Shor's algorithm is possible with as few as 10,000 reconfigurable atomic qubits
Abstract: Quantum computers have the potential to perform computational tasks beyond the reach of classical machines. A prominent example is Shor's algorithm for integer factorization and discrete logarithms, which is of both fundamental importance and practical relevance to cryptography. However, due to the high overhead of quantum error correction, optimized resource estimates for cryptographically relevant instances of Shor's algorithm require millions of physical qubits. Here, by leveraging advances in high-rate quantum error-correcting codes, efficient logical instruction sets, and circuit design, we show that Shor's algorithm can be executed at cryptographically relevant scales with as few as 10,000 reconfigurable atomic qubits. Increasing the number of physical qubits improves time efficiency by enabling greater parallelism; under plausible assumptions, the runtime for discrete logarithms on the P-256 elliptic curve could be just a few days for a system with 26,000 physical qubits, while the runtime for factoring RSA-2048 integers is one to two orders of magnitude longer. Recent neutral-atom experiments have demonstrated universal fault-tolerant operations below the error-correction threshold, computation on arrays of hundreds of qubits, and trapping arrays with more than 6,000 highly coherent qubits. Although substantial engineering challenges remain, our theoretical analysis indicates that an appropriately designed neutral-atom architecture could support quantum computation at cryptographically relevant scales. More broadly, these results highlight the capability of neutral atoms for fault-tolerant quantum computing with wide-ranging scientific and technological applications.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a big question: How soon could a real quantum computer break today’s internet security? The authors show that, with smarter error-correcting codes and a clever machine layout using neutral atoms (single atoms held in place by light), Shor’s algorithm—the famous method for cracking widely used cryptography—might run with as few as around 10,000 physical qubits. With a bit more hardware and smarter scheduling, it could finish important jobs in days, not years.
What are the main goals and questions?
The researchers focus on simple, practical questions:
- How can we shrink the number of physical qubits needed to run Shor’s algorithm on real, important problems like breaking RSA-2048 or ECC P-256?
- Can neutral-atom hardware (which can move qubits around) make error correction and long-range connections easier?
- How fast could such a machine run, given realistic error rates and speeds?
- How much faster can we go if we run many operations in parallel?
How did they approach the problem?
Think of building a skyscraper from Lego where some blocks are fragile. You must:
- pack your rooms smartly,
- install a great safety system,
- organize the elevators so people move efficiently,
- and plan the schedule to avoid jams.
Here’s the translation to quantum computing:
Physical vs. logical qubits
- Physical qubits are the real atoms in the machine.
- Logical qubits are “protected” qubits made by combining many physical ones with error-correcting codes—like a team spelling-checker that catches mistakes so the message stays correct.
High-rate error-correcting codes (packing more into less space)
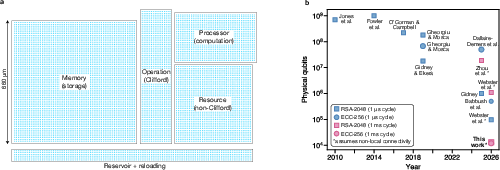
Most previous plans used a popular code (the surface code) that protects well but needs a lot of extra qubits—often hundreds per logical qubit. The authors instead use high-rate “qLDPC” codes that can protect many logical qubits at once with much less overhead (about 30% of the total qubits hold useful data, versus roughly 4% in some older approaches). This cuts total qubits by 10–100× compared to common designs.
A neutral-atom layout with “zones”
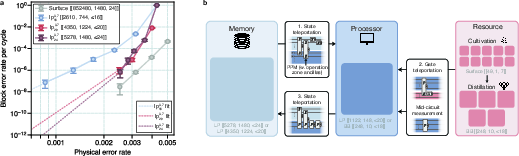
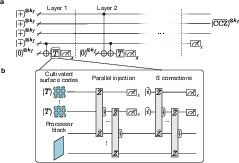
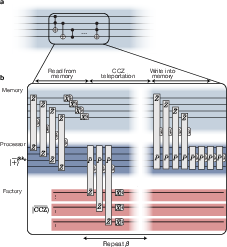
Neutral atoms can be trapped in arrays of light and moved around during the computation. The paper proposes four zones:
- Memory zone: stores most of the data safely.
- Processor zone: does the heavy work.
- Operation zone: helps perform special measurements that apply complex “combined” instructions.
- Resource zone (“magic factory”): makes special states that power the rare, hard gates needed for Shor’s algorithm.
