- The paper presents a certified set convergence framework for piecewise affine systems using a neural HJ value function and zonotope propagation to enable robust and scalable control.
- It introduces a three-stage pipeline that decouples policy and value function verification, overcoming conservative Lipschitz constraints typical in ReLU networks.
- Experimental results demonstrate 100% strict set containment and trajectory-level certification across challenging benchmarks in high-dimensional, mode-switching systems.
Certified Set Convergence for Piecewise Affine Systems via Neural Lyapunov Functions
Problem Statement and Motivation
The paper addresses the problem of verifiable set-wise control for discrete-time piecewise affine (PWA) systems under bounded additive disturbances. In such systems, safety-critical operation necessitates that a single control action robustly drives an initial state set toward a target, accounting for mode switching and the propagation of set fragments under distinct affine dynamics as sets intersect polyhedral mode boundaries. Classical approaches for set-based control or reachability either (1) operate on zonotope over-approximations without Lyapunov certificates, or (2) employ neural Lyapunov candidates for pointwise guarantees, but fail to extend to set-wise certification due to the curse of compositional Lipschitz bounds.
The primary technical bottleneck arises from the need to ensure that, for all x in the current set, one action simultaneously decreases the Lyapunov value across modes and disturbances. This couples the policy and value function Lipschitz constants, which can be egregiously loose for large ReLU networks, leading to an expressivity-certifiability trade-off that is well-documented in recent literature.
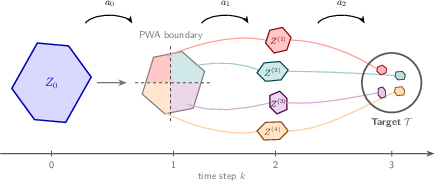
Figure 1: Certified set convergence for PWA systems over discrete time steps, with mode-boundary-induced fragmentation of the set and a common control steering all fragments.
Methodology
The framework resolves the certification barrier via a three-stage, decoupled pipeline:
- Neural Hamilton-Jacobi (HJ) Value Function as Lyapunov Candidate: The backward reachable set is encoded as a negative-level set of a deep HJ value function V∗, learned with a travel-cost reward structure through actor-critic RL (DDPG). Rewards are structured for vanishing values outside the target, and strictly negative within, ensuring that all non-target initial conditions yield V∗(x)≤0, with negative values characterizing reachability.
- Set-Based Policy Distillation: A pointwise oracle policy (actor) is employed to distill a set-based controller using a Deep Sets architecture. Zonotope fragments are tokenized into permutation-invariant encodings, and a common control is constructed through regret minimization (Equation 10). The loss targets the maximal actor-critic regret in the worst-case tail of set samples, focusing expressivity on the behaviorally relevant guarantee boundary.
- Set Verification via Zonotope Propagation: The critical contribution is that, for a fixed sequence of reachability-induced set fragments, certified convergence is established by propagating zonotopes through the trained value function using exact neural network reachability protocols. This upper-bounds the maximal Lyapunov value in each set, allowing trajectory-level certification that is fundamentally decoupled from the (potentially high) policy Lipschitz constant.
Theoretical Results and Certification Hierarchy
The expressivity-certifiability trade-off is formalized: the standard Lipschitz-overbounding approach produces an exponential contraction of certifiable set diameter with ReLU depth, limiting practical certification to trivial sets for expressive policies (Proposition 1). Theorem 1 shows that propagating through the value network exclusively allows set-level Lyapunov decrease certification for the true reachable set, given arbitrary (potentially non-Lipschitz) policies, as long as the neural value overapproximation covers all fragments.
A multi-level certification hierarchy emerges:
- Diagnostic Certification (Global): Sufficient conditions for global set convergence are specified, but are only practical in low dimensions due to loose Lipschitz overestimations.
- Trajectory-Level Certification (Local/Empirical): For a specific set trajectory and initial zonotope, Theorem 1 ensures certified set convergence to the target based on the value function's neural overapproximation (no policy regularity required).
- Terminal/Core Set Certification: A restricted-value function and policy (with spectral normalization and limited support) are trained and verified locally near the target. Here, the Lipschitz and value depth estimates become tight, so the terminal guarantee can be closed (Theorem 2), making certification robust to approximation errors accumulated during long-horizon reachability.
Experimental Validation
The framework is validated on four challenging PWA benchmarks:
- 4Quad and 8Sec (2D, axis-aligned and diagonal boundaries): Baseline evaluation of pipeline, demonstrating 100% strict set-containment.
- CoupledOsc and TripleOsc (4D and 6D, non-axis-aligned, underactuated): The only tested method achieving trajectory-level certification and strict set containment for all fragments at n=6 with M=8 modes, with mode operator norms exceeding unity—a regime that necessitates spectral CQLF transformation.
For all benchmarks, the scheme certifies convergence with positive margin, as exemplified in Table 2. The set-actor outperforms policy-center or scenario-optimized policies, which either fail on corner cases or incur prohibitive computation at runtime.
