- The paper demonstrates that an LLM-guided curriculum improves sample efficiency, reducing training time by 74% while boosting win rates in complex Blackjack environments.
- The methodology employs action masking and staged curriculum adaptation to mitigate exploration complexity and stabilize performance in both DQN and Tabular RL agents.
- Quantitative results reveal improved win and reduced bust rates, with optimal policy performance achieved at an intermediate curriculum stage before full action exposure.
LLM-Guided Curriculum Learning for Efficient and Robust Blackjack RL
Introduction and Motivation
This paper proposes an LLM-guided curriculum learning framework for RL agents in the domain of Blackjack, leveraging a LLM (Gemini 2.0 Flash) to generate a staged progression over agent actions. Traditional RL methods, particularly in environments with expanded or high-dimensional action spaces like Blackjack, often encounter intractable exploration complexity and policy instability, induced by the simultaneous availability of all possible actions. By contrast, this framework incrementally introduces actions according to their game-theoretic complexity, which is adaptively controlled based on the agent’s learning progress. The system’s efficacy is evaluated using both Tabular Q-Learning and Deep Q-Network (DQN) agents across several Blackjack environments, focusing primarily on a realistic, 8-deck casino setting.
LLM-Guided Curriculum Learning Framework
The core contribution is a tightly integrated curriculum mechanism powered by the Gemini LLM, which operates in a closed loop: (1) generating an initial curriculum where only a subset of actions is available, (2) receiving structured agent performance summaries after each stage, and (3) adaptively updating the curriculum and success thresholds based on these summaries. A major operational principle is action masking—unavailable actions are explicitly disallowed, thereby making exploration more focused and reducing early-stage sample complexity.
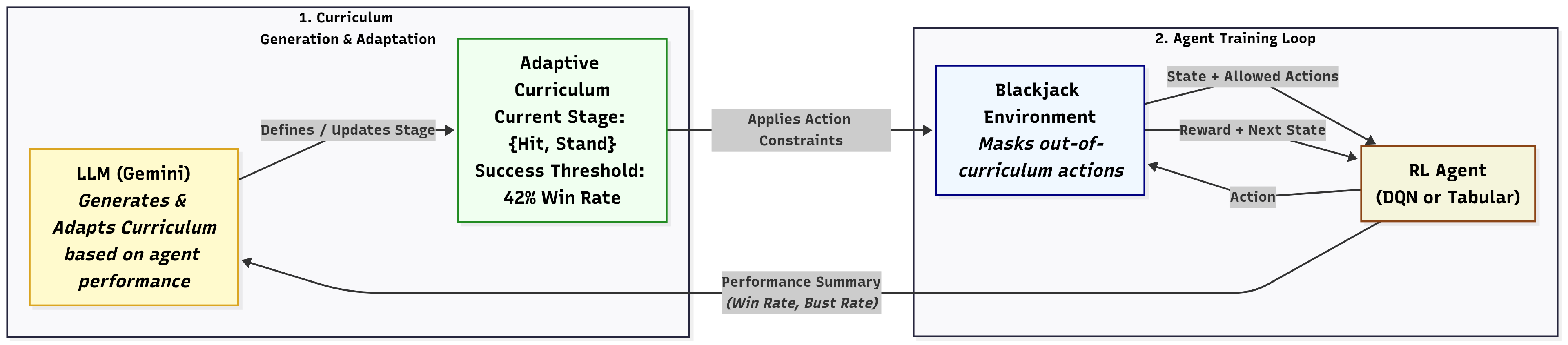
Figure 1: The LLM-guided curriculum learning system dynamically generates training stages and thresholds, gating agent actions and adapting based on the agent’s performance.
The system also provides real-time enforcement (no out-of-curriculum actions) and robust fallback mechanisms (curriculum freeze on LLM/API response failure). The LLM is prompted with high-level game context, available actions grouped by complexity, and feedback as concise JSON performance statistics.
Experimental Methodology and Baselines
Evaluation contrasts the LLM-guided curriculum with standard RL baselines, where all actions are immediately accessible. The DQN agent is a three-layer MLP with experience replay, and the Tabular agent employs frequency-adapted step sizes. Both agents use ϵ-greedy exploration with staged decay. Experiments span 1, 4, 8, and infinite-deck environments, with the 8-deck case representing the key scenario due to its realism in casino play. Each protocol is repeated with 10 random seeds, dynamically engaging the LLM in real time.
Quantitative Results
In the 8-deck condition, the LLM-guided curriculum boosts the DQN's average win rate from 43.97% (baseline) to 47.41%, and reduces the bust rate from 32.9% to 28.0%. Training efficiency is dramatically improved; the curriculum protocol is completed in 12.5 minutes on average versus 48.4 minutes for the baseline training, a 74% acceleration—such that the total curriculum training time is shorter than the baseline agent's evaluation runtime, not just its training. All performance comparisons are based on statistically robust results from multiple seeds and full-length evaluation rollouts.
