- The paper introduces PSPA-Bench, a structured benchmark that leverages Task Decomposition Graphs to encode both fixed and preference-sensitive GUI tasks for personalized evaluation.
- The paper demonstrates that fine-grained metrics such as APR (ρ=0.95, MSE=0.005) align closely with human judgments, underscoring the framework’s reliability.
- The paper highlights the critical role of persistent memory and self-evolution in smartphones, enabling agents to improve both immediate and long-term personalization performance.
PSPA-Bench: A Principled Benchmark for Personalization in Smartphone GUI Agents
Smartphone GUI agents, which emulate user actions directly on mobile application interfaces, are increasingly poised to deliver highly individualized task automation. Unlike system-level voice assistants that rely on fixed APIs, GUI agents must adapt to the rich diversity of user workflows, preferences, and evolving needs. However, current benchmarks predominantly evaluate generic task execution, neglecting both the scarcity of personalized user data and the lack of process-oriented, fine-grained evaluation metrics. PSPA-Bench addresses this gap by introducing a structured framework to systematically study and quantify the personalization capabilities of smartphone GUI agents.
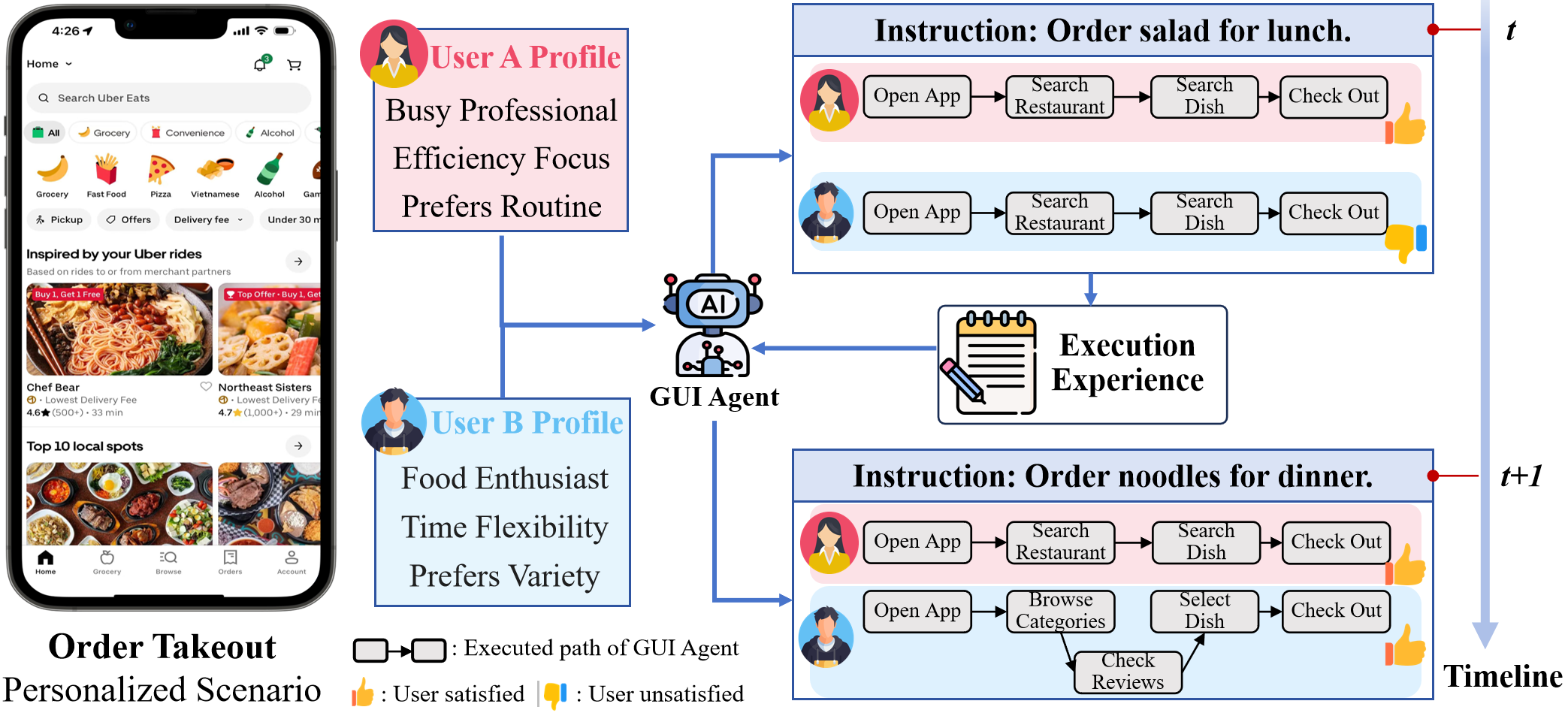
Figure 1: GUI agents are transitioning from generic, one-shot execution to long-term, personalized service models based on user preferences and historical execution context.
