- The paper demonstrates that superposition causes standard alignment metrics (RSA, CKA, linear regression) to deflate even when latent features are identical.
- Analytical expressions show that alignment scores decrease with the compression ratio (m/n), reflecting confounds in measuring true feature overlap.
- Empirical simulations validate the theoretical predictions, underscoring the need for feature recovery techniques like dictionary learning in alignment analysis.
Measuring Representational Alignment in Neural Systems under Superposition
Introduction
The problem of quantifying representational alignment between neural systems is central to both theoretical neuroscience and the interpretation of artificial neural networks. Standard alignment metrics—such as Representational Similarity Analysis (RSA), Centered Kernel Alignment (CKA), and linear regression-based measures—typically operate directly on raw neural activations, implicitly equating representational similarity with similarity in neural activity patterns. However, the coding mechanism of superposition—in which networks encode more features than available neurons by linear compression—poses a significant challenge to these metrics. This paper, "Measuring the Representational Alignment of Neural Systems in Superposition" (2604.00208), presents a rigorous mathematical and empirical analysis of how superposition confounds standard approaches to representational alignment, highlights systematic biases introduced by compression, and offers prescriptions for future methodology.
Superposition and Its Consequences for Alignment Metrics
Superposition refers to the scenario where a neural system linearly projects a high-dimensional latent vector z∈Rn into a lower-dimensional neural activation y=Az, where A∈Rm×n and m<n. This phenomenon inherently produces mixed selectivity or polysemantic neural activations, with individual neurons contributing to multiple latent features. Compressed sensing theory ensures that, provided the latent code is sparse and A satisfies the restricted isometry property, the original features can theoretically be recovered from y without loss [donoho_compressed_2006]. Thus, the intrinsic feature content is unchanged, but the arrangement and mixture of features across neural coding directions may vary arbitrarily between networks.
When raw activations Ya and Yb from two such systems (with different Aa and Ab) are compared using linear metrics, spurious misalignment is detected—even if both systems encode identical features. This is visually articulated in the paper’s illustrative core figure.
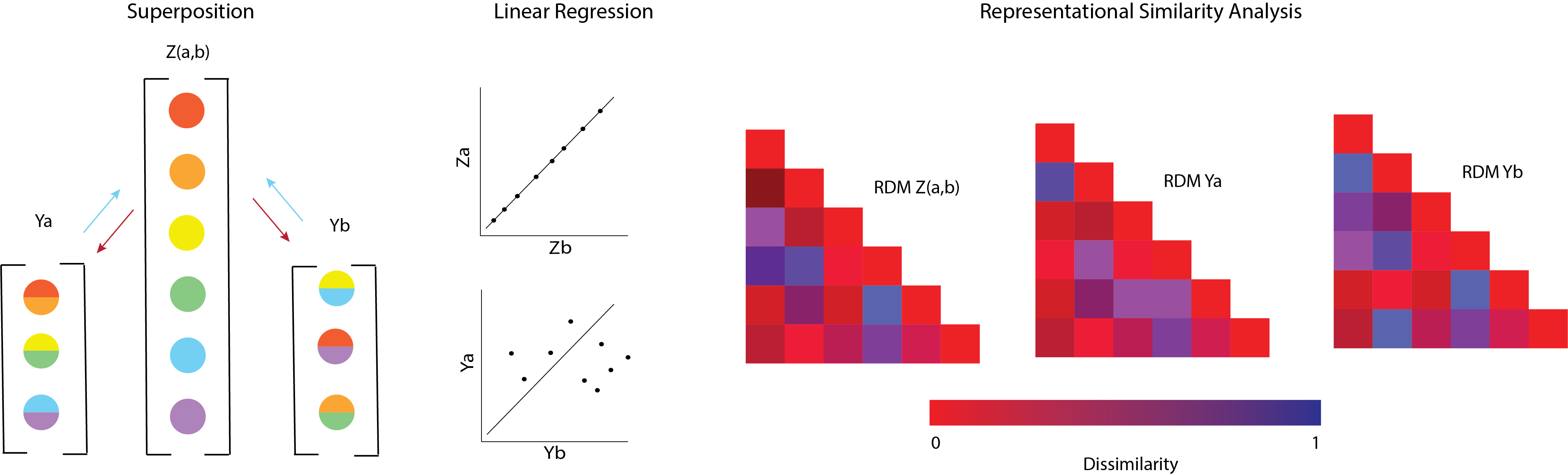
Figure 1: The confounding effect of superposition on representational alignment; identical latent features yield distinct activations under different compression matrices, artificially lowering measured alignment.