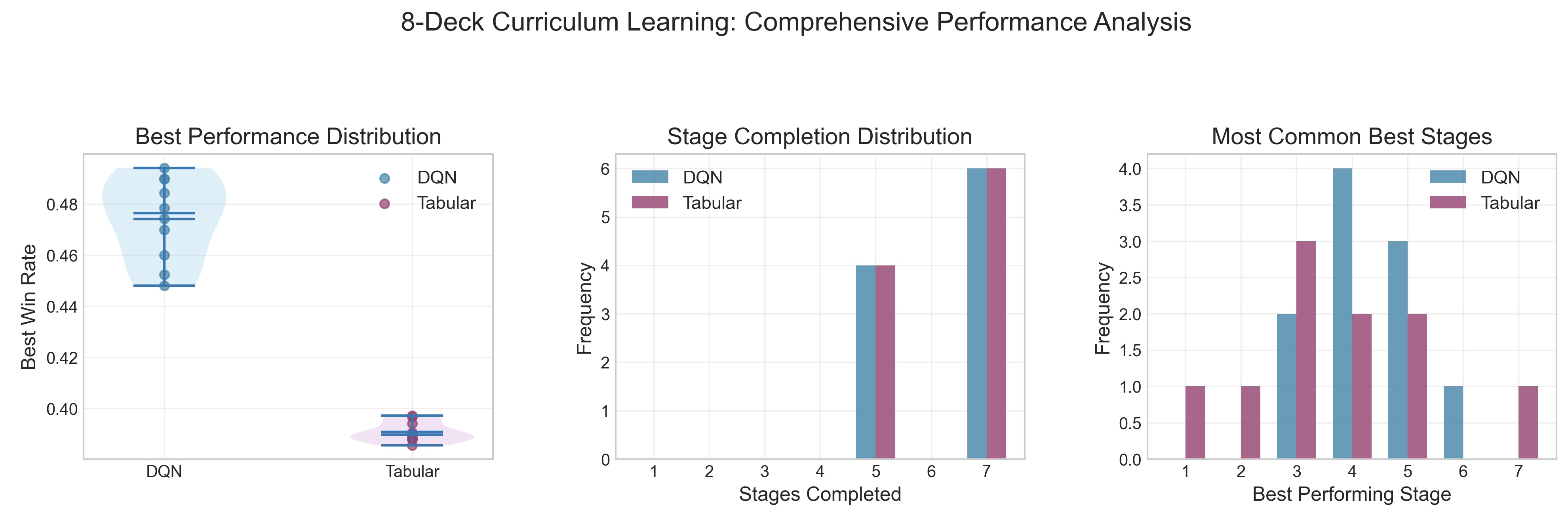
Figure 2: Curriculum-trained DQN agents achieve higher performance, with peak outcomes most often at an intermediate curriculum stage.
The volatility and instability that characterize DQN training on the unpruned action space are eliminated via curriculum learning.
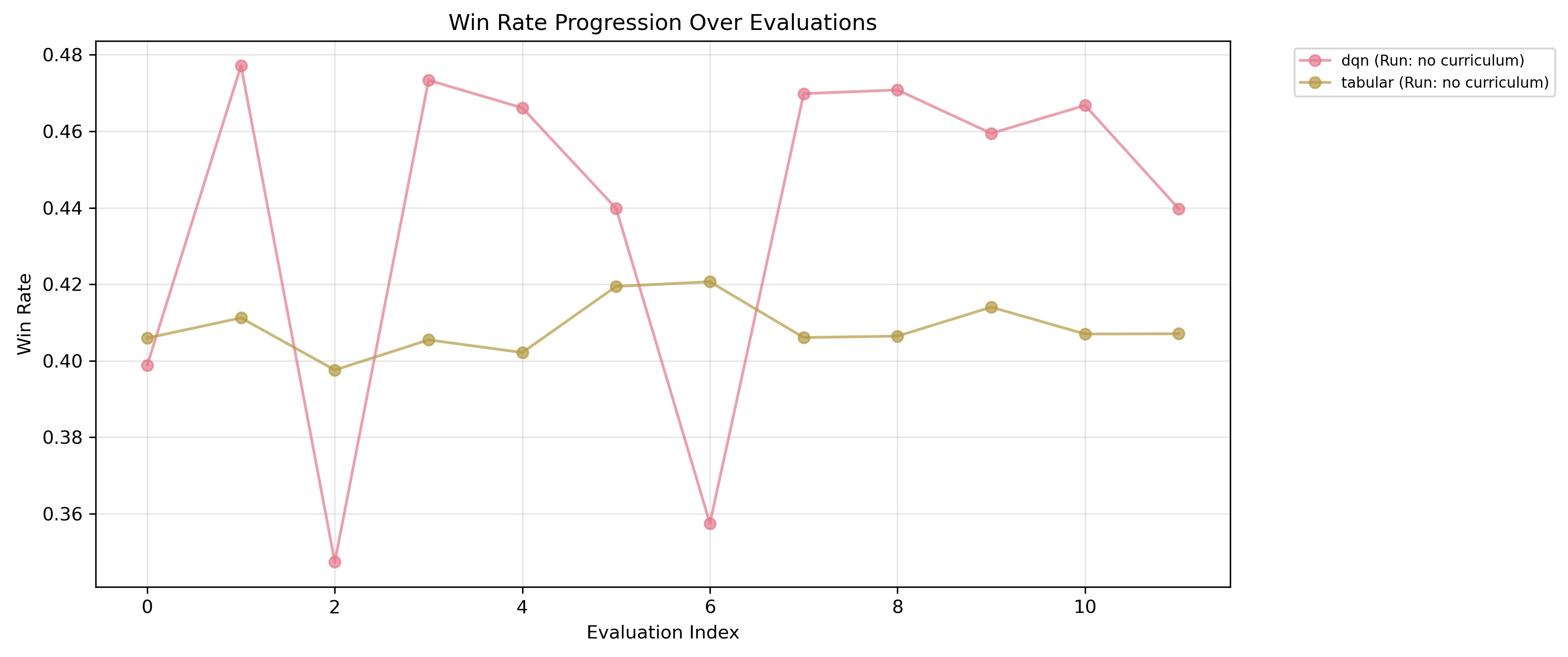
Figure 3: Training without curriculum yields volatile and inconsistent learning curves, with DQN agents often regressing after transient policy improvements.
After curriculum introduction, learning trajectories stabilize, and agents are more reliably able to exploit higher-order tactics (e.g., Split, Double Down).
