- The paper demonstrates that subagent architectures achieve rapid early gains through parallel exploration and reliable resilience.
- It shows that agent team frameworks, while slower initially, yield complex, multi-dimensional modifications despite higher crash rates.
- The study highlights a trade-off between operational throughput and theoretical deliberation, advocating dynamic, task-adaptive architectures.
Empirical Analysis of Multi-Agent Collaboration in Automated Research
Motivation and Background
The paper "An Empirical Study of Multi-Agent Collaboration for Automated Research" (2603.29632) provides a systematic evaluation of distinct multi-agent coordination frameworks for autoresearch, focusing on how agentic topology governs operational efficiency, stability, and research productivity in automated machine learning codebase optimization. The authors depart from monolithic LLM-based single-agent architectures—widely used in recent autoresearch pipelines—but which present systemic limitations such as context window decay, deterministic search, and poor handling of complex, multi-dimensional edits. The study is motivated by the need to architect advanced multi-agent systems (MAS) able to dynamically coordinate, specialize, and adapt across scientific tasks requiring both empirical breadth and theoretical depth.
Architecture and Coordination Frameworks
Three agentic topologies are empirically evaluated: single-agent, hierarchical subagent, and peer-based agent teams. The testbed is strictly controlled, leveraging Git worktree isolation, explicit memory mechanisms, structured patch contracts, and preflight validation to rigorously neutralize environmental contamination and memory degradation—ensuring fair and reproducible comparisons of coordination strategies.
The Subagent architecture employs a central orchestrator agent delegating tasks to specialized worker subagents operating in parallel isolated worktrees. These subagents independently propose code modifications and, when multiple improvements are detected, a centralized Coordinator merges patches into a unified candidate which is then evaluated. The system provides high controllability, modularity, and operational resilience but limits inter-subagent communication as all exchanges go through the orchestrator.
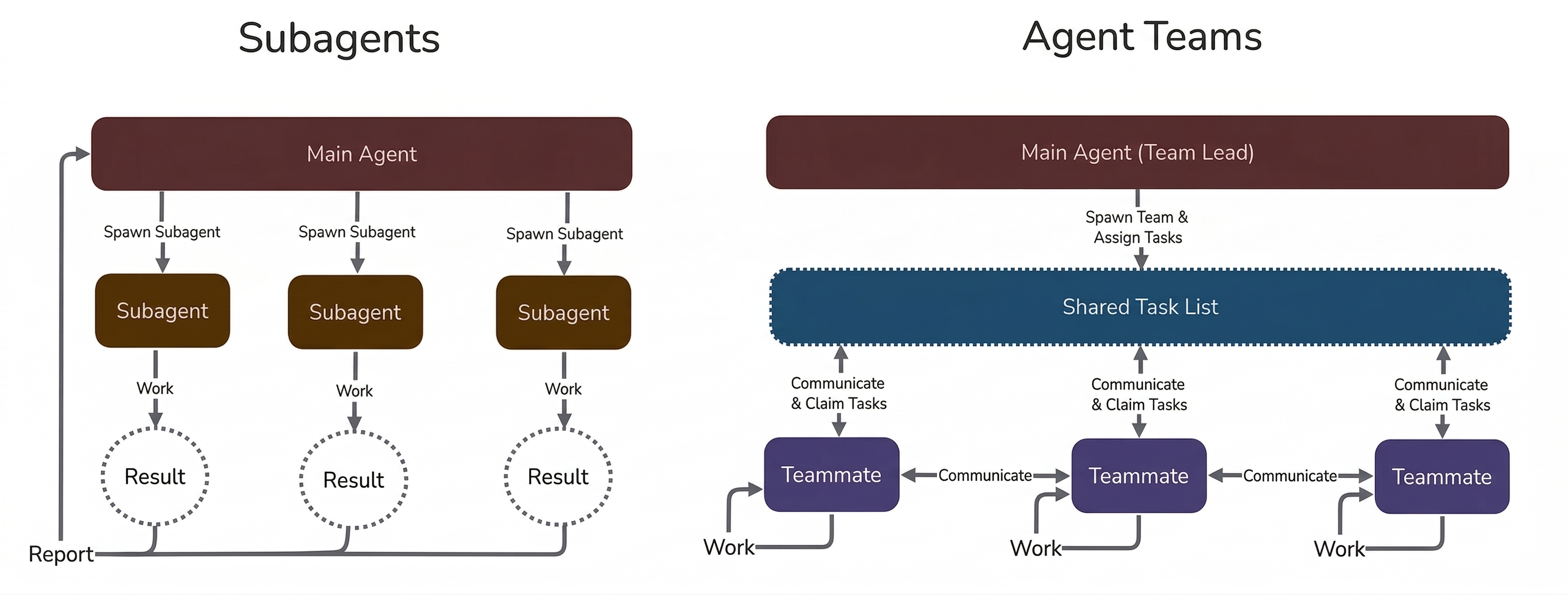
Figure 1: Multi-Agent Coordination Frameworks highlighting single-agent, subagent, and agent team architectures.