Benchmark Framework
PSPA-Bench employs Task Decomposition Graphs (TDGs) to explicitly encode the hierarchical structure of GUI tasks at the unit-instruction level, separating universal steps (fixed nodes) from preference-sensitive operations (flexible nodes). This abstraction supports two core functionalities: adaptive generation of task templates for realistic, user-specific instruction synthesis, and trace-graph alignment for evaluation along immediate and long-term objectives. TDGs enable personalization even in the absence of large-scale user logs, and facilitate process-level progress tracking.
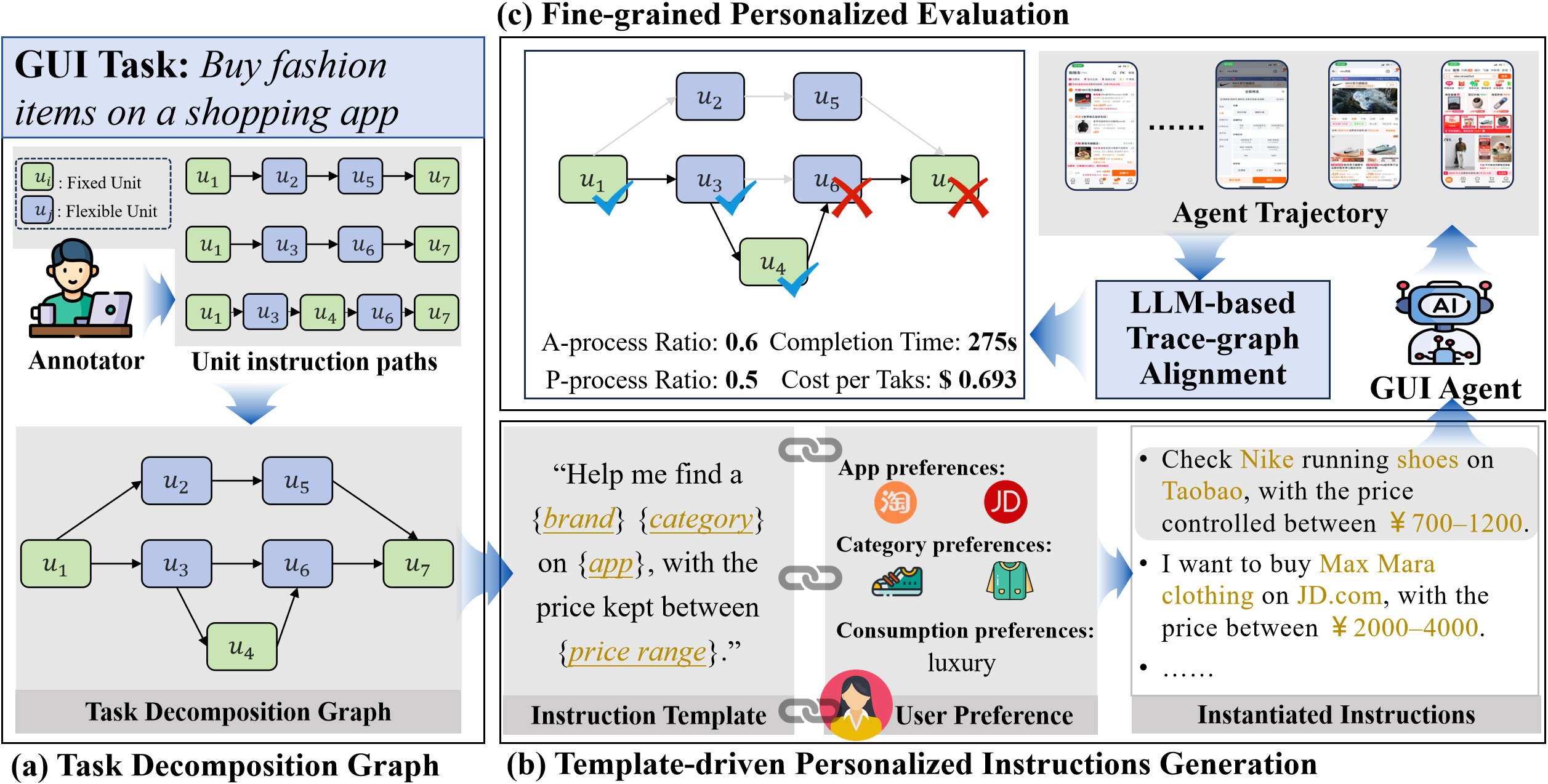
Figure 2: PSPA-Bench framework: TDG for task structure, template-driven personalized instruction instantiation, and trace-graph alignment for fine-grained evaluation.