You can picture it like a school campus:
- Library (memory),
- Classrooms (processor),
- Hall monitors and equipment (operations),
- Workshop making special tools (resource factory).
The system “teleports” information (using special measurements) between zones, so the processor can work on bite-sized chunks while the memory keeps everything safe.
Magic states and special gates
Some gates (like the three-qubit Toffoli gate) are hard to do reliably. The machine makes “magic states” in the resource zone and uses them to apply these hard gates through clever measurements—like using a special tool from the workshop when needed instead of building that tool from scratch each time.
Parallelism (doing many things at once)
If you do many independent operations at the same time, you finish much sooner. The authors show that with more qubits (to supply more magic states in parallel and hold temporary helper data), you can cut runtime dramatically.
Modeling, simulations, and assumptions
- They simulate and benchmark their error-correcting codes and decoders and assume realistic error rates per operation (about 0.1% chance of error per basic step) and a 1 millisecond cycle time for measurements and moves.
- They estimate how many qubits, how many steps, and how long Shor’s algorithm would take under different layouts and levels of parallelism.
What did they find, and why does it matter?
In short: the job looks much closer than many thought—especially on neutral-atom hardware.
Here are the headline numbers (all times assume a 1 ms “clock” per cycle):
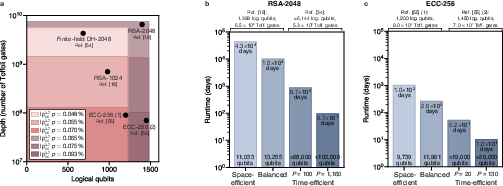
- With about 10,000–13,000 physical qubits:
- You can run Shor’s algorithm at “cryptographically relevant” scales.
- For ECC P-256 (elliptic-curve discrete log), estimated times can be from a few months down to a few weeks depending on the exact layout and circuit details.
- For RSA-2048 factoring, it’s 10–100× slower than ECC because the circuits are deeper (so think many months to years at this small scale).
- With more qubits and parallelism:
- About 26,000 qubits could solve ECC P-256 in around 10 days.
- About 102,000 qubits could factor RSA-2048 in about 97 days.
- Why ECC looks “easier” than RSA:
- ECC uses smaller numbers (256 bits) than RSA-2048’s 2048 bits, so the quantum circuit is much shorter, even though they aim for similar security classically.
- Why neutral atoms help:
- You can move atoms to create long-distance links when needed.
- That makes high-rate codes and “measure-and-teleport” logic practical.
- Recent experiments already show arrays with over 6,000 atoms and below-threshold error rates, so scaling up looks feasible.
- Why the new codes matter:
- The high-rate codes (about 30% data “packing”) cut total qubits by around 10× versus some other recent high-performance designs, and up to 100× versus traditional surface-code-only plans. That’s the difference between “millions of qubits” and “tens of thousands.”
Here’s a compact snapshot:
| Task | Example scale (physical qubits) | Estimated runtime (1 ms cycle) |
|---|---|---|
| ECC P-256 discrete log | ~10k–12k | weeks to months (depends on details) |
| ECC P-256 (parallelized) | ~26k | about 10 days |
| RSA-2048 factoring | ~11k–14k | 10–100× longer than ECC at similar scale |
| RSA-2048 (parallelized) | ~102k | about 97 days |
Note: These are theory-based resource estimates. Real systems could be faster or slower depending on engineering details (like readout speed, motion speed, and error rates).
What are the broader implications?
- Cybersecurity: This work strengthens the case that today’s standard cryptography (RSA and ECC) needs to move to “post-quantum” methods. Agencies are already standardizing new quantum-safe schemes, and this paper adds urgency and a clear path that looks technically achievable.
- Hardware roadmap: Neutral-atom quantum computers appear especially promising for large, error-corrected machines because they can rearrange qubits, connect far-apart parts of the chip, and pack data efficiently with high-rate codes.
- Faster in the future: The authors outline clear ways to cut runtime further—more parallelism, smarter compilers, faster measurements and motion (possibly reducing milliseconds to microseconds), and improved codes. Hours-scale runs for big jobs don’t look impossible in the long term.
- Beyond breaking codes: A machine that can run Shor’s algorithm at this scale could also unlock new science and technology—better materials, chemistry, optimization, and machine learning tasks—because it means thousands of reliable logical qubits running millions to billions of gates.
