- The paper introduces an input-side adaptive allocation policy that uses query-specific Beta distributions to efficiently adjust video frame resolution before encoding.
- The paper demonstrates that dynamic cost-aware policy optimization and temporal regularization significantly boost efficiency and accuracy, achieving up to 15% improvement in long-context tasks.
- The paper shows that by saving visual tokens, ResAdapt enables extended temporal coverage and reduces latency by as much as 59.5% compared to baseline methods.
ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning
Scaling Multimodal LLMs (MLLMs) for video reasoning fundamentally challenges current architectures with suboptimal efficiency–accuracy trade-offs. High visual fidelity and long temporal context acquisition dramatically inflate visual token budgets, rendering joint scaling computationally prohibitive. Traditional efficiency solutions—token pruning post-encoding and output-side retrieval—either incur irreversible evidence loss or excessive inference latency, and none preserve native compatibility with optimized attention infrastructures.
ResAdapt directly addresses this bottleneck with input-side adaptation. Instead of compressing or retrieving after expensive pixel encoding, ResAdapt employs an Allocator to predict per-frame visual budget before the backbone encoder processes any input, dynamically resizing each frame. This preserves standard token interfaces and fully leverages high-performance inference kernels.
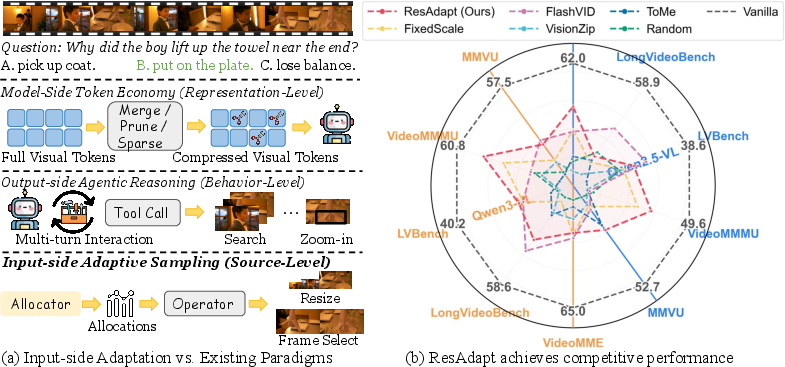
Figure 1: Input-side adaptation shifts efficiency control from post-encoding/model-side or agentic/output-side to the input itself, establishing a new Pareto frontier in visual-token efficiency.
Formally, the system is cast as a contextual bandit: given a query q and video V, the Allocator πθ emits a continuous allocation s, determining spatial resolution for each frame, and applies a visual operator O (typically resizing in this work). The transformed input is then processed by the backbone MLLM policy πϕ. The learning objective is to maximize end-task reward under a strict expectation constraint on visual cost.
Methodology: ResAdapt Pipeline and RL Optimization
The Allocator leverages a lightweight frozen vision encoder and shallow Transformer with temporal self-attention and gated cross-attention to the query. Each frame's allocation is parameterized with a Beta distribution, naturally enforcing bounds and supporting both upscaling and downscaling. This facilitates a fine-grained, query-dependent, per-frame allocation.
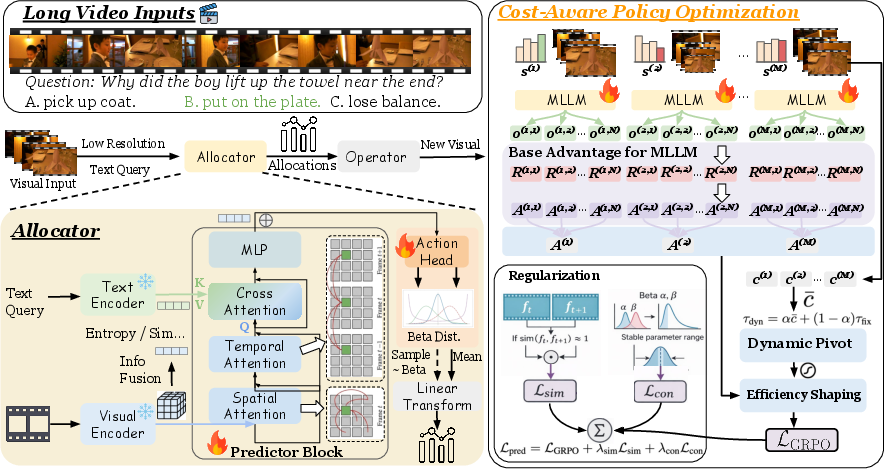
Figure 2: ResAdapt framework overview. Left: Allocator predicts per-frame allocations via Beta variables, applied as input resize factors. Right: CAPO reward shaping and temporal-similarity regularization enhance training stability and selectivity.