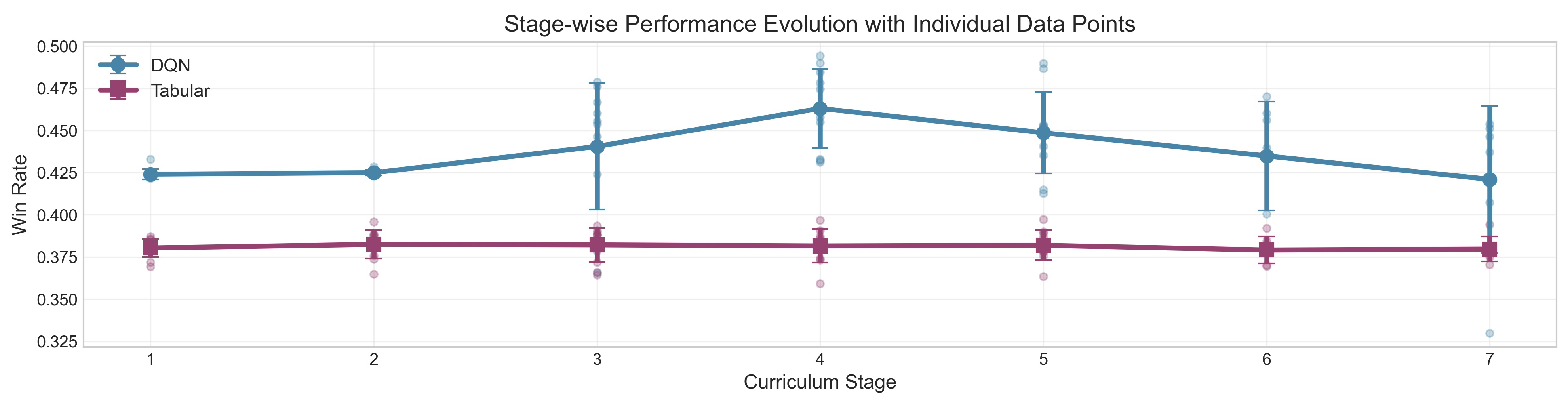
Figure 4: The curriculum-constrained agent learns in a smooth, monotonic fashion, achieving consistent and high win rates.
Notably, the best agent performance is observed before all actions are enabled: final policy quality peaks at an intermediate stage (Stage 4; all basic actions but excluding Insurance and Surrender), after which introducing further complex, high-risk actions results in decay of average reward.
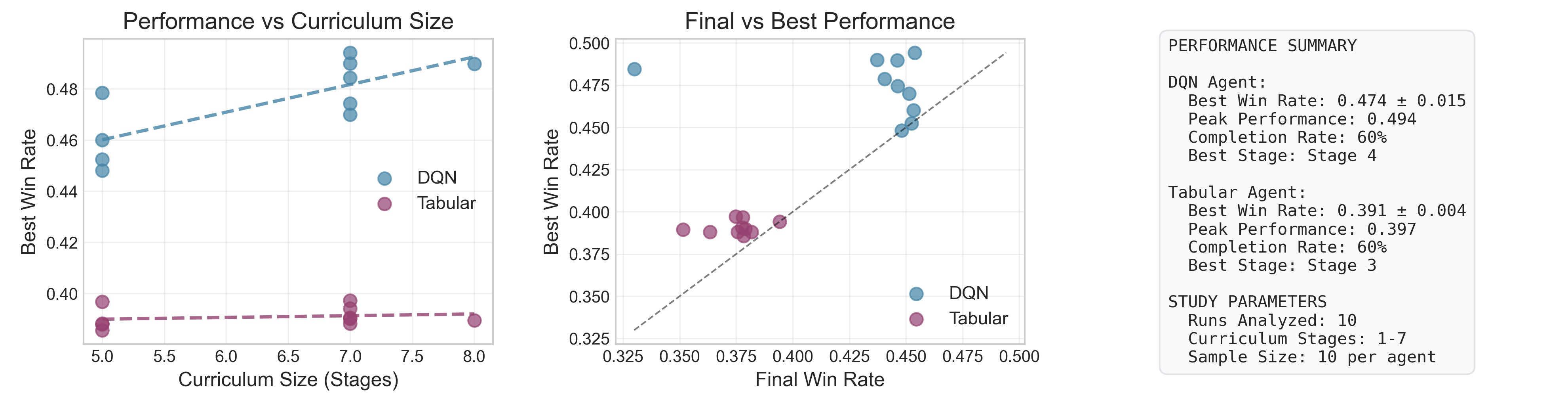
Figure 5: There is a positive correlation between curriculum progress and peak win rate, but the best results are not always at the final (most complex) stage.
Qualitative Policy Analysis
Strategy heatmaps show that curriculum-trained agents infer and execute structured policies that closely resemble human "basic strategy". In comparison, baseline-trained agents produce less coherent, under-specialized strategies with diffused decision boundaries and poor exploitation of domain-optimal plays (e.g., rarely doubling down with hard 11).
