- The paper demonstrates that non-task prompt context can reduce LLM reasoning trace lengths by up to 50%.
- It employs controlled experiments across diverse models and tasks to show compressed self-verification and decreased uncertainty monitoring.
- The findings imply that effective context management is crucial for maintaining robust multi-step reasoning in high-stakes AI applications.
Reasoning Shift in LLMs: The Influence of Context on Chain-of-Thought Execution
Introduction
"Reasoning Shift: How Context Silently Shortens LLM Reasoning" (2604.01161) systematically investigates a critical yet understudied phenomenon in LLMs: the context-driven compression of reasoning traces during inference. The authors challenge the assumption that LLMs’ chain-of-thought (CoT) reasoning is invariant to the surrounding prompt context when solving a problem. Through targeted protocol manipulations across tasks and models, they present robust empirical evidence that various forms of non-task-related prompt context cause LLMs to significantly reduce their reasoning trace lengths—frequently by as much as 50%—with substantial ramifications for self-verification, uncertainty management, and performance on complex tasks.
Experimental Setup and Key Observations
A comprehensive experimental framework is developed to compare LLM reasoning under four explicit context conditions: (1) Baseline (task in isolation), (2) Subtask (solving two independent problems), (3) Long input (insertion of large irrelevant text chunks), and (4) Multi-turn (solving in a chat sequence). Evaluations span SOTA models including Qwen3.5-27B, GPT-OSS-120B, Gemini 3 Flash, Kimi K2 Thinking, and reasoning-specialized Olmo-3 variants, with performance measured on MATH500 and IMOAnswerBench datasets.
Across models and tasks, all non-baseline scenarios consistently precipitate compressed reasoning: LLMs generate up to 50% fewer reasoning tokens per problem without any prompt modifications targeting their stopping strategy or explicit output truncation. The effect magnitude is context-size dependent: even the inclusion of irrelevant content spanning several hundred tokens reduces reasoning budgets by nearly 20%, whereas insertion of distractors on the order of tens of thousands of tokens imposes the most severe trace shortening.
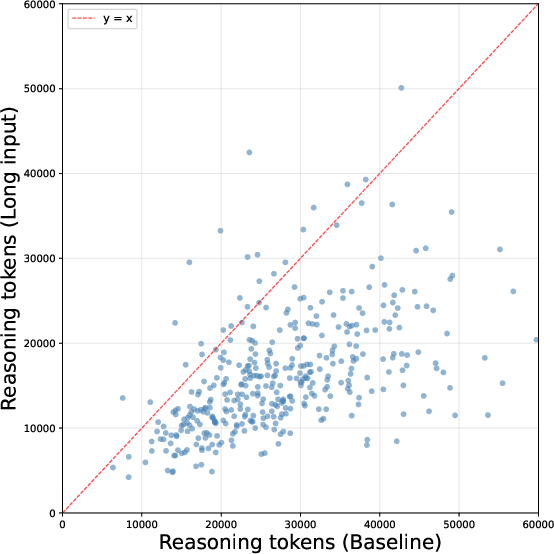
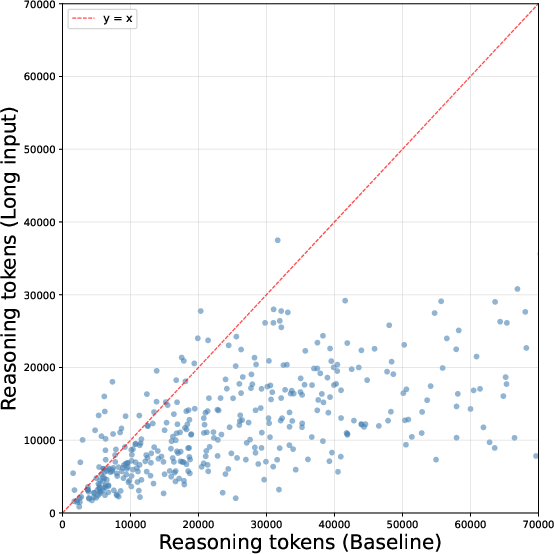
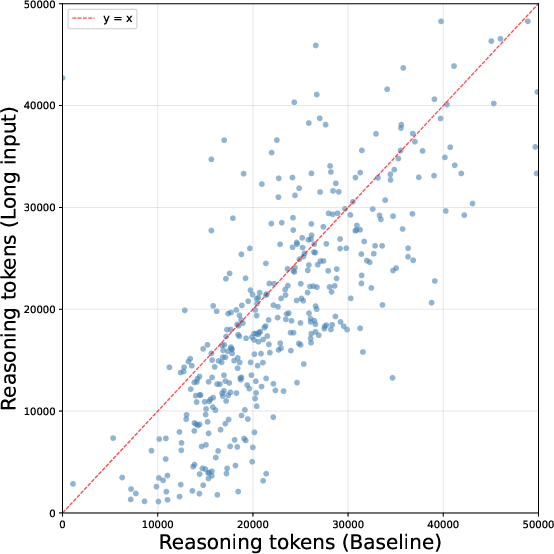
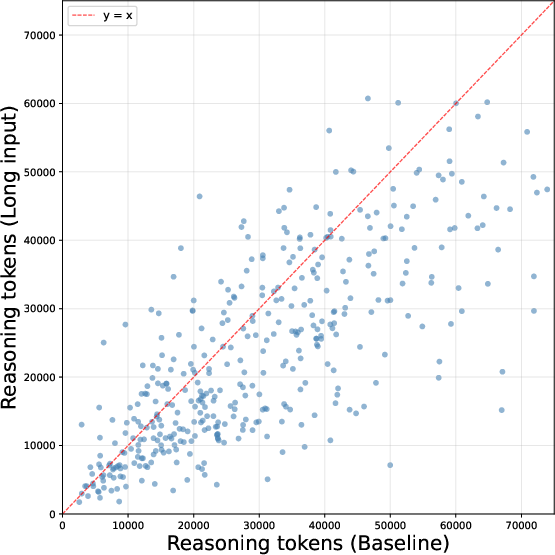
Figure 1: Scatterplot of reasoning token counts per problem for Qwen3.5-27B comparing Baseline and Long Input protocols, visualizing systematic trace compression under contextual distraction.
