- The paper introduces Simula, a reasoning-driven framework that decomposes domains into taxonomies for generating diverse and controllable synthetic data.
- It employs an innovative generator-critic alternation and best-of-N sampling to ensure semantic consistency and effective complexity scoring.
- Experiments across benchmarks like GSM8k and Global MMLU show that optimizing data composition, not just quantity, is key to enhanced downstream AI performance.
Reasoning-Driven Synthetic Data Generation and Evaluation: The Simula Framework
Motivation and Framework Design
The scarcity of specialized, high-quality, and privacy-sensitive datasets constrains the development and deployment of advanced AI models across domains. Traditional dataset construction via manual annotation is expensive, error-prone, and lacks scalability, prompting increased reliance on synthetic data. However, existing approaches—ranging from prompt-based generation, evolutionary sampling, or seed expansion—often fail to optimize for explainability, control, and scalable resource allocation. The paper presents Simula, a reasoning-driven, seedless synthetic data generation and evaluation framework that orchestrates coverage, diversity, complexity, and sample quality control at scale. Simula enables controllable coverage of semantic spaces via taxonomies, agentic refinement of samples, and critic-based quality filters.

Figure 1: Synthetic coverage examples illustrate the consequences of random sampling, perfect global planning, and progressive coverage loss via taxonomic expansion.
Simula's pipeline begins with decomposition of the conceptual domain into prime factors (e.g., "cat type", "story format", "audience"). These factors are expanded into hierarchical taxonomies that represent discrete semantic spaces at increasing granularity, allowing precise targeting of data diversity and coverage. The resulting taxonomic nodes provide anchors for "meta prompts," which drive generator LLMs to synthesize diverse and complex data points. Critic steps evaluate semantic consistency and correctness, harnessing the generator-critic gap for improved sample quality.
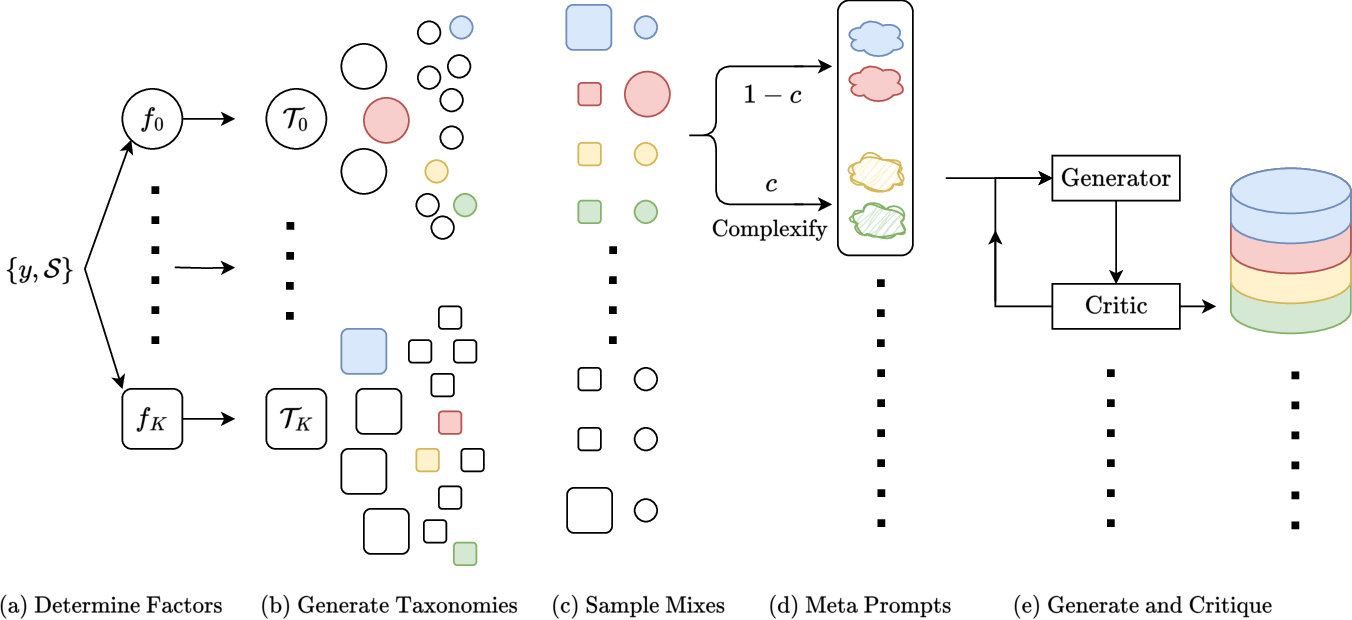
Figure 2: The Simula framework schematic: taxonomic expansion, agentic meta-prompting, and iterative critic-based refinement enable explainable, controllable synthetic dataset generation.
