- The paper introduces Discrete Native Autoregression (DiNA) that unifies text, vision, and audio modalities within a single embedding space.
- It employs Residual Vector Quantization and modality-agnostic tokenizers to ensure semantic completeness for high-fidelity generation and reasoning.
- Empirical results demonstrate competitive performance across OCR, visual understanding, and audio tasks, validating a unified multimodal framework.
LongCat-Next: A Unified Discrete Autoregressive Paradigm for Multimodal Modeling
Motivation and Paradigm Shift
LongCat-Next introduces Discrete Native Autoregression (DiNA), establishing a unified framework that moves beyond language-centric multimodal systems by representing all modalities—text, vision, and audio—as discrete token sequences within a single embedding space. This paradigm eliminates the architectural fragmentation typical of multimodal LLMs, where vision and audio are treated as bolt-on modules, and instead leverages shared infrastructure and objective, thus reconciling the competing demands of understanding and generation.
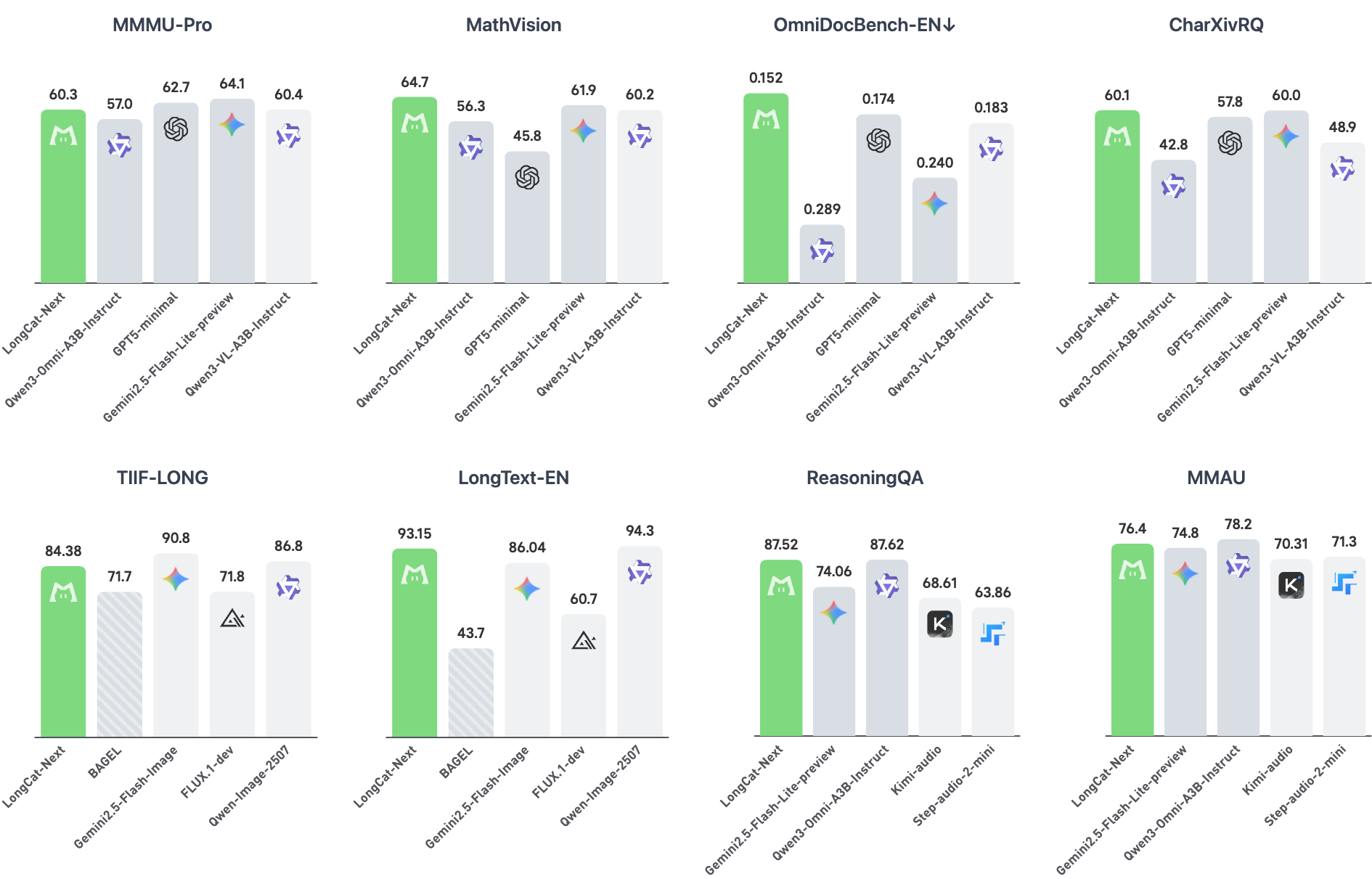
Figure 1: Benchmark performance of LongCat-Next demonstrating competitive results across multimodal tasks.
Tokenizer Architecture and Semantic Completeness
The heart of LongCat-Next is the Discrete Native-Resolution Vision Transformer (dNaViT), which employs Residual Vector Quantization (RVQ) to encode visual data into hierarchical discrete tokens. Unlike low-level reconstructive models (e.g., VQ-VAE), dNaViT leverages Semantic-and-Aligned Encoders (SAE) pre-trained on large-scale vision-language datasets to ensure semantic completeness: the discrete representation preserves the information required for both high-fidelity generation and complex reasoning.
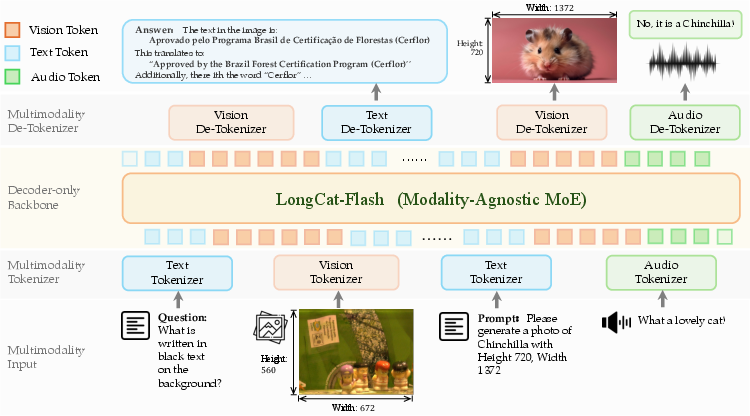
Figure 2: Overview of the LongCat-Next architecture, showing paired tokenizers and modality-agnostic decoding.
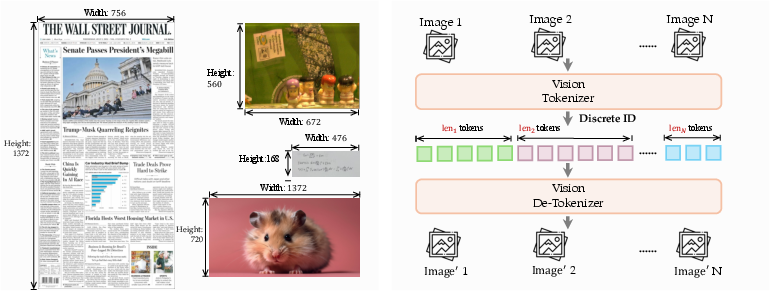
Figure 3: dNaViT design enables tokenization at native (arbitrary) resolution through hierarchical RVQ.
The pixel decoder, paired with SAE and RVQ, recovers spatial layouts, structures, and even fine-grained details from frozen discrete tokens, as empirical analysis shows residual pathways fundamentally supporting information recovery.