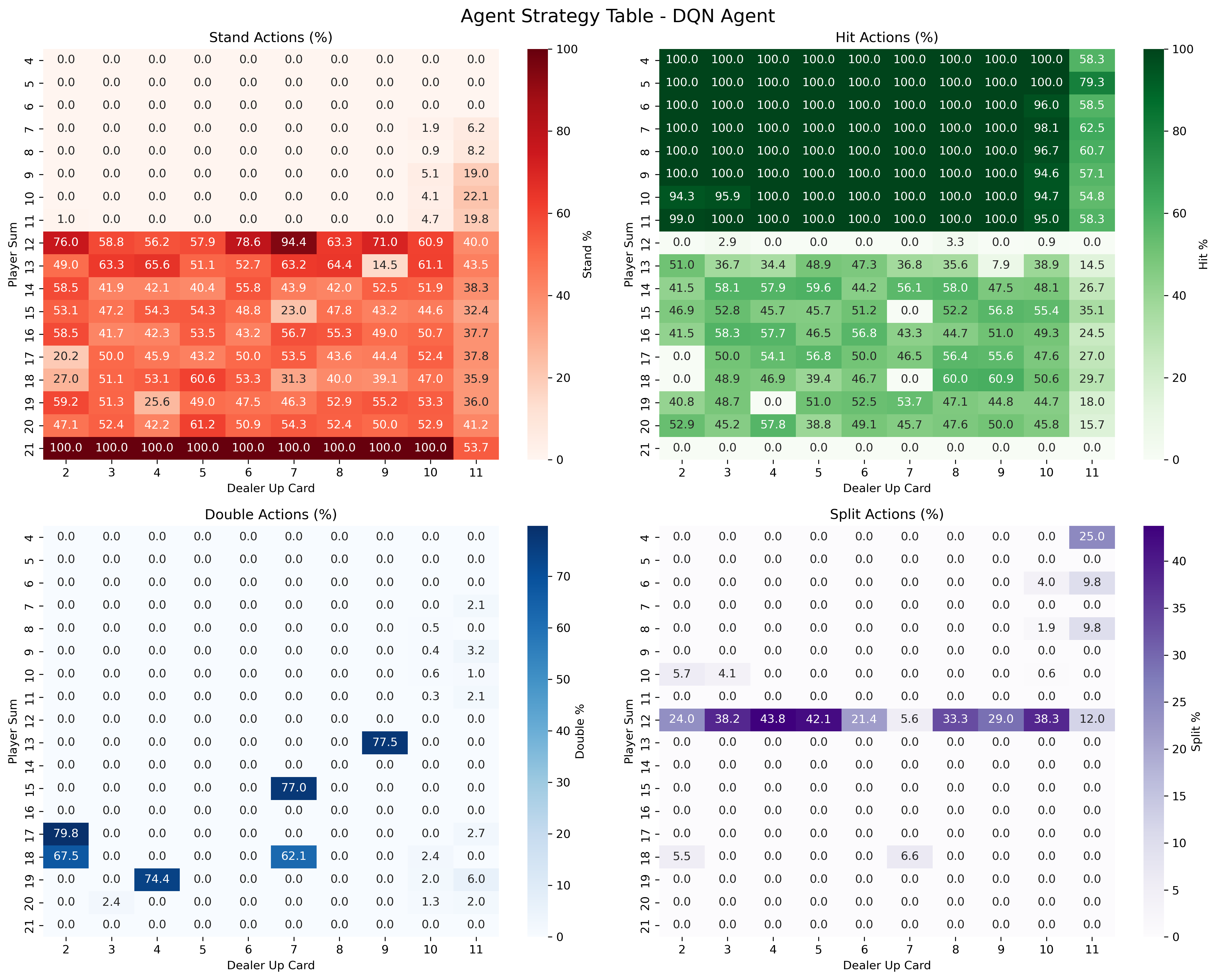
Figure 6: Agent trained without curriculum exhibits diffuse, unstructured strategy with underuse of tactical actions.
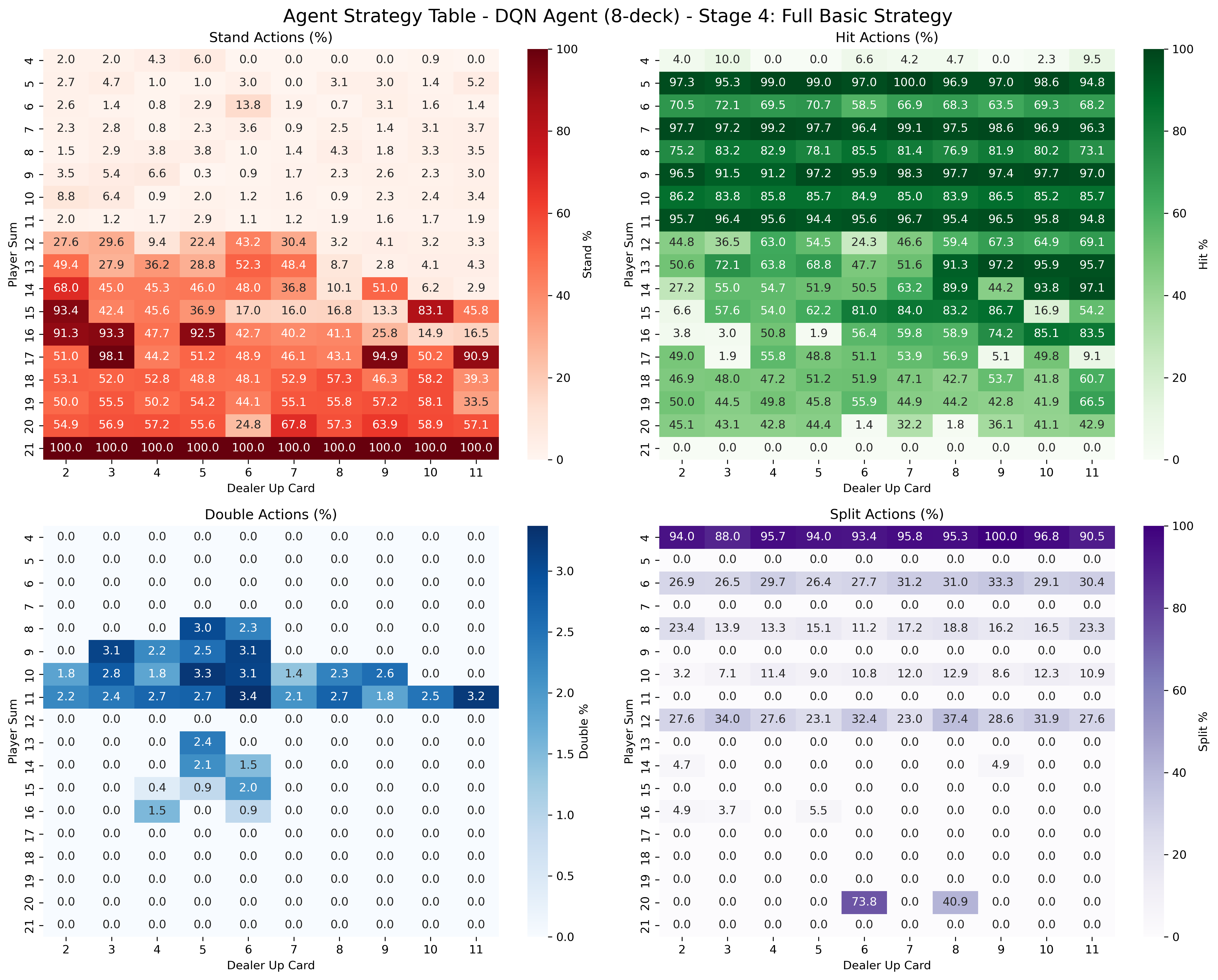
Figure 7: Curriculum-trained agent demonstrates crisp, state-dependent boundaries for advanced actions, indicating better strategic knowledge generalization.
