- The paper introduces a benchmark that enforces significant distribution shifts to realistically assess catastrophic forgetting in Video-LLMs.
- It implements a comprehensive 6-protocol evaluation framework, measuring performance, computational efficiency, and storage overhead across diverse tasks.
- Empirical results reveal a stability-plasticity trade-off where specialized anti-forgetting methods often compromise generalization on held-out benchmarks.
CL-VISTA: A Rigorous Benchmark for Continual Learning in Video-LLMs
Current video understanding benchmarks for continual learning are fundamentally misaligned with the capabilities of large-scale Video-LLMs, due to two key limitations: (1) capability bias—benchmarking on weakly- or non-pretrained models; and (2) distribution bias—partitioning a single dataset by superficial question types induces high task redundancy and fails to produce realistic forgetting. As quantitatively assessed, modern Video-LLMs such as Video-LLaVA exhibit negligible catastrophic forgetting on legacy benchmarks, indicating that these settings do not meaningfully test continual learning. In contrast, the introduction of CL-VISTA enforces significant distributional shifts between tasks, demonstrated by pronounced performance drops and negative backward transfer (BWT) under sequential fine-tuning.
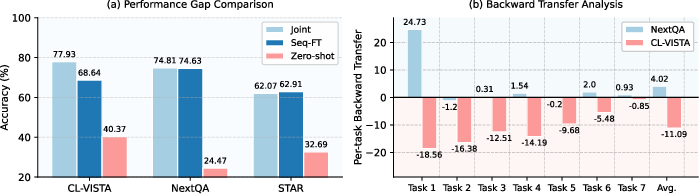
Figure 1: Significant performance gap in existing benchmarks is exposed only by CL-VISTA, which induces substantial forgetting under sequential fine-tuning.
A t-SNE–based analysis of joint video-question embeddings further reveals that CL-VISTA achieves much clearer task separation and greater inter-task distances than prior benchmarks, confirming its efficacy in mitigating distributional and capability bias.
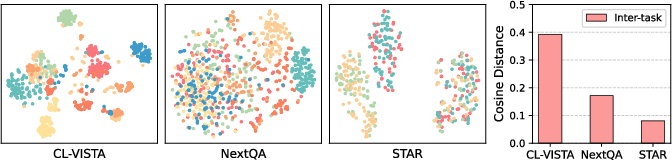
Figure 2: Embeddings on CL-VISTA display high inter-task distance, in stark contrast to previous benchmarks with severe entanglement.
In training trajectory analysis, sequential task learning on CL-VISTA evokes sharp loss spikes at task boundaries, confirming considerable shifts, whereas prior datasets show homogeneous optimization curves, signifying trivial task transitions.
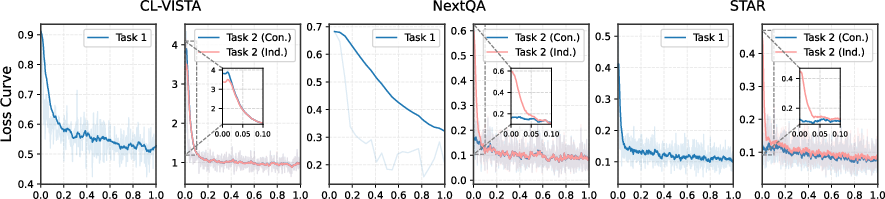
Figure 3: Under CL-VISTA, loss spikes at task boundaries reflect non-trivial distribution shifts.
CL-VISTA Benchmark Design and Task Suite
CL-VISTA comprises eight tasks spanning three foundational dimensions:
- Perception: Counting, Space
- Understanding: Traffic, Movie, GUI, Science, Sports
- Reasoning: STAR-based distributed temporal and causal reasoning
The benchmark integrates open datasets and a dedicated high-quality video QA data generation pipeline supported by multi-discriminator filtering for rigorous domain-specific QA synthesis.
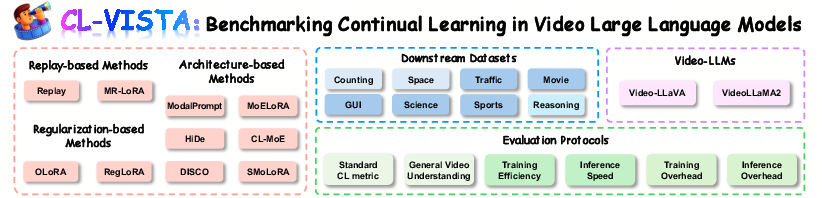
Figure 4: The CL-VISTA benchmark—modular, extensible, and supporting systemic evaluation protocols.

Figure 5: Dual-discriminator video-based QA data generation and refinement pipeline.
Visualization of individual tasks highlights the heterogeneity and complexity of the curated benchmark, with significant diversity in scenario, domain, and instruction type.