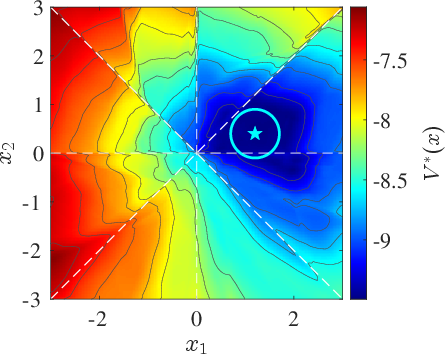
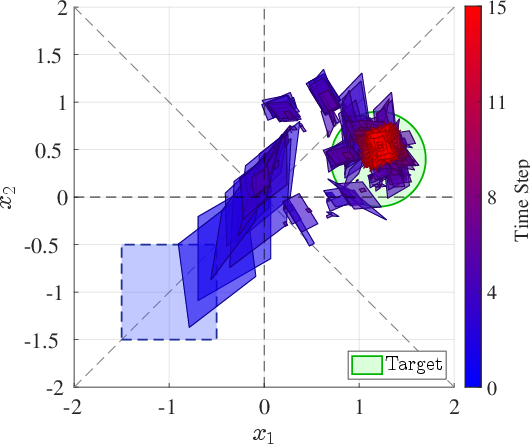
Figure 2: Learned value function V∗(x) with sectoral mode boundaries and set-actor reachability for the 8Sec benchmark.
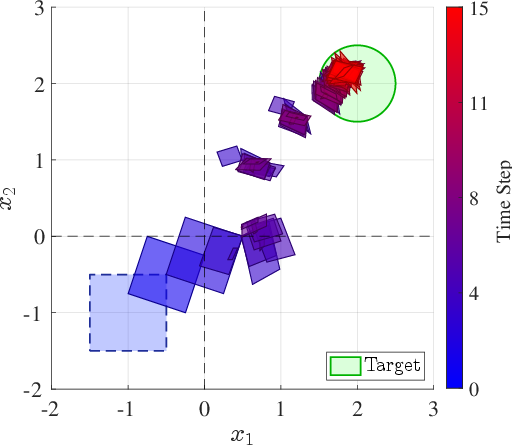
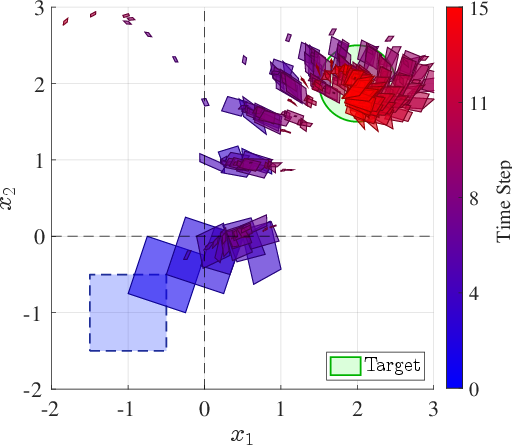
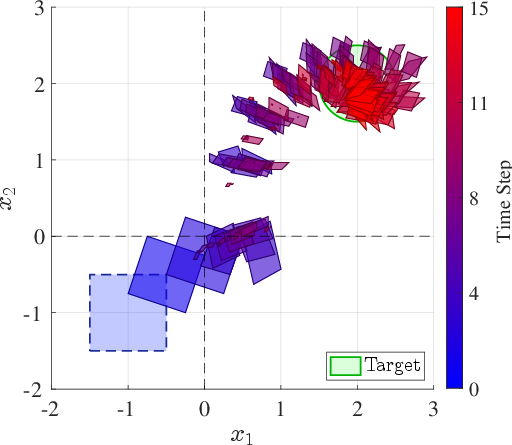
Figure 3: Reachable set propagation comparison on 4Quad: set-actor achieves containment, while oracle-center and scenario-optimized baselines fail to do so in select fragments.
Certifiable margins are achieved in all dimensions (Table 3), and the framework confirms (1) closed-loop containment at constant inference cost, (2) exponential reductions in required Lipschitz bounds via zonotope-based verification, and (3) robust certification with positive margins for high-dimensional systems with nontrivial mode switching.
Implications and Future Directions
Practical Impact: The decoupling of set-level verification from policy Lipschitz constants directly addresses the scalability and conservativeness bottlenecks of neural certification for set-based control of hybrid systems. The approach delivers constant-time, online-certifiable controllers suitable for real-time safety-critical applications on high-dimensional, switched-affine plants.
Theoretical Significance: The result demonstrates that expressive neural Lyapunov certificates, when composed with set-centric verification procedures (as opposed to pointwise regularity constraints), can enable meaningful guarantees for RL-driven set-based control beyond classical contraction-based certificates.
Limitations and Open Questions: The framework is limited by the CQLF existence assumption, which excludes PWA systems lacking a global contraction metric, and by the trajectory-specific nature of set containment certification, which currently requires a separate verification per initial condition. Generalization to amortized family-wise certificates and relaxation to piecewise quadratic Lyapunov functions are natural next steps. The extension of these methods to data-driven or partially identified PWA models is also plausible.
Conclusion
This work offers a scalable, numerically certified approach to set-based control for neural policies on PWA systems, leveraging a tri-level verification architecture that strictly separates learning and certification. The key innovation is the shift from a Lipschitz-focused to a reachability-centric view of neural Lyapunov certification, enabling robust set convergence analysis for high-dimensional, mode-switching systems without sacrificing policy expressivity. The implications span both practical deployment for RL-based control in hybrid domains and theoretical understanding of the certification landscape for deep learning-driven control policies.
Reference: "Certified Set Convergence for Piecewise Affine Systems via Neural Lyapunov Functions" (2604.00286)