Personalized instructions are instantiated via probabilistic sampling from user profiles, which model both long-term stable preferences and short-term dynamic interests. A logarithmic growth function governs long-term preference accumulation, while a sinusoidal function ensures realistic oscillation of short-term needs; normalized weights drive slot selection during template instantiation, producing instructions that reflect both enduring behaviors and current context.
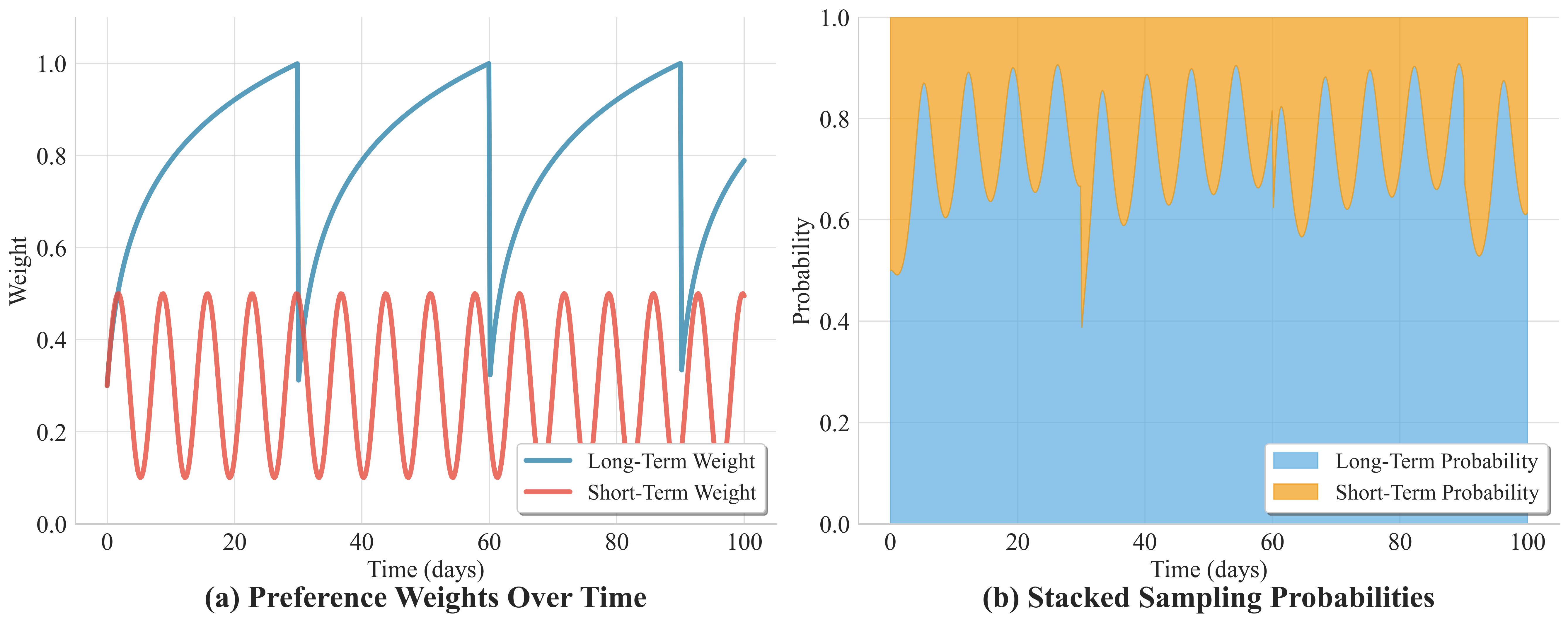
Figure 3: Evolution of preference weights and resulting probability distributions for instruction generation, capturing both temporal stability and periodic dynamics.
