- The paper introduces a unified taxonomy and modular framework that integrate diffusion and flow models into reinforcement learning.
- The proposed JAX-based codebase enables reproducibility and rapid prototyping across diverse continuous control benchmarks.
- The study highlights trade-offs in guidance mechanisms, regularization, and network architectures, affecting performance in diffusion RL.
A Taxonomy and Modular Framework for Reinforcement Learning with Diffusion Policies
Introduction
The emergence of expressive generative models—specifically diffusion models (DMs) and flow models (FMs)—has motivated a shift in reinforcement learning (RL) away from conventional unimodal policies toward richer classes capable of modeling complex, multi-modal, and high-dimensional action distributions. However, incorporating DMs and FMs as policy classes in RL presents foundational algorithmic challenges, primarily due to the lack of tractable log-likelihood estimates and the incompatibility with conventional optimization paradigms (e.g., vanilla policy gradient or reparameterization trick). This paper presents a unified taxonomy of reinforcement learning with diffusion policies (DPRL), introduces a modular, high-throughput JAX-based RL codebase targeting reproducibility and extensibility, and provides systematic empirical benchmarks across diverse continuous control settings.
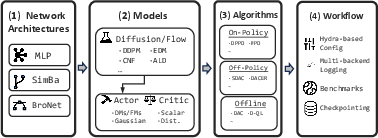
Figure 1: Semantic system overview of the proposed codebase, showing the modular decomposition spanning neural network backbones, generative model layers, algorithmic instantiations, and experimental workflows.
RL with Diffusion Policies: Taxonomy and Algorithmic Landscape
The paper frames RL with DMs and FMs through the general regularized RL objective:
πmaxEπ[Q(s,a)]−λDKL(π∥ν),
where π is the policy, Q is the state-action value function, ν is a reference policy, and λ modulates regularization. The structural choice of ν—uniform, past policy, or dataset behavior policy—determines the algorithm's exploration–exploitation balance and its suitability for online vs. offline learning.
The interaction of two axes—(1) guidance method for incorporating Q values, and (2) regularization reference policy—anchors the taxonomy. The guidance schemes differ in how they inject value information and impose regularization into the learning dynamics of diffusion policies.
Guidance Mechanisms
- Best-of-N (BoN) Sampling: Pretrain the DM to match ν, then at test time, sample N actions per state, select argmaxQ(s,ai). Used primarily in offline RL and for evaluation-time refinement.
- Q-value Guidance: Drawing from classifier-guided sampling in diffusion literature, Q enters the action scoring as an energy function, leading to guidance via gradients ∇aQ(s,a). Variants include direct score regression (e.g., QSM) and importance-weighted estimators approximating the true energy landscape at intermediate diffusion steps.
- Weighted Matching: Recasting policy improvement as weighted conditional score/flow matching, with sample weighting by exp(Q(s,a)/λ) to bias the policy toward high-value actions. This matches the optimal policy ∝ν(a∣s)exp(Q(s,a)/λ) stochastically.
- Reparameterization: Employ BPTT over the entire sampling chain or amortized estimators to maximize Q(s,a(0)) for generated actions. With intractable log-probabilities, these methods rely on auxiliary regularization (e.g., score matching, tractable entropy surrogates).
- Policy Gradient: Exploit (approximate) tractable Markovianization of the generative process allowing direct application of on-policy algorithms such as PPO, or alternative approximations of the evidence lower bound (ELBO) for policy ratios.
JAX-Based Modular Framework: Codebase Architecture
The introduced \libname library is modular and decomposable. It supports:
- Network Layer: Interchangeable neural architectures such as MLP, SimBa, BroNet; important as architectural confounds materially affect empirical RL results.
- Model Layer: Generic support for DMs, FMs, and normalizing flows; actors instantiated from any generative model; critics supporting distributional variants.
- Algorithm Layer: Algorithms abstracted as composable agents; new algorithms only require dedicated logic for initialization, parameter updates, and sampling, all JIT-compiled for computational efficiency.
- Workflow Layer: Hydra-based hierarchical configuration, seamless integration with logging, checkpointing, multiple continuous control benchmarks (including hardware-accelerated IsaacLab).
This modularity enables efficient ablation studies (architecture, guidance, and regularization), rapid prototyping, and reproducible training, directly addressing significant reproducibility gaps in generative policy RL.
Benchmarking Diffusion Policies in RL
Task Suites and Evaluation Protocol
Evaluation covers three families: (1) Gym-Locomotion (MuJoCo), (2) DMC, and (3) IsaacLab (GPU-accelerated, diverse robotic tasks). Representative tasks are shown below.