Bottom line
This study shows a realistic path to running Shor’s algorithm with tens of thousands—not millions—of physical qubits by:
- using high-rate error-correcting codes to pack more useful information per qubit,
- exploiting neutral atoms’ reconfigurability to move qubits and connect distant parts,
- and scheduling many operations in parallel.
It doesn’t claim the machine exists today, but it argues that with focused engineering, the needed hardware is within reach—and that’s a major milestone for both quantum computing and cybersecurity.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unaddressed, written to highlight concrete avenues for future work.
- Error model realism and robustness:
- Quantify performance under hardware-relevant noise (heralded erasures from atom loss, biased Pauli noise, leakage, coherent over-rotations, and spatial/temporal correlations) rather than i.i.d. depolarizing noise; provide erasure-/bias-aware decoding and updated logical error budgets.
- Assess code and surgery thresholds under correlated errors and non-Markovian drift typical for neutral-atom systems.
- Code distance, thresholds, and finite-length scaling:
- Provide certified (or tightly bounded) distances for the selected lifted-product (LP) and bivariate-bicycle (BB) codes at the studied block sizes; current distances are partly inferred from bounds and heuristics.
- Establish accurate thresholds and finite-size scaling for the chosen codes under circuit-level noise with syndrome extraction.
- Decoder performance and deployability:
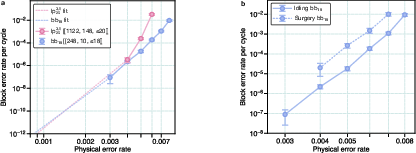
- Demonstrate real-time decoding at millisecond-cycle speeds for blocks with O(103)–O(104) qubits, including latency, throughput, and energy budgets for the localized-statistics/BP decoders.
- Quantify how decoder suboptimality (noted as “decoder-limited”) affects logical error rates and overall algorithm success; benchmark next-generation decoders on the targeted code families and gadgets.
- Extrapolation validity:
- Replace power-law extrapolations of block error rates at low
p(≤0.1%) with direct simulations or hardware experiments; bound uncertainties in the fitted exponents and constants.
- Replace power-law extrapolations of block error rates at low
- Scalable code-surgery constructions:
- Construct and benchmark the full set of required surgery gadgets for
\bar{Z}_i\bar{P}and\bar{X}_jPPMs at the targeted block sizes; quantify actual fault distance, constant factors, and ancilla overhead. - Validate that surgery error rates remain within an order of magnitude of the processor/factory codes when scaled to thousands of logical qubits.
- Construct and benchmark the full set of required surgery gadgets for
- Parallel surgery at scale:
- Demonstrate and characterize hundreds to thousands of concurrent PPMs (as required for the time-efficient architecture with
P≈130–1160) without degrading code distance or introducing cross-gadget crosstalk. - Provide scheduling protocols and conflict-avoidance rules for simultaneous PPMs across memory, processor, and factory zones.
- Demonstrate and characterize hundreds to thousands of concurrent PPMs (as required for the time-efficient architecture with
- Low-weight logical operator synthesis:
- Develop constructive algorithms (and certify results) to obtain low-weight bases for
\bar{Z}/\bar{X}on large LP memory/factory codes (k≈103–103.5), and quantify weight–distance trade-offs.
- Develop constructive algorithms (and certify results) to obtain low-weight bases for
- Magic-state pipeline realism:
- Give an end-to-end throughput analysis for cultivated
Tstates + high-rate8T→CCZdistillation (latency, yield, error, and buffering), and verify that CCZ supply meets steady-state demand for the proposedToff.and parallelismP. - Detail distribution and synchronization mechanisms for delivering distilled
|CCZ⟩states to the processor with low latency and error.
- Give an end-to-end throughput analysis for cultivated
- Surface-code cultivation on neutral atoms:
- Present concrete layouts, timing, and code-switching protocols for running surface-code patches alongside LP/BB blocks, including the error budget for code switching and inter-code teleportation.
- Teleportation and data-movement overheads:
- Quantify the error and latency from repeated memory↔processor↔memory teleportations, including motion-induced decoherence/heating, rearrangement timing, and any extra gates beyond the 2d/3-cycle PPM model.
- Cycle-time assumption:
- Substantiate the assumed 1 ms stabilizer cycle at the required scale with demonstrated fast readout, motion, and reconfiguration; decompose the cycle into measurement, movement, gate, and decoding latencies.
- Laser power and duty-cycle scaling:
- Provide an engineering analysis of the proposed ~1000× increase in active duty cycle via beam rastering (thermal loads, AOM/EOM bandwidths, settling times, beam-pointing jitter, and fidelity impacts).