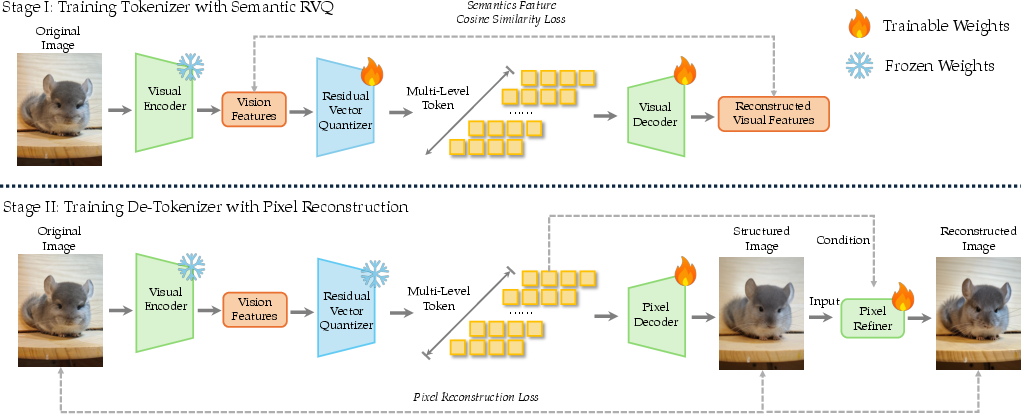
Figure 4: The dNaViT training pipeline encodes images via RVQ and decodes them back at arbitrary resolutions.

Figure 5: Visual reconstruction from different vision encoders, revealing intrinsic signal preservation from residual connections.
Generalization to Audio and Modal-Agnostic Integration
The audio tokenizer applies a Whisper encoder and RVQ, capturing both semantic and paralinguistic features. The system supports both parallel and serial text-guided speech generation, using special tokens for segment alignment. Architectural integration ensures visual, audio, and textual embeddings are learned jointly, not projected separately.
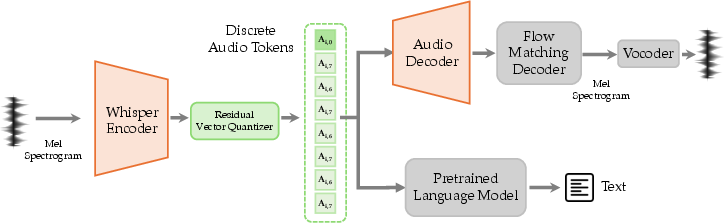
Figure 6: Audio tokenizer framework, mapping waveforms to discrete semantic/acoustic tokens.
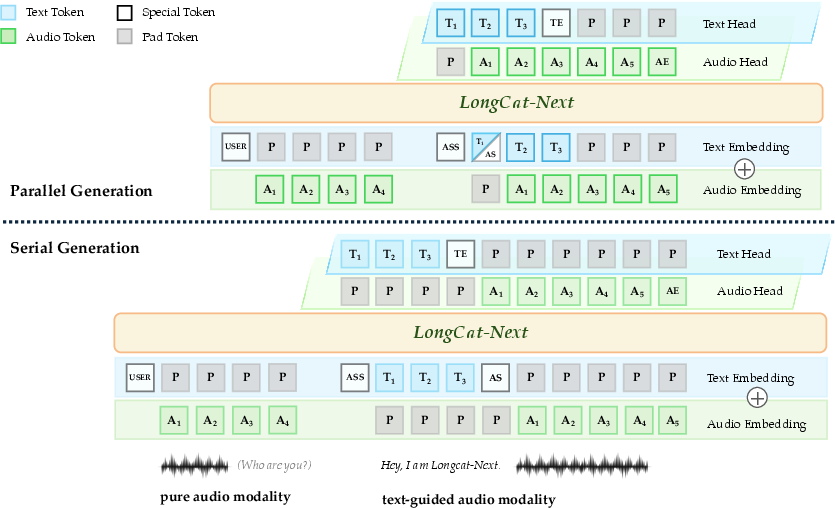
Figure 7: Internal linguistic guidance enables flexible speech generation modalities with segment alignment.
Unified Modeling of Understanding and Generation
LongCat-Next unifies the objectives of understanding and generation under next-token prediction. Empirical studies demonstrate nearly identical loss and performance for models trained solely on understanding, generation, or both, indicating that generation does not compromise understanding—in fact, understanding improves generation quality.

Figure 8: Understanding and generation cases at arbitrary resolution illustrating the unified paradigm.
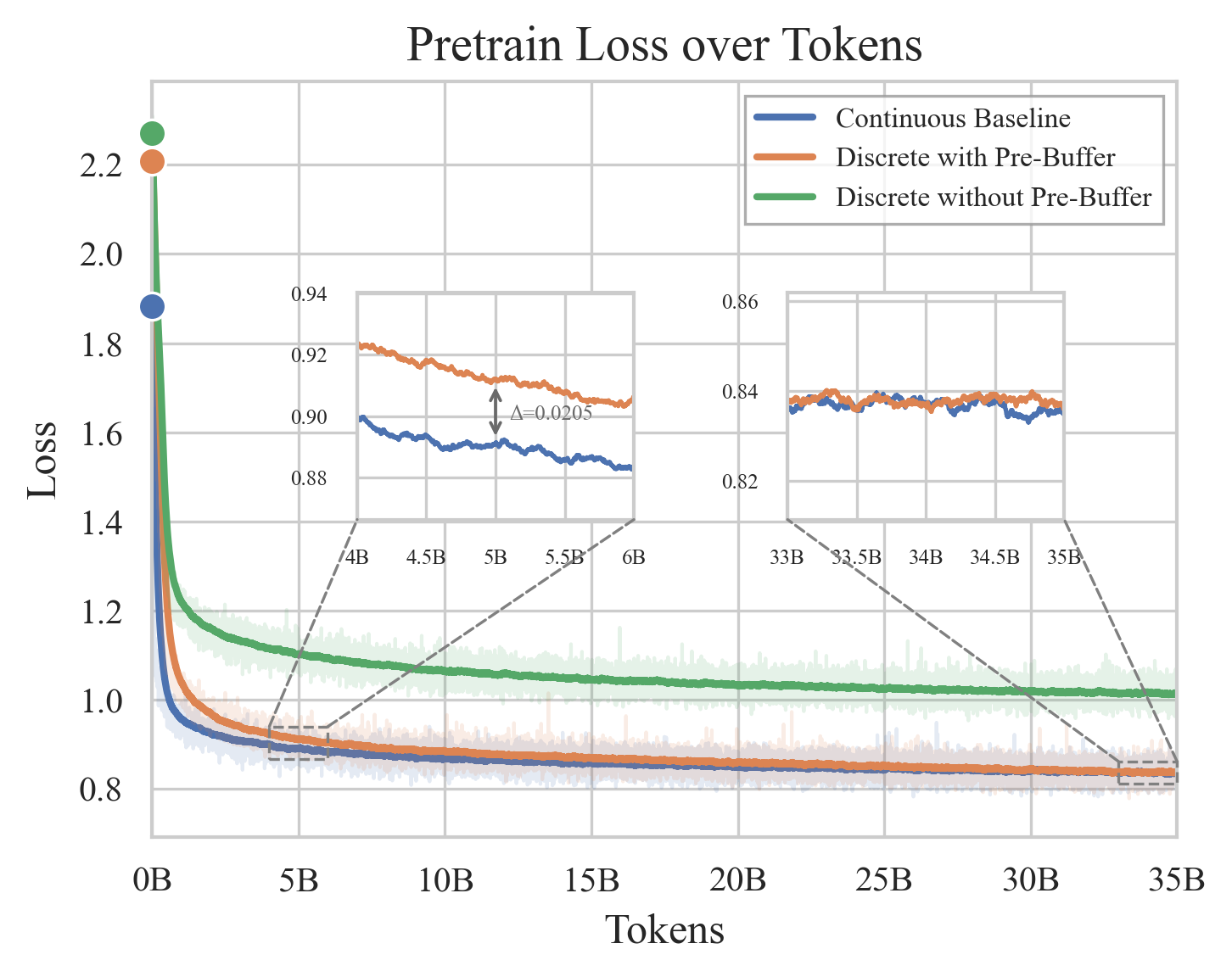
Figure 9: Loss and performance comparison between discrete and continuous vision representations; scaling closes the gap.