The Agent Teams architecture features decentralized collaboration among peer expert agents operating sequentially within a shared worktree. Each agent specializes (architecture, optimization, efficiency) and directly communicates, passing summaries and motivations downstream. Collisions and runtime errors from multi-author edits are managed by an Engineer agent executing conservative debugging post-handoff, prioritizing preservation of expert intent. This topology supports flexible, adaptive problem-solving but is susceptible to increased crash rates and emergent coordination issues.
Experimental Evaluation and Results
Empirical benchmarking is conducted under fixed wall-clock budgets (300s, 600s), tracing the absolute reduction in validation bits per byte (Δval_bpb), proposal validity, and system stability across research rounds. The agents deployed are variants of GLM (glm-4.6v, glm-4.7), selected for their competitive performance in code generation.
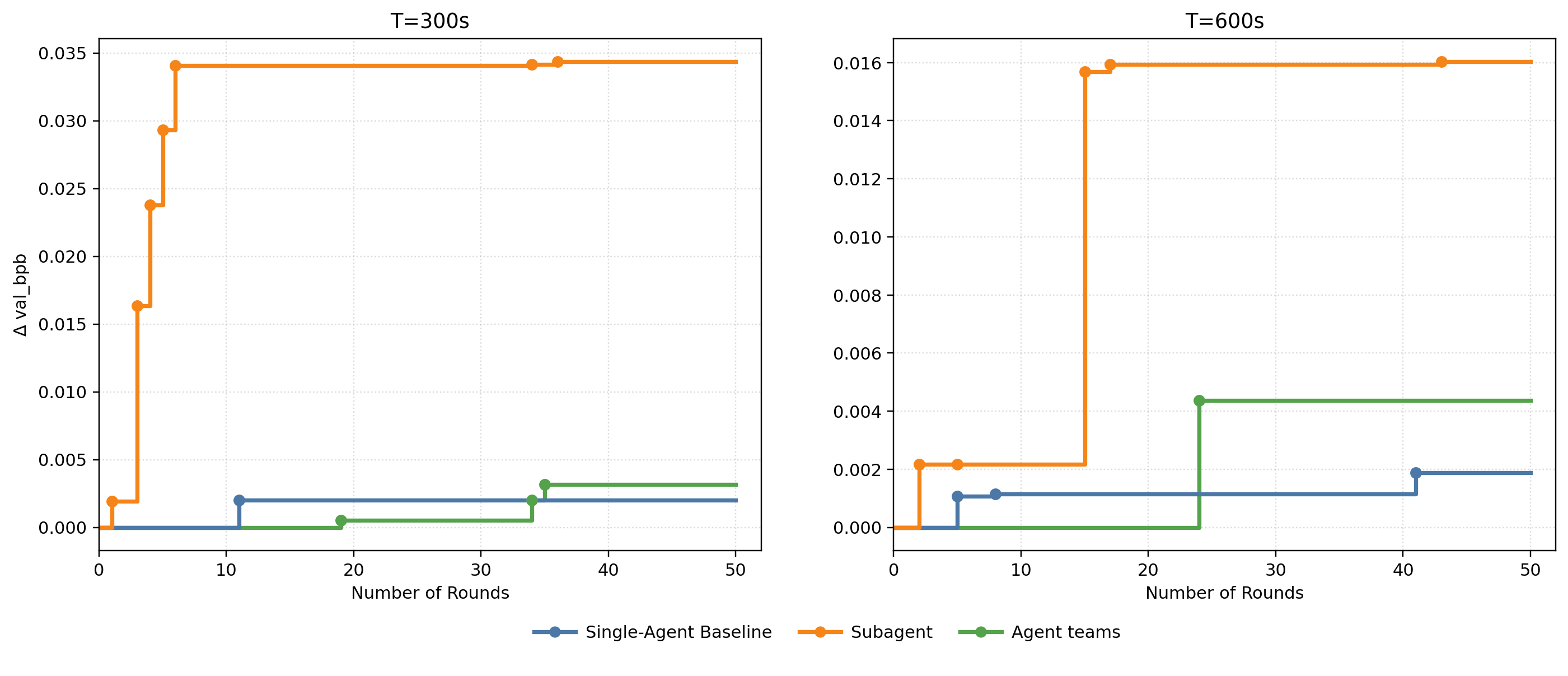
Figure 2: Autoresearch Progress showing Δval_bpb improvements across single-agent, subagent, and agent team frameworks under time constraints.
Key findings include:
- Subagent mode exhibits rapid, high-throughput improvement early in the research cycle, accumulating localized gains through parallel exploration and frequent merging. However, it suffers from lack of diversity, frequently fixating on single-dimensional parameter sweeps (e.g., MLP widths), leading to convergence on local optima.