The phenomenon is not restricted to LLMs operating in explicit 'thinking' mode but is vastly more pronounced there, as shown by the comparison of Qwen3.5-27B in both standard and chain-of-thought–enabled regimes.
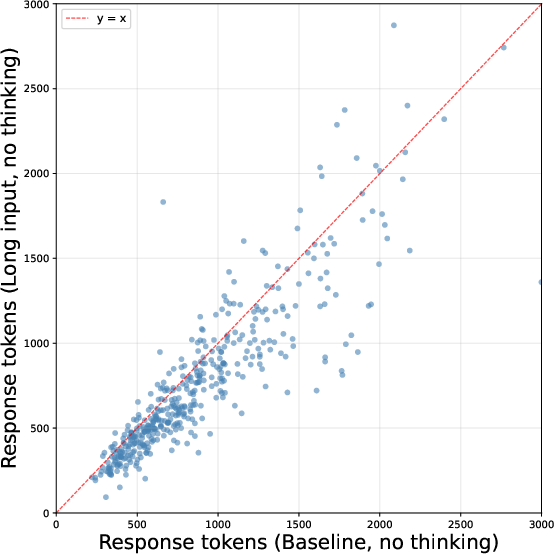
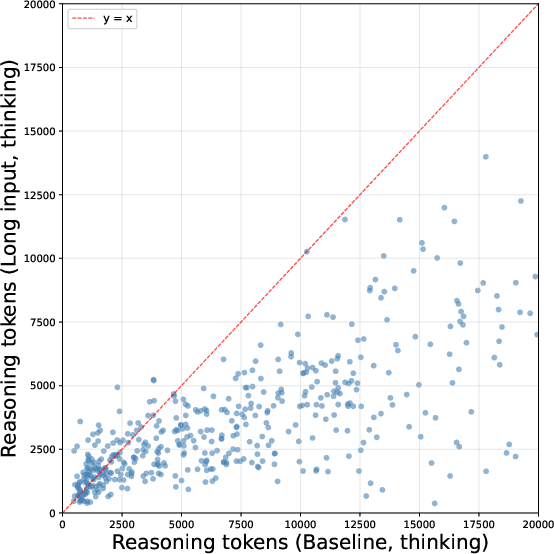
Figure 2: Per-problem response token comparison for Qwen3.5-27B in standard (no thinking) mode, indicating trace compression in the presence of long context distractors.
Behavioral Analysis: Self-Verification and Uncertainty Management
Manual and automated fine-grained annotation of reasoning traces, drawing from established frameworks [venhoff2025understanding], exposes the qualitative nature of this reasoning shift. While LLMs do not appear confused by prompt distractors or fail to parse the task, the reasoning chains produced in rich context exhibit truncated post-solution behaviors—especially self-checks, alternative strategy generation, and explicit uncertainty statements.
Sentence-level transition matrices extracted from Qwen3-32B on MATH500 reveal a pronounced increase in the terminal transition from 'final answer emission' to stopping, bypassing metacognitive behaviors such as "but let me check," "alternatively," "wait," or systematic review steps. This is further corroborated by targeted resampling experiments which demonstrate that the same reasoning prefix, when continued in a long-context scenario, yields a much higher ratio of immediate termination and sharply reduced self-verification token frequencies.