Evaluation Protocol and Metrics
Evaluation is conducted at two granularities:
- Immediate Objective: Execution performance and efficiency are measured for a single personalized instruction, using metrics such as A-Process Ratio (APR; completion over all unit instructions), P-Process Ratio (PPR; completion specific to flexible nodes), Completion Time (CT), and Cost Per Task (CPT).
- Long-Term Objective: Agents' capability to adapt over consecutive personalized tasks is quantified by incremental improvements (ΔAPR, ΔPPR, ΔCT, ΔCPT).
Trace alignment is done via LLM-assisted mapping of agent actions to TDG nodes; optimal paths are selected to maximize matched unit instructions, with tie-breaking favoring flexible preference satisfaction, shortest paths, and earliest matches.
Empirical validation demonstrates that APR—unlike coarse metrics such as success signals or task completion rates—closely aligns with human judgments by tolerating diverse execution strategies and yielding high correlation (ρ=0.95, MSE=0.005) with annotator ratings.
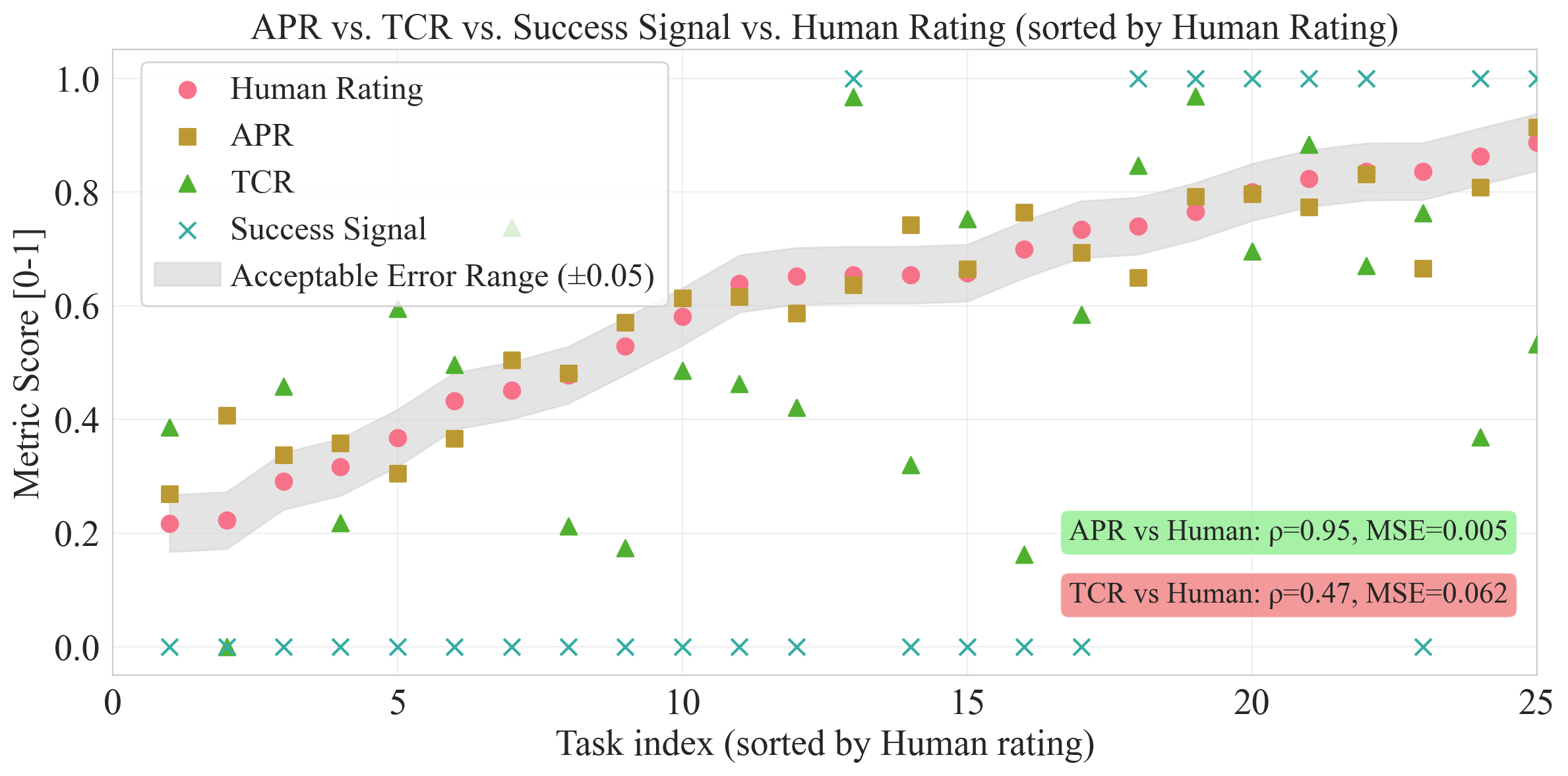
Figure 4: APR delivers strong alignment with human ratings, outperforming binary and fixed-path metrics on personalized tasks.
Empirical Results and Comparative Analysis