Cost-Aware Policy Optimization (CAPO) and Regularization
Direct penalization of visual cost induces policy collapse. CAPO is introduced to avoid this, incorporating:
- Dynamic cost pivoting: Blends prompt-local and global budget baselines for stability and absolute constraint adherence.
- Asymmetric shaping: Bonuses for correct low-cost answers and strong penalties for incorrect high-cost rollouts ensure the policy is incentivized for cost-effective, accurate reasoning, not degenerate minimization of cost.
- Temporal-similarity regularizer: Lsim penalizes redundant budget assignment to temporally adjacent, visually similar frames, driving sparse, selective allocations.
Training alternates PPO-style steps for the Allocator and the backbone, employing rollouts and shaped advantages to drive joint or decoupled optimization.
Experimental Results
Video QA and Temporal Grounding
Empirical evaluation on diverse video reasoning and perception benchmarks demonstrates that ResAdapt achieves superior efficiency–accuracy trade-offs compared to both model-side and output-side baselines. Under aggressive compression (∼10% retention), ResAdapt outperforms token-merging (ToMe), token-pruning (VisionZip), and merged-tree (FlashVid) approaches, especially on reasoning-heavy tasks such as VideoMMMU and LVBench.
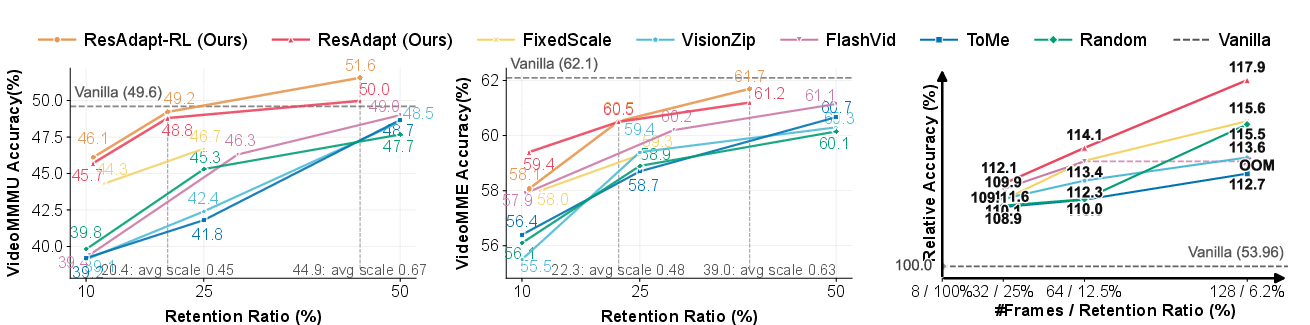
Figure 3: ResAdapt is consistently on or near the Pareto frontier over multiple benchmarks, enabling higher accuracy at lower visual-token retention, especially under low-budget operation.
A notable result is the model’s ability to reinvest spatial budget savings into temporal coverage—ResAdapt at 22.9% retention processes four times as many frames as the uncompressed baseline, leading to >15% absolute accuracy gains on long-context tasks.
Latency and Computational Efficiency
Wall-clock analysis shows that while the Allocator introduces minor fixed front-end overhead, backbone FLOPs savings dominate in the long-context regime. With 64 or 128 frames, ResAdapt reduces end-to-end latency by up to 59.5%, and backbone attention cost scales quadratically with respect to the token reduction, leading to theoretical speedups of more than an order of magnitude in typical operating regions.
Analysis: Policy Behavior and Emergent Active Perception
ResAdapt’s learned allocation policy is highly selective and query-adaptive. It does not follow a simple positional or fixed allocation, but instead detects information-rich frames (e.g., scene changes, overlays, motion) and concentrates resources on them, commonly compressing background or contextually irrelevant frames.
