- The paper introduces a context-augmented paradigm that combines structured Wikipedia retrieval with LLM summarization to improve verifiable claim detection.
- It employs a four-stage pipeline—BERT-driven entity extraction, hybrid retrieval, LLM summarization, and joint classification—to achieve up to 89.71% F1 on PoliClaim.
- The study highlights model-specific error modes and underscores the importance of prompt design and context quality in refining automated fact-checking.
ContextClaim: A Context-Driven Paradigm for Verifiable Claim Detection
Introduction
ContextClaim establishes a context-augmented methodology for verifiable claim detection within automated fact-checking (AFC) pipelines, addressing the fundamental weakness of prior work that relies exclusively on claim text. By leveraging structured knowledge retrieval from Wikipedia, combined with LLM-based context summarization, the system explicitly incorporates background information at the detection phase to improve discernment of whether a claim is in principle checkable against external evidence. This paradigm is motivated by the observation that the verifiability of a claim often depends on its entities and referents—information unobservable from surface form alone. The framework formalizes and systematically evaluates each computational stage, demonstrating non-uniform yet often significant performance improvements across model architectures and AFC learning regimes.
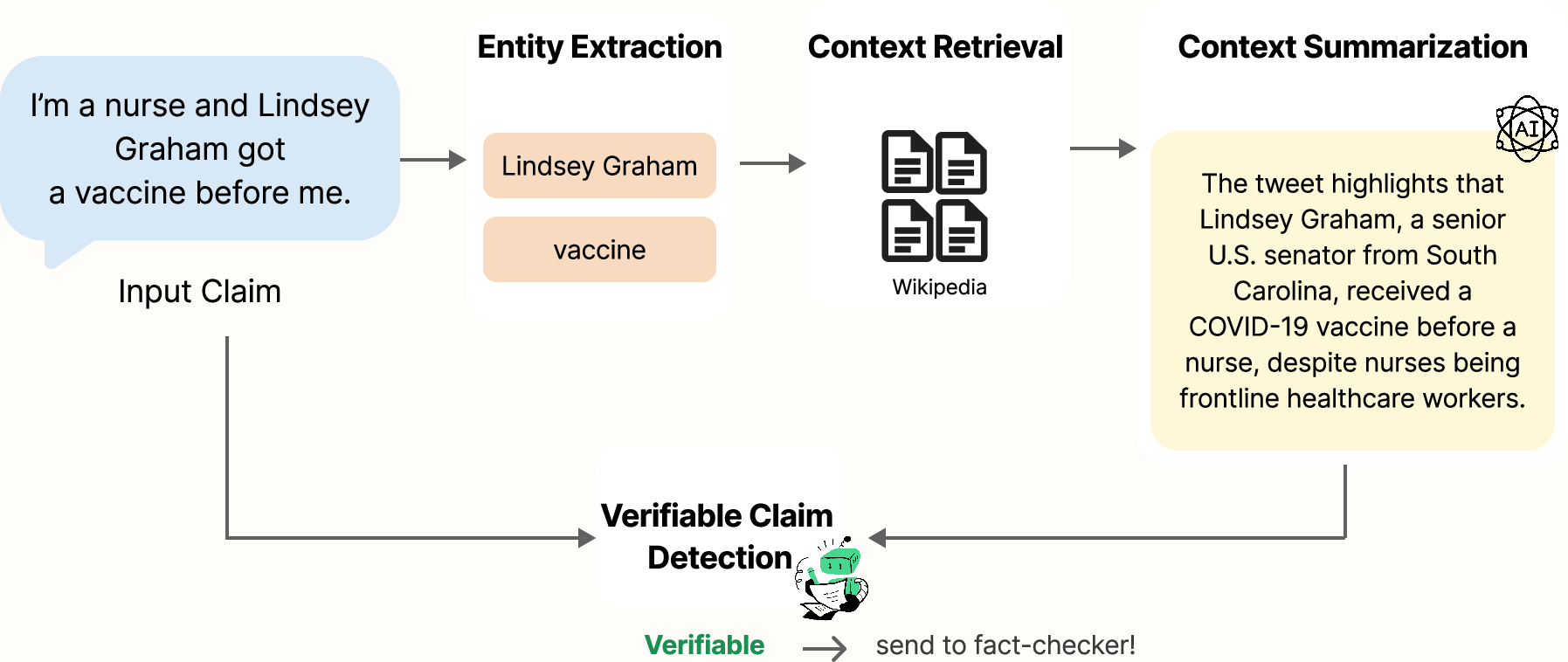
Figure 1: Example of ContextClaim system processing a vaccine claim about Lindsey Graham.