Comparative Analysis and Agent Architecture Effects
While both DQN and Tabular agents benefit from the action curriculum, the DQN agent profoundly outperforms the Tabular model due to the greater capacity for function approximation and conditional behavior learning; the latter is less able to capture state-specific strategies, particularly as the number of environment states explodes with deck size and card counting features.
Comparisons across all deck sizes consistently confirm the curriculum’s positive impact on sample efficiency and final policy quality.
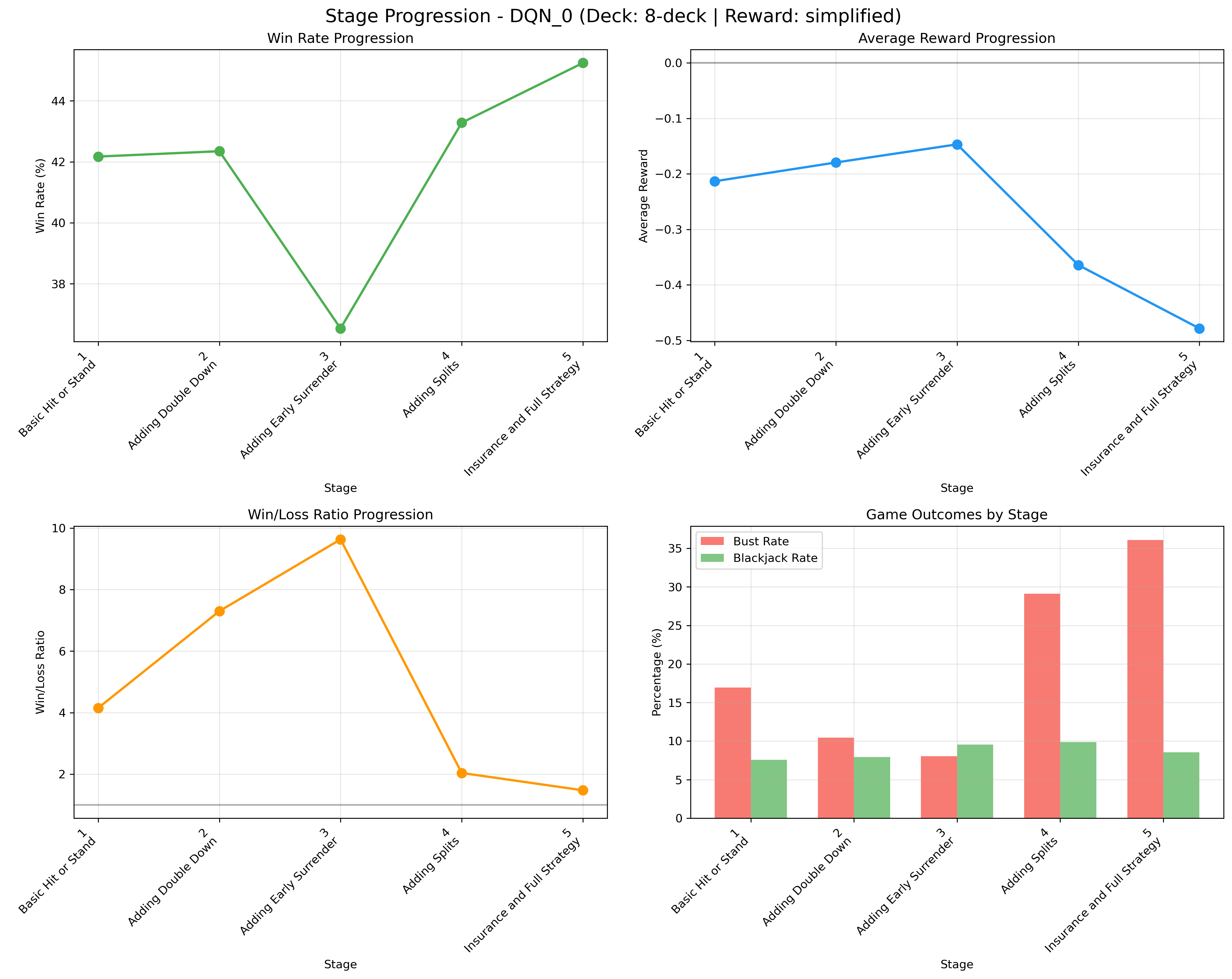
Figure 8: DQN learning progression traces through defined curriculum stages, illustrating bottlenecks and inflections at increased complexity levels.
