- The paper proposes a modular decomposition of motion generation by decoupling a universal frozen motion prior from domain-specific interaction adaptation.
- It employs Meta-Interaction Modules and Frame-wise Segment Refinement to ensure responsive, coherent motion generation in real time (<0.05s/frame) with improved performance metrics.
- Empirical results demonstrate robust zero- and few-shot transfer across human-human, human-scene, and mixed interactions, achieving metrics like 0.166 FID on Inter-X.
Real-Time Human Interaction-to-Reaction Generation via Modular Learning from Diverse Data: An Expert Perspective on ReMoGen
Problem Statement and Motivation
The challenge of generating real-time human motion that reacts appropriately to multi-source cues—including the actions of other agents, 3D scene context, and optional high-level textual intent—poses core difficulties for interactive graphics, robotics, and virtual embodiment. Data scarcity across heterogeneous domains (single-person, human-human, and human-scene interactions) and the requirement for responsive, high-fidelity, online motion generation create a scenario unaddressed by prevailing end-to-end or domain-specialized pipelines. ReMoGen introduces a modular approach to decouple kinematic priors from interaction-specific adaptation, enabling robust zero- and few-shot transfer across arbitrarily composed interaction modalities.
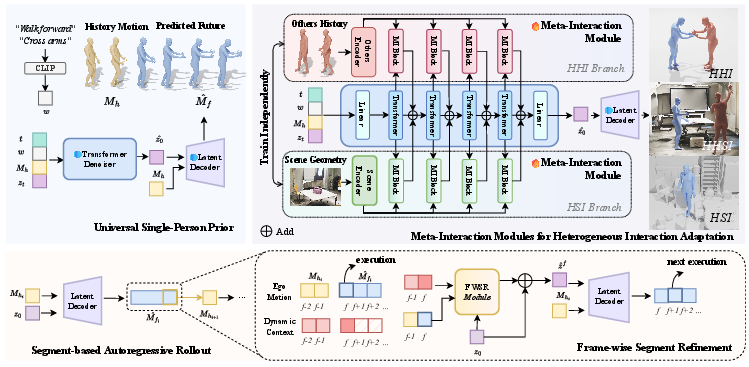
Figure 1: Overview of the ReMoGen Framework. The architecture addresses data scarcity and real-time responsiveness for interaction-to-reaction generation via a universal motion prior, modular interaction adaptation, and segment-level inference with frame-wise refinement.
Architectural Components
Universal Single-Person Motion Prior
At its foundation, ReMoGen employs a frozen, text-conditioned, single-person motion prior, learned from single-agent, large-scale datasets (specifically, HumanML3D). This backbone is architected as a VAE-based latent diffusion network operating in an autoregressive, segment-based regime, factorizing sequence prediction to support both computational tractability and temporal consistency. The diffusion latent is conditioned on text and recent motion history:
M^fi=Dθ(Mhi,zi),z^0=Gψ(zt,t,Mhi,w).
Such a prior encodes low-level motion statistics, kinodynamic priors, and language-motion correspondence, exposing an interface for modular adaptation without catastrophic interference in downstream domains.
Meta-Interaction Modules for Domain Adaptation
A suite of Meta-Interaction Modules (MIMs)—specialized trainable adapters for distinct interaction sources—injects domain-aware modulation into the frozen prior. Each MIM (HHI, HSI) receives contextual embeddings (Surrounding agents, voxelized scenes), encodes them via a dedicated network (TCN for other-agent motion, ViT for 3D scene occupancy), then produces FiLM-style feature-wise modulations (γ, β) on the intermediate latent features of the prior. This design enables robust plug-in conditioning per interaction mode without expensive joint retraining.
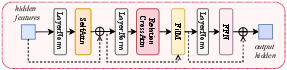
Figure 2: Architecture of Meta-Interaction Block. Context features induce modulation signals controlling the generative pathway during denoising.
The system supports compositional inference: modulations from several adapters can be combined via weighted, L2-clamped summation, ensuring stability even as novel interaction types (e.g., mixed human-human-scene) are constructed on the fly.
Frame-wise Segment Refinement (FWSR)
While segment-based generation optimizes for long-term motion coherence, it incurs inherent latency and loses granularity for reaction to online cues. ReMoGen introduces a lightweight Frame-wise Segment Refinement module, which, operating directly in latent space atop the initial segment prediction, incorporates latest observed cues to refine motion at each frame. FWSR mirrors the attention-plus-FiLM structure of MIMs but applies only a single-step correction per frame, ensuring fine-grained responsiveness without repeated diffusion sampling.

