- The paper introduces a fully automated mask annotation framework, PromptForge-350k dataset, and ICL-Net for localized forgery detection in prompt-based image editing.
- It employs a triple-stream network architecture with noise, main, and frozen backbones, optimized via intra-image contrastive loss to enhance segmentation accuracy.
- Experimental results show superior IoU and F1 scores, demonstrating robust performance against JPEG compression, cropping, and cross-model generalization challenges.
PromptForge-350k: Large-Scale Dataset and Contrastive Framework for Prompt-Based AI Image Forgery Localization
Motivation and Overview
The proliferation of prompt-based AI image editing tools has resulted in a significant increase in the risk of image forgery, facilitating malicious content creation and misinformation. Traditional forgery localization datasets and methods, centered on Photoshop-like operations or mask-based AI editing, are insufficient for prompt-based editing paradigms, which lack explicit region mask supervision and disrupt low-level forensic cues. This work introduces three principal contributions: an automated mask annotating framework, the PromptForge-350k dataset, and ICL-Net, a triple-stream forgery localization network utilizing intra-image contrastive learning.
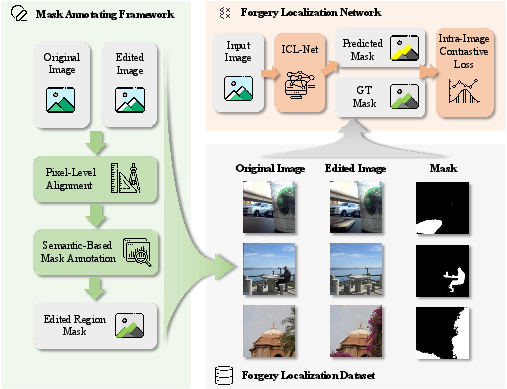
Figure 1: Overview: (1) Fully automated mask annotating framework for prompt-based image editing. (2) PromptForge-350k, the comprehensive dataset. (3) ICL-Net, an effective localization network.
Automated Mask Annotating Framework
Localization of edited regions in prompt-based AI images is nontrivial, as generative models synthesize the entire image without explicit masks, precluding naive pixel-wise differencing. The annotation pipeline proceeds via pixel-level spatial alignment followed by semantic-space mask estimation. Pixel-level alignment uses ORB keypoint extraction and RANSAC-driven affine registration to resolve cropping and scaling artefacts introduced by editing models.
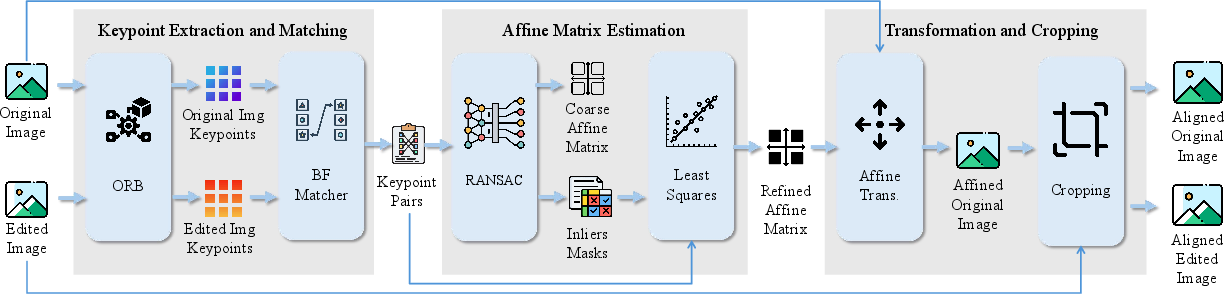
Figure 2: Pixel-level alignment: keypoint extraction/matching, affine estimation, coordinate transformation, border cropping.
Semantic-based mask annotation leverages DINO v3 for dense feature extraction and spatially-correlated cosine similarity computation between aligned image pairs. Binarization via Otsu's thresholding yields pixel-level edited masks, robustly discriminating semantic variations introduced by prompt-driven edits, while ignoring incidental pixel-level noise.
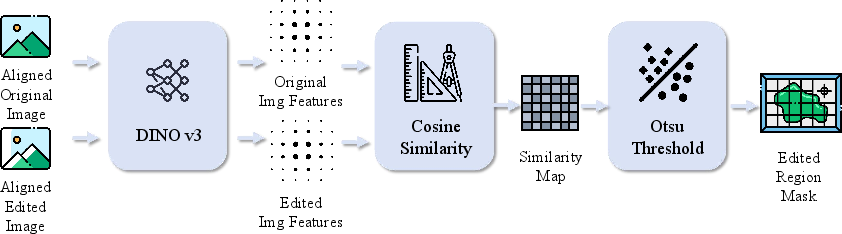
Figure 3: Semantic-based mask annotation: DINO v3 features, pixel-wise similarity, thresholding yields precise edited region mask.
PromptForge-350k Dataset Construction and Quality
The constructed PromptForge-350k dataset comprises 354,258 image pairs sourced from X2Edit and PicoBanana, curated to include only local editing tasks across eight categories—object replacement, addition, removal, material conversion, pose change, text editing, portrait editing, and state conversion. Four SOTA prompt-based editors (Nano-Banana, BAGEL, Flux.Kontext, Step1x-edit) are represented, ensuring diversity and coverage.
Sample filtering eliminates images with insufficient keypoints/matches or failed annotation, enhancing reliability. Masks are standardized to 128×128 for efficient training. Computational overhead profiling shows feature extraction (DINO v3) as the principal bottleneck (72%), while pixel-level alignment incurs marginal cost.