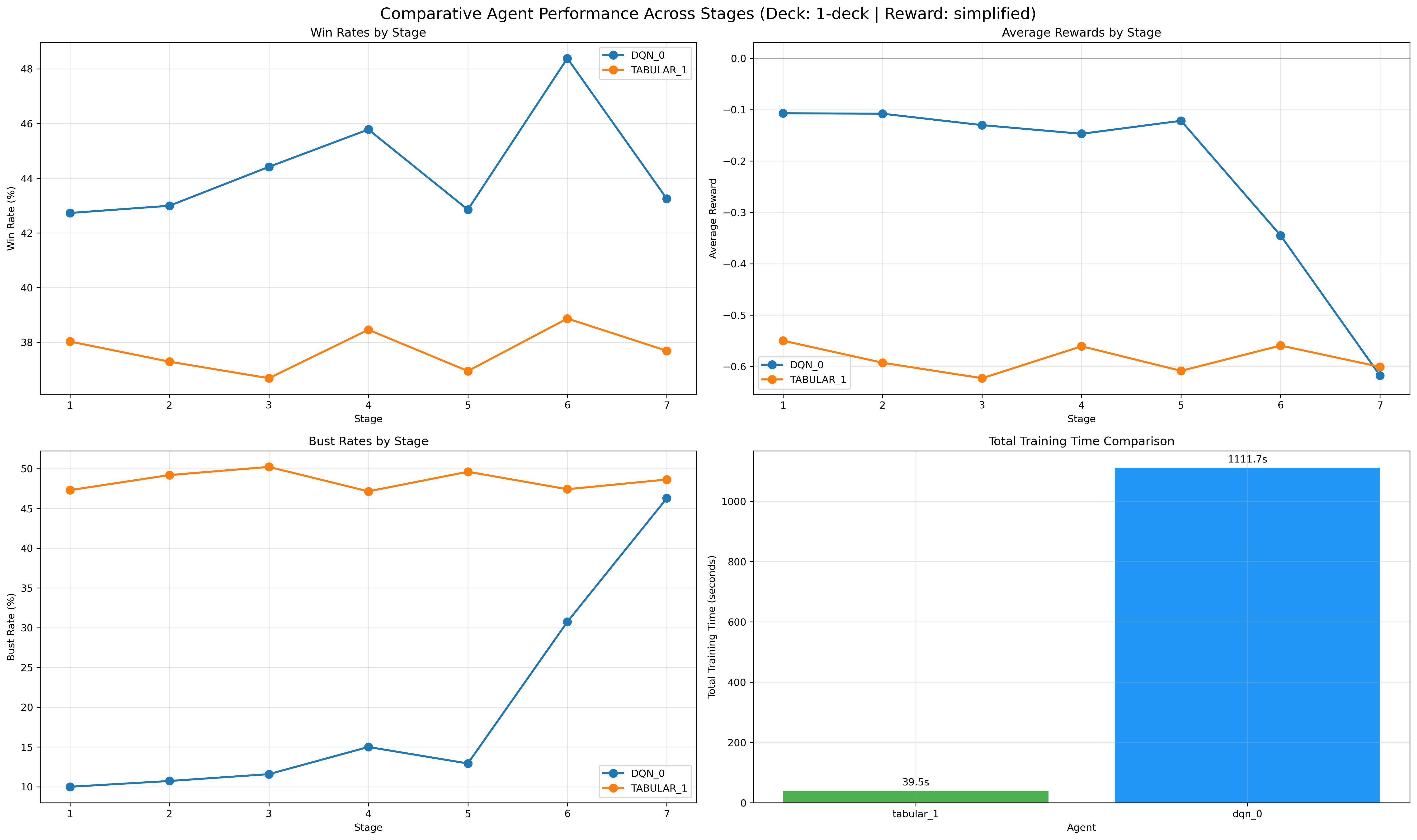
Figure 9: Comparative analysis in the 1-deck setting, showing curriculum advantage.
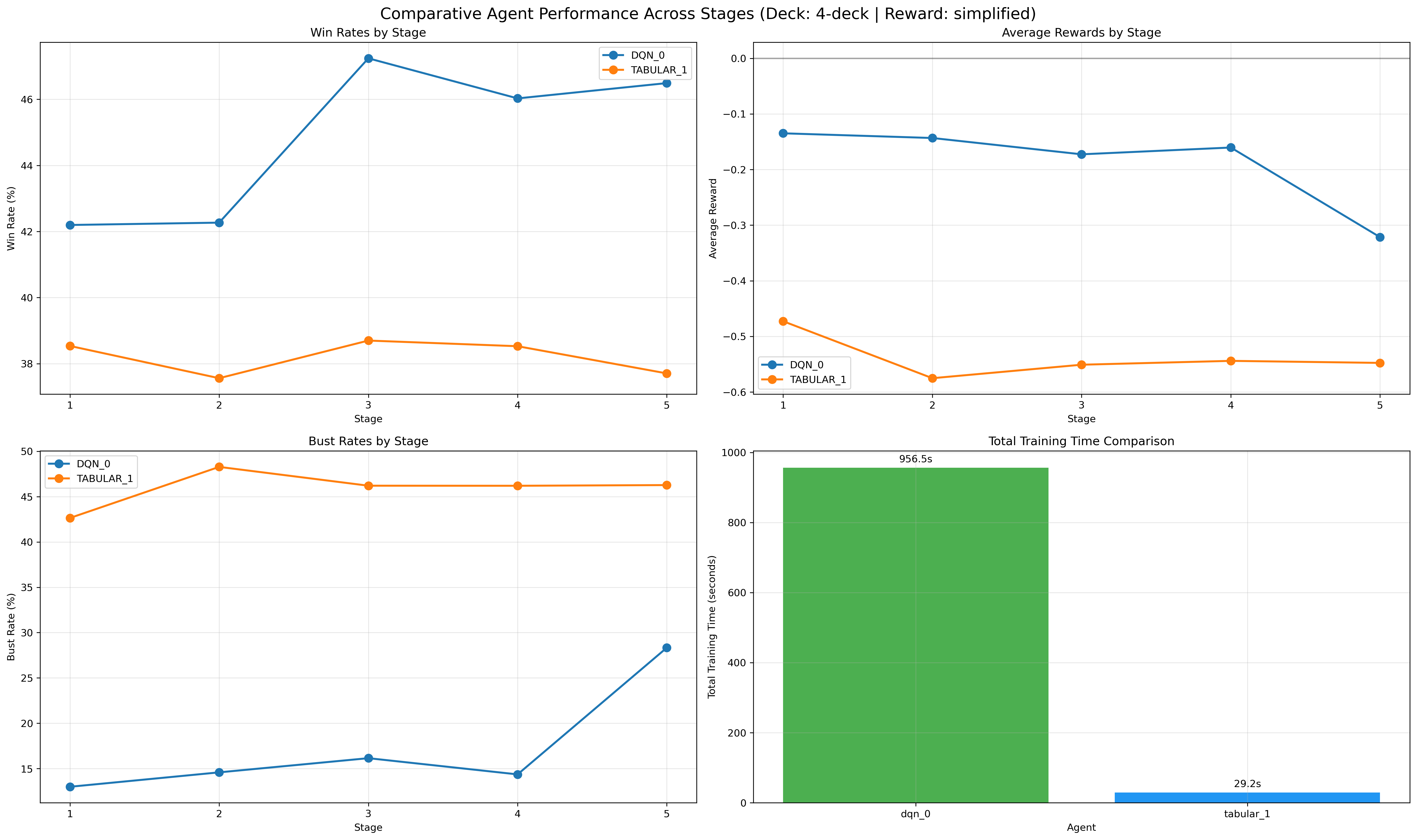