Figure 6: Counting and spatial tasks in CL-VISTA.


Figure 7: Traffic and movie domain tasks.

Figure 8: GUI and science specialized QA tasks.


Figure 9: Sports and temporal reasoning tasks.
CL-VISTA is designed for the latest Video-LLMs, especially Video-LLaVA and VideoLLaMA2, both of which possess significant pre-training on large-scale video data.
Evaluation Framework: Metrics and Protocols
CL-VISTA implements a comprehensive 6-protocol evaluation framework across three axes:
- Performance: Standard CL metrics (MFT, MFN, MAA, BWT) and general video understanding via evaluation on five diverse held-out benchmarks (MMVU, MVBench, NExTQA, LongVideoBench, MMBench-Video).
- Computational Efficiency: Measures both per-task training and aggregate inference latency.
- Storage Overhead: Quantifies parameter and memory requirements during training and inference.
A robust LLM-as-Judge protocol (Qwen3-30A3B-Instruct) supresses spurious forgetting inherent in string-matching methods.
Empirical Results and Quantitative Analysis
Standard CL evaluation on Video-LLaVA reveals that most existing multimodal CL methods, including those using regularization and architecture expansion (e.g., RegLoRA, HiDe, MoELoRA, CL-MoE), are unable to control forgetting under the challenge imposed by CL-VISTA. Only task-specific adaptation and replay-based methods, such as DISCO and MR-LoRA, attain minimal negative BWT.
However, these task-specialized approaches display a trade-off between stability and plasticity: although memory of seen tasks is preserved, generalization to held-out benchmarks is often worse than simple LoRA-FT sequential fine-tuning. For instance, MR-LoRA and DISCO, despite strong anti-forgetting, cause relative drops of 4.94% and 5.98% on general video understanding, especially on NExTQA, highlighting detrimental distributional overspecialization.
Training and inference efficiency are also diverse: regularization-based and parameter-expansion methods (e.g., SMoLoRA, MoELoRA, RegLoRA) entail substantial time and memory costs, with RegLoRA imposing extreme storage due to parameter protection overheads.
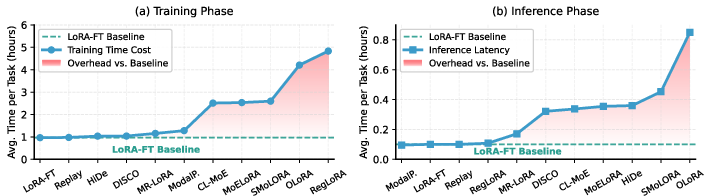
Figure 10: Training and inference computational efficiency of CL algorithms.
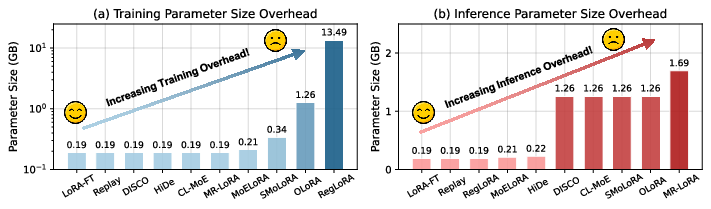
Figure 11: Parameter size overhead for major CL-Video-LLM strategies during training and inference.
This tension renders none of the tested approaches universally optimal: state-of-the-art forgetting mitigation is inevitably achieved at the cost of generalization and resource requirements.
Implications and Future Directions
The rigorous distributional properties and multidimensional evaluation of CL-VISTA reveal that:
- Existing CL algorithms for Video-LLMs are highly susceptible to trade-offs between generality and forgetting, especially when confronted with realistic distribution shifts.
- Parameter-expansion and architectural modularity control forgetting at the expense of significant computation and overfitting to specific data regimes.
- Progressive, curriculum-aligned learning sequences can enhance fundamental generalization but are vulnerable to forgetting.
- Effective continual learning for Video-LLMs requires new advances in scalable, adaptive, and generalizable representation consolidation—beyond static mixture-of-experts or regularization paradigms—as well as more efficient routing, lifelong memory integration, or meta-continual learning protocols.
By establishing a rigorous, standardized, and scalable testbed, CL-VISTA provides an essential foundation for the evaluation and development of practical, generalizable continual learning for Video-LLMs and other future multimodal foundation models.
Conclusion
CL-VISTA sets a new standard for continual learning in Video-LLMs, exposing the inadequacy of current methodologies and evaluation protocols for modern models. Its challenging task heterogeneity, distributional robustness, and multidimensional evaluation not only provoke catastrophic forgetting but also reveal limitations in generalization and practical deployment. The open-source release of CL-VISTA, along with a unified codebase and leaderboard, constitutes a necessary infrastructure for advancing research on robust, scalable, and efficient continual video understanding systems.