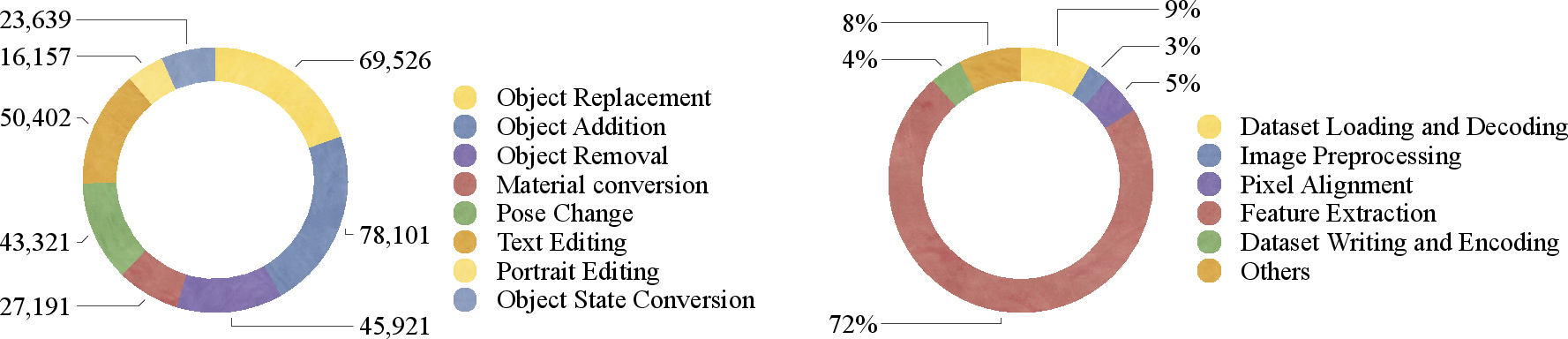
Figure 4: Left: Distribution across editing categories. Right: Time consumption breakdown for annotation pipeline operations.
A user study (200 sample pairs) validates annotation quality: 86% rated as "Perfect", 10% as "Minor Error", and only 4% as "Significant Error," confirming high-fidelity automatic mask generation except for localized color edits.
ICL-Net: Triple-Stream Forgery Localization Network
ICL-Net is designed to surmount the limitations of traditional artifact-based approaches, which are ineffective due to global image resynthesis in prompt-based editing. The network incorporates three parallel backbones:
- Noise Backbone: Extracts high-frequency trace artefacts.
- Main Backbone: Captures semantic-level irregularities.
- Frozen Backbone: Maintains pretrained invariance, mitigating catastrophic forgetting.
All backbones are initialized from SegFormer-B4. Feature concatenation feeds a convolutional segmentation head, outputting mask predictions.
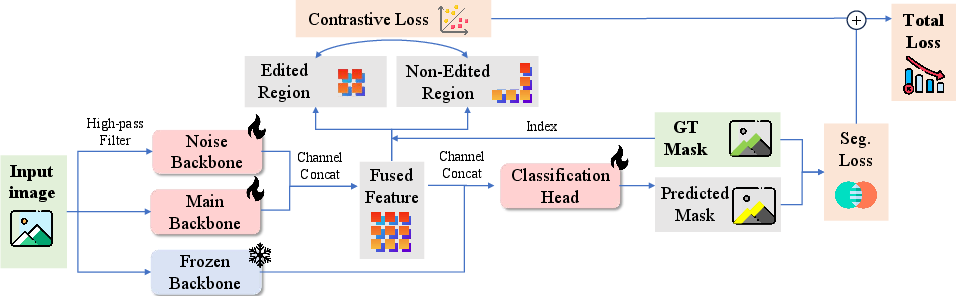
Figure 5: ICL-Net architecture: three parallel backbones optimized via intra-image contrastive and segmentation losses.
Optimization uses an intra-image contrastive loss, directly maximizing separability in feature space between forged and real regions, combined with Dice and Focal Loss to counter class imbalance (<20% forged pixels).
Experimental Results
ICL-Net achieves IoU of 62.5% and F1 of 75.2% on PromptForge-350k, outperforming strong baselines by 5.1% IoU, with negligible robustness degradation under JPEG compression and cropping (<1% IoU drop). Generalization tests show average IoU of 41.5% on unseen editing models, with performance generally higher for open-source editors relative to closed-source Nano-Banana. Qualitative overlays further demonstrate superior precision and recall on manipulated regions.

Figure 6: Predicted (red), ground truth (green), overlap (yellow) masks for ICL-Net on prompt-based edited images.
Ablation studies confirm the necessity of the contrastive loss for discriminative feature learning, and the inclusion of noise and frozen backbones contributes to peak performance.
Implications and Future Directions
PromptForge-350k lays the foundation for large-scale, robust, and reproducible research in forgery localization for prompt-based AI editing, filling the void in region-annotated datasets for this paradigm. ICL-Net's architecture and loss design are effective at extracting semantic and textural cues lost in global image resynthesis. The findings highlight critical gaps in generalization from open-source to closed-source model artefacts, emphasizing the need for adversarial training and domain adaptation strategies.
Future research should focus on enhancing color sensitivity in mask annotation (e.g., via joint DINO tuning or multi-modal fusion), improving cross-model generalization (especially for proprietary closed-source models), and accelerating feature extraction. There is also scope for leveraging emerging large vision-LLMs for instruction-aware forgery localization.
Conclusion
PromptForge-350k establishes a comprehensive benchmark with automatic and reliable mask annotation for prompt-based image editing. The intra-image contrastive approach embodied in ICL-Net substantially advances local forgery localization, with resilient performance across degradations and moderate cross-model generalization. This work provides both practical tools and theoretical insights to catalyze progress in the secure, forensic analysis of AI-generated image content.