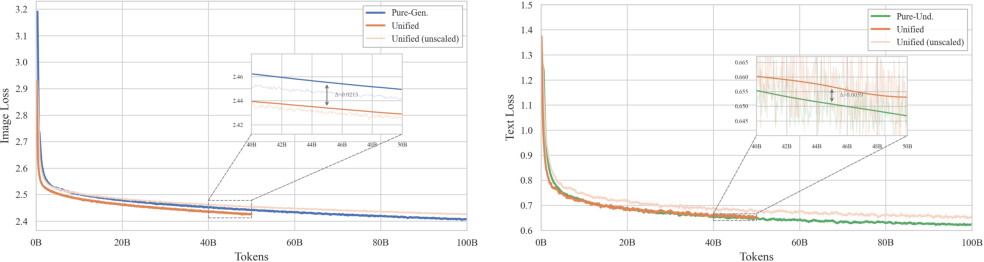
Figure 10: Visual understanding and generation interaction under the unified DiNA framework.
Modality-Agnostic Mixture-of-Experts (MoE)
LongCat-Next adopts a Mixture-of-Experts backbone, where experts are functionally agnostic but specialize across modalities over the course of training. Empirical routing analysis shows increasing expert diversity and utilization.
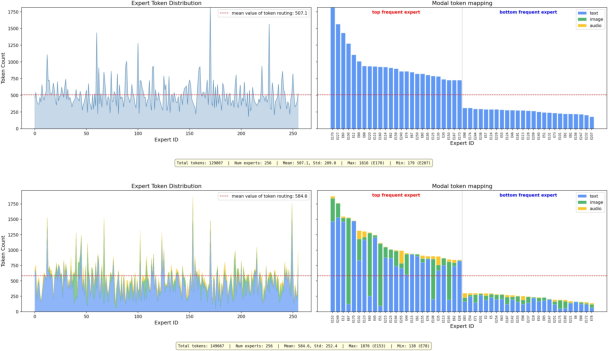
Figure 11: MoE dynamics: token distribution and emergence of modality-specific specialization.
Semantic Alignment and Platonic Representation Hypothesis
Token-level t-SNE analysis reveals interwoven text and vision embeddings within a unified space, supporting the Platonic hypothesis: modalities represent different expressions of the same underlying reality. This validates native discrete modeling for cross-modal semantic integration.
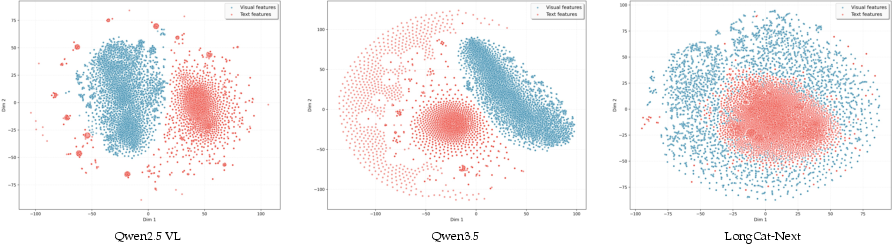
Figure 12: Token-level distribution divergence: LongCat-Next internalizes cross-modal semantics better than previous frameworks.
Data Curation, Training, and Infrastructure
Data scaling, semantic clustering, and structured instruction-following are core to LongCat-Next’s training pipeline. Visual generation data is rebalanced via cluster-driven sampling; OCR and STEM datasets are constructed and cleaned for robust generalization. Infrastructure adopts a V-shaped pipeline schedule for efficient multimodal training and minimized communication overhead.
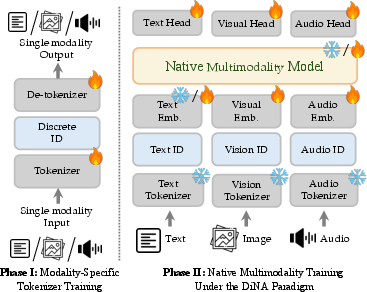
Figure 13: Overview of LongCat-Next training phases for multimodal integration.
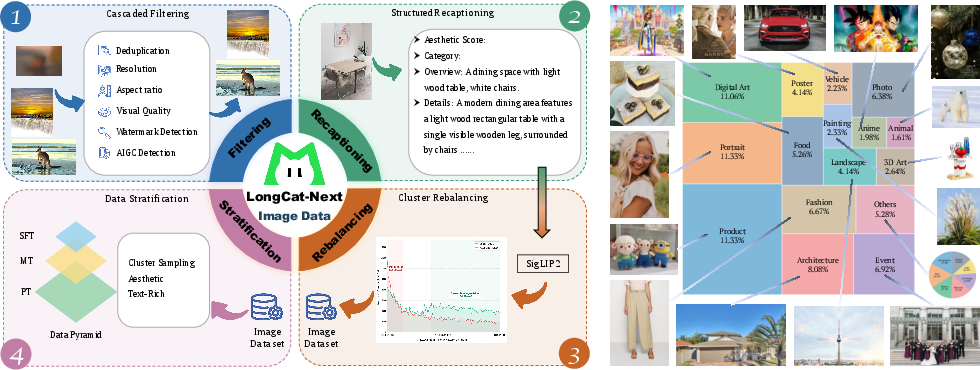
Figure 14: Data curation process and image source distribution.
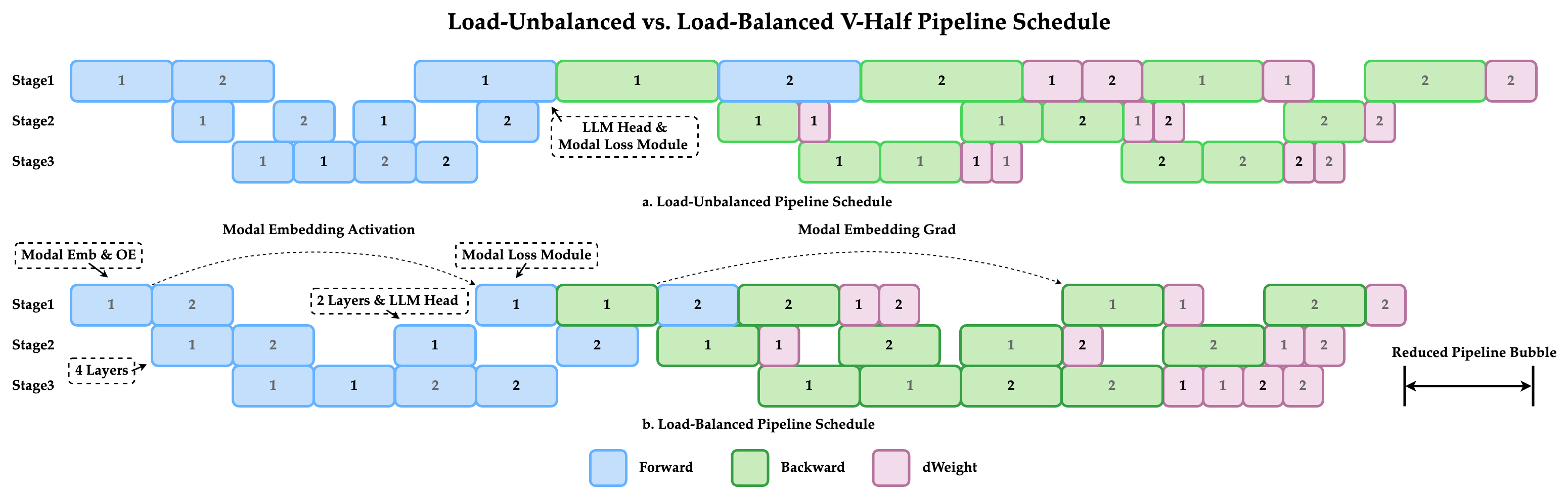
Figure 15: Infra pipeline for optimized multimodal model training.
