- The paper systematically refines seven Japanese VQA datasets, addressing ambiguity, annotation errors, and lack of visual grounding.
- It details a rigorous two-stage manual curation process that improves accuracy and stabilizes model ranking with LLM-based adjudication.
- Empirical analysis reveals significant performance gains and reduced evaluation variance, underscoring the benefits of targeted dataset enhancement.
JAMMEval: Systematic Refinement for Reliable Japanese VQA Benchmarking
Motivation and Limitations of Existing Japanese VQA Benchmarks
Japanese VQA (Visual Question Answering) benchmarks have lagged behind their English counterparts in iterative data cleaning and standardization, resulting in significant quality issues that undermine reliable VLM (Vision-LLM) evaluation. Commonly observed defects include ambiguous or subjective question formulations, ground-truth annotation errors, and questions that can be answered using only textual cues without referring to the input image. These issues induce high evaluation noise and can distort true model capability assessment, especially when evaluating non-English VLMs in Japanese language contexts.

Figure 1: Representative categories of problematic instances in Japanese VQA datasets, including ambiguity, lack of image grounding, annotation errors, and subjectivity.
Systematic Construction and Multi-Round Refinement of JAMMEval
JAMMEval addresses these shortcomings by conducting an in-depth, two-stage manual refinement of seven prominent Japanese VQA datasets spanning OCR, Japanese cultural knowledge, document understanding, chart/table analysis, and multi-image reasoning domains. The construction pipeline involves rigorous auditing and re-annotation, prioritizing rephrasing and correction over removal to maintain sufficient sample sizes and statistical stability even for datasets with low instance counts.

Figure 2: The JAMMEval curation pipeline applies two rounds of human annotation and re-annotation across seven heterogenous seed datasets.
Annotators systematically target three main issue categories: ambiguity (disambiguation of open-ended or subjective questions), lack of visual grounding (ensuring questions require image understanding), and erroneous ground-truths (manual correction of inaccurate answers). Minor edits (e.g., phrasing, typographic corrections) are also applied, and a unified short-answer format is enforced for all datasets except for multiple-choice CVQA-JA.
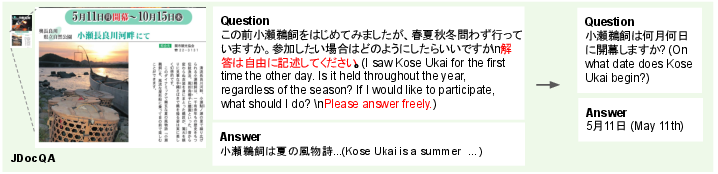
Figure 3: Re-annotation example where an open-ended, ambiguous question is converted into a precise, image-grounded query.
Quantitative Analysis of Refinement Operations
JAMMEval reports detailed statistics on the distribution of refinement operations across the different seed datasets. The proportion of instances requiring major intervention (disambiguation, answer correction, replacement, removal) depends strongly on the initial dataset quality and prior verification steps during their original construction.
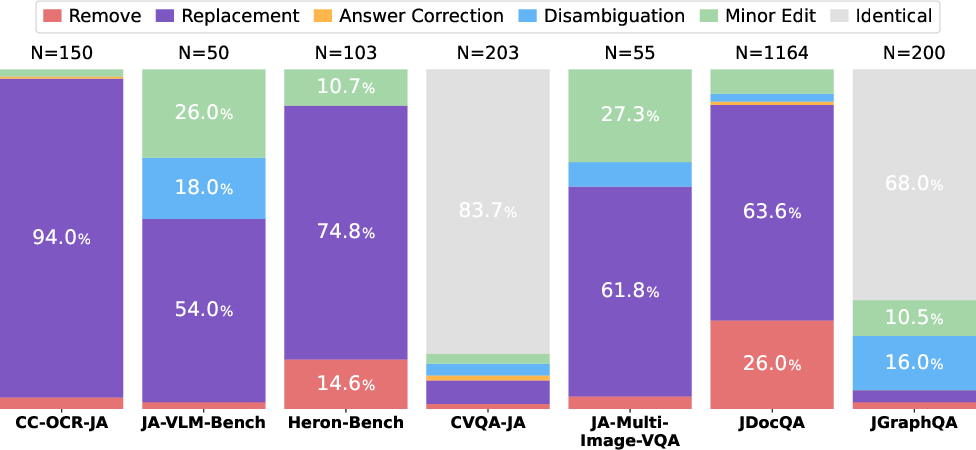
Figure 4: Dataset-specific breakdowns showing the frequency and type of refinement operation (e.g., minor edits, disambiguation, answer correction, removal, replacement).