PSPA-Bench comprises 12,855 personalized instructions across 10 scenarios (e.g., shopping, navigation, travel) and 22 Android apps, with 100 user personas. Eleven state-of-the-art agent frameworks covering LLM baselines, general agent paradigms, and specialized mobile agent architectures were evaluated.
Key findings:
- Perception is critical: Access to structured GUI context (A11y trees, vision) is indispensable. LLM-Base without perception yields APR = 0.002, whereas A11y-augmented models reach APR ≈ 0.62–0.67.
- Reasoning capacity: Advanced planning or reflection (ReAct, Reflexion, Mobile-Agent V2/E) delivers substantial gains under ambiguous or complex personalized instructions.
- Memory mechanisms: Persistent memory (Reflexion, Mobile-Agent V2/E) is essential for longitudinal adaptation, with Mobile-Agent E achieving maximal ΔAPR (+6.72) and ΔCT (−57.02) upon self-evolution and rule updating.
- Tradeoff between accuracy and efficiency: Mobile-Agent E optimizes for completion but incurs higher computational cost (CT up to 716s), while AppAgent or LLM+A11y variants offer faster but less exhaustive execution.
Method ranking radar plots illustrate that only frameworks with sophisticated memory and self-evolution capabilities achieve comprehensive improvements across both performance and efficiency metrics.