Empirical Results and Model Capabilities
LongCat-Next achieves competitive or superior results relative to both unified and specialist models across multimodal benchmarks:
- Visual understanding: Highest scores on MathVista and MathVision (83.1, 64.7); best OCR and chart extraction on OmniDocBench, CharXiv, ChartQA; competitive on MMStar, RealWorldQA, GUI tasks.
- Visual generation: Matches or exceeds specialized T2I models on compositional alignment (GenEval), prompt fidelity (DPG), and text rendering.
- Audio: Outperforms Gemini-3.1-Flash-Lite-preview and other baselines in ASR, TTS (WER < 2 on SeedTTS), audio QA and reasoning (86.8 on AlpacaEval).
- Text: Shows robust agentic and coding capabilities (43.0 accuracy on SWE-Bench), resisting typical multimodal degradation.
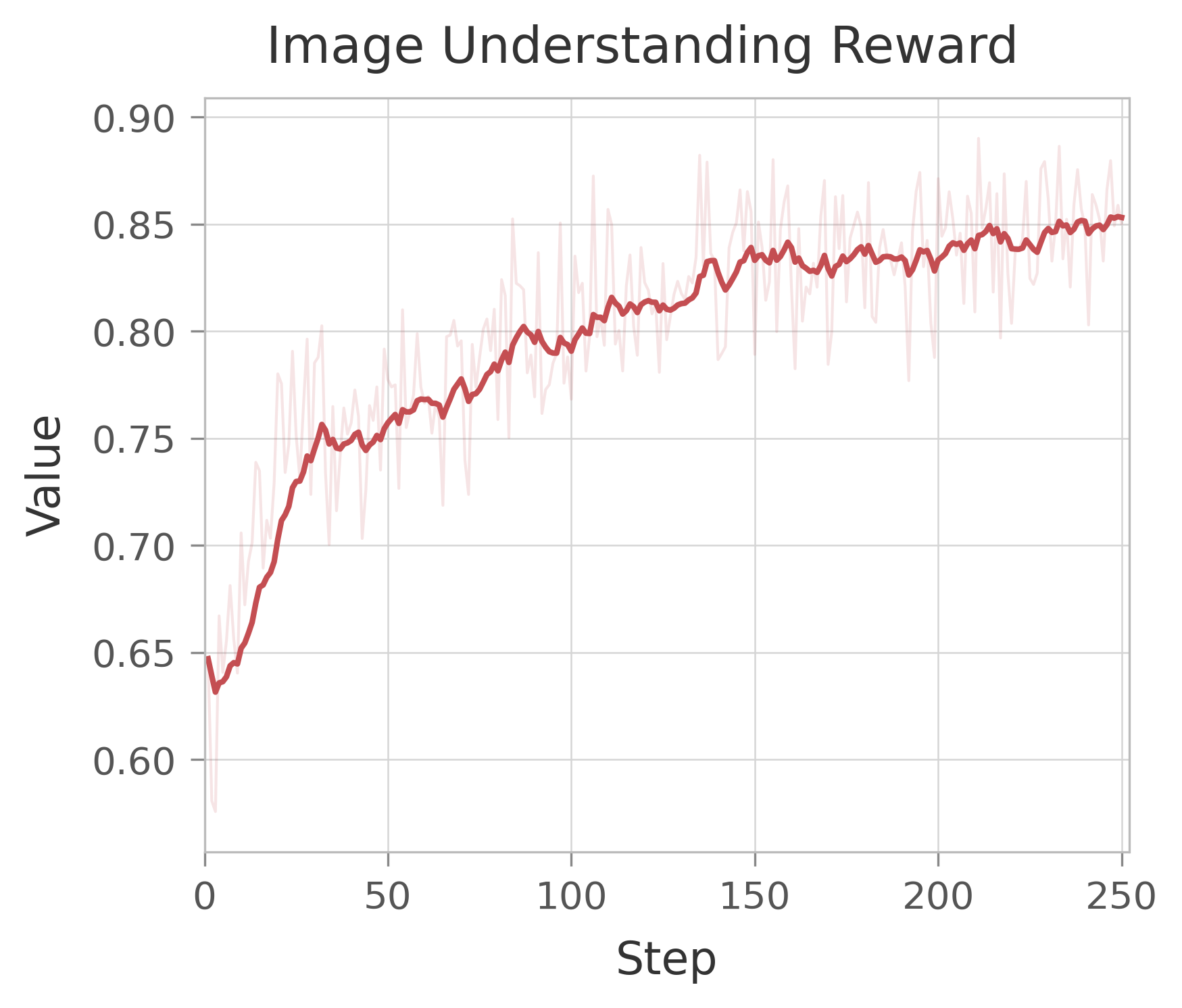
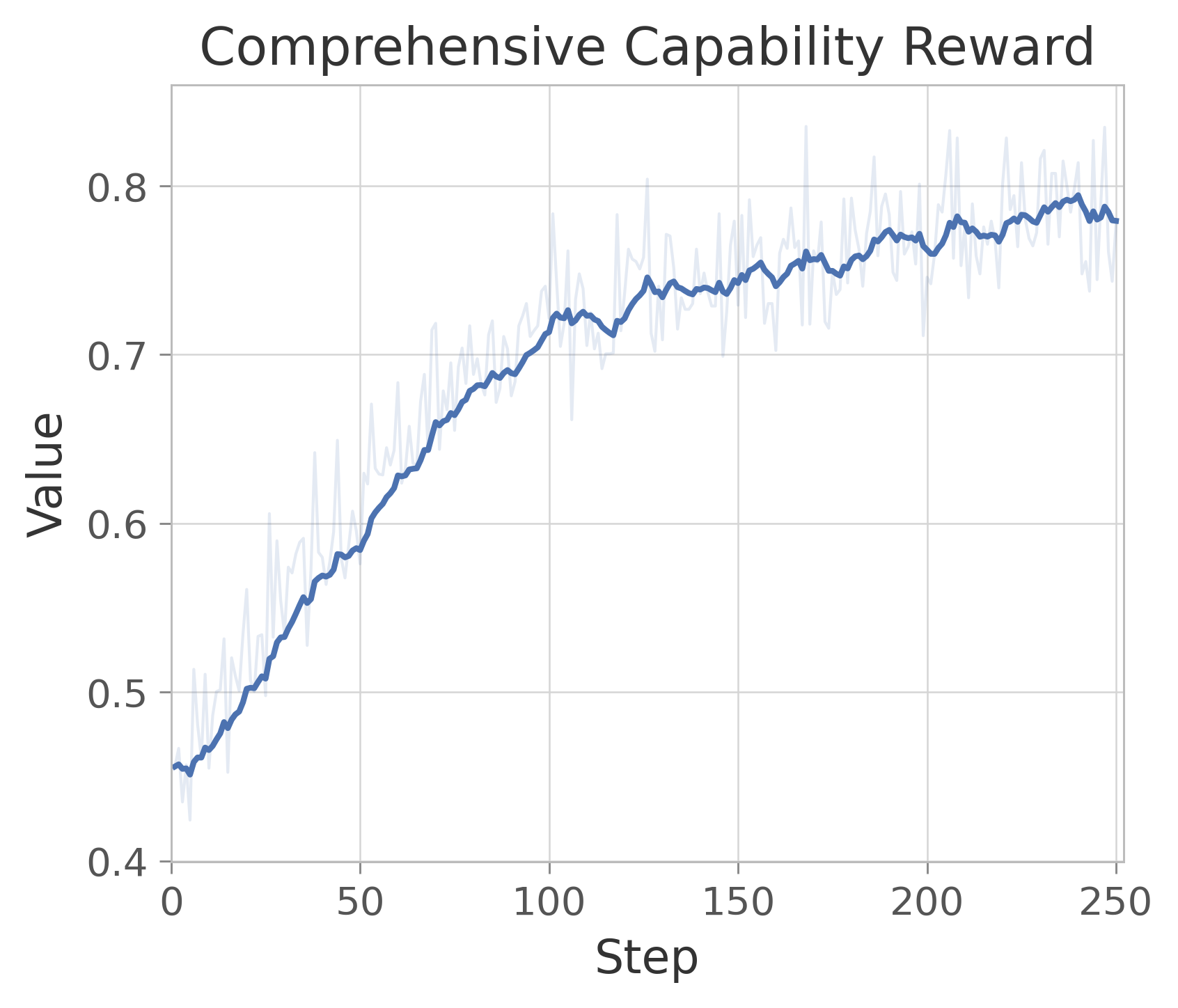
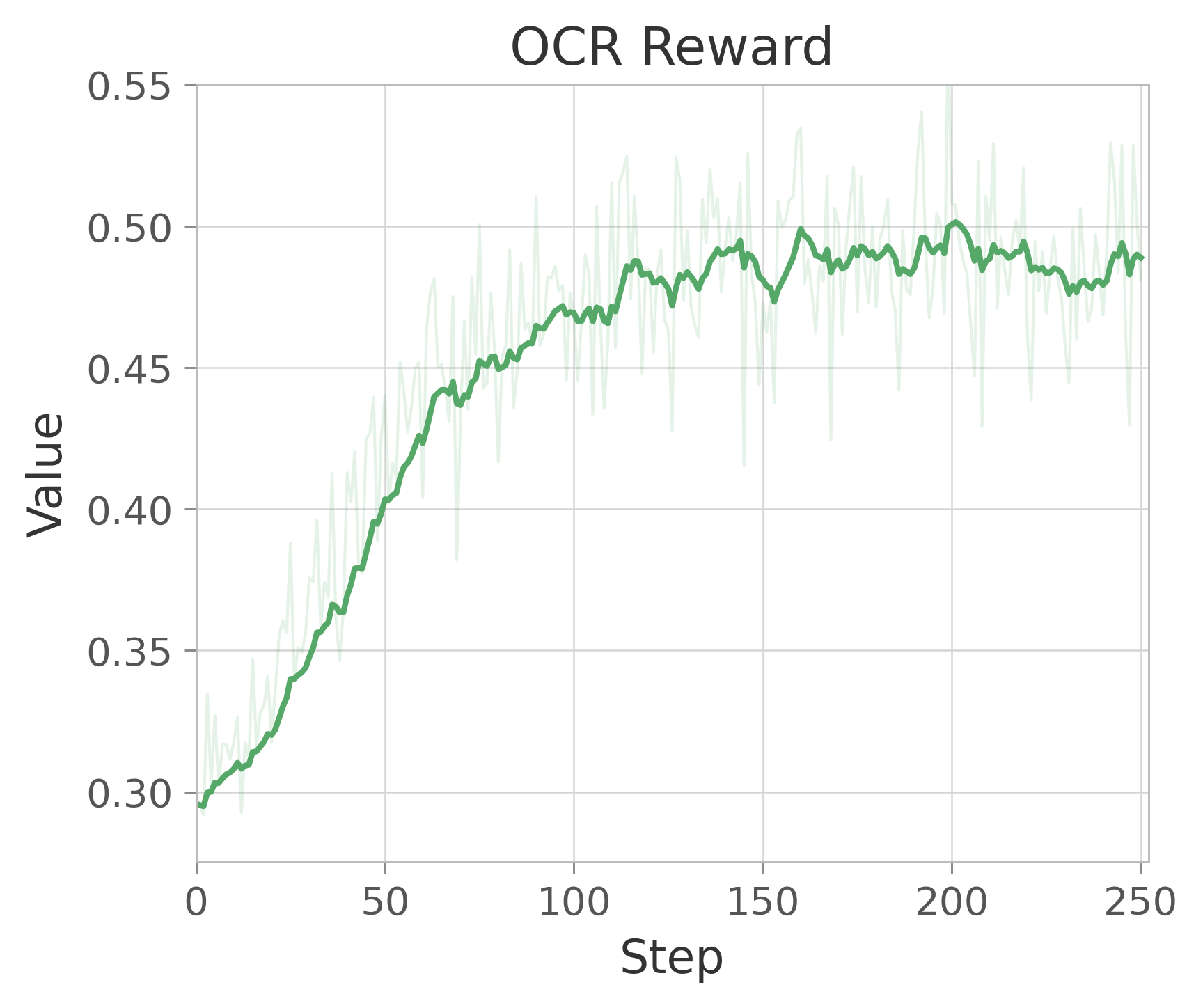
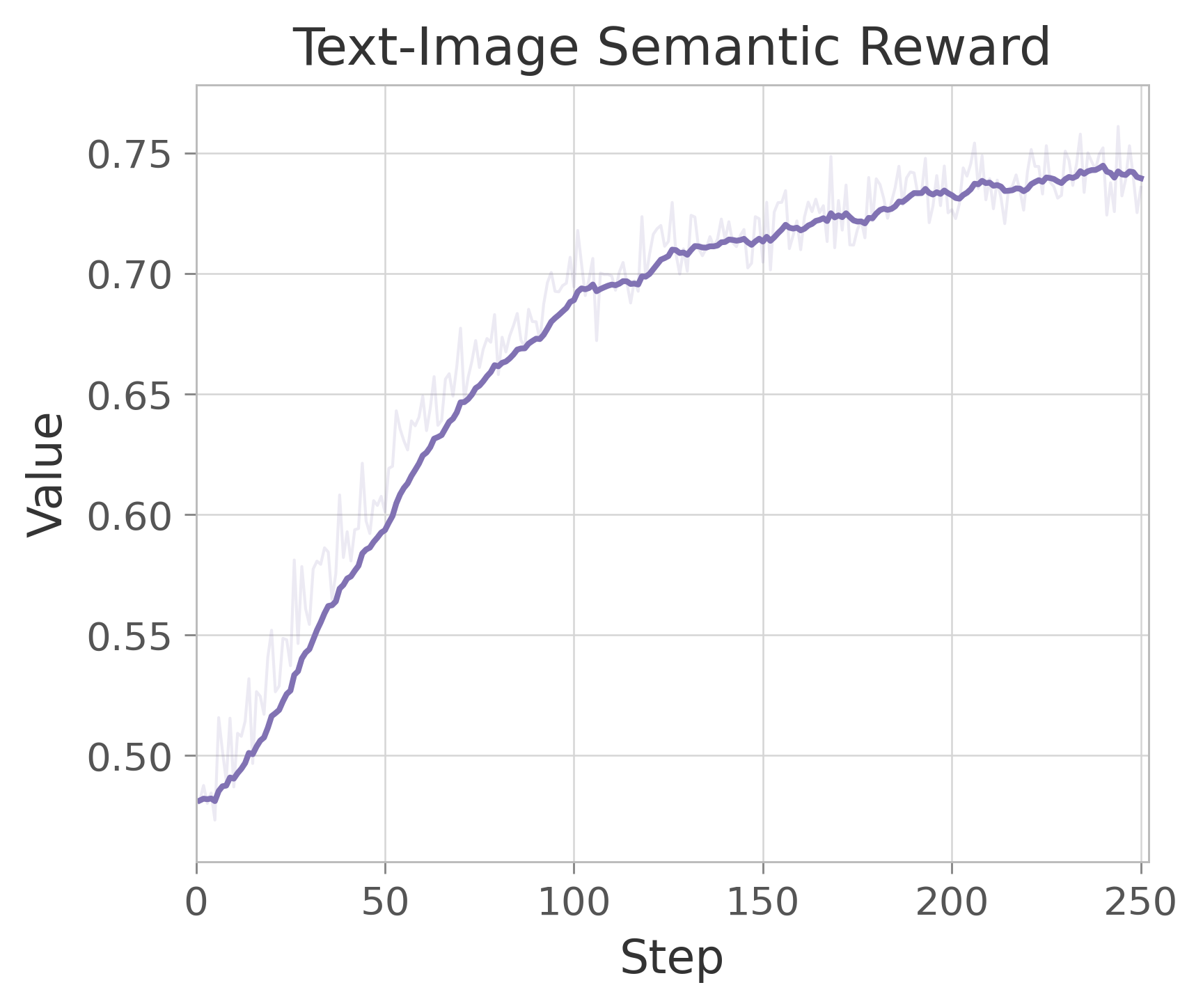
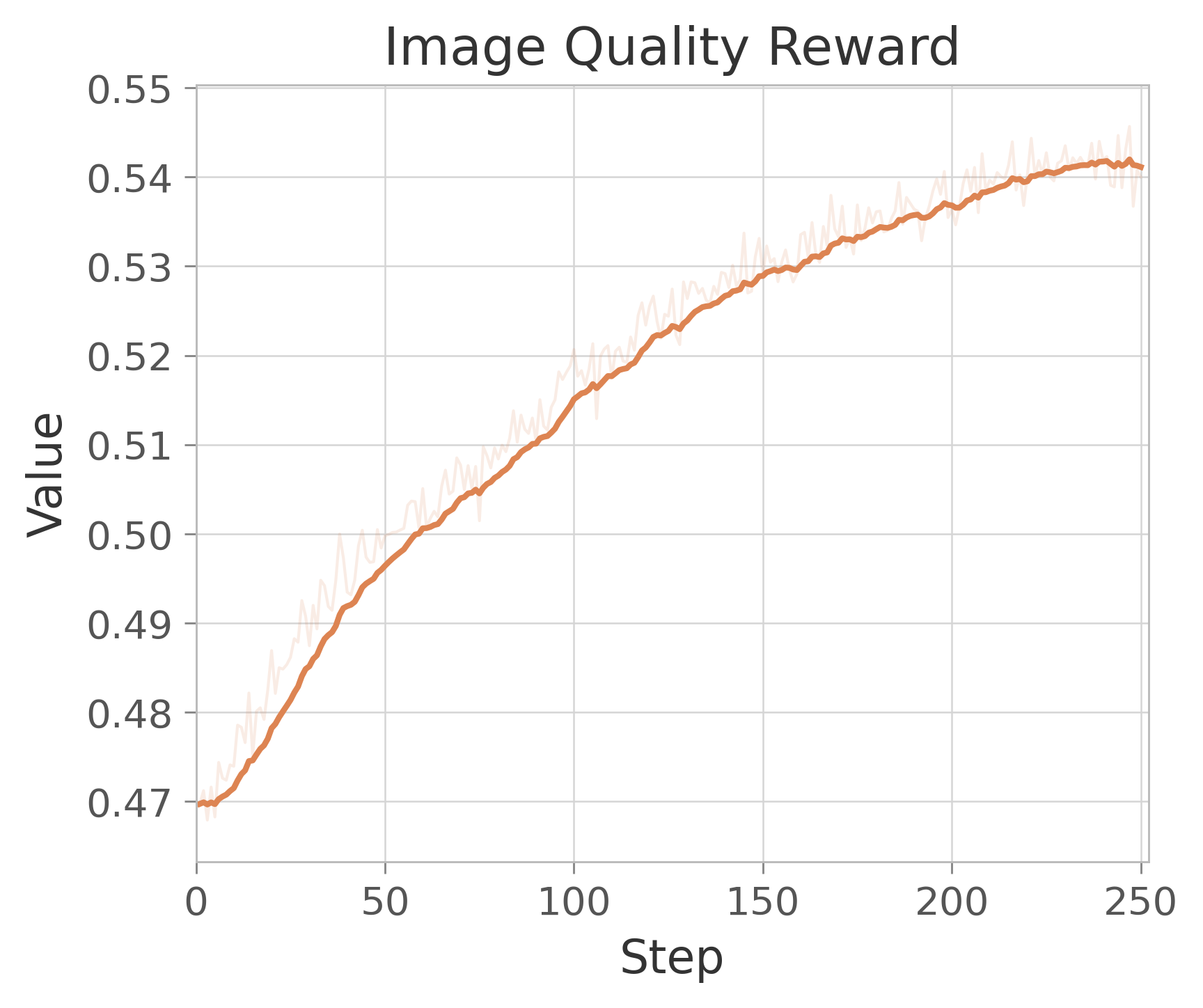
Figure 16: Reward Scores in RL for comprehensive image generation and understanding.
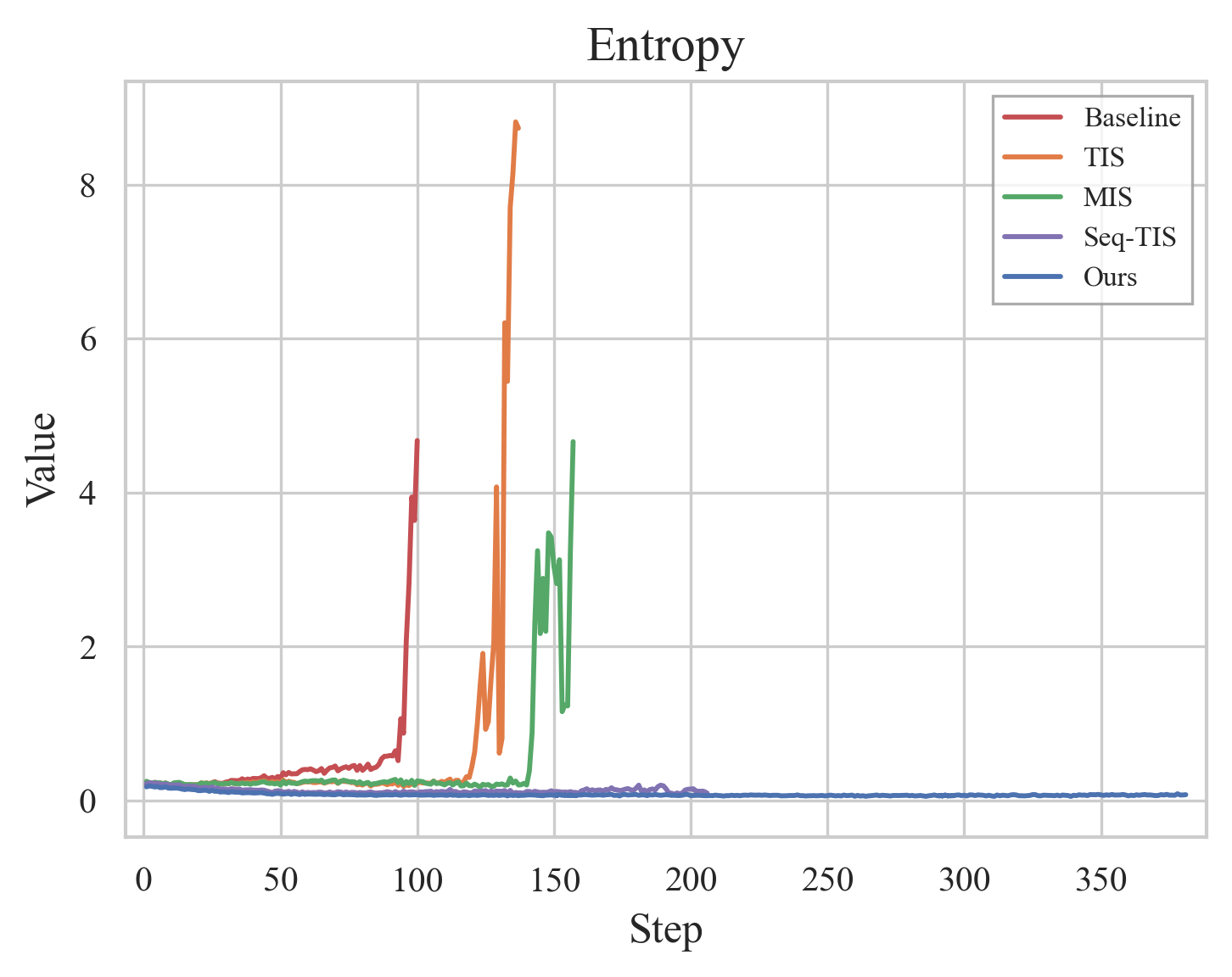
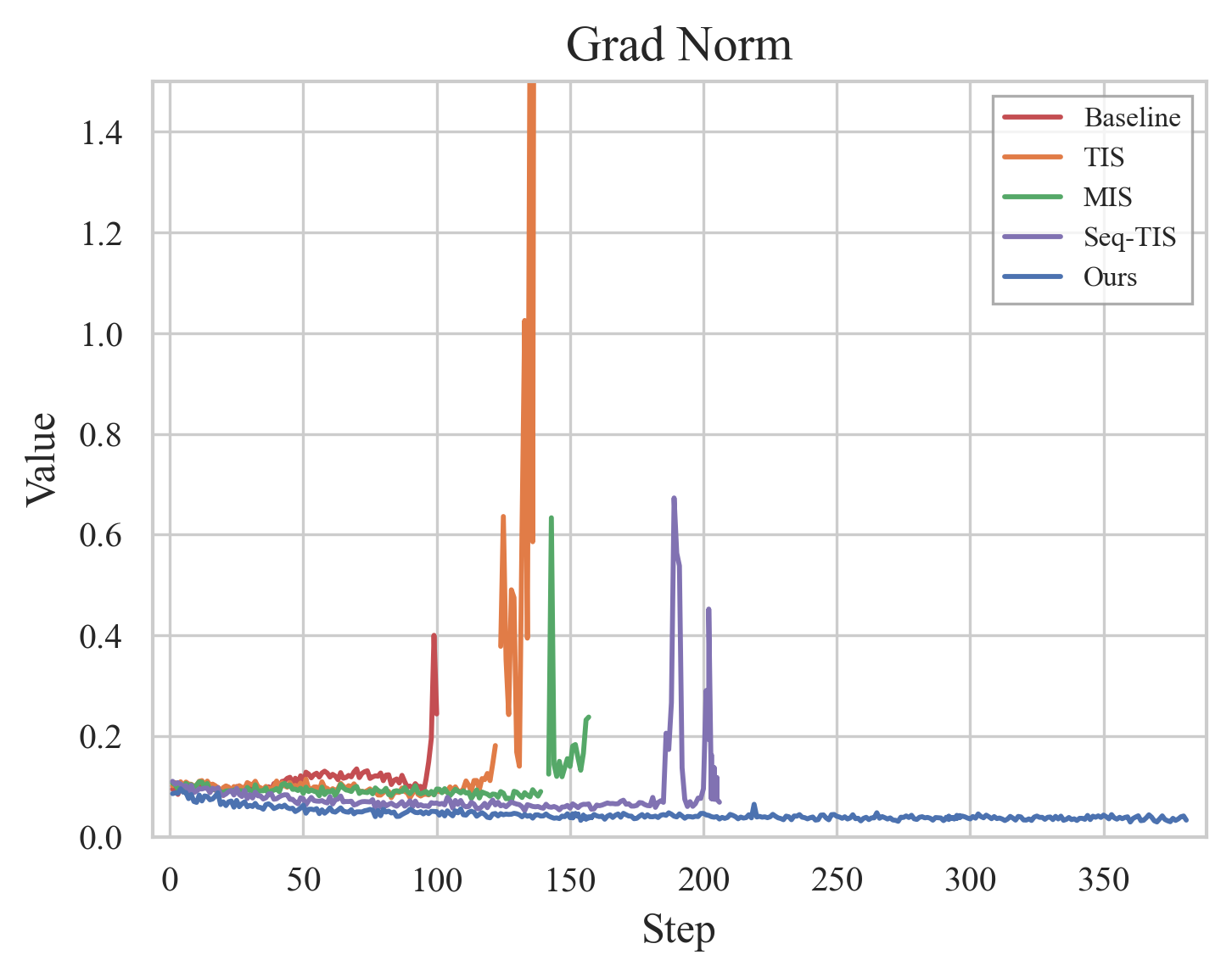
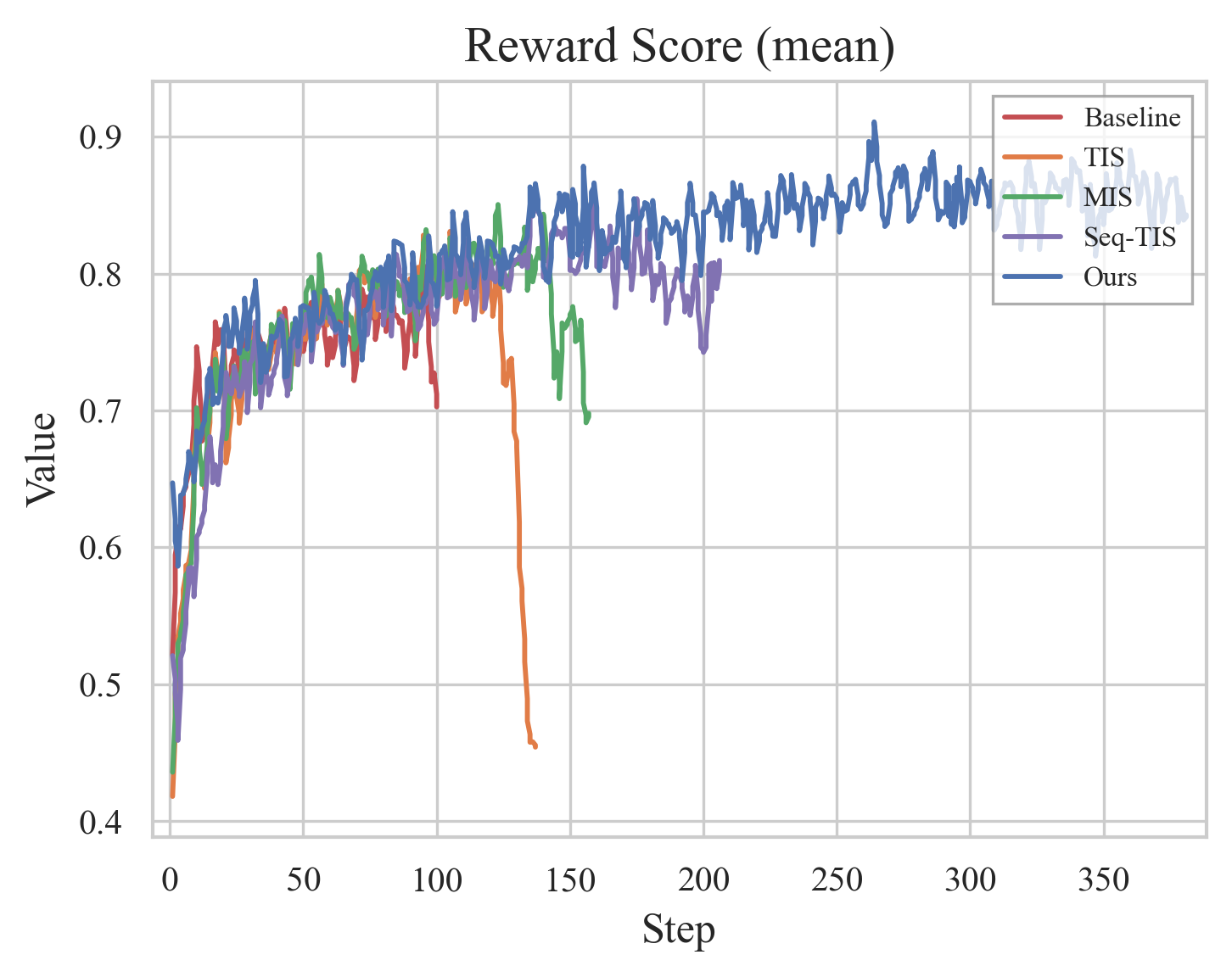
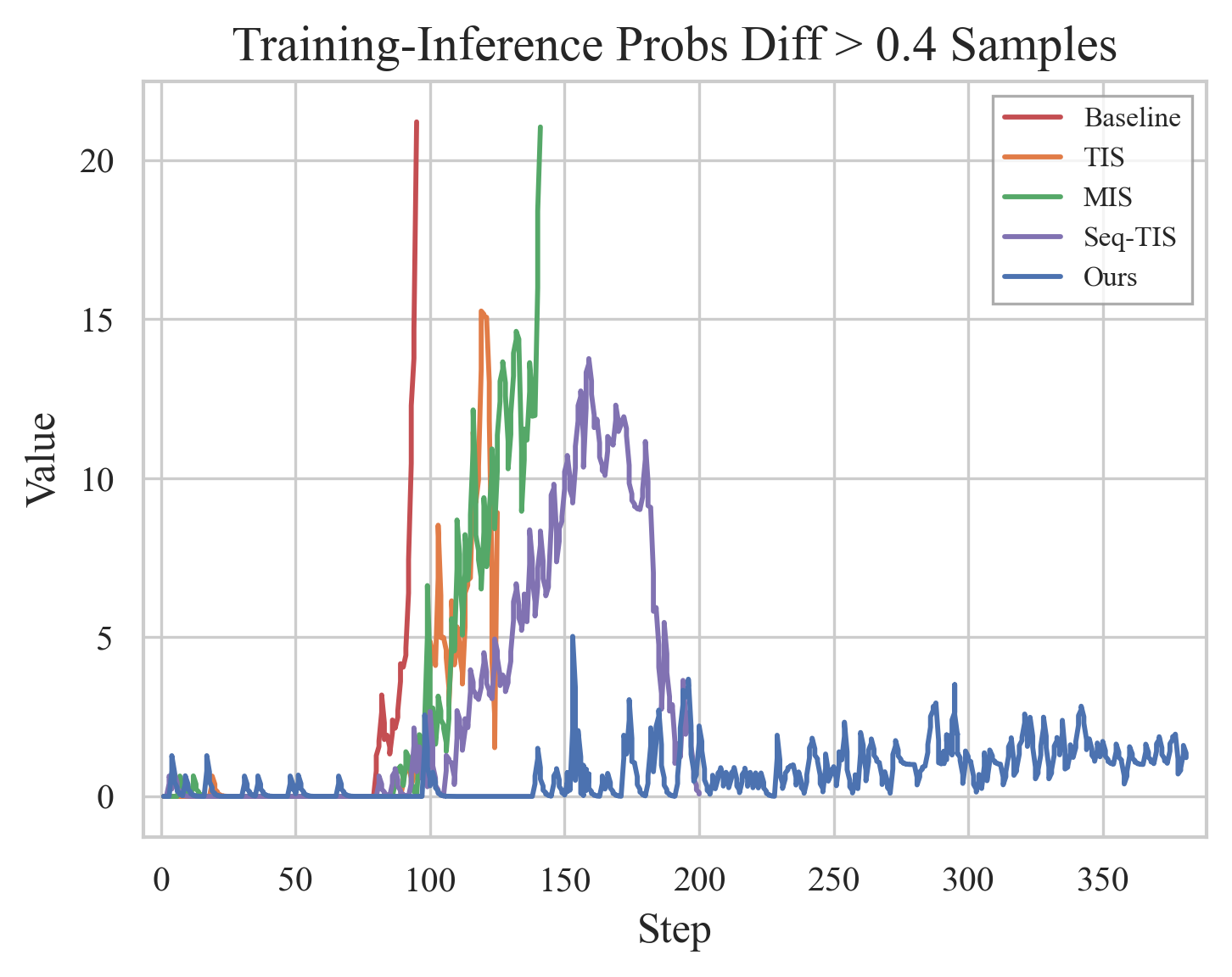
Figure 17: RL training metrics comparison: entropy, gradients, reward.
Methodological Analyses
Ablations validate that RVQ dramatically reduces quantization error, enabling information-preserving visual tokenization. Sequence-level filters in RL stabilize training by discarding