The resulting refined benchmark contains 1,592 instances after filtering and correction down from the original 1,925, with preservation of fair domain and task coverage.
Protocols and Model Evaluation
JAMMEval establishes clear format-specific prompting, consistent evaluation protocols, and LLM-based soft exact match adjudication for short-answer tasks to minimize penalization from minor surface-level discrepancies in response formatting. The evaluation uses a strong LLM (GPT-5.1) as the primary judge, controlling for non-determinism via multiple independently seeded evaluation runs.
Seven VLMs—including both open-weight (Qwen3-VL-{2B, 4B, 8B}, InternVL3.5-{2B, 4B, 8B}, Sarashina2.2-Vision-3B) and proprietary (GPT-4o, GPT-5.1, Gemini 3 Pro) models—are benchmarked across all datasets and tasks. Results are measured using accuracy and inter-run standard deviation.
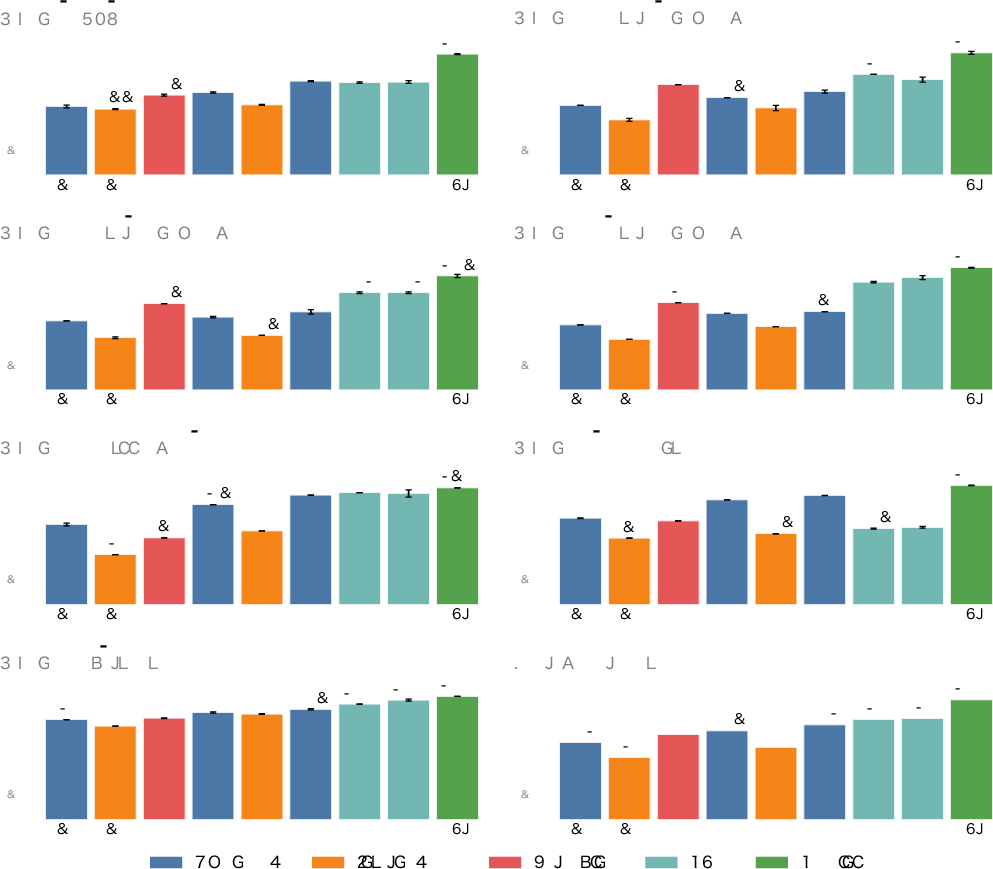
Figure 5: Comparative model performance for each VLM on the refined JAMMEval suite. Gemini 3 Pro achieves the highest accuracy across all tasks.
Gemini 3 Pro achieves robust performance—exceeding 90% accuracy on all tasks. Qwen3-VL-8B demonstrates leading results among open models, outperforming GPT-5.1 on OCR and document tasks. Sarashina2.2-Vision-3B, which is tailored to Japanese, is competitive on Japanese cultural benchmarks, underscoring the utility of language/culture-specific pretraining.
Error Analysis and Domain-Specific Weaknesses
A taxonomy of Gemini 3 Pro's remaining errors reveals the most prevalent causes: knowledge (e.g., failure to bridge specific Japanese cultural concepts), general visual perception (inaccuracies in counting, orientation, or compositional understanding), and judge errors (where gold LLM adjudication misidentifies correct answers due to minor wording variations).