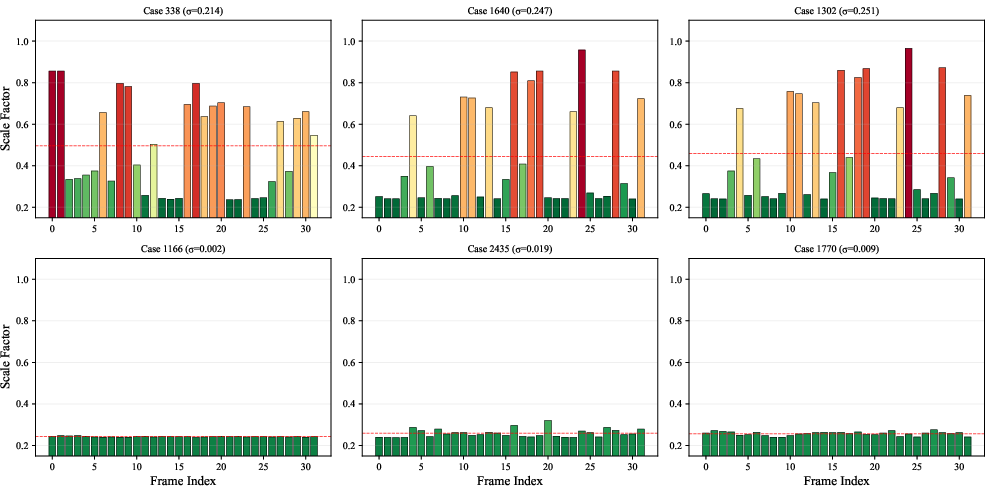
Figure 4: Emergent active perception. Allocation over time is sparse and content-adaptive; high-resolution spikes co-locate with answer-bearing events.
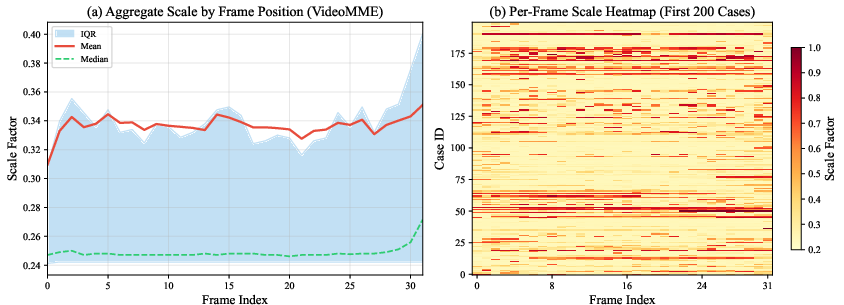
Figure 5: Global scale allocation distribution. High-fidelity allocations manifest as localized bursts without fixed positional bias, emphasizing content-driven selection.
This selectivity is not just empirical: ablation studies confirm that removal of temporal regularization collapses this differentiated behavior into uniform, less effective allocation. Success cases are strongly correlated with concentrated allocation (high Gini coefficient), confirming that accuracy arises from focused visual investment. Error analysis shows robustness but also exposes the limitation that, as an open-loop policy, missed transient cues cannot be recovered if compressed at input.
Generalization to Other Operators and Image Benchmarks
While the main operator is resizing, the learned allocation policy generalizes to frame selection and hybrid selectors, showing higher scores than vanilla subsampling for the same frame budgets. Transfer to static image benchmarks is incomplete: ResAdapt occasionally identifies critical static images, but efficiency gains are inconsistent without retraining.
Theoretical and Practical Implications
The results substantiate several important implications:
- Efficiency–accuracy decoupling: Input-side allocation allows video MLLMs to break the quadratic scaling barrier between spatial and temporal context, enabling long-horizon reasoning previously infeasible under fixed budgets.
- Plug-and-play compatibility: The approach preserves backbone inference optimizations, requiring no kernel modifications, and generalizes across different MLLM architectures.
- Learning over heuristics: Query- and context-conditioned visual token allocation learned via RL offers substantial gains over handcrafted budget rules.
Limitations and Future Directions
Primary limitations include fixed Allocator cost dominating short-context scenarios, reliance on coarse features prone to missing subtle cues, restricted validation to resizing and video tasks, and lack of closed-loop adaptive revision during reasoning. Promising extensions include:
- Integration of motion-aware and multi-scale features
- Hybrid dynamic budget revision during reasoning based on partial backbone feedback
- Expanding to broader multimodal or image-centric tasks with retraining
Conclusion
ResAdapt redefines efficient multimodal reasoning by establishing input-side, RL-driven adaptive resolution allocation as a new efficiency–accuracy paradigm. By directly allocating spatial budget at the pre-encoding stage, MLLMs maintain peak accuracy at an order of magnitude lower visual token budget—immediately translating these savings into extended temporal context and substantial improvements on long-video reasoning tasks. This content-adaptive allocation mechanism outperforms all comparable baselines, both in computational resource efficiency and in emergent behavioral analysis, signaling a critical shift in multimodal model design strategies.
Reference: "ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning" (2603.28610)