Figure 3: Ablation on Frame-wise Segment Refinement. FWSR updates enable rapid response to dynamic cues without sacrificing global coherence.
Empirical Evaluation
Human-Human and Human-Scene Interaction
On Inter-X (HHI) and LINGO (HSI), ReMoGen decisively outperforms both autoregressive and diffusion-based baselines in FID, R-Precision, MM-Dist, and achieves real-time rollout (<0.05s/frame). Notably, it achieves a 0.166 FID on Inter-X with FWSR enabled—a substantial margin over FreeMotion and ReGenNet. ReMoGen maintains high diversity, low peak jerk, and competitive contact and collision metrics, evidencing physically plausible, semantically consistent, and stable motion rollouts in online evaluation settings.

Figure 4: Qualitative comparisons on HHI: ReMoGen produces temporally coordinated and intention-aligned interaction responses—prior methods exhibit unstable contacts and mistimed reaction.
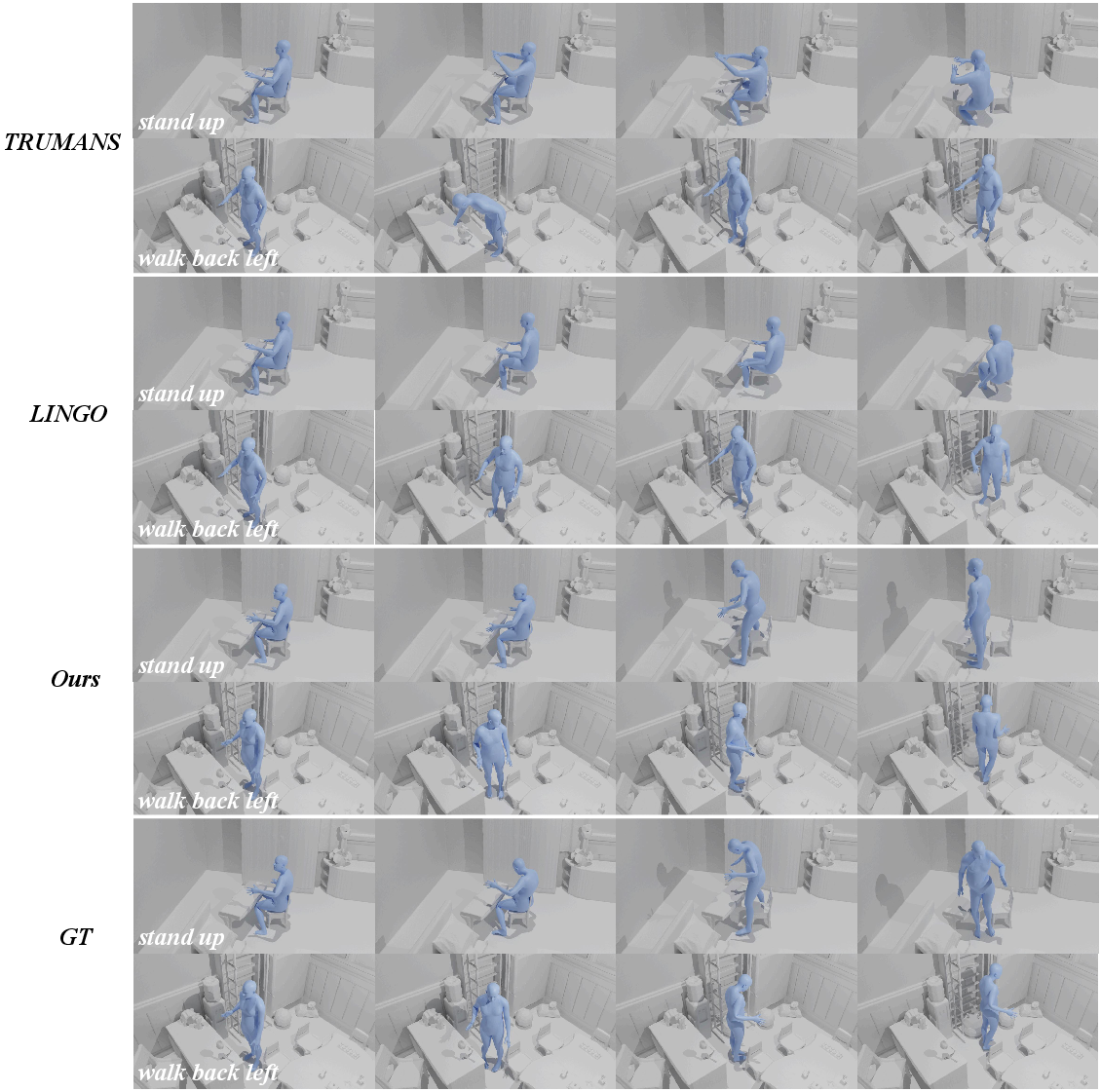
Figure 5: Qualitative comparisons on HSI: Strong scene awareness and object interaction emerge from modular conditioning, outperforming scene-naïve baselines.
Generalizability and Compositionality
Experimental results on EgoBody illustrate the capacity for zero-shot composition and rapid few-shot adaptation. While single-domain modules are insufficient for mixed scenarios, a linear composition of respective modulations improves adaptation, and prior-initialized fine-tuning achieves near-optimal FID (<0.3) in as few as 2k–10k steps—orders of magnitude more efficient than training from scratch.