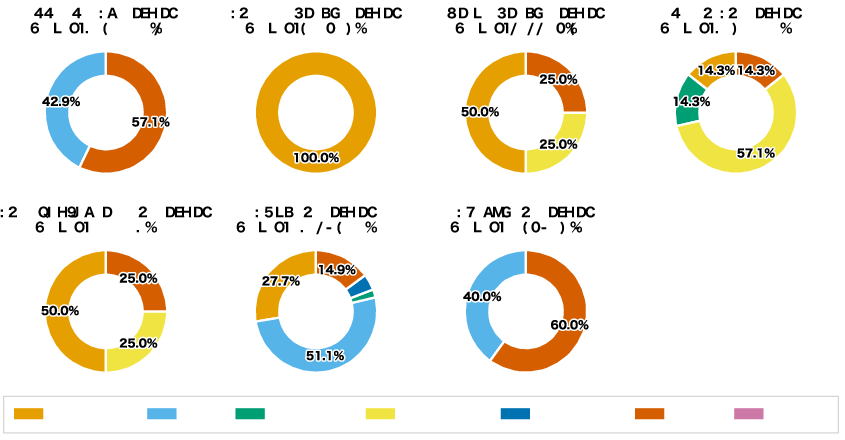
Figure 6: Error category proportions for Gemini 3 Pro classified by instance and dataset; knowledge errors are notable in Japanese-culture tasks.
Judge errors highlight limitations of current LLM-only grading setups on short answers—future work should incorporate VLM-as-judge methods where the judge accesses both image and textual response for more accurate evaluation.
Empirical Effects and Benefits of Dataset Refinement
JAMMEval's refinement substantially improves several metrics:
- Mean accuracy increases: indicates original dataset flaws induced artificially depressed scores, now corrected.
- Run-to-run variance decreases: refined datasets yield more robust, stable evaluation across multiple runs.
- Model ranking stability: high correlation between rankings before and after refinement confirms preservation of relative difficulty.
- Increased performance gap: refined datasets yield larger differences between strong and weak models, improving discriminative power, critical for research and ablation studies.
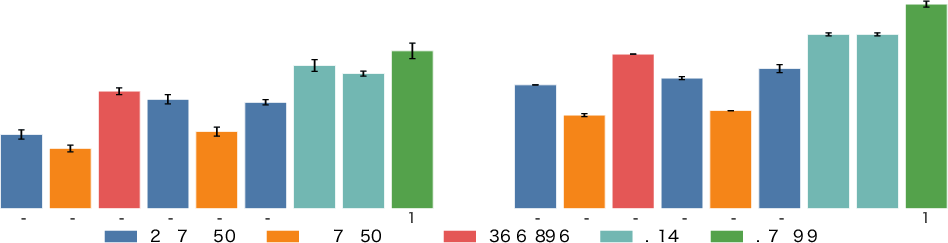
Figure 7: Effects of refinement on Heron-Bench; all models’ accuracy improves, and variance across runs is reduced, reflecting more reliable scoring post-refinement.
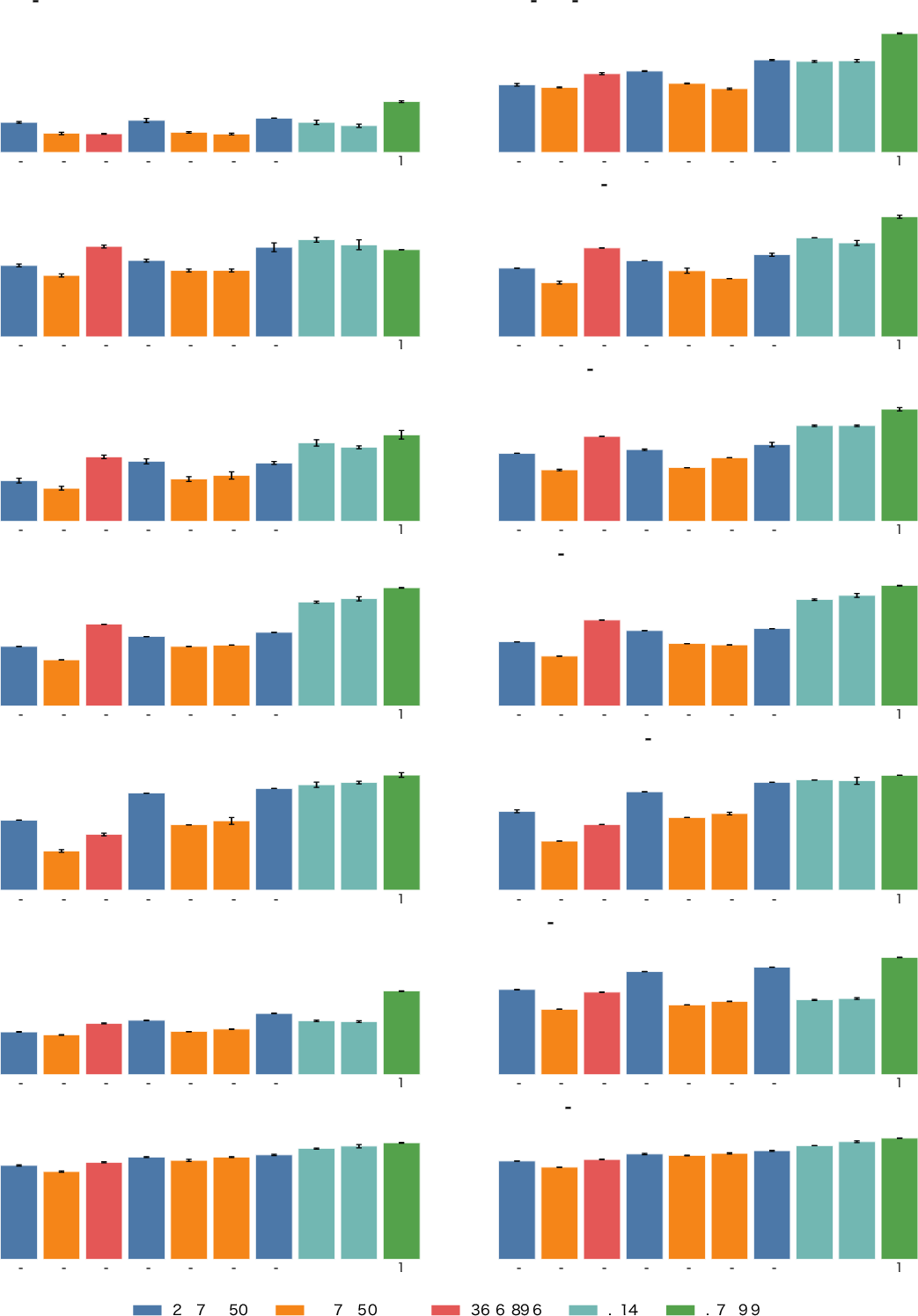
