- The paper reveals that a subset of dermatoscopic images systematically misleads both CNN ensembles and human experts due to intrinsic ambiguity.
- It employs rigorous ensemble methods and statistical isolation to identify 'difficult images,' highlighting the influence of image quality on diagnostic failures.
- The study advocates for uncertainty-aware models and enhanced dataset curation to improve diagnostic reliability in skin lesion assessments.
Intrinsic Ambiguity in Dermatoscopic Image Diagnosis: Convergent Failures of AI and Human Expertise
Introduction
The paper "When AI and Experts Agree on Error: Intrinsic Ambiguity in Dermatoscopic Images" (2604.00651) presents a systematic investigation into errors shared by both convolutional neural networks (CNNs) and expert dermatologists in the diagnosis of dermatoscopic images. Rather than contrasting model performance against human experts (the dominant paradigm in AI-for-medicine research), this study shifts the focus toward intrinsic dataset complexity, identifying and analyzing images that are systematically misclassified by both AI systems and clinicians. The findings emphasize the irreducible ambiguity in a subset of skin lesion images—a phenomenon attributed to image quality and inherent visual complexity—posing limitations for both algorithmic and human diagnostic performance.
Methods: Model Ensembles, Statistical Isolation of Difficult Images, and Human Review
The study employs five state-of-the-art CNN architectures pretrained on ImageNet—ResNeXt-50, ResNet-152, EfficientNet-B4, EfficientNet-B5, and EfficientNet-B6—replicated across five data splits, for robust classification of the ISIC 2019 dermatoscopic dataset. Ensemble methods and meta-classifiers are used for aggregating predictions.
To identify intrinsically difficult images, the authors propose a rigorous statistical framework. They isolate images that are jointly misclassified by all architectures and employ a stratified permutation test to validate that this number far exceeds what is expected under a null hypothesis of independent random misclassifications. This remains valid even accounting for dependencies induced by shared training data across models.
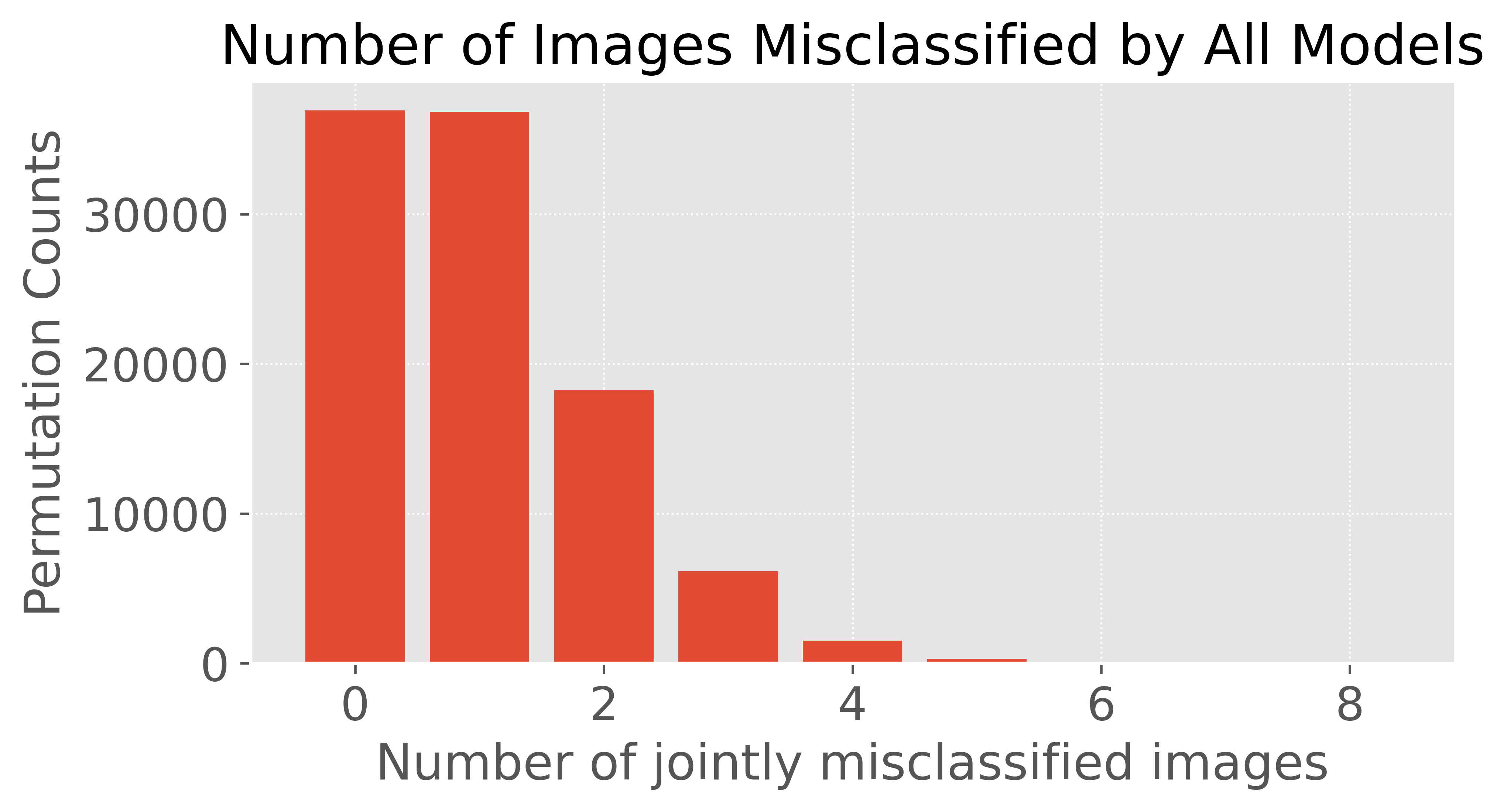
Figure 1: The distribution of images jointly misclassified by all models demonstrates a significant excess over the null permutation, confirming systematic error patterns.