- High-fidelity entangling operations at scale:
- Demonstrate Rydberg entangling gates with p≲0.07–0.10% across thousands of qubits with uniform performance; quantify spatial nonuniformity and long-range spectator errors in dense arrays.
- Atom loss and continuous reloading:
- Model realistic atom-loss rates over multi-day runs, reloading latency and induced noise, and their integration with active error correction without halting the algorithm; quantify impact on logical failure rates.
- Classical control and feed-forward:
- Show that Pauli frame updates, syndrome processing, and conditional branching fit within sub-millisecond timelines, including controller architecture, bandwidth, and determinism/jitter constraints.
- End-to-end success probability and repeats:
- Produce a comprehensive error budget combining code, surgery, teleportation, magic factories, and mid-circuit measurements to predict per-run success; include the expected number of algorithm repeats (e.g., for order finding).
- Algorithm-to-architecture mapping:
- Compile the full ECC-256 and RSA-2048 circuits onto the proposed processor codes to obtain actual
(m_i, β_i, γ_i)distributions; verify the amortizedToff.per the real schedule rather than heuristic estimates.
- Compile the full ECC-256 and RSA-2048 circuits onto the proposed processor codes to obtain actual
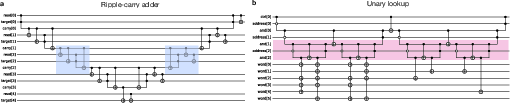
- Carry-lookahead adder (CLA) realization:
- Provide resource-accurate CLA designs (ancilla counts, logical connectivity, measurement cadence) on the processor code and quantify how they constrain achievable parallelism
Pand ancilla-zone size.
- Provide resource-accurate CLA designs (ancilla counts, logical connectivity, measurement cadence) on the processor code and quantify how they constrain achievable parallelism
- Memory coherence and long-run drift:
- Measure and mitigate clock-state dephasing, light-shift-induced phase noise, and calibration drift over days with frequent atom motion; specify dynamical decoupling schedules and overheads.
- Crosstalk and blockade spillover:
- Quantify spatial spillover during high-throughput Rydberg gates in densely packed zones and its effect on concurrent surgeries, factories, and idling qubits.
- Operation-zone scaling:
- Reassess the 10–20% ancilla-zone overhead under time-efficient parallelization; provide explicit scaling laws of ancilla count vs processor/memory sizes and
P, and validate feasibility within 26k/102k-qubit budgets.
- Reassess the 10–20% ancilla-zone overhead under time-efficient parallelization; provide explicit scaling laws of ancilla count vs processor/memory sizes and
- Scheduler and routing:
- Develop and benchmark global schedulers for movement, raster patterns, syndrome extraction, and magic factories to avoid deadtime and collisions; provide performance guarantees.
- Reproducibility of LP constructions:
- Publish the LLM-assisted seed matrices and verification scripts; certify distances and stabilizer weights for the reported codes and characterize variance across instances.
- Comparison normalization:
- Normalize resource comparisons with prior work to a common cycle time and noise model to isolate the benefits of high-rate codes vs hardware assumptions.
- Broader cryptographic coverage:
- Extend resource estimates to additional curves and key sizes (e.g., Curve25519, P-384, larger RSA moduli) and analyze scaling bottlenecks under the proposed architecture.
Practical Applications
Overview
This paper introduces a practical neutral‑atom architecture and compilation toolchain that, under plausible hardware assumptions, reduces the qubit requirements for cryptographically relevant instances of Shor’s algorithm to as few as ~10,000 physical qubits. By combining high‑rate qLDPC codes (~30% encoding rate), code‑surgery based Pauli‑product measurements, and high‑rate magic‑state distillation, the authors outline space‑efficient and time‑efficient configurations that could break ECC‑P256 in days with ~26,000 qubits and RSA‑2048 in months with ~102,000 qubits (assuming ~1 ms cycle times and scalable parallel surgery). These methods generalize to other algorithms, suggesting a broad path to fault‑tolerant neutral‑atom quantum computing.
Below are the practical applications that follow from the paper’s findings. Each item names sectors, concrete use cases, potential tools/products/workflows, and the key assumptions/dependencies that govern feasibility.
Immediate Applications
The following can be pursued now using current capabilities, prototypes, and near‑term engineering work.