Methodological Framework
ContextClaim operationalizes entity-centric information retrieval and summarization for verifiable claim detection through a four-stage pipeline: (1) BERT-driven entity extraction with domain-adaptive extension for disease terminology on the CT22 dataset, (2) hybrid dense-sparse Wikipedia retrieval of relevant extracts using semantic and title similarity, (3) LLM-guided extractive summarization (GPT-4o and Mistral-7B), and (4) joint claim-context classification across encoder- and decoder-only models. Candidate context is subject to type-filtering based on empirical informativeness, and summarized context is represented in prompts or as cross-attended vectors according to backbone architecture.
The pipeline therefore hybridizes retrieval-augmented generation (RAG) concepts with early-stage claim selection, diverging from classical AFC systems that apply retrieval exclusively at evidence verification. The resulting input to claim detection is a tuple (xi,ci), with xi the claim and ci its context summary, supporting both classification-based and instruction-prompted LLM consumption.
Experimental Setup
Evaluation is conducted on CheckThat! 2022 COVID-19 Twitter (CT22) and PoliClaim datasets, which vary in discourse, entity density, narrative self-containment, and annotation consistency. Both are annotated for binary verifiability, and present disparate linguistic environments: CT22 consists of noisy, highly contextualized social media data, while PoliClaim sentences are formal, fragmented, and discourse impoverished (Figure 2).
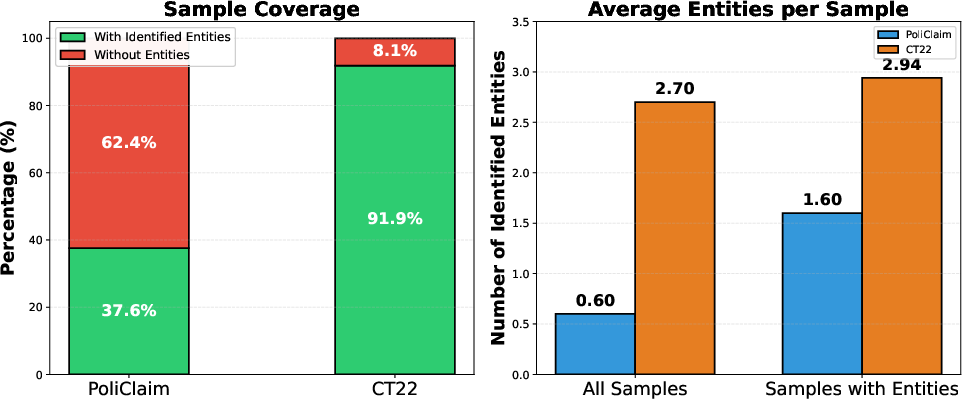
Figure 2: Entity Coverage and Quantity Comparison of PoliClaim and CT22.
Models include BERT-base and RoBERTa-large (encoder-only), along with Llama-3-8B and Mistral-7B (decoder-only), evaluated under fine-tuning, zero-shot, and few-shot in-context learning, as well as GPT-4o for prompt-based experiments. The primary quantitative metrics are F1 and accuracy; all architectures are compared both in baseline (text-only) and context-augmented configurations.
Results
Aggregate Performance and Context Integration
Across 20 model--dataset configurations, context augmentation (particularly using GPT-4o summaries, CC-G4o) yields improvements over baseline in the majority of pairings (13/20 for accuracy, 14/20 for F1). The gains are domain- and regime-specific, with CT22 (richer in recoverable entities) benefiting more systematically from augmentation than the more context-deficient PoliClaim. The strongest F1 is obtained by RoBERTa+CC-G4o on PoliClaim (89.71%) under fine-tuning, exceeding prior state-of-the-art annotator-assisted models (Table SOTA in the paper).