Figure 10: Consistent curriculum-induced win rate improvements in 4-deck environments.
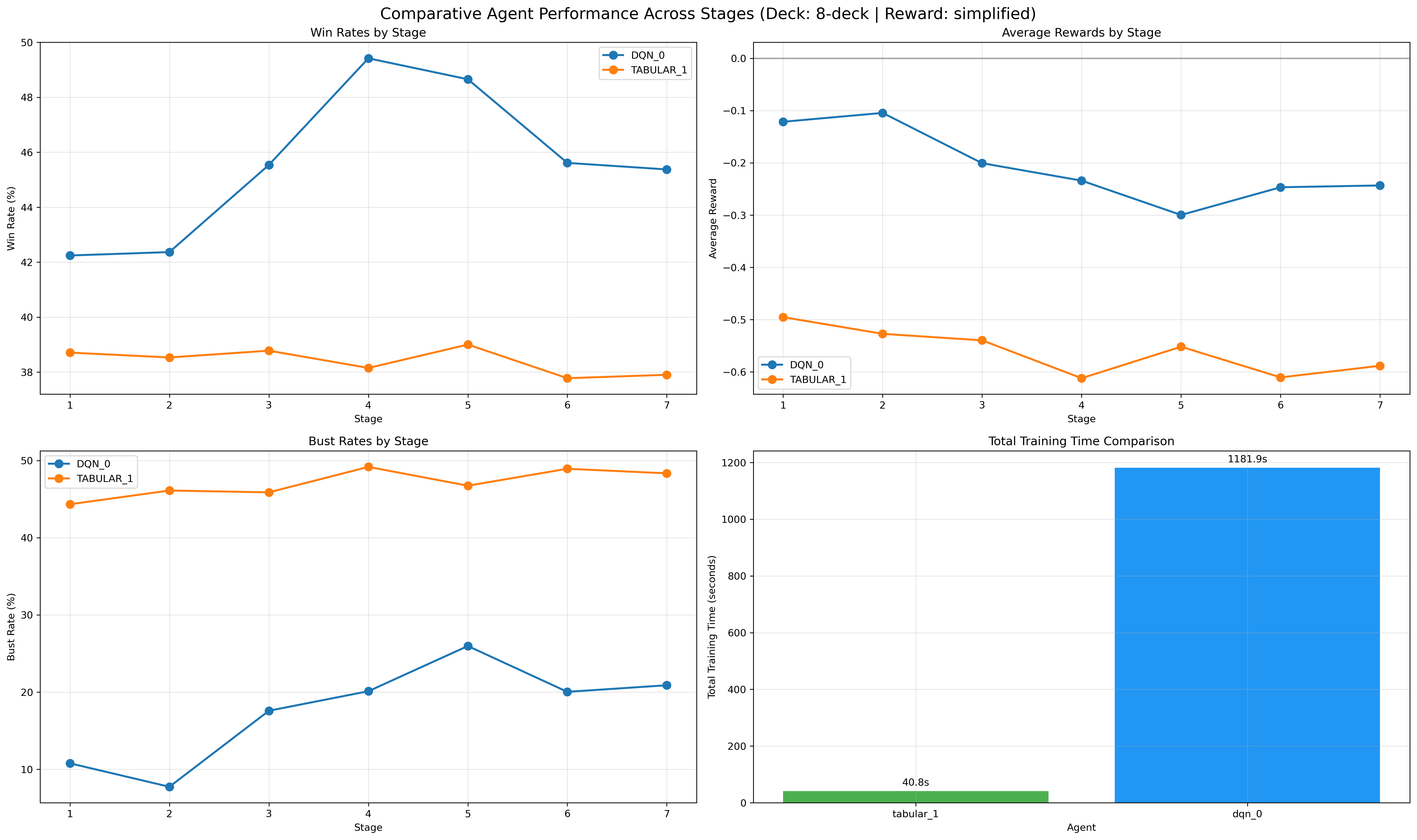
Figure 11: 8-deck scenario, with curriculum effect evident even as state complexity increases.