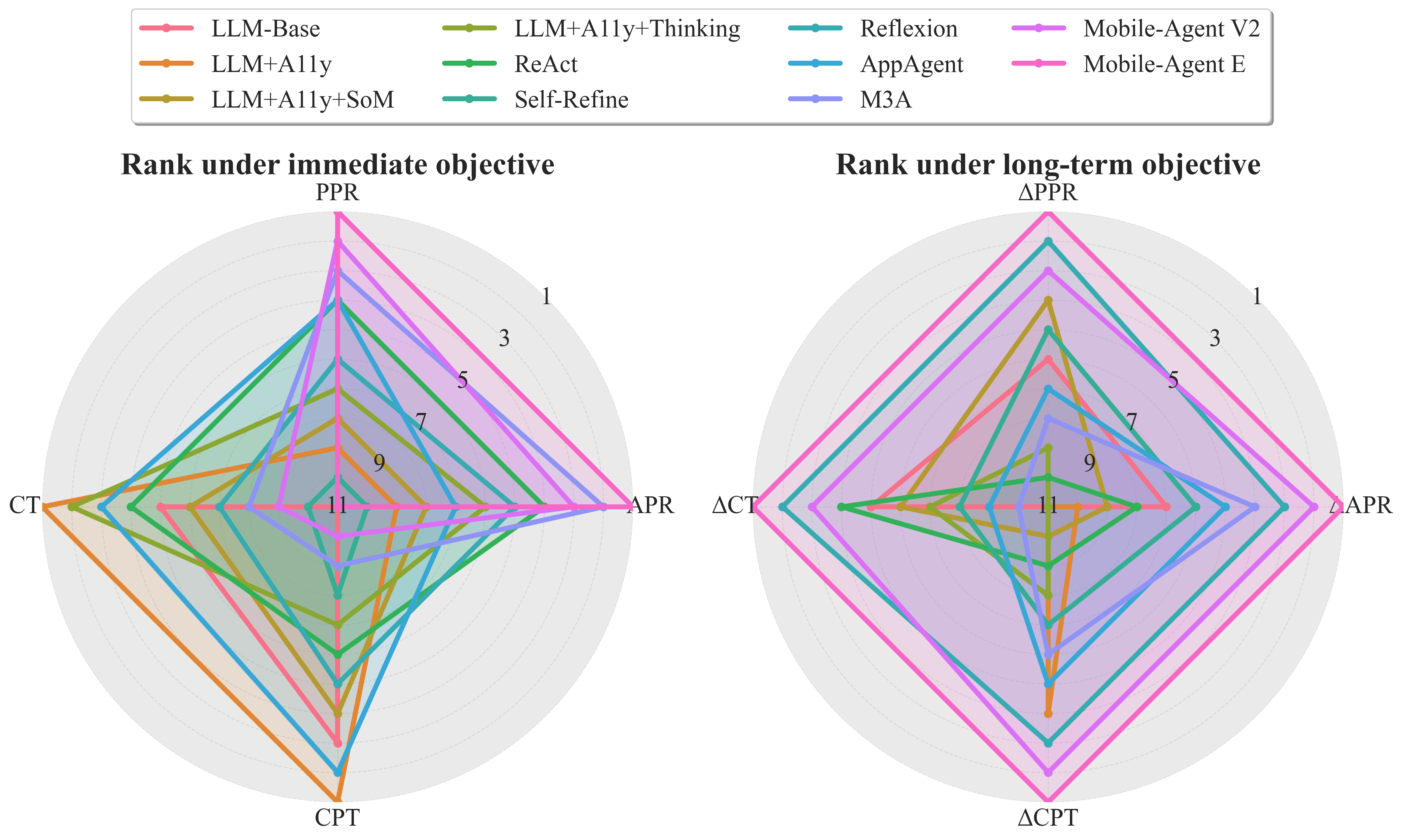
Figure 5: Comparative ranks under immediate (left) and long-term (right) objectives; persistent memory and adaptive evolution are decisive for sustained personalization improvements.
Task Structure and Scenario Diversity
TDGs were constructed for four representative personalized scenarios, demonstrating explicit delineation of fixed and flexible steps. This graphical formalism supports nuanced personalization and enables agents to exploit alternative valid paths.