Performance exhibits high sensitivity to the stability of context integration in different architectures (Figure 3). BERT, Llama3, and GPT-4o are robust to both context variants, while Mistral is prone to context-induced degradation with lower-quality context summaries, illustrating that summarizer/model mismatch and context irrelevance can actively harm detection.
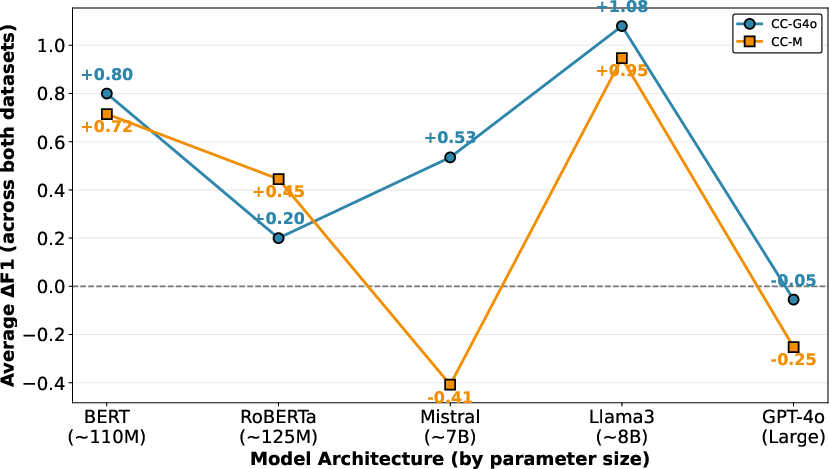
Figure 3: Model Architecture Effects on Contextual Information Benefits.
Learning setting exerts a strong modulating effect (Figure 4), with fine-tuning enabling the most reliable exploitation of external context. Zero-shot augmentation serves as a strong decision anchor on claim-rich datasets, but frequently increases false positive bias. Few-shot regimes—especially in weakly supervised settings—can produce antagonistic interactions, where context and demonstration cues conflict, leading to trade-offs in recall and precision.
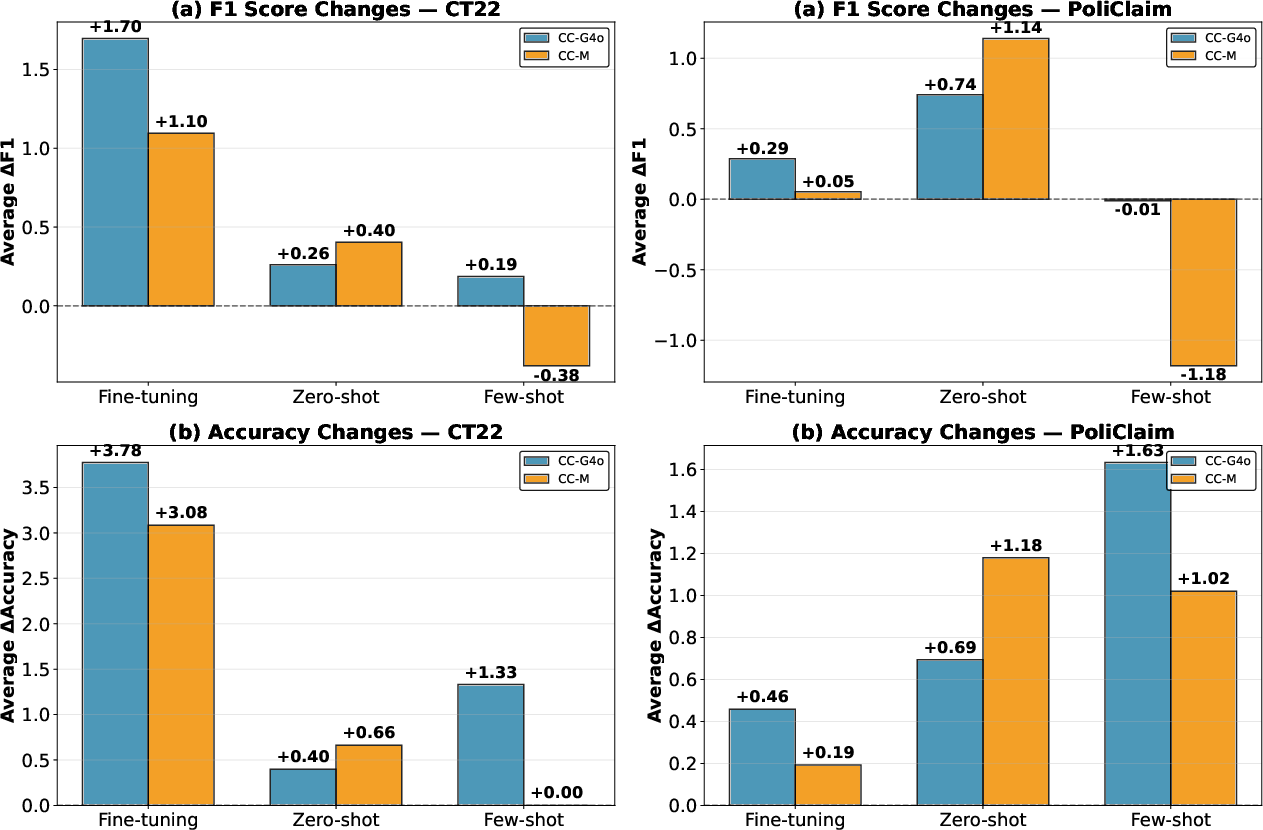
Figure 4: Learning Setting Comparison.
Error Taxonomy and Analysis
Detailed error analysis on CT22 reveals paradigm-level and architecture-specific failure modes. The context-augmented decoder-only Llama3 model, when provided with factual context, frequently shifts from false negatives to false positives, predicting verifiability whenever entity context is supplied, even for subjective or anecdotal claims. Conversely, encoder-only RoBERTa utilizes cross-attention to suppress such false positives, but at the risk of increasing false negatives if context mismatches or is missing.
The main error drivers in context-augmented models are:
