterative refinement and on-tool vision; compliance-aware action tokens for contact tasks.
- Assumptions/dependencies: harsh environment robustness; compliance control integration; extensive real-world data.
- Agriculture: harvesting, pruning, and crop care requiring multi-step, variable-condition sequences with correction under occlusion and pose changes.
- Potential products: crop-specific DFM-VLA policies; seasonally retrainable action vocabularies; on-board inference with KV caching for battery life.
- Assumptions/dependencies: crop-specific datasets; weather and lighting variability; bio-safety and gentle handling requirements.
- Software/UI Agents (Decision Automation): adaptation of discrete flow refinement to UI action tokens for robust multi-step workflows (e.g., enterprise RPA, lab informatics).
- Potential tools: DOM/GUI action tokenizers; two-stage decoding to ensure final correctness; rollback/redo support guided by probability velocities.
- Assumptions/dependencies: reliable mapping from UI to discrete tokens; labeled trajectories; acceptable latency; guardrails for high-stakes operations.
- Standards, Policy, and Compliance Frameworks: certification templates for learning-based controllers that include iterative refinement and deterministic validation phases.
- Potential tools: conformance test suites that track irreversible-commitment rates; velocity-field logs as audit artifacts; safety thresholds on token-change rates.
- Assumptions/dependencies: multi-stakeholder agreement on test metrics; sector-specific regulations; standardized logging formats.
- Cross-Modal Reasoning-to-Action Stacks: unified perception–reasoning–action systems where discrete flow refinement stabilizes long chains from vision-language reasoning to actuation.
- Potential products: “reason-then-refine” controllers combining CoT with DFM-VLA; safety layers that gate final actions via deterministic validation.
- Assumptions/dependencies: large-scale multimodal training; robust alignment between reasoning tokens and action tokens; explainability requirements.
- Energy- and Cost-Aware Operations: broader adoption of KV caching and parallel refinement as low-energy inference strategies in “green robotics” initiatives.
- Potential tools: energy profilers that tie cache reuse to watt-per-task metrics; workload schedulers for multi-robot cells.
- Assumptions/dependencies: hardware telemetry; acceptance of mixed-precision inference; facility-level optimization.
- Open Benchmarking and Tooling Ecosystem: community standards around iterative-refinement controllers for manipulation, with shared datasets, schedulers, and evaluation harnesses.
- Potential tools: standard β(t) schedules and two-stage defaults; public leaderboards tracking long-horizon error correction; visualization suites for discrete velocities.
- Assumptions/dependencies: sustained community support; dataset governance; compute sponsorship.
Notes on feasibility across all applications:
- DFM-VLA depends on high-quality action tokenization (e.g., FAST + BPE) and adequate demonstrations that cover target variability.
- Real-time deployment requires profiling and potentially pruning/quantization; deterministic validation trades some flexibility for stability in the last steps.
- Safety-critical domains will need extensive validation, monitoring of token transitions/velocities, and fail-safe stop conditions.
Glossary
- Adaptive KV Caching: A transformer inference optimization that reuses key–value attention states across steps to reduce latency. Example: "Adaptive KV Caching."
- Action-embedding-guided formulation: A velocity-field design that uses distances in the action token embedding space to guide probability paths and refinement. Example: "and an action-embedding-guided formulation."
- Autoregressive (AR) methods: Sequence models that generate tokens left-to-right by predicting the next token conditioned on prior outputs. Example: "Autoregressive (AR) methods~\citep{brohan2022rt,kim2024openvla,univla} decode tokens sequentially with a next-token prediction objective."
- Auxiliary velocity-head formulation: A design that adds a dedicated head to predict token replacement velocities from backbone hidden states. Example: "an auxiliary velocity-head formulation"
- Byte Pair Encoding (BPE): A subword compression/tokenization algorithm that merges frequent symbol pairs to reduce sequence length. Example: "and further compress action tokens using Byte Pair Encoding (BPE), with an action vocabulary size of 1024."