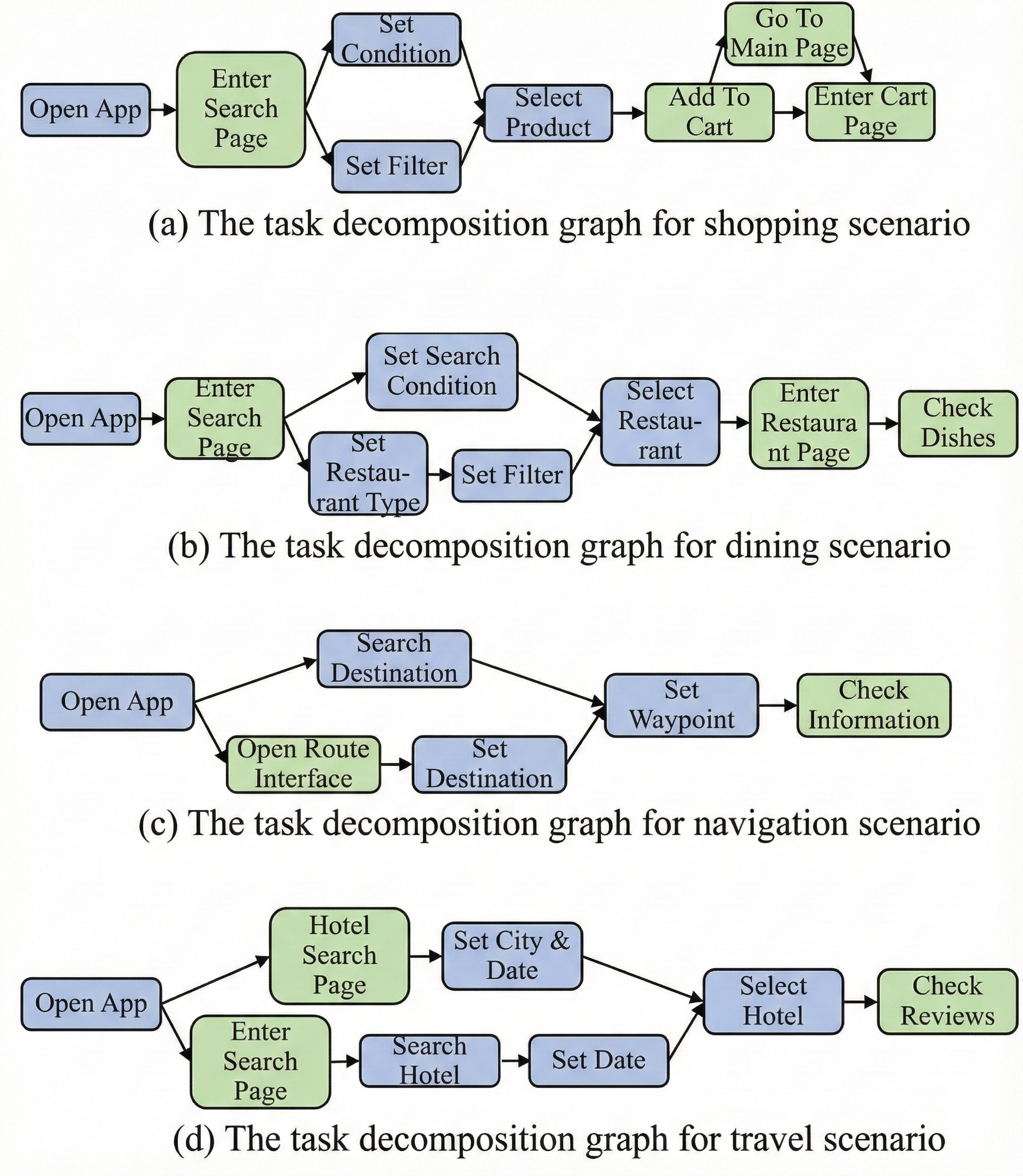
Figure 6: Example TDGs for shopping, dining, navigation, and travel, distinguishing universal and user-specific steps.
Theoretical and Practical Implications
PSPA-Bench formalizes the personalization problem in GUI agents, addressing data sparsity and metric inadequacy by leveraging TDG-driven instruction generation and evaluation. Results indicate that contemporary agents are inadequate in delivering robust personalization, suggesting fundamental architectural gaps in perception, reasoning, memory, and evolutionary adaptation. The benchmark enables the systematic study of adaptive agent designs, scalable instruction synthesis, and process-level progress evaluation.
Practically, PSPA-Bench provides a pathway toward privacy-compliant, user-centered mobile AI systems capable of long-term personalization. Theoretically, it invites future development in automated TDG construction, unsupervised preference modeling, and persistent memory integration across agent frameworks.
Conclusion
PSPA-Bench advances evaluation for personalized smartphone GUI agents via explicit task decomposition, realistic user modeling, and fine-grained, process-level metrics. Empirical analysis demonstrates that current agents are substantially limited in personalized settings, with persistent memory and self-evolution being necessary prerequisites for both immediate and long-term adaptation. The benchmark establishes a principled foundation for further research in adaptive, user-centric mobile agent architectures, and highlights directions for integration of dynamic preference modeling, reasoning, and persistent experience accumulation.