- Quantum risk assessment and PQC migration acceleration (policy, finance, healthcare, government, software)
- Use case: Update enterprise/government quantum‑risk models to reflect that ECC (e.g., P‑256) is likely to be broken earlier than RSA under neutral‑atom roadmaps; prioritize migration of ECC‑dependent systems (TLS, code signing, mobile payments, blockchains) to NIST‑standardized post‑quantum algorithms.
- Potential tools/products/workflows:
- Organization‑wide crypto inventories and crypto‑agility playbooks.
- Hybrid key exchange/signatures (e.g., X25519+Kyber; RSA/ECDSA+Dilithium) in TLS, VPNs, code‑signing, firmware updates.
- Risk dashboards that model “record‑now, decrypt‑later” exposure and re‑keying plans.
- Assumptions/dependencies:
- Adoption of FIPS 203/204/205 standards.
- Integration support from OS vendors, browsers, and cloud KMS/HSMs.
- Leadership buy‑in to shorten cryptoperiods and rotate keys.
- Compliance and standards modernization (policy, industry)
- Use case: Embed quantum risk in procurement, audit, and certification frameworks (e.g., require PQC‑ready stacks and crypto‑agility in RFPs; extend PCI‑DSS, HIPAA, FedRAMP, ISO 27001 controls to include PQC).
- Potential tools/products/workflows:
- Conformance test suites for hybrid and PQC‑only protocols.
- Certification profiles that measure “cycles‑per‑Toffoli” risk proxy and key exposure timelines.
- Assumptions/dependencies:
- Timely guidance from NIST, ETSI, IETF; vendor roadmaps for PQC hardware modules.
- Hardware R&D roadmaps for neutral‑atom FTQC (hardware, photonics, academia)
- Use case: Align experimental milestones with the paper’s four‑zone architecture (memory, processor, operation, magic factory) and 1 ms cycle‑time target; plan scaling to 10k–30k qubits.
- Potential tools/products/workflows:
- High‑duty‑cycle beam rastering modules; scalable Rydberg gate optics; fast readout subsystems.
- Trap arrays and vacuum modules scaled to 10k+ atoms; qubit‑loss mitigation with continuous reload.
- Assumptions/dependencies:
- Achieving 0.07–0.1% physical error rates and ~d≈20 code distances.
- Laser power, thermal management, and beam steering that support high‑fidelity parallel ops.
- High‑rate QEC software stack (software, academia, cloud)
- Use case: Build open toolchains that target high‑rate qLDPC codes and code‑surgery gateways for Pauli‑product measurements and magic consumption.
- Potential tools/products/workflows:
- Libraries for LP/BB code families with belief‑propagation+localized‑statistics decoders.
- Surgery gadget compilers; schedulers for sequential and batched PPMs; “Toffoli‑throughput” profilers.
- Integration with Qiskit/Cirq/PennyLane backends and neutral‑atom error models.
- Assumptions/dependencies:
- Decoder performance near simulated levels; stable APIs to hardware control stacks.
- Benchmark suites for cryptographically relevant workloads (academia, cybersecurity, finance)
- Use case: Establish community benchmarks that report Toffoli count/depth, PPM scheduling, and success probability vs. code distance/error rates for ECC‑256 and RSA‑2048 circuits.
- Potential tools/products/workflows:
- Reference circuits (ripple‑carry and carry‑lookahead adders, unary LUTs) with neutral‑atom timing models (1 ms cycle).
- Public leaderboards and reproducible experiment harnesses.
- Assumptions/dependencies:
- Agreement on noise models (depolarizing+erasure/bias) and logical error extrapolation methods.
- Experimental testbeds for surgery and high‑rate magic (academia, vendors)
- Use case: Demonstrate on hundreds–thousands of qubits: (i) sequential PPMs with code surgery, (ii) cultivation + 8T→CCZ distillation pipelines, (iii) teleportation between memory and processor codes.
- Potential tools/products/workflows:
- Calibrated “operation zone” ancilla layouts; metrology of per‑cycle block error rates.
- Assumptions/dependencies:
- Sustained below‑threshold operation; validated gadget fault distances; magic factory yield matching compile‑time plans.
- Optical/photonics supply‑chain mobilization (photonics, manufacturing)
- Use case: Develop productized beam‑rastering controllers, scalable high‑power lasers, metasurface optics for large tweezer arrays, and fast detectors optimized for 1–10 μs readout R&D.
- Potential tools/products/workflows:
- Modular optical racks with field‑replaceable subassemblies and diagnostics.
- Assumptions/dependencies:
- Reliability and cost curves enabling multi‑kW optical budgets; thermal stability.