Figure 6: Few-shot fine-tuning on EgoBody initialized from the universal prior yields rapid convergence toward natural, semantically rich responses.

Figure 7: ReMoGen outputs in diverse human-human-scene settings display strong behavioral variety and robust adaptation to mixed cue types (finetuned 65k steps).
Role of Universal Prior and Modular Adaptation
Ablation studies highlight the necessity and effectiveness of both the universal prior and modular adaptation strategy. Models without the prior or with naive joint fine-tuning overfit or suffer from unstable kinematics. The decoupled approach—retaining a frozen prior and adapting only via MIMs—preserves low-level motion diversity and structure while infusing scenario-specific responsiveness.

Figure 8: Prior-guided modular learning (right) maintains coherence and naturalness compared to from-scratch or joint-finetuned baselines (left).
Robustness and Sensitivity Analysis
ReMoGen is robust to perturbations in semantic input; in the absence or contradiction of text prompts, the interaction-driven cues dominate behavior, leading to stable, contextually plausible outputs. Encoder architecture choices for interaction context have marginal impact, affirming the architectural flexibility and scalability of the proposed modular scheme.

Figure 9: No-text and shuffled-text results: physically plausible reactions are preserved by design, as only the universal prior consumes text; MIMs are explicitly text-agnostic.
Practical and Theoretical Implications
Practically, ReMoGen’s latency-optimized inference, coupled with compositional conditioning, makes it well-suited for deployment in embodied agents, real-time animation, and interactive robotics. The modular paradigm permits rapid adaptation to new interactive tasks, environments, or compositions of social/physical cues with minimal overhead. Theoretically, the separation of universal and domain-specific modules models a reusable "motor manifold" with context-driven modulation—an approach analogous to hierarchical control in biological motor planning.
Future directions may involve expanding the range of available adapters (e.g., for contact-rich, manipulation-focused, or non-human entities), dynamic adaptive weighting for context fusion, multi-lingual or multimodal high-level intents, or integration with reinforcement learning for objective-driven interaction adaptation. More expressive priors (e.g., foundation-model-scale motion networks) and more sophisticated fusion schemes for dynamic composition are likely developments.
Conclusion
ReMoGen constitutes a significant step towards data- and compute-efficient, real-time, interaction-to-reaction motion generation. Its modular paradigm, leveraging a universal motion prior with pluggable interaction awareness and lightweight frame-wise refinement, enables robust performance across diverse, heterogeneous, and dynamic interaction scenarios. Its architecture provides a strong foundation for future research in scalable, adaptive, and generalizable embodied intelligence.

Figure 10: Qualitative results demonstrate broad versatility—ReMoGen enables Taichi, chat, pursuit, and scene-aware behaviors from unified, multimodal conditioning.