outlier samples, and eight-stage RVQ achieves minimal information loss. Qualitative demonstrations confirm OCR formatting and reasoning capabilities, mathematical logic and geometry problem solving, and semantic image reconstruction.
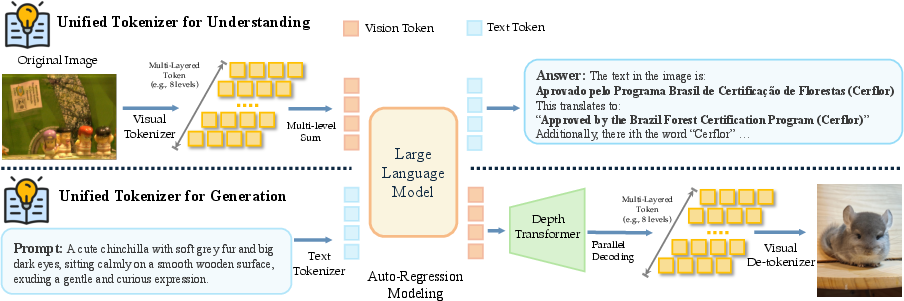
Figure 18: Unified tokenizer/detokenizer for understanding and generation under DiNA.

Figure 19: Formatted outputs and numerical comparisons (OCR phase) enhance interpretability.

Figure 20: Multi-step mathematical reasoning via visual and textual interaction.

Figure 21: Geometric problem solving by decomposing spatial relationships and validating constraints.

Figure 22: Visual de-tokenizer analysis—pixel decoder and refiner jointly recover semantic structure.
Theoretical and Practical Implications
LongCat-Next demonstrates that discrete tokens can suffice for multimodal modeling with minimal performance trade-off, provided semantic completeness is achieved in the tokenizer. The DiNA paradigm lays groundwork for unified multimodal foundation models, offering infrastructure-friendly deployment, robust autoregressive training, and compatibility with RL-based optimization in generation and understanding tasks. Discrete latent spaces naturally serve as RL action spaces, further harmonizing multimodal integration with LLM scaling laws.
Key theoretical implications: modality-agnostic modeling enables cross-modal generalization, and semantic alignment emerges architecturally; practical implications include streamlined deployment, efficient training, and systematic reward-driven capability improvement.
Conclusion
LongCat-Next adopts a principled approach to native multimodality, unifying text, vision, and audio under discrete autoregressive modeling. Empirical results validate strong competitive performance in comprehension, generation, and audio, challenging the assumption of an intrinsic ceiling for discrete vision modeling. This framework points toward scalable, generalist multimodal intelligence and opens new directions for flexible any-to-any generation, semantic representation learning, and interleaved reasoning across modalities. Future work will expand data scaling, co-design of pretraining strategies, and optimizations in semantic tokenization and broader evaluation.