Figure 2: Representative environments spanning standard RL benchmarks (MuJoCo, DMC) and scalable robotic simulations (IsaacLab).
Policies are evaluated across online off-policy, online on-policy, and offline regimes. Hyperparameters, network architectures, and diffusion model settings are meticulously aligned for equitable comparison. All online experiments are run for fixed frames (1M for Gym/DMC, 100M for IsaacLab), while offline RL uses D4RL datasets.
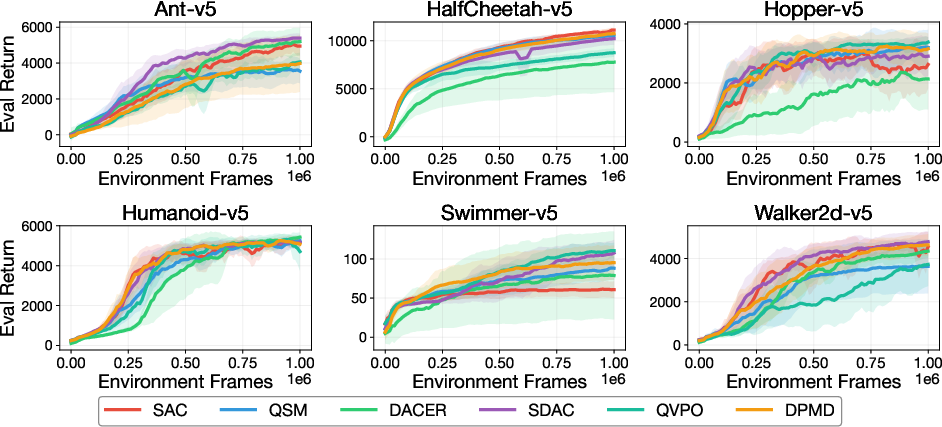
Figure 3: Training curves for leading off-policy DPRL algorithms in Gym-Locomotion, normalized against SAC.
Strong results are reported for SDAC, DACER, and DPMD, which generally outperform unimodal Gaussian baselines (SAC) in multiple environments. However, no single DPRL algorithm universally dominates—SAC remains competitive in several domains, highlighting that the flexibility of diffusion-based policies alone does not guarantee superior performance.
On-Policy RL with Diffusion

Figure 4: On-policy learning curves (IsaacLab): DPPO, GenPO, FPO, and PPO baselines.
In high-throughput IsaacLab tasks, standard PPO maintains robust performance, with GenPO leading among DPRL approaches at the cost of higher computational demands (Jacobians for ELBO estimation). FPO is prone to collapse, attributed to instability in policy ratio estimation for negative advantage samples.
Offline RL
Notably, diffusion RL policies—when trained with RL-guided objectives rather than solely as behavior priors—significantly outperform classic offline actor-critic algorithms like IQL and inference-time only schemes.
Empirical Analysis: Key Factors in Diffusion RL
Action Dimensionality
Weighted matching approaches (e.g., SDAC) are disadvantaged as action space dimensionality increases due to inefficient high-value sample acquisition, as evidenced below.
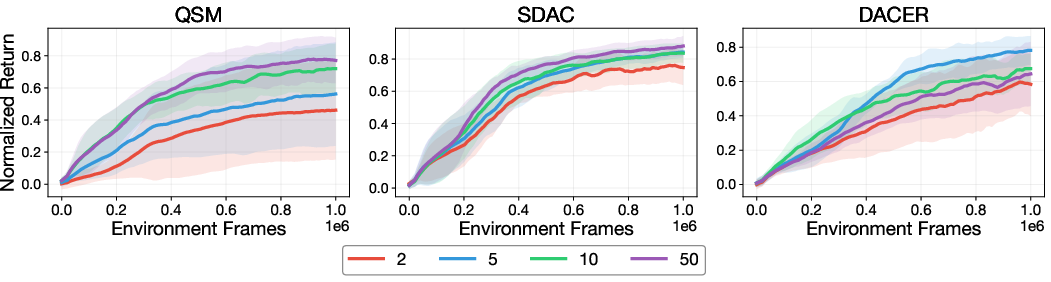
Figure 5: Performance of QSM, SDAC, and DACER as a function of number of diffusion steps, highlighting scaling behavior with action dimension.
Q-value guidance (QSM) and reparameterization (DACER) methods show more robust scaling with increasing action dimension.
Diffusion Step Count
Increasing diffusion steps generally improves performance for score-matching and weighted matching (QSM, SDAC), but harms reparameterization-based algorithms (DACER) beyond a threshold, due to increased gradient estimation complexity and optimization instability.
Architectural Effects

Figure 6: Substitution of MLP with SimBa backbone yields universally higher returns across DMControl hard tasks for both QSM and DACER.
Network backbone is a strong confound across all families of diffusion guidance.
Noise Schedule Sensitivity
Switching from cosine to linear noise schedule yields minimal performance change in RL, in contrast to sample quality sensitivity observed in generative modeling.
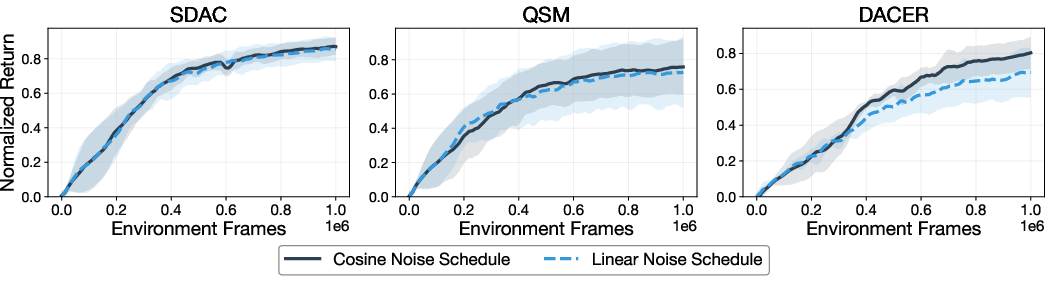
Figure 7: Performance impact of cosine versus linear noise schedule is negligible across tested algorithms.
Conclusion
This work establishes a unified taxonomy for RL with diffusion and flow policies, decomposing the field along guidance mechanism and regularization axes. The accompanying open-source, modular JAX-based library closes significant empirical gaps regarding reproducibility and ablation power. Comparative benchmarks demystify the empirical behavior of disparate DPRL algorithms, reveal actionable design heuristics for practitioners, and highlight the nuanced dependencies on architecture, guidance strategy, regularization, and hyperparameters. Open directions include improved robustness to environment diversity, scaling to sparse-reward and long-horizon domains, and closing the gap in sample complexity versus unimodal baselines. The framework’s extensibility positions it as an ideal substrate for future exploration into generative RL and broader applications in robotics and structured control.