The resultant subset—denoted as "difficult images"—is subsequently presented to six expert dermatologists for blinded diagnosis, alongside an equally-sized control set (images correctly classified by all models). These high-expertise raters evaluate images via a custom-designed online portal, with inter-rater reliability and agreement with ground truth measured by Cohen's and Fleiss' kappa metrics.
Results: Concordant Diagnostic Failure of Human and AI Systems
Statistical analysis confirms a vast surplus of images misclassified by all CNNs (823 versus ~3 expected under the null), strongly implicating dataset-intrinsic complexity rather than mere model idiosyncrasy.
Crucially, human expert classification mirrors AI limitations on these images. On the "difficult" subset:
- Agreement with ground truth deteriorates sharply (Cohen’s kappa: 0.08 vs 0.61 for control)
- Inter-expert consensus falls to modest levels (Fleiss’ kappa: 0.275 vs 0.456, control)
- Diagnostic accuracy for expert consensus drops to 29.6% (vs 66.2%)
- For example, sensitivity for melanoma in the control set reaches 0.90, but only 0.53 for difficult images; BCC is not correctly identified at all in the latter group
Notably, both AI and human raters show highest performance on visually distinctive classes (e.g., vascular lesions).
Figure 2: Representative dermatoscopic images from each diagnostic class; the first row shows universally correct cases, the second row depicts those systematically misclassified by all models.
Contingency analysis demonstrates that errors in the difficult group frequently stem from confusion between visually distinct disease categories—highlighting not mere class overlap but fundamental image ambiguity.
Image Quality as a Confounding, Yet Partial, Explanation
A significant fraction of systematically misclassified images are recognized by dermatologists as being of poor quality, especially as regards focus and the presence of artifacts (e.g., hair occlusion). The study utilizes automated quality metrics—Laplacian, Fourier, and wavelet-based blur detection—to support expert annotation in identifying low-quality images.
Figure 3: Examples of images with strong high-frequency components indicating hair occlusion and dataset duplication—artefacts substantially impeding both AI and human assessment.