Mathematically, the crux is that alignment metrics such as RSA and linear CKA depend not on the latent features per se, but on the Gram matrices y=Az0 that encode the geometry of the projected space. Thus, similarity measures are confounded by arbitrary differences in projection, not only the “what” but heavily by the “how” of neural coding.
Theoretical Analysis of Alignment under Superposition
The authors derive asymptotic analytical expressions for the three major classes of alignment metrics, assuming random i.i.d. features and compression:
- RSA/CKA with Linear Kernel:
The expected alignment between two systems is given by the normalized Frobenius inner product of their Gram matrices:
y=Az1
For y=Az2 chosen at random, the expected value of alignment is approximately y=Az3 in the high-compression (y=Az4) regime. Thus, as the dimension of the activity space decreases, alignment scores approach zero even when feature content is identical.
The optimal regression weights and y=Az5 (explained variance) are similarly reducible to functions of the projection matrices, with maximal achievable alignment always bounded by the degree of shared projection structure.
Analytical Results
- Monotonic Decrease of Raw Alignment with Compression:
The closed-form expressions predict, and simulations confirm, that all metrics decrease monotonically as the compression ratio y=Az6 falls, despite identical latent content.
- Apparent Misalignment is Not Informational Loss:
Within the compressed sensing regime, all latent information is preserved and recoverable (i.e., feature sharing remains maximal), yet the alignment scores remain deflated due to differing projections.
Empirical Validation
Extensive simulations are performed using random Gaussian projections and sparse latent variables to validate the theoretical predictions:
- For fixed features and increasing compression, both RSA, linear CKA, and linear regression y=Az7 decrease as predicted.
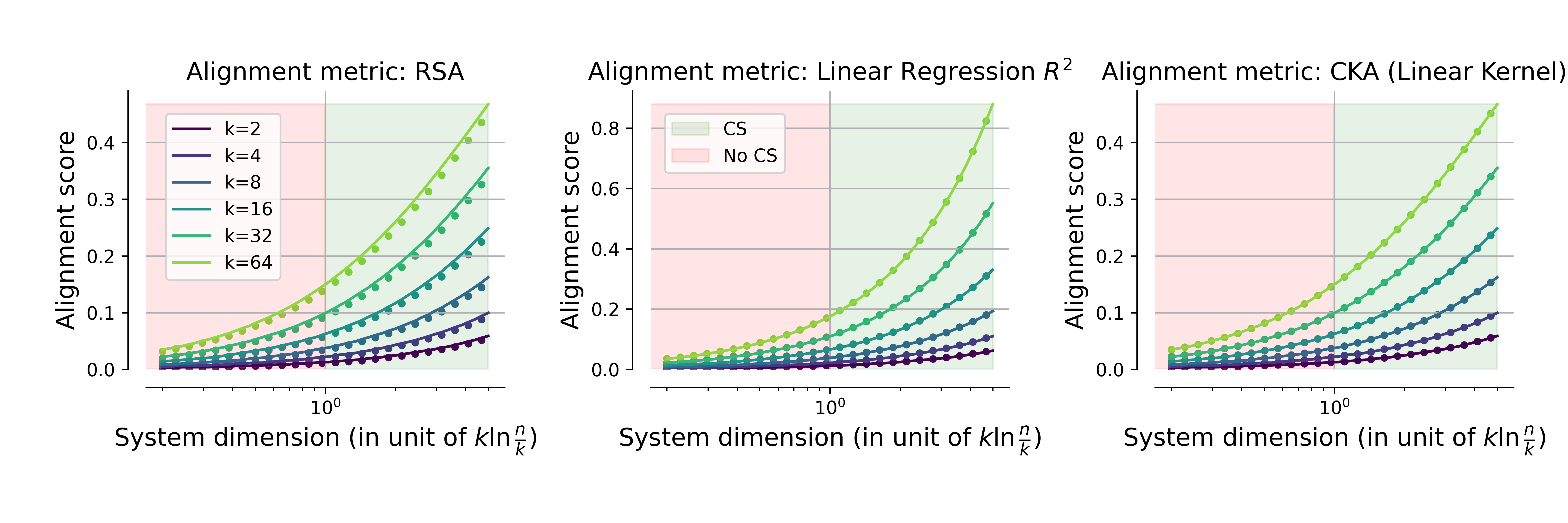
Figure 2: Alignment scores for RSA, linear regression y=Az8, and linear CKA as functions of system dimension y=Az9 (relative to compressed sensing threshold); analytical predictions (lines) and empirical simulations (dots) are in strong agreement.
The critical transition between full latent recoverability (A∈Rm×n0) and unrecoverable regimes is also reflected in the measurements.
Implications for Feature Overlap
The analysis is extended to the case where networks share only a fraction of their features. Let A∈Rm×n1 be the geometric mean-normalized ratio of overlap. One would hope that alignment would increase monotonically with increasing A∈Rm×n2, faithfully tracking computational similarity. In practice, the interaction between projection compression and overlap is not monotonic; the degree of superposition can invert the expected order—networks sharing fewer features may report higher alignment than those sharing more, if the latter are more compressed.