- Agent teams demonstrate slower initial progress but produce more structurally complex and diverse modifications, able to conceptualize multi-faceted improvements (joint architectural and scheduling changes) within single research rounds. This is attributed to pre-execution deliberation and specialization but entails higher operational fragility, with compounded errors from sequential, multi-agent edits.
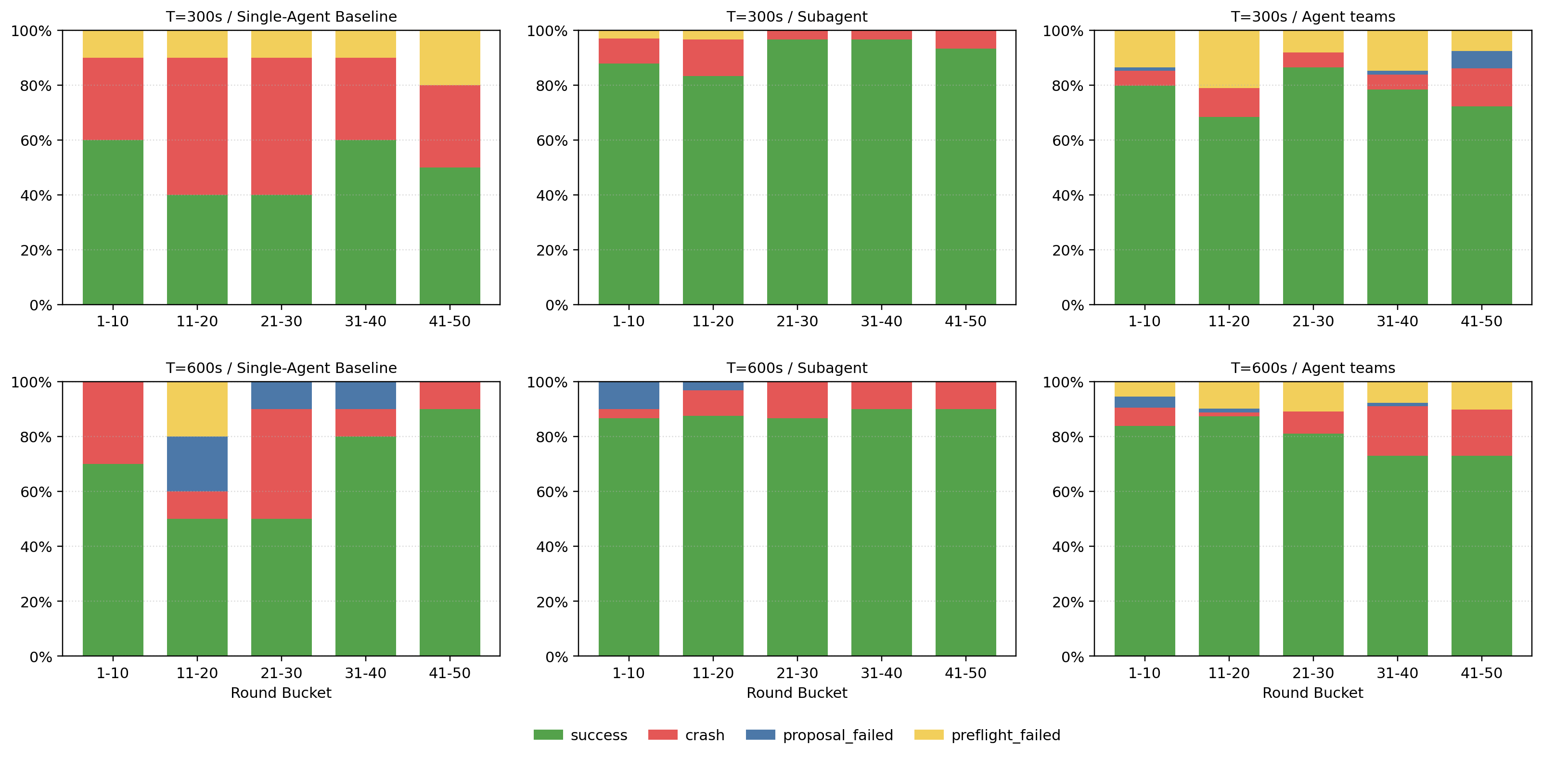
Figure 3: Ratio of each phase showing proposal failure, preflight failure, training crash, and success rates for each topology.
System stability analysis reveals:
- Subagent architectures maintain the lowest effective crash and preflight failure rates, as isolated worker failures do not propagate and sabotage overall progress.
- Agent teams experience elevated crash rates due to multi-author code generation, with logical incompatibilities accumulating across conversational turns and agent handoffs. Strict debugging by the Engineer agent mitigates but does not fully resolve these issues.
Comparative Insights and Design Implications
The empirical results establish a fundamental trade-off between operational throughput and theoretical deliberation: subagents excel at broad, shallow optimizations with robust resilience, ideal for high-volume hyperparameter sweeps within strict time budgets; agent teams are better suited for deep architectural refactoring and exploration, albeit with reduced stability and throughput.
Dynamic routing architectures are advocated, where subagents are deployed for empirical, parallel searches while specialist teams are activated for complex, multi-layered innovations, contingent on real-time task complexity and resource constraints. Organizational rigidity should be eschewed—future autoresearch systems must fluidly adapt their topology to task demands.
Theoretical Implications and Future Directions
This work exposes critical organizational variables controlling MAS efficacy in scientific research. It quantifies how collaboration modalities, communication timing, specialization, and explicit memory affect both search diversity and operational resilience. The results challenge the conventional preference for single-agent autonomy in autoresearch, presenting evidence that holistic exploration and complex edits necessitate structured peer deliberation—even at the expense of execution stability.
Future autoresearch systems should integrate dynamic, context-aware routing across subagent and team-based modalities, leveraging explicit memory, robust isolation, and adaptive debugging. Research trends will likely favor autonomous agentic swarms orchestrated across distributed compute clusters, capable of negotiating both shallow empirical optimization and theoretical paradigm shifts.
Conclusion
This empirical study systematically compares multi-agent coordination frameworks for automated machine learning research. Subagent architectures deliver robust, high-throughput search suitable for empirical tasks, while agent teams enable diverse, theoretically motivated architectural modifications with increased operational risk. The fundamental trade-off between throughput and deliberation underscores the need for dynamic, task-adaptive agentic organization in future autoresearch systems, ultimately marking autonomous multi-agent swarms as the trajectory for scalable AI-driven scientific discovery.