- The paper presents CLeaRS, a comprehensive benchmark designed for continual vision-language learning in remote sensing.
- It introduces sequential evaluation protocols, including long-horizon, modality-incremental, and task-incremental setups, to measure catastrophic forgetting.
- Empirical results reveal that state-of-the-art VLMs suffer from severe, multi-causal forgetting, emphasizing the need for novel continual learning strategies.
Continual Vision-Language Learning for Remote Sensing: Benchmarking and Analysis
Motivation and Problem Definition
Vision-LLMs (VLMs) for remote sensing (RS) have demonstrated significant capabilities for dynamic scene understanding. However, their operational paradigm typically relies on static, joint training over large instruction-tuning datasets—a strategy ill-suited for field deployment scenarios where sensing modalities and downstream interpretation tasks continually evolve. The core challenge addressed is enabling RS VLMs to incorporate new knowledge (modalities, tasks, instructions) without catastrophic forgetting of previously acquired capabilities, thereby achieving lifelong continual vision-language learning.
Despite continual learning being widely studied in vision or task-specific RS models, there is an absence of large-scale, dedicated benchmarks for systematic assessment of continual vision-language learning in RS. The presented work introduces CLeaRS (Continual Learning Remote Sensing), a benchmark specifically curated to fill this gap, supporting rigorous empirical and diagnostic studies across multiple modalities, interpretation tasks, and evaluation protocols.
The CLeaRS Benchmark: Design and Coverage
CLeaRS consists of 10 high-quality image-text subsets, totaling over 200,000 pairs and spanning 93,000+ images. These subsets are designed to comprehensively cover RS vision-language interpretation tasks, including:
The data diversity is further extended to cover three imaging modalities: optical, SAR, and infrared, as well as mission-critical application domains such as disaster management (fire/hurricane risk and damage assessment). Construction involved multi-stage integration: leveraging established RS datasets, automated and template-driven instruction generation, and rigorous expert verification for data fidelity.