Taxonomic Coverage and Sampling Mechanism
Simula's taxonomy-driven approach distinguishes between global and local diversity. It uses breadth-first expansion with generator-critic alternation, leveraging best-of-N sampling for coverage of edge cases and critic refinement for completeness and soundness. Each data point is synthesized by sampling compatible taxonomic mixes, constructing meta-prompts, and applying complexification as needed. The system supports resource allocation by allowing users to adjust coverage granularity and local diversity via sampling ratios. Critic steps ensure semantic and syntactic requirements are satisfied, and in tasks requiring correctness, double-critic evaluation mitigates label sycophancy bias.
Intrinsic Evaluation: Diversity and Complexity
Simula's evaluation protocols advance beyond embedding-based metrics by introducing taxonomic coverage and calibrated complexity scoring. Global (dataset-wide) and local (nearest-neighbors) diversity are measured via cosine similarity in a distilled embedding space, while taxonomic coverage quantifies domain representation. Complexity is assigned using batch-wise, relative scoring calibrated via Elo rankings—allowing control and cross-dataset comparison of sample difficulty irrespective of manual annotation.
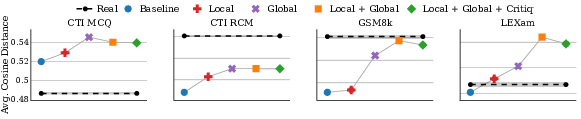

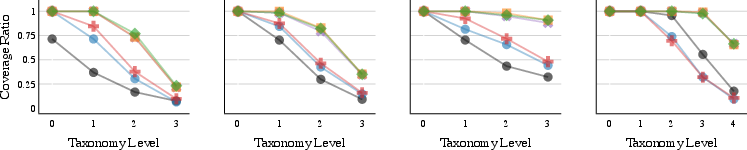
Figure 3: Dataset-wide embedding diversity and local diversity for synthetic vs. real data. Global diversification is essential for maximizing diversity; synthetic sets often outperform real datasets in taxonomic coverage.
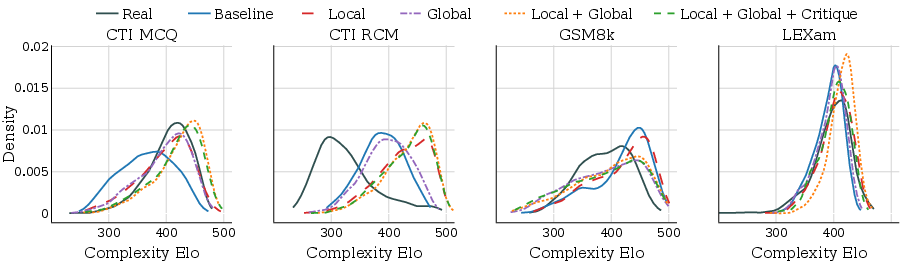
Figure 4: Complexity Elo distribution for synthetic and real datasets. Simula variants span the entire complexity range; local and global diversification are additive in complexity coverage.
Simula's framework is evaluated across a selection of benchmarks, including GSM8k, LEXam, CTI-MCQ, CTI-RCM, and subsets of Global MMLU, with student models fine-tuned on synthetic data produced by different system ablations. Results substantiate several claims:
- The full Simula pipeline, integrating global and local diversification plus critic refinement, dominates in downstream performance across all datasets and scales.
- Data scaling laws depend not only on sample count, but on composition—baseline random sampling is outperformed at all scales.
- Complexity boosts downstream accuracy in domains with strong teacher models, but can degrade performance where teacher label weakness predominates.
- Critic-based filtering (double critic) boosts correctness or maintains coverage control without reducing diversity.