- Opinion/policy/subjective surface forms: Factual context triggers "verifiable" predictions even for claims lacking checkable content.
- Inadequate entity retrieval: Absence or misalignment of retrieved context leads to undetected verifiable claims.
- Humor/anecdote misclassification: Narrative style combined with entity context increases spurious verifiability detection.
- Context ambiguity: Retrieved information confirms entity existence but does not clarify event documentability.
These findings underscore the dependence of context-driven systems on retrieval specificity and context summary expressiveness.
Human Assessment and Prompt Effects
Human annotators rate both summarization models (GPT-4o, Mistral) highly on topical relevance but substantially lower on signal clarity and practical utility for verifiability assessment. This supports empirical results indicating relevance alone is insufficient for decision calibration. The limiting factor is therefore the extraction of decision-relevant signals—such as entity reality, event historicity, and checkability—from context.
Prompt bias significantly affects model operating points in in-context settings. Instructions to default to "Yes" under uncertainty inflate recall (sometimes to near 1.0) but degrade precision. Ablation of this directive rebalances performance, but typically at the expense of lower F1 due to increased type II errors. The optimal prompt structure remains highly sensitive to both dataset and backbone LLM.
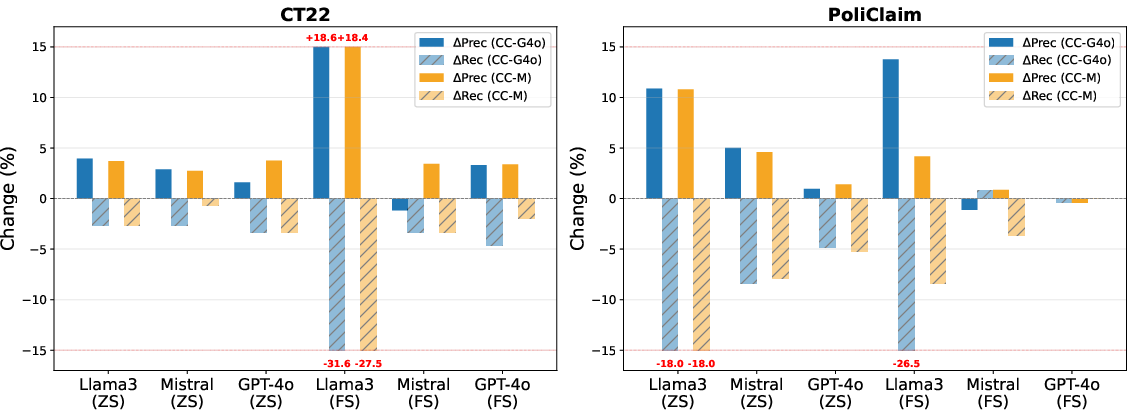
Figure 5: Effect of Removing Prompt Bias: Precision vs Recall Trade-off.