- Causal attention: An attention masking scheme that prevents positions from attending to future tokens, enforcing left-to-right generation. Example: "AR VLA uses causal attention to generate future action tokens from previously generated ones"
- Chain-of-thought (CoT): Explicit intermediate reasoning traces that guide generation or control. Example: "visual or textual chain-of-thought (CoT)and jointly diffuse future frames, reasoning traces, and action tokens for unified perception--reasoning--action generation."
- Confidence-guided decoding: A decoding heuristic that updates tokens based on model confidence during iterative generation. Example: "they may still produce erroneous tokens in early iterations under confidence-guided decoding"
- Continuous-Time Markov Chain (CTMC): A stochastic process with state transitions occurring in continuous time governed by transition rates. Example: "we use a Continuous-Time Markov Chain (CTMC)."
- CTMC Euler step: A discrete-time approximation step for simulating CTMC dynamics by applying rates over a small time increment. Example: "Update by a CTMC Euler step"
- Deterministic validation stage: A final decoding phase that disables stochastic updates and uses greedy decisions to stabilize convergence. Example: "followed by a deterministic validation stage for stable convergence."
- Discrete diffusion (DD) methods: Parallel denoising approaches for discrete sequences that iteratively reconstruct tokens from corrupted inputs. Example: "Discrete diffusion (DD) methods~\citep{song2025accelerating,liang2025discrete,wen2025llada} improve parallelism and often reduce latency"
- Discrete Flow Matching (DFM): A framework that learns velocity fields over discrete tokens to transport a base distribution to data via probability paths. Example: "Recent Discrete Flow Matching (DFM) studies on Large-LLMs or VLMs have demonstrated competitive performance"
- Euler discretization: A first-order numerical integration scheme to approximate continuous-time dynamics with small discrete steps. Example: "we employ an Euler discretization of the continuous-time Markov chain (CTMC) process"
- Greedy decoding: A deterministic inference strategy that selects the highest-probability token at each position without sampling. Example: "we adopt a greedy decoding strategy to improve stability in the final refinement steps."
- Kinetic-optimal velocity: The velocity field that minimizes transport energy while satisfying the target probability path constraints. Example: "we adopt the kinetic-optimal velocity obtained by minimizing transport energy under the flow constraints"
- Mixture path: A probability path that interpolates between a base distribution and a target point mass via a time-dependent mixture coefficient. Example: "A common choice is the mixture path used in~\citep{gat2024discrete,havasi2025edit}, defined by a time-dependent scheduler :"
- Point mass: A degenerate distribution placing all probability on a single discrete outcome. Example: "and a point mass , i.e., if and $0$ otherwise."
- Probability paths: Time-indexed distributions that smoothly interpolate from a source to a target distribution in discrete space. Example: "referred to as probability paths."
- Probability velocity: The instantaneous rate governing probability flow between discrete states along a prescribed path. Example: "Its dynamics are governed by a probability velocity , also called the transition rate"
- Transition rate: The parameter in a CTMC that sets the rate at which transitions occur from one state to another. Example: "probability velocity , also called the transition rate"
- Vector quantization (VQ): A technique that maps continuous signals to discrete codebook entries, used here for tokenizing images. Example: "Methods based on vector quantization (VQ)~\citep{wang2025vq,liu2025faster,dong2026actioncodec} provide a flexible alternative by learning discrete latent representations."
- Velocity field: A set of tokenwise rate functions that determine how discrete states evolve over time toward targets. Example: "The velocity field is central to DFM, which defines the probability-path dynamics and is the main quantity learned during training."
- Vision--Language--Action (VLA): Models that map visual observations and language instructions to executable robot actions. Example: "Vision--Language--Action (VLA) models that encode actions using a discrete tokenization scheme are increasingly adopted for robotic manipulation"
- Vision-LLMs (VLMs): Multimodal models trained to jointly process visual and textual inputs. Example: "which enables scalable training with Vision-LLMs (VLMs) backbones and leverages their strong capabilities in vision and language"
Collections
Sign up for free to add this paper to one or more collections.