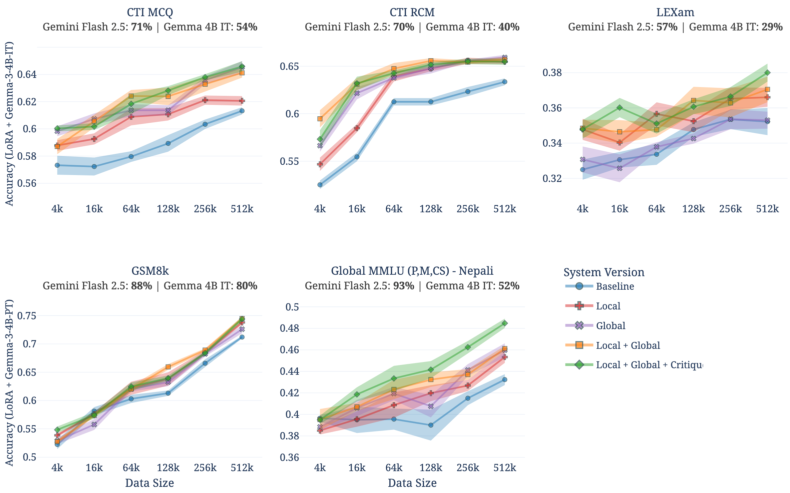
Figure 5: Downstream performance across datasets and Simula system versions. The full system consistently achieves highest performance; benefits depend on dataset and scale.
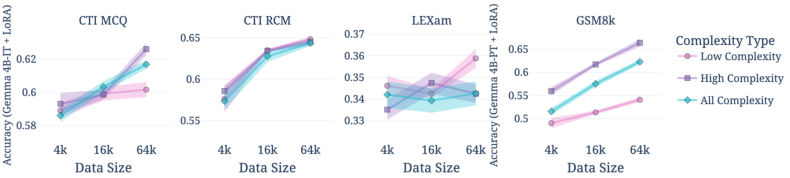
Figure 6: Data complexity impact: higher complexity improves scaling in GSM8k and CTI-MCQ; for LEXam, only low-complexity subsets improve accuracy due to weak teacher labeling.
Mechanism Design Principles and Implications
Central to Simula is the idea that mechanism design—how synthetic data is generated—constitutes an orthogonal research axis to traditional notions of what defines "good" data (quality, diversity, complexity). The framework operationalizes explainability and controllability at scale; users can tailor datasets for unique requirements, audit domain coverage, and diagnose potential biases. Rigorous experiments demonstrate that absolute performance and scaling behavior are context-dependent, calling into question the existence of a single optimal synthetic data solution.
Theoretically, the reasoning-driven pipeline ensures future-proofing: as underlying model capabilities improve, so does Simula’s output quality. Empirically, taxonomic and complexity-based evaluation delivers actionable metrics for coverage and challenge. Practically, resource allocation (more meta-prompts or critic passes) is targeted where domain-specific requirements are most stringent.
Further, Simula's approach is modality-agnostic—while focus is exclusively on text, its principles extend directly to other modalities (vision, speech, multimodal tasks).
Ethical Considerations and Future Directions
Simula introduces dual-use potential: fine-grained control could both mitigate and exacerbate dataset biases, depending on user intent. However, transparency and auditing mechanisms, such as taxonomic coverage analysis and calibrated complexity scoring, provide tools to monitor and rectify undesirable outcomes. Safeguards against label sycophancy and suboptimal critic rejection rates are embedded for contexts where teacher label quality is variable.
The framework invites several future research directions: analysis across additional model families, scaling with heterogeneous student models, exploring reinforcement learning and alternative optimization strategies, and extending taxonomy-driven coverage metrics for cross-modality datasets.
Conclusion
Simula operationalizes reasoning-driven synthetic data generation, prioritizing transparency, explainability, scalability, and resource allocation. The framework demonstrates that orchestrating diversity, complexity, and correctness via taxonomic decomposition and agentic refinement is essential for optimizing downstream model performance. Its intrinsic and extrinsic evaluation protocols provide actionable, robust metrics for dataset composition, complexity, and coverage. The paper underscores the deep context-dependency of synthetic data and advocates for flexible, mechanism-aware frameworks as prerequisites for future AI advancement.