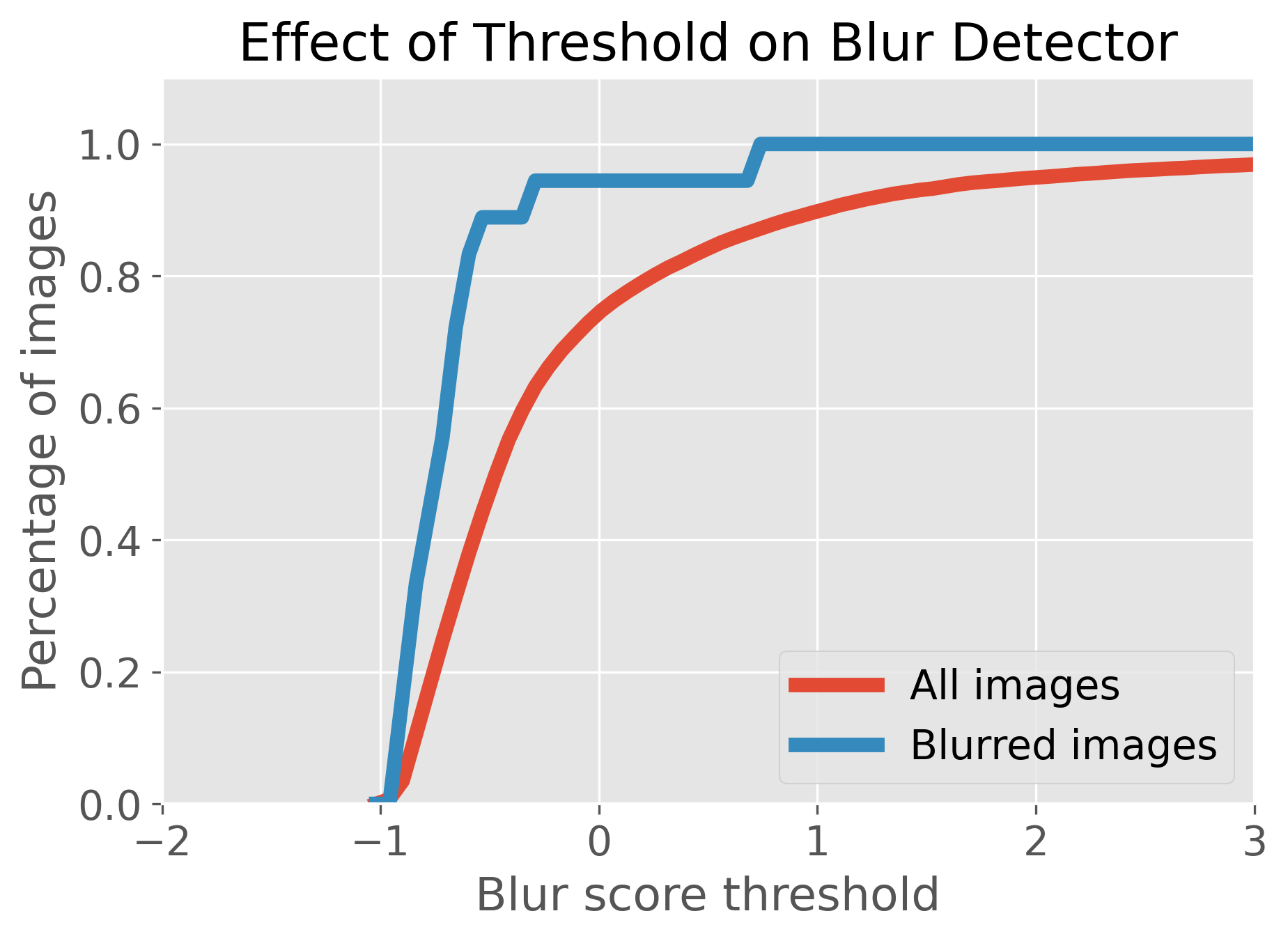
Figure 4: The effect of varying the blur-score threshold: appropriate selection allows effective exclusion of the majority of low-quality images while retaining the diagnostically valuable majority.