Figure 1: The CLeaRS benchmark comprises 10 subsets that progressively cover diverse interpretation tasks, sensing modalities, and application scenarios, facilitating systematic investigation of continual vision-language learning behaviors in RS VLMs.
A salient feature is progressive and compositional data organization—CLeaRS emulates the evolution of RS tasks and modalities seen during actual system deployment. This is visible at the granularity of per-subset class distributions, instruction format variations, and cross-modality coverage.
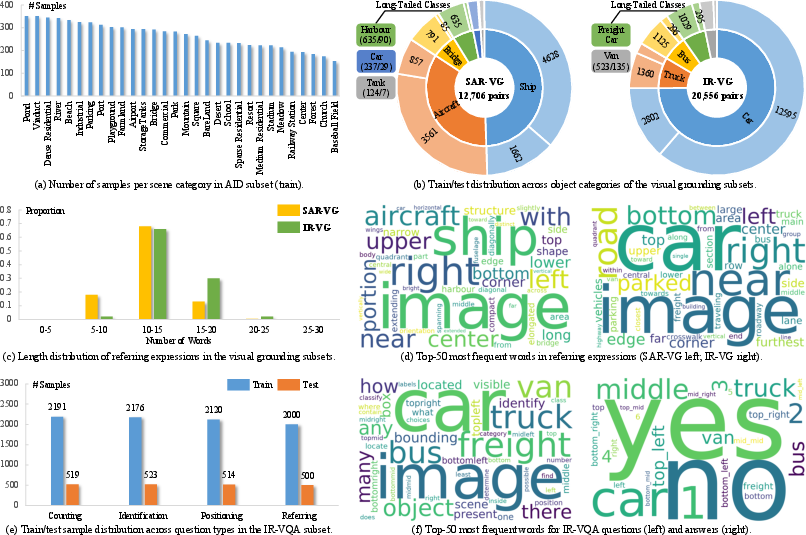
Figure 2: Statistics of the newly constructed subsets in CLeaRS, illustrating sample and class distribution characteristics.
Moreover, for previously unavailable tasks—such as visual grounding in SAR/IR—significant engineering is undertaken. Modality-specific prompting is used to auto-generate unambiguous referring expressions leveraging SOTA VLMs (Qwen3-VL and Gemini-3) and followed by targeted post-processing and human validation.
Evaluation Protocols
To diagnose stability-plasticity trade-offs and pinpoint failure modes, CLeaRS supports three protocols:
- Long-horizon: Sequentially exposes the model to all 10 subsets, simulating multi-task and multi-modal continual adaptation over a lengthy horizon.
- Modality-incremental: Fixes the vision-language task while incrementally increasing the number of sensing modalities (optical, SAR, IR).
- Task-incremental: Fixes the sensing modality while introducing new task types (e.g., from classification to VQA).
At each step, evaluation is performed on all previously observed and current tasks, enabling quantification of knowledge retention and new information integration.
Empirical Analysis: Forgetting and Its Drivers
Rigorous benchmarking is performed across general-purpose and domain-specific SOTA VLMs: Qwen2.5-VL, MiniGPT-v2, LLaVA-1.5, GeoChat, and VHM. Across all protocols and models, consistent and severe catastrophic forgetting is observed, as measured by persistent negative backward transfer (BWT) and final accuracy (MFN) significantly below joint-training upper bounds.
Analysis reveals several important phenomena:
- Forgetting severity is not monotonic in sequence length: In many cases, switching between fundamentally different vision-language tasks induces more forgetting than increasing the number of adaptation stages.
- Joint training is not necessarily optimal per-task: There exist subsets for which individual sequential adaptation outperforms the corresponding component of a jointly trained model, highlighting the limitation of joint learning as an idealized oracle.
- Plasticity and stability are uncorrelated: Models exhibit inconsistent acquisition/retention trade-offs, as indicated by discrepancies in mean fine-tune accuracy (MFT), MFN, and MAA.
Additionally, a focused ablation study diagnoses the impact of task heterogeneity, instruction format changes, and modality transitions on forgetting:
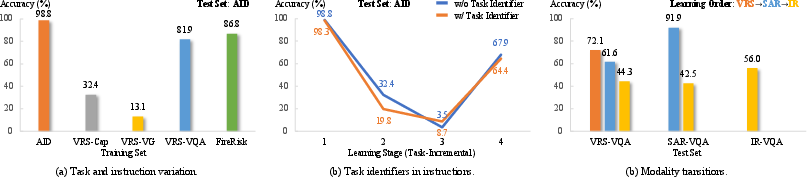
Figure 3: Analysis of factors contributing to forgetting in RS VLMs, showing that task, instruction, and modality changes independently and collectively induce forgetting.
Key findings:
- Instruction format alignment (e.g., inserting explicit task tags) may improve joint training, but does not reliably mitigate forgetting in sequential learning.
- Even when task and instruction cues are matched, changing the underlying sensing modality yields marked performance drops on prior subsets (severe negative BWT).
- Forgetting is thus multi-causal, jointly driven by task transitions, instruction semantics, and visual domain shift.
Visual Grounding in SAR and IR: Task-Specific Challenges
The benchmark exposes the acute difficulty of continual grounding in non-optical modalities. Both SAR and IR exhibit low per-subset and cross-modality transfer, partially due to low intra-image object density (in SAR), and extreme homogeneity (in IR).

Figure 4: Examples from the SAR-VG (left) and IR-VG (right) subsets in CLeaRS, revealing the modality-specific complexity of generating and understanding referring expressions.

Figure 5: Prompts for referring expression generation in SAR and infrared imagery, exemplifying the modality-tailored instruction engineering.
Effectiveness of Existing Continual Learning Methods
Three state-of-the-art parameter-efficient continual learning methods (MoELoRA, HiDe-LLaVA, SEFE) are adapted to the RS VLMs and comprehensively evaluated. Despite nominal gains in MFN in some scenarios, all methods show persistently negative BWT; gains are not robust to protocol variant or learning order (sequence permutation). In some cases, these methods exacerbate forgetting relative to unconstrained fine-tuning. There is no single approach that provides stable, cross-protocol improvement.
Implications and Future Directions
The introduction of CLeaRS reveals that catastrophic forgetting remains an unsolved and acute challenge for RS VLMs in lifelong adaptation scenarios. The unique demands of continual vision-language adaptation in RS—arising from shifting sensing modalities, intrinsic heterogeneity of tasks, and dynamically evolving instruction semantics—demand novel continual learning strategies beyond those effective in natural image or single-task contexts.
Practically, the results highlight the need for architectural and training modifications supporting decoupled adaptation, memory consolidation, and robust cross-domain transfer for both visual and language components. Theoretically, the multi-causal forgetting failures demonstrated here suggest new research is required on representation disentanglement, hybrid memory/expansion strategies, and dynamic task/instruction recognition for vision-language systems operating in open-world, evolving environments.
Conclusion
The CLeaRS benchmark is a significant resource for the formal investigation of continual learning in RS VLMs. The experimental results and analyses provide a rigorous baseline, highlighting the limits of current methods and laying the groundwork for future work on continual, multi-task, multi-modal vision-language systems in remote sensing.