- The paper demonstrates that dynamic planning and policy adaptation enhance LLM agent security against evolving, indirect prompt injection attacks.
- The methodology employs a compositional architecture separating orchestration, policy enforcement, and execution to effectively minimize the attack surface.
- The study emphasizes controlled LLM interactions and human-in-the-loop checkpoints to ensure auditability and adaptive defense in secure AI deployments.
Architecting Secure AI Agents: System-Level Defenses Against Indirect Prompt Injection
Introduction
The deployment of LLM-based agents in open-world environments has exposed them to indirect prompt injection (IPI) attacks, where maliciously crafted content in untrusted data sources hijacks agent behavior. The paper "Architecting Secure AI Agents: Perspectives on System-Level Defenses Against Indirect Prompt Injection Attacks" (2603.30016) presents a systems-oriented approach for defense, articulating the fundamental architectural requirements and their implications for both agent utility and security.
System-Level Perspective and Architecture
A critical perspective advanced in this work is the treatment of the LLM agent as a complex computing system, rather than as a monolithic model or a black-box function. The authors emphasize compositional architectures, separating roles into orchestrator, plan/policy approver, executor, policy enforcer, and explicit environment interaction loops.
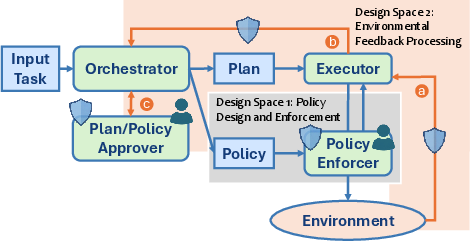
Figure 1: High-level system architecture for secure LLM-powered agents, delineating policy update, enforcement, dynamic replanning, and checkpoints for human-in-the-loop oversight.
Central to this architecture is the explicit handling of plan (execution trajectory) and policy (allowable behaviors), with dynamic, context-aware updates. Crucially, the design exposes clear security-critical interfaces (blue shields) and human-in-the-loop checkpoints, rather than relying solely on static, a priori policies or model-level robustness enhancements.
Core Positions
Dynamic Policy and Replanning
It is asserted that static policies and single-execution plans are insufficient for realistic agentic settings. Agents must respond to non-deterministic or evolving environments, runtime exceptions, and ambiguous user tasks, warranting on-the-fly updates to both plans and security policies. The paper provides concrete counterexamples where plan-execution isolation fails, and static policies become both over-constraining and under-constraining in practice (e.g., differentiating benign from adversarial context-dependent tool invocations).
This stance stands in explicit contradiction to prior proposals advocating for fixed plans or non-interactive policy enforcement [debenedetti2025defeating, shi2025progent]. Instead, the authors call attention to an architectural trade-off: dynamic adaptation yields higher utility but expands the security attack surface, requiring nuanced decision-making at each plan/policy update.
Controlled Use of LLMs for Security Decisions
A notable claim is that learned models (LLMs or specialized classification architectures) are indispensable for context-dependent security decisions, yet they must be tightly bounded in both observability and authority. Rather than exposing LLMs to attacker-controlled natural language, the architecture admits narrowly scoped, structured artifacts (e.g., typed diffs, DSL-encoded plans) as the only LLM-facing input at policy inflection points. The LLM's role is restricted to semantic judgment over constrained spaces, not open-ended task execution or policy definition.
The proposed approach calls for decoupling instruction recognition and policy adjudication (e.g., via explicit instruction verbalization and provenance-tracing). The system can choose to block, request human confirmation, or adjudicate novel external instructions by context, rather than implicitly relying on the model's adversarial robustness—a major deviation from approaches focused solely on LLM fine-tuning [chen2025secalign, chen2025meta, wallace2024instruction].
Necessity of Human Oversight
Where ambiguity or under-specification in user intent or environmental context is irreducible, the architecture incorporates explicit human-in-the-loop (HITL) checkpoints. These checkpoints target the developer or end-user for personalized policy updates or clarification—especially where language semantics or objective alignment is at stake (e.g., ambiguous definitions of "urgent," risk-prone code execution steps).
This acknowledges the theoretical limits of automation: certain forms of semantic ambiguity and intention cannot be resolved by algorithmic or learned methods alone, and safe agent deployment thus necessitates structured human intervention.
Critique of Existing Benchmarks and Broader Implications
The paper argues that the seeming effectiveness of system-level defenses omitting key architectural components is a by-product of benchmark limitations, including:
- Inadequate coverage of long-horizon, dynamic tasks, and the absence of tasks requiring replanning or policy evolution (see limitations in AgentDojo and AgentDyn [debenedetti2024agentdojo, li2026agentdyn]).
- Static, non-adaptive attack payloads, failing to instantiate adaptive attackers or reinforce goal ambiguity.
- The lack of model-level or system-level adversaries that optimize their attacks given defensive structure, enabling a false sense of security.
The architectural perspective advocated here directly informs the development of improved, realistic benchmarks and evaluation methodologies that better reflect the operational threat landscape and agent requirements, including adaptive, RL-driven prompt injection adversaries [wen2025rl, nasr2025attacker, yin2026pismith].
Theoretical and Practical Implications
By enforcing explicit separation of planning, policy creation, action execution, and enforcement, the architecture offers several advantages:
- Reduction of LLM Attack Surface: By filtering and structuring all LLM-relevant context, risk of prompt injection is localized and quantifiable.
- Support for Defense-in-Depth: Multiple, composable security enforcement agents (both programmatic and learned) can be interposed in the policy and feedback update loops.
- Auditability and Explainability: The explicit tracing of plans, policies, and decisions enables richer analysis of both successful and failed defense.
- Guidance for Robustness Research: Model-level defenses can now target constrained, structured judgment tasks, rather than unbounded string-level adversarial robustness—making the robustness question more tractable.
Practically, the architecture provides a blueprint for real-world agent deployment, supporting both dynamic utility and enforceable security, and creating actionable interfaces for future improvements in HITL, semantic recognition, and adaptive defense.
Speculation on Future AI Agent Security
Anticipated developments include:
- System-model-human co-design pipelines, with system-level constraints increasingly determining the feasible space for both model-level and adversarial advances.
- Task-specific and context-conditional policy synthesis, supported by HITL interactions and potentially formal verification for subcomponents.
- Integration of robust, adaptive adversarial benchmarking as a standard in agent security evaluation.
- Expansion of this architectural paradigm to multimodal AI agents and non-textual control domains, where semantics and ambiguity are even more prevalent.
Conclusion
The paper provides a principled architectural foundation for securing LLM-powered agents against indirect prompt injection, highlighting the necessity for dynamic plans and policies, system-constrained use of learned models in security-critical decisions, and unavoidable HITL components for ambiguity resolution. By shifting evaluation standards and best practices in agent security away from model- or rule-based silos towards compositional systems engineering, it lays essential groundwork for both the secure deployment and future research on autonomous AI agents.