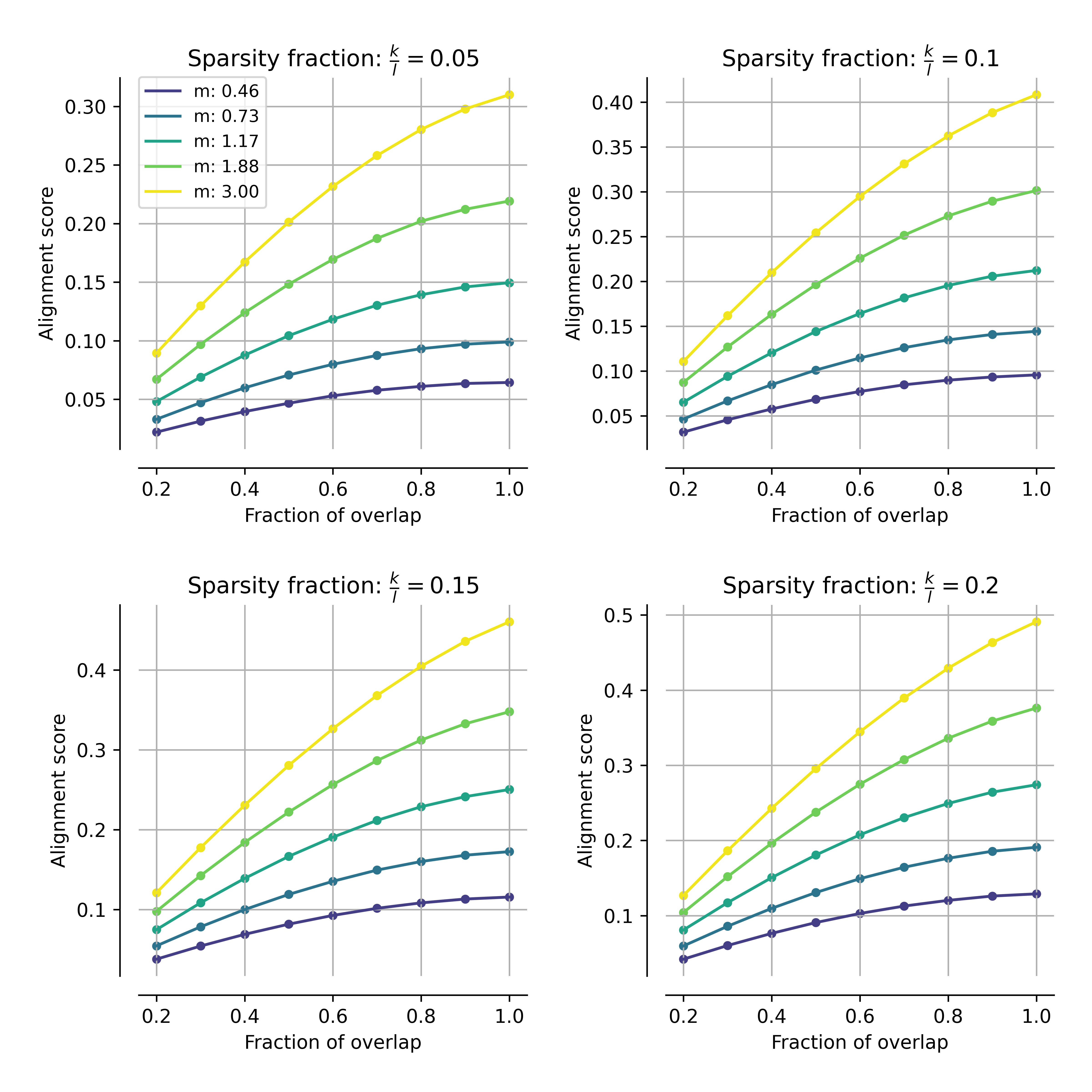
Figure 3: Alignment measured by CKA as a function of feature overlap ratio A∈Rm×n3, for multiple superposition regimes; greater overlap yields higher alignment, but overall scores remain modulated by compression.
In the more general case where systems differ in their degree of compression, the effect is exacerbated. Regions exist where systems with relatively low true feature overlap can appear to have greater alignment than fully overlapping systems, simply due to differences in superposition.
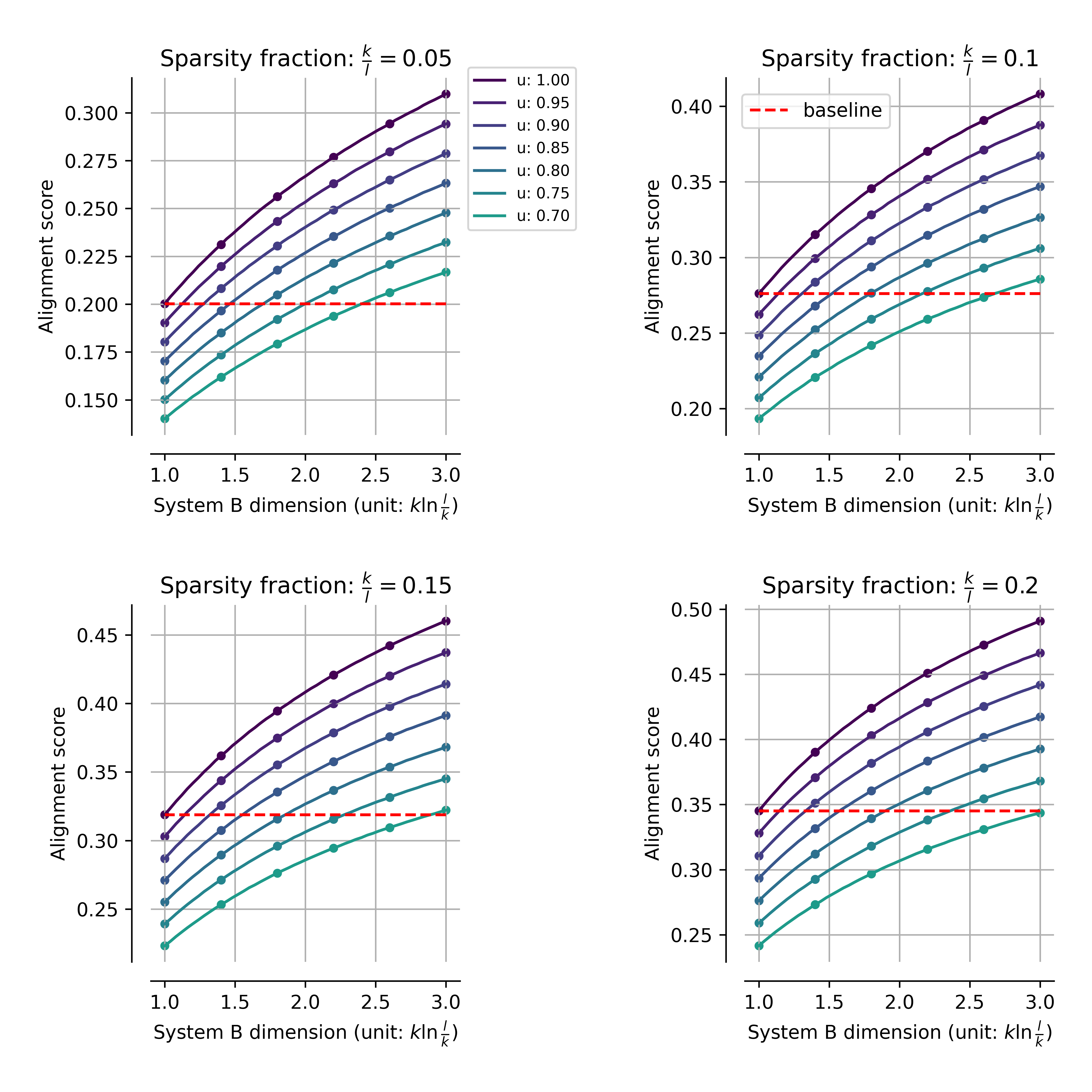
Figure 4: Alignment as a function of system A∈Rm×n4's compression for partial and full overlap; for sufficiently strong compression, systems sharing fewer features can appear more aligned than perfectly overlapping systems, a direct artifact of superposition.
Theoretical and Practical Implications
Methodological Prescription
The core methodological implication is that alignment analyses based on raw activations are fundamentally limited and confounded in the presence of superposition. Reliable measurement of shared representations requires analytic or algorithmic recovery of the underlying latent features—i.e., dictionary learning, sparse coding, or similar techniques [cunningham2023sparse, bricken2023towards, lan2024sparse, olshausen1997sparse].
Impact on Empirical Trends
The consistent finding that raw-measured alignment correlations increase with model size is canonically interpreted as an indicator of higher representational congruence in larger models [huh2024platonic, elmoznino2024high, kornblith2019similarity]. The present analysis reveals that this may be an artifact of reduced superposition in high-dimensional systems, not deeper computational similarity.
Future Directions in AI
Further theoretical and empirical effort is warranted to:
- Quantify alignment in latent space via identifiability-based feature recovery.
- Investigate the precise geometry of superposition, particularly how local versus global alignment metrics are differentially affected [groger2026revisitplatonic].
- Establish robust pipelines for alignment benchmarking across neural and artificial systems that explicitly account for superposition and redundancy.
Conclusion
This paper provides comprehensive theoretical, numerical, and empirical evidence that standard raw activation-based alignment metrics are systematically deflated by superposition in neural systems. The findings demand a refocusing from raw activation patterns to the comparison of underlying latent features for any analysis aimed at quantifying the similarity of neural computations in compressed representations. This framework necessitates the integration of feature extraction and dictionary learning as indispensable components of computational neuroscience and AI interpretability toolkits.