- Education and workforce development (academia, industry)
- Use case: Train engineers in high‑rate QEC, neutral‑atom control, compilation for PPM‑centric logic, and PQC migration engineering.
- Potential tools/products/workflows:
- Courses, summer schools, and certification programs; open‑source curriculum on qLDPC and code surgery.
- Assumptions/dependencies:
- Sustained funding; partnerships across universities, vendors, and standards bodies.
- End‑user security hygiene and crypto‑agility (daily life, SMEs)
- Use case: Encourage updates that enable PQC/hybrid modes (OS, browsers, VPN clients), faster patch cycles, and shorter certificate lifetimes to mitigate “record‑now, decrypt‑later.”
- Potential tools/products/workflows:
- PQC‑capable passwordless authentication; automated certificate renewal with hybrid signatures.
- Assumptions/dependencies:
- Vendor support for hybrid TLS/signing; enterprise MDM/IT readiness to deploy at scale.
Long‑Term Applications
These require additional research, scaling, or ecosystem development beyond current prototypes.
- Authorized quantum cryptanalysis services and red‑team platforms (cybersecurity, government, finance)
- Use case: Regulated offerings to assess legacy ECC/RSA system risk pre‑migration, validate PQC deployments, and support incident investigations.
- Potential tools/products/workflows:
- “Cycles‑per‑Toffoli” SLAs; secure enclaves for sensitive inputs; audit trails and legal/regulatory governance.
- Assumptions/dependencies:
- Availability of 10k–100k‑qubit neutral‑atom systems with ~1 ms cycles and parallel surgery; strict legal/ethical frameworks.
- Quantum cloud backends built on high‑rate qLDPC (cloud, software)
- Use case: General‑purpose FTQC services exposing PPM‑centric logical instruction sets and magic‑factory capacity as schedulable resources.
- Potential tools/products/workflows:
- Compilers that map subcircuits into “processor zones” and orchestrate teleportation; batch‑PPM APIs; usage‑based billing tied to Toffoli‑depth and code distance.
- Assumptions/dependencies:
- Robust remote operation with continuous reloading and error‑budget monitoring; mature orchestration software.
- Domain accelerators: chemistry, materials, optimization, finance (pharma, energy, manufacturing, finance)
- Use case: Apply the same architecture to algorithms with heavy non‑Clifford content (e.g., phase estimation, qubitization, quantum Monte Carlo) once logical qubits and throughput scale.
- Potential tools/products/workflows:
- Vertical solution stacks (problem formulation → logical circuits → PPM schedules → execution).
- Assumptions/dependencies:
- Algorithm‑level optimizations comparable to cryptanalysis circuits; improved decoders and parallelism.
- Modular neutral‑atom FTQC hardware (hardware, manufacturing)
- Use case: Rack‑scale systems with 10k–100k+ reconfigurable qubits, zoned layouts, high‑duty‑cycle addressing, μs‑scale readout, and continuous qubit reload.
- Potential tools/products/workflows:
- Standardized zone modules; beam‑rastering firmware; fast motion control with constant‑velocity transport.
- Assumptions/dependencies:
- Engineering integration of lasers, control, and vacuum; reliability and maintenance at data‑center scale.
- Advanced compilers and EDA‑like toolchains (software)
- Use case: Automated selection of ripple‑carry vs. carry‑lookahead adders, batched PPM scheduling, single‑shot surgery/code‑switching, and transversal‑gate opportunities.
- Potential tools/products/workflows:
- Cost models that optimize “cycles per Toffoli” under hardware constraints; verified gadget libraries with machine‑learned decoders.
- Assumptions/dependencies:
- Demonstrated single‑shot surgery and scalable parallel PPMs; stable, measurable hardware costs.
- Decoder accelerators (semiconductors, hardware)
- Use case: ASIC/FPGA accelerators for belief‑propagation + localized‑statistics decoding with low latency to support higher cycle rates and larger blocks.
- Potential tools/products/workflows:
- PCIe or embedded modules co‑located with experiment control; firmware for adaptive syndrome processing.
- Assumptions/dependencies:
- Decoder algorithms with predictable memory/computation footprints and hardware‑friendly primitives.
- Sector‑wide crypto transitions (finance/crypto, IoT/healthcare, automotive)
- Use case: Mass re‑keying of PKI, firmware signing, secure boot, and blockchain signatures to PQC (e.g., Dilithium, Falcon), including hard forks and migration bridges.