Figure 8: Visualization of changes in model performance between original and refined datasets; refinement yields higher, more consistent scores.
Most of the error reduction post-refinement was due to elimination of ambiguous or subjective annotation instances and ground-truth answer corrections, not improved underlying model capability.
A specialized web-based annotation tool was constructed for efficient re-annotation. Annotators are presented with paired image and QA, and can directly revise, replace, or skip non-repairable examples, streamlining the multi-stage pipeline and minimizing human error.
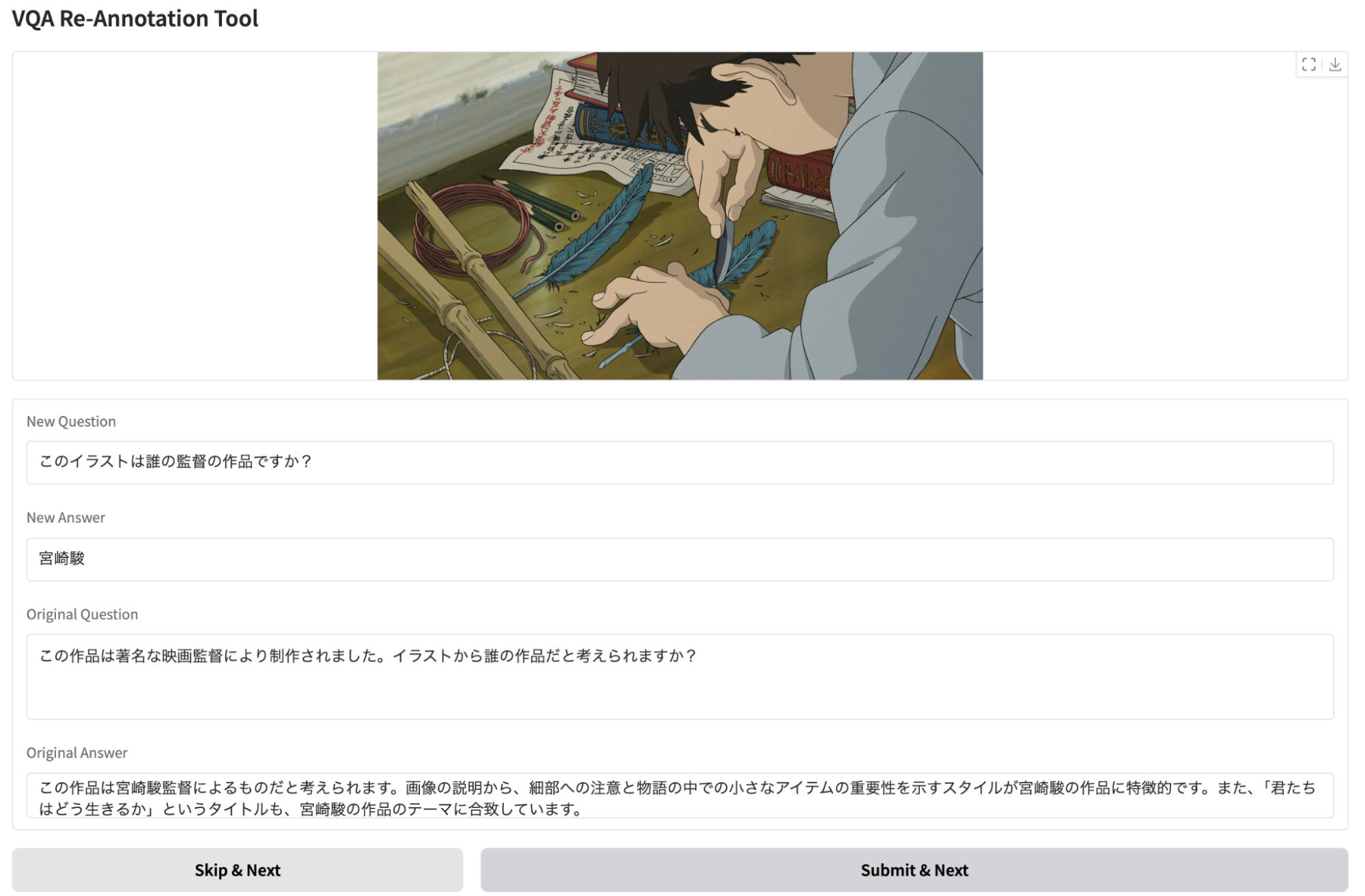
Figure 9: Screenshot of the custom annotation interface for re-annotation, enabling annotation consistency and rapid quality assurance.
Representative Error Cases
Qualitative error analysis for Gemini 3 Pro further elucidates the nature of common failure modes, including misinterpretation of Japanese-specific references, counting mistakes, and residual issues where LLM-based judges penalize syntactically variant but semantically correct answers.
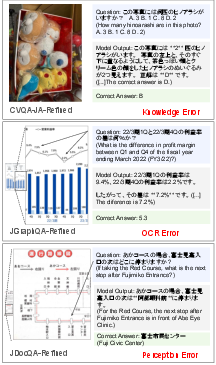
Figure 10: Example errors from Gemini 3 Pro, demonstrating typical remaining failure modes in the most challenging instances.
Limitations and Future Directions
JAMMEval highlights several emergent bottlenecks in Japanese VQA evaluation:
- Performance Saturation: Leading models (e.g., Gemini 3 Pro) approach benchmark ceilings, with further improvements limited by annotation and judging errors.
- Scalability: Manual refinement at the ~2K instance scale is feasible, but does not scale to future benchmarks with 105+ examples or deep domain specificity. Automated refinement (e.g., semi-automatic LLM+human curation, VLM-as-judge) is increasingly necessary.
- Need for more challenging benchmarks: To track ongoing VLM advances, future evaluation datasets must be designed for discriminative power in super-human regimes and localized knowledge sensitivity.
Conclusion
JAMMEval constitutes a rigorously curated, multi-domain, and systematically refined evaluation suite targeting reliable, fair, and discriminative VQA assessment in Japanese across diverse domains. The findings demonstrate that high-quality annotation and careful dataset revision significantly impact both accuracy reporting and model comparison validity. These outcomes have direct implications for cross-linguistic VLM evaluation, tool-chain robustness, and the design of future scalable multimodal benchmarks. JAMMEval establishes a new standard for Japanese VQA and identifies methodological priorities for extending reliable multimodal evaluation to new languages and task spaces.
Reference: "JAMMEval: A Refined Collection of Japanese Benchmarks for Reliable VLM Evaluation" (2604.00909)