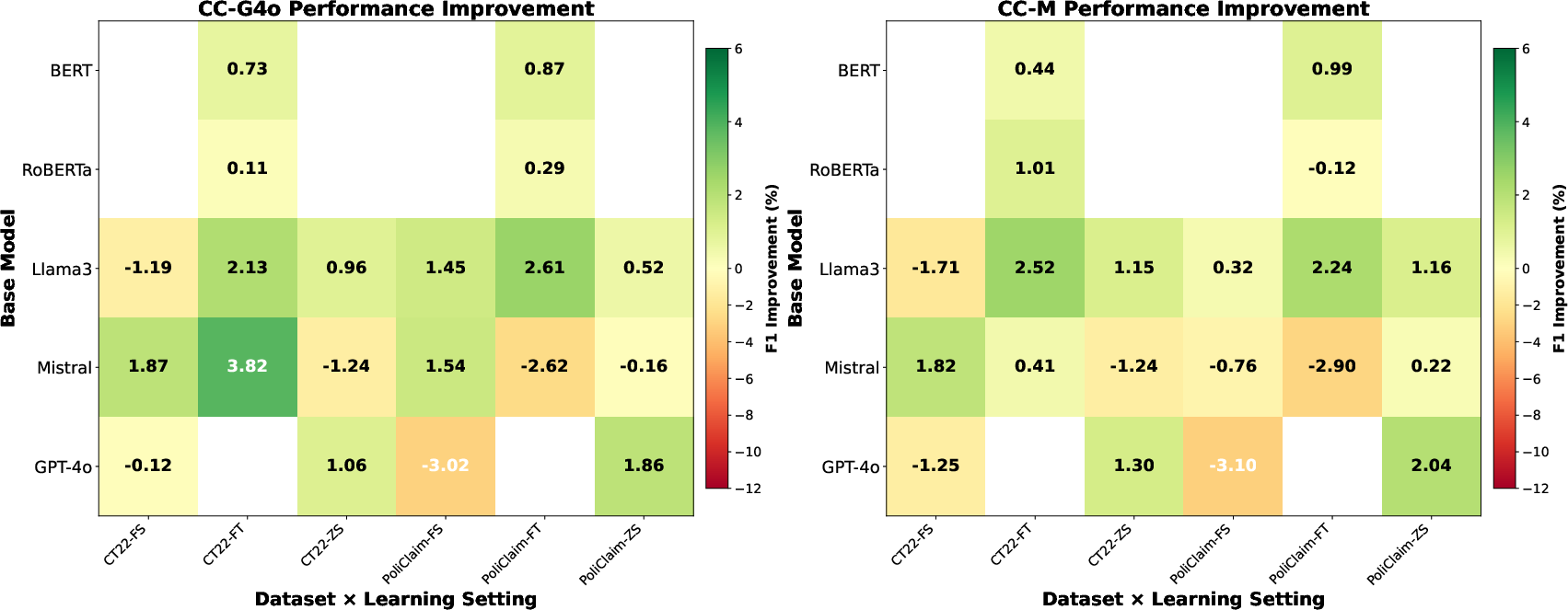
Figure 6: Performance Improvement on two Datasets with three Settings.