- Potential tools/products/workflows:
- Asset migration windows for blockchains; OTA updates for medical/industrial/automotive devices; post‑quantum secure boot chains.
- Assumptions/dependencies:
- PQC size/performance fit within device constraints; consensus and governance for blockchain transitions.
- National initiatives and consortia testbeds (government, academia, industry)
- Use case: Joint programs to build 10k–100k‑qubit neutral‑atom testbeds, share code/decoder IP, and validate benchmarks for cryptanalysis and science use cases.
- Potential tools/products/workflows:
- Shared facilities and open datasets; workforce pipelines; coordinated standards input.
- Assumptions/dependencies:
- Multi‑year funding; IP frameworks enabling collaboration.
- End‑to‑end “quantum build systems” for secure algorithm deployment (software, cybersecurity)
- Use case: Tooling that transforms high‑level specs into verified logical circuits, allocates magic‑factory budgets, schedules PPMs, and produces attestable execution artifacts.
- Potential tools/products/workflows:
- Provenance and reproducibility layers; security policies that constrain gadget choices and parallelism levels.
- Assumptions/dependencies:
- Formal verification methods for gadget fault distances and compiler correctness.
- Hardware‑level speedups enabling hour‑scale runtimes (hardware, photonics)
- Use case: Push toward μs‑scale cycle times via faster readout and transport, yielding order‑of‑magnitude runtime reductions beyond the 1 ms baseline.
- Potential tools/products/workflows:
- Photodetector/optical upgrades; motion systems with constant‑velocity transport and minimal idle.
- Assumptions/dependencies:
- Integration into FTQC with full entropy removal; preservation of error rates under higher speeds.
Cross‑cutting assumptions and dependencies from the paper
- Physical error rates at or below ~0.07–0.1% with cycle times ~1 ms; code distances ~d≈20 and per‑cycle block error rates ~10⁻¹¹ for target blocks.
- High‑rate qLDPC codes (~20–30% encoding rates) with performant decoders; surgery gadgets whose fault distances track processor/factory code distances.
- Scalable parallel surgery for batched PPMs and CCZ consumption; magic‑state cultivation and 8T→CCZ distillation with yield and error budgets matching compile‑time plans.
- Neutral‑atom hardware with reconfigurable connectivity, high‑duty‑cycle addressing, sufficient laser power, continuous reload, and large trap arrays (10k–100k qubits).
- Continued algorithmic/circuit advances (carry‑lookahead adders, batched/single‑shot surgery, transversal gates) and improved hardware (readout/motion) to reach days‑to‑hours runtimes.
These applications translate the paper’s architectural and algorithmic results into concrete next steps for industry, academia, policymakers, and everyday users.
Glossary
- Ancillary qubits: Extra helper qubits used to implement fault-tolerant measurements or operations without storing algorithmic data. "The operation zone is comprised of ancillary qubits used to perform Clifford logical Pauli product measurements (PPMs)"
- Belief propagation and localized statistics decoder: A decoding algorithm combining message-passing (BP) with local statistical heuristics to infer error syndromes in LDPC codes. "decode with a customized belief propagation and localized statistics decoder"
- Bivariate bicycle code: A family of quantum LDPC codes constructed from bivariate polynomials that provide good rates and distances at modest block sizes. "a $[[248, 10, \ bivariate bicycle code~\cite{liang2025generalized}, denoted$"
- Block error rates (per cycle): The probability that any logical qubit in a code block fails during one round of error-correction cycles. "Block error rates per cycle for several lifted product codes and surface codes."
- Carry-lookahead adder: A parallel adder circuit that reduces depth by computing carry bits in a tree-like fashion, enabling faster quantum arithmetic. "carry-lookahead adders~\cite{draper2004logarithmic}"
- CCZ (state): A three-qubit non-Clifford resource (controlled-controlled-Z) often distilled from T states and used to implement Toffoli-class logic. "We use high-rate $8T$-to-CCZ distillation"
- Clifford operations: The subgroup of quantum gates (e.g., H, S, CNOT) that map Pauli operators to Pauli operators and are efficiently classically simulable. "Clifford operations can in principle be implemented directly on a large qLDPC block"
- Code distance: A code parameter indicating the minimum weight of a logical operator; it bounds how logical error rates scale with physical noise. "where is the processor code distance."
