- The paper introduces StarHash, detailing a method to generate memorable, deterministic astronomical object names via HEALPix grid partitioning and FF3-based index scrambling.
- The methodology partitions the sky into ~3.2 arcsec pixels and maps each coordinate to a unique three-word phrase drawn from an optimized word list for error resilience.
- Empirical evaluation on ~50 million coordinate pairs confirms the system’s robustness against transcription errors and spatial misidentification, ensuring efficiency for large surveys.
StarHash: Deterministic, Memorable, and Scrambled Phrase-Based Astronomy Object Identifiers
Motivation and Context
The proliferation of heterogeneous naming conventions for astronomical objects has been a persistent source of confusion in astronomical record keeping, data retrieval, and human communication. Traditional coordinate-based ("telephone number") identifiers are neither robust to transcription errors nor memorable for practitioners, while the accumulation of aliases across surveys and catalogues exacerbates cross-matching complexity. Survey-dependent "internal" naming schemes further fragment identification, especially for transients. The field faces amplified challenges with the advent of high-cadence surveys such as LSST, where the rate of new discoveries is expected to render legacy approaches untenable.
The "StarHash" system addresses these issues by leveraging principles from geohashing in a manner tailored for astronomical requirements. It offers unique, highly memorable, and deterministic string identifiers for arbitrary sky locations, underpinned by strong algorithmic and statistical guarantees.
StarHash Methodology
The StarHash algorithm partitions the celestial sphere using a HEALPix grid at Nside=216, yielding pixels of ∼3.2 arcsec, closely aligned with established association radii. Each location's coordinate is mapped to a unique integer pixel index via HEALPix's angular-to-pixel (ang2pix) transformation. To decorrelate neighboring pixels in coordinate space from semantic proximity in identifier space, StarHash applies FF3 format-preserving encryption to the zero-padded HEALPix index. While FF3 lacks cryptographic robustness, its use here is solely for bijective scrambling rather than security, thus the weaknesses of FF3 are not relevant in this domain.
Word assignment proceeds through repeated modular decomposition of the encrypted index into base wordlist indices, constructing a k-tuple of words (with k=3 in the baseline implementation). The word list, drawn from the EFF long wordlist (with astronomy-specific augmentation), optimizes for memorability and avoids problematic homophony or profanity. This mapping ensures each 3.2 arcsec region has a unique triplet of words associated with it, and the process is fully reversible given public parameters.
Empirical Evaluation
Rigorous numerical assessment underscores StarHash's resistance to both coordinate-to-identifier and identifier-to-coordinate confusions.
On a sample of ∼50 million sky coordinate pairs, uniformly drawn, the distribution of Hamming distances between corresponding StarHash strings exhibits no residual spatial correlation. Even for minimal angular separations, identifier triples differ in two or all three words with high probability, sharply reducing the risk of confusion via transcription errors.
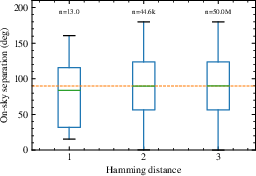
Figure 1: Box plot of Hamming distance over ∼50M unique coordinate pairs uniformly distributed across the sky versus on-sky distance.
This robust decorrelation holds in the regime of localized, dense sky sampling near clusters, as shown for a Gaussian distribution centered on M31. The use of FF3-encrypted indices as the basis for word selection is crucial to this property.
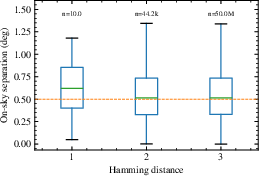
Figure 2: Box plot of Hamming distance for ∼50M coordinate pairs with Normal (0.5 deg) distribution centered on Andromeda, versus on-sky distance.
Further, analysis using Levenshtein distance (edit distance) confirms the minimal semantic proximity—single character errors in a StarHash phrase are exceedingly unlikely to yield nearby sky locations, providing resilience against manual entry mistakes.
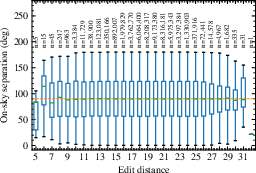
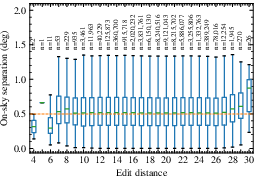
Figure 3: Levenshtein edit distances for large coordinate pair samples, for both uniform all-sky and localized samples, as a function of angular separation.
The system is computationally efficient, achieving throughput of approximately 6600 hashes per second single-threaded in Python, allowing large-scale catalog processing (e.g., Gaia DR3) on commodity hardware.
Examples and Use Cases
Visual demonstration of StarHash's assignment confirms its practical utility. The StarHash grid overlays on HST imagery of SN 1987A exhibit grid correspondence with astrophysically meaningful regions, and the resulting phrase names are distinctive and unambiguous for human communication.
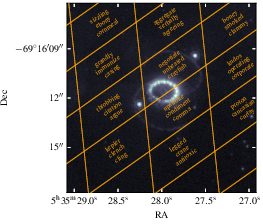
Figure 4: HST image of SN 1987A with overlaid StarHash grid and names, visualizing phrase assignment to sky patches.
A projection of StarHash phrase assignments for a curated set of notable transients further highlights the improved mnemonic and communicative properties compared to existing IAU or survey-based identifiers.
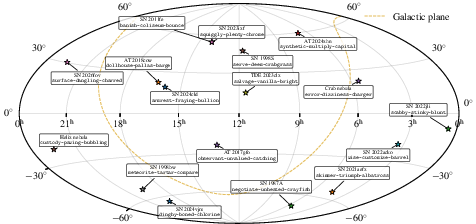
Figure 5: All-sky projection of StarHash names for significant transients, shown alongside conventional names; dashed line indicates the Galactic plane.
Limitations and Extensibility
Several caveats are inherent in the current StarHash scheme. Its Anglocentric word list impairs universal accessibility, motivating future language-localized variants at the potential cost of universality. The chosen HEALPix resolution is fit for most optical applications but is suboptimal for high-precision domains; this is straightforwardly addressable by increasing k or the wordlist size, but at the expense of identifier length.
Temporal information is not encoded, contrasting with some transient-specific naming conventions. Extensions for encoding discovery epoch or additional parameters are possible via additional words, with scaling behaviors favorable for the foreseeable future. Integration into legacy systems and community buy-in are recognized as significant, though surmountable, barriers.
Implications and Outlook
StarHash is a reproducible, open, and production-ready system for astronomical object naming, blending algorithmic rigor with enhanced usability. It stands as a practical remedy to systemic confusion in astro-nomenclature—resolving error sensitivity, memorability, and cross-survey reproducibility, with demonstrable benefit over both coordinate-based identifiers and non-open, proprietary systems like What3words (2603.29584).
The framework is broadly extensible (including to non-optical/astrometric applications), well-suited to pipeline integration, and supports large-scale parallelization. Future work may refine language inclusivity, phrase space scaling, or integration with temporal and contextual metadata.
Conclusion
StarHash offers a robust, deterministic, and memorable alternative to traditional astronomical object naming systems. Its mathematical foundation ensures that phrase identifiers are unambiguous, easily communicable, resistant to minor entry errors, and decorrelated from coordinate proximity, as substantiated by extensive empirical validation. The system is open source and its adoption could harmonize object identification practices across astronomy, fostering both practical efficiency and reduced cognitive burden for researchers.