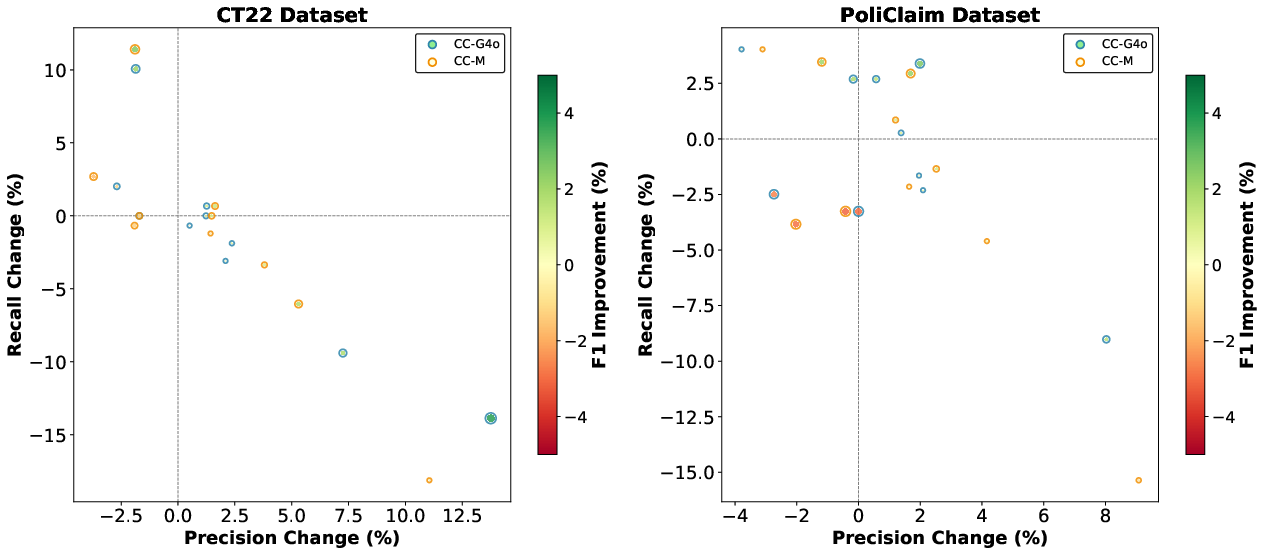
Figure 7: Precision-Recall Trade-off on Two Datasets.
Theoretical and Practical Implications
By reframing verifiability as a function of both claim linguistic content and evidence retrieval feasibility, ContextClaim operationalizes a more objective, evidence-grounded foundation for claim detection, diminishing reliance on subjective or time-variant importance heuristics typical of check-worthiness estimation. This paradigm enables detection models to anticipate the success of downstream verification stages and aligns AFC pipelines with rational task decomposition: non-verifiable claims can be reliably eliminated upstream, minimizing annotation and retrieval costs.
Empirically, results demonstrate that—subject to retrieval/summarization/model compatibility—incorporating even noisy external context can outperform advanced LLM-only (parametric-knowledge dependent) verifiable claim annotators. The findings on model/context stability suggest that future progress depends less on scaling LLM parameters and more on co-design of retrieval quality, context distillation, and cross-modality integration. Given the instability observed in weakly supervised/few-shot settings, robust context ingestion architectures and prompt-expressive strategies merit further investigation.
Future Directions
The research highlights three primary bottlenecks:
- Context Distillation Quality: LLM summarizers struggle to consistently produce explicit, verifiability-relevant signals, necessitating research into targeted, classifier-aligned context filtering strategies.
- Knowledge Base Limitations: Wikipedia coverage, while empirically adequate for high-profile entities/events, is insufficient for emerging domains, necessitating extension to multi-source or specialized repositories.
- Standardized Evaluation: Systematic evaluation of context-driven claim detection paradigms across diverse genres and annotation schemes remains open.
Given escalating misinformation volume and diversity, a robust, generalizable framework such as ContextClaim could form the substrate for more transparent, evidence-driven AFC systems and facilitate end-to-end verifiability reasoning that is both more reliable and interpretable.
Conclusion
ContextClaim presents a structured, retrieval-augmented paradigm for verifiable claim detection, bridging the gap between claim text analysis and evidence-driven verification stages. Through robust experimentation and granular analysis, the framework demonstrates that context augmentation regularly, but not universally, enhances detection accuracy, with the magnitude and robustness of benefit a function of architectural compatibility and learning regime. The principal limitation remains the translation of retrieved evidence into clear, decision-relevant context. Advances in entity disambiguation, domain-adaptive retrieval, and task-focused summarization will be critical for unlocking the full potential of context-driven claim detection architectures.