While automated quality scoring removes a substantial proportion of images rated as blurred by experts, image quality does not fully account for all difficult cases, indicating that some ambiguity arises independently of technical factors and may indeed reflect the inherent limitations of image-based diagnosis.
Additional experiments within the paper evaluate ensemble- and meta-classification approaches, incorporating both image-based predictions and clinical metadata (age, gender, lesion location). Ensemble learning and meta-classification (random forest, MLP) confer significant gains over single CNNs, with balanced accuracy up to 89.42% (random forest meta-classifier).
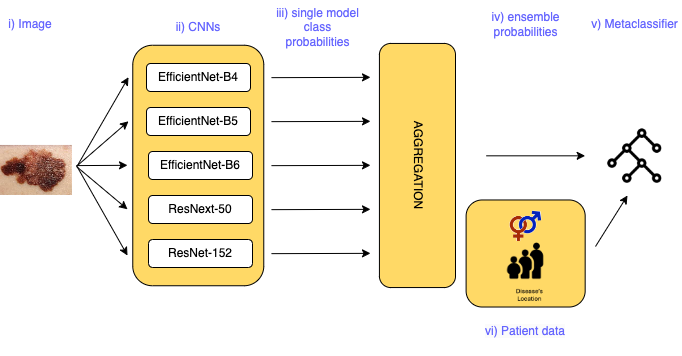
Figure 5: Training architecture overview—individual CNN predictions are aggregated, with further meta-classification possibly leveraging clinical metadata.
Critical difference analysis indicates these ensemble methods outperform all constituent single models; however, the addition of demographic and anatomical metadata does not yield further improvements, contrary to clinical expectations. The authors speculate that richer, labeled metadata or more sophisticated integration may be required to realize gains from this information source.
Implications: Theoretical, Methodological, and Clinical
This study demonstrates that certain dermatoscopic images intrinsically elude robust algorithmic and expert diagnosis. The implication is that a subset of diagnostic errors reflects irreducible uncertainty, attributable to limitations in visual morphologic information—rather than to flaws in either model architecture or clinical expertise.
Practical and theoretical consequences include:
- Evaluation protocols: Benchmarking AI by performance parity with clinicians is incomplete; true diagnostic capability is bottlenecked by dataset ambiguity. Efforts should focus on error analysis and case difficulty stratification rather than global accuracy statistics.
- Dataset curation: Rigorous, automated quality assessment pipelines are necessary in dermatology AI; further, researchers must account for ambiguous and low-information images in their training and evaluation protocols.
- Clinical translation: For OOD deployment and real-world settings, diagnosing clinicians require systems that can flag potentially ambiguous or low-quality cases, promoting caution and perhaps recommending alternative validation/biopsy.
- Future method development: There is latent value in the identification and separate handling of irreducibly ambiguous cases (including "uncertainty-aware" AI models, abstention mechanisms, etc.), perhaps integrating multi-modal data or richer clinical context.
Future Directions
Open questions and areas for further work include:
- Automated and scalable quality labeling for large datasets, possibly harnessing self-supervised or unsupervised learning approaches.
- Exploration of more advanced meta-learning and uncertainty quantification frameworks, suited for triaging highly ambiguous cases.
- Prospective studies integrating real-life clinical data with images, emphasizing fair human-AI comparisons and error case localization.
- SHAP or other explainability analyses to clarify why clinical metadata failed to boost model performance.
Conclusion
The analysis establishes that both state-of-the-art CNN ensembles and highly-trained human dermatologists display convergent diagnostic failure on a subset of dermatoscopic images. This shared failure arises not from algorithmic inadequacy alone but reflects inherent ambiguity—driven by poor image quality and visual indistinctness—within the clinical data. These findings advocate a paradigm shift toward transparency in dataset curation, methodological rigor in error analysis, and development of uncertainty-aware AI tools for dermatology. Addressing intrinsic diagnostic ambiguity remains a requisite step for advancing both automated and clinical skin cancer diagnostics, with significant implications for AI deployment in medical imaging.