- Code surgery: A fault-tolerant technique that measures joint logical operators between codes or code regions to implement gates and teleportation. "these PPMs can be implemented using standard code surgery techniques"
- Depolarizing noise: A noise model where qubits randomly undergo Pauli errors with a fixed probability, modeling uniform decoherence and gate imperfections. "experience depolarizing noise with error rate "
- Diffie–Hellman (DH–2048): A discrete-log-based key exchange benchmark (2048-bit finite field) used to assess cryptanalytic performance of quantum algorithms. "finite-field \mbox{DH--2048}~\cite{chevignard2025reducing}"
- Elliptic-curve cryptography (ECC–256): A cryptographic scheme based on elliptic-curve discrete logarithms at a 256-bit security level; a quantum-breaking benchmark. "elliptic-curve cryptography with 256-bit keys (ECC--256)."
- Encoding rate: The fraction of physical qubits that encode logical qubits (k/n); higher rates reduce qubit overhead for error correction. "encoding rates of approximately "
- Fault-tolerant quantum computers (FTQCs): Architectures that reliably execute arbitrarily long quantum computations by correcting errors below a threshold. "fault-tolerant quantum computers (FTQCs)"
- Gate teleportation: Implementing a non-Clifford gate by consuming a prepared magic state and performing Pauli product measurements with corrective feedback. "arising from -gate teleportation"
- Heralded atom loss: An erasure-like error where loss events are detected (heralded), enabling targeted recovery strategies in neutral-atom devices. "\,50\% of errors due to heralded atom loss"
- High-rate quantum low-density parity-check (qLDPC) codes: Quantum codes with sparse checks and relatively large k/n that protect many logical qubits in one block. "high-rate quantum low-density parity check (qLDPC) codes"
- Lifted-product (LP) codes: A construction of qLDPC codes from products of classical codes over polynomial rings, yielding good distance and structure. "lifted product codes"
- Logical qubit: An error-corrected qubit encoded across many physical qubits that stores quantum information robustly. "hundreds of physical qubits to encode a single logical qubit"
- Magic state: A specially prepared non-stabilizer state (e.g., T or CCZ) consumed to realize non-Clifford gates fault-tolerantly. "The resource zone generates magic states"
- Magic state cultivation: Producing high-fidelity magic states by preparing them in surface-code patches before distillation. "using surface-code cultivation"
- Magic state distillation: A protocol that purifies noisy magic states into fewer, higher-fidelity ones using fault-tolerant circuits. "We use high-rate $8T$-to-CCZ distillation"
- Nonlocal connectivity: The ability to entangle or measure qubits across large distances in a processor, enabling high-rate codes and transversal operations. "nonlocal connectivity"
- Pauli-based computation: A model where Clifford gates are commuted and absorbed, and computation proceeds via sequences of Pauli product measurements. "Pauli-based computation"
- Pauli product measurement (PPM): A joint measurement of a multi-qubit Pauli operator (e.g., Z⊗X⊗Z) used for teleportation and gate implementation. "Pauli product measurements (PPMs)"
- Rydberg states: Highly excited atomic states enabling strong, controllable interactions for entangling neutral-atom qubits. "excitation to Rydberg states"
- Stabilizer measurement cycle: A repeated round of measuring X- and Z-type checks to detect and correct errors in stabilizer codes. "we assume a 1\,ms stabilizer measurement cycle."
- Stabilizer weight: The number of qubits a stabilizer acts on; higher weight generally implies more entangling gates per check measurement. "the stabilizer weight is related to how many entangling gates are needed for stabilizer measurements."
- Surface code: A topological stabilizer code with local checks on a 2D lattice, widely used for fault-tolerant architectures. "surface codes"
- Threshold (error-correction threshold): The physical error rate below which increasing code distance suppresses logical errors exponentially. "below the error-correction threshold"
- Teleportation (logical/state): Moving a logical state between code blocks by measuring joint logical operators and applying Pauli corrections. "The logical qubits are teleported from the memory code to the processor code"
- Toffoli count: The total number of Toffoli gates in a circuit, often dominating runtime in fault-tolerant resource estimates. "the total runtime is proportional to the Toffoli count of the algorithm"
- Toffoli gate: A three-qubit controlled-controlled-NOT gate that is non-Clifford and typically implemented via magic states. "Each Toffoli gate requires approximately stabilizer measurement cycles"
- Transversal gates: Gates applied qubit-wise across code blocks that preserve code structure and avoid spreading errors within a block. "the use of transversal gates"
- Unary lookup table: A technique that replaces arithmetic with table-based operations indexed by unary-encoded values to reduce Toffoli depth. "unary lookup table"
Collections
Sign up for free to add this paper to one or more collections.