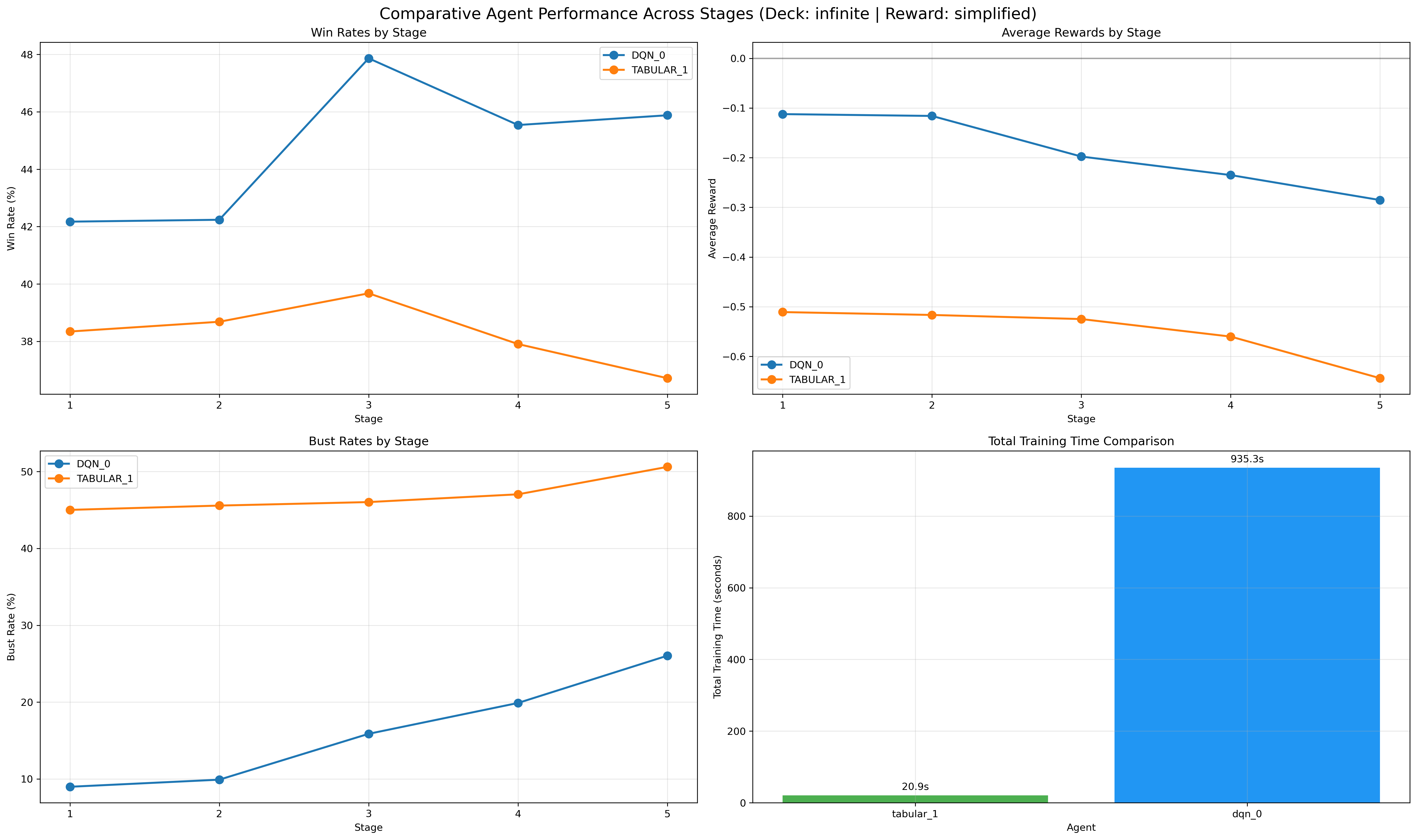
Figure 12: Infinite-deck analysis demonstrates framework robustness regardless of environment scale.
Theoretical Implications and Future Directions
The action-masked curriculum approach demonstrates that staged task decomposition, guided by LLMs, can dramatically reduce exploration complexity and improve RL sample efficiency in domains with modular tactics. This method establishes a strong precedent for the integration of LLM reasoning into agent curriculum design, serving as a pedagogical proxy to human domain experts.
A key finding is that the optimal policy for maximal win rate does not always coincide with the maximal action set—the opportunity to halt curriculum progression at a best-performing stage is currently absent and merits explicit integration into future frameworks. Moreover, given the heavy dependence on LLM behavior and its inherent stochasticity and possible non-determinism (due to proprietary model updates), strict reproducibility is recognized as unattainable unless the LLM weights and decoding pipelines are version controlled.
The current curriculum design’s modularity implies potential transferability to other RL tasks; however, extension to settings with continuous or unstructured action spaces remains nontrivial. The utility of richer LLMs (e.g., GPT-4, LLama2) and advanced prompting strategies for curriculum optimality is another avenue for investigation.
Conclusion
This paper systematically demonstrates that an LLM-guided curriculum based on staged action introduction and adaptive progression enables robust, efficient learning of complex tactical domains such as Blackjack. The combination of structured curriculum generation, action masking, and real-time feedback leads to substantial improvement in both performance and sample efficiency for DQN and Tabular RL agents. Analysis reveals that the curriculum not only accelerates training and stabilizes learning but also produces interpretable strategies surpassing human expert-level play.
Broader implications indicate that LLM-guided curriculum frameworks provide a practical, generalizable scaffold for RL in diverse complex environments, especially those exhibiting modular task structure. Future work should integrate mechanisms for curriculum early stopping, handle continuous action decompositions, and address long-term reproducibility in LLM-dependent methodologies.