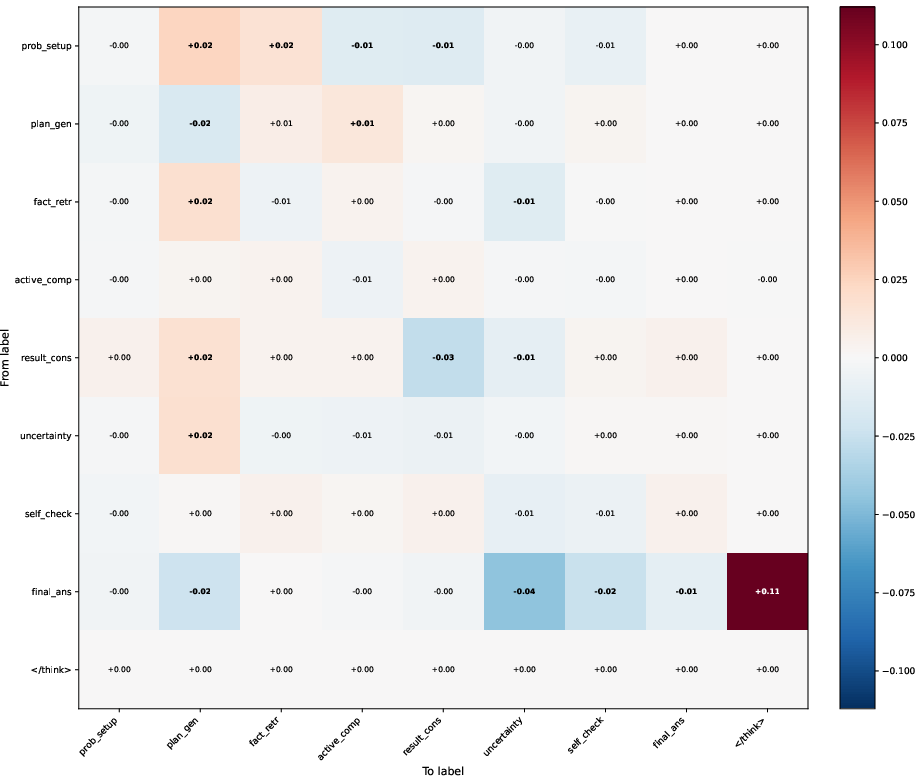
Figure 3: Heat map of the difference in transition probabilities between Long Input and Baseline setups; critical increases in transitions to task termination highlight suppressed metacognition.
Concrete analysis of inserted prompt references shows LLMs typically detect and dismiss distractor content at the outset ("the old data is Shakespeare, but the problem is math"), but this meta-awareness does not mitigate the trace length suppression, nor does it trigger additional justification steps for the answer found.
Implications for Model Robustness and Reasoning Calibration
A direct corollary of these findings is a performance drop on harder problems paralleling trace compression in all non-baseline setups. While for easy tasks, the forced brevity can reduce excessive deliberation ("overthinking") without impacting accuracy, in complex or multi-step reasoning tasks the absence of self-reflection and verification steps leads to degraded correctness. This is manifested across all agentic, long-context, and multi-task settings. The effect is robust across model families and remains substantial after scaling context sizes and verifying with various inference protocols.
The work convincingly demonstrates that current LLM test-time scaling and chain-of-thought paradigms do not effectively insulate stepwise rationality or metacognition from context interference. The inability to maintain calibrated reasoning effort regardless of prompt condition signals a gap in robust agentic behavior—a critical consideration as LLMs are deployed for multi-agent collaboration, hierarchical decomposition, or persistent agent loops where context drift or clutter is common.
Theoretical and Practical Ramifications
The central finding—that prompt context can silently and non-locally modify high-level reasoning control signals—undermines a tacit assumption of agentic LLM reliability across prompt scopes. This exposes new avenues for adversarial context injection, unintentional forgetting, or breakdowns in multi-step CoT workflows. Practically, imposed prompt compaction, recursive breakdown, or parallel agent architectures may not realize their expected benefits if the underlying reasoning supervisor (the LLM) implicitly short-circuits its own metacognition under broader context.
Mechanistically, this aligns with prior works that document prompt length and context fragmentation effects on retrieval capabilities [du2025context_length_alone, needleinhaystack, laban2026llms_get_lost], but the present study establishes that even perfect task localization does not guarantee robust, invariant stepwise reasoning execution.
This draws attention to the need for explicit context management strategies, structural prompt designs, and innovations in LLM training regimes to mitigate reasoning drift. Potential directions include dynamic CoT budget negotiation, explicit uncertainty tracking, selective context gating or pruning, and recursive or parallel agent frameworks that support stable high-level behavioral policies even under variable context windows [yang2025pencil, ning2024skeletonofthought, zheng2025parallelr1, zhang2025recursive]. Analysis of these failure modes should inform safe deployment in high-stakes, persistent, or open-ended agent scenarios.
Conclusion
"Reasoning Shift: How Context Silently Shortens LLM Reasoning" rigorously delineates a significant, previously unquantified vulnerability in LLM chain-of-thought execution: context-induced reasoning trace compression that selectively suppresses self-verification and uncertainty monitoring, degrading performance on complex tasks even when task recognition remains robust. These findings have nontrivial implications for LLM robustness, context management, and the design of multi-agent or multi-tasking AI systems. Further research is needed to engineer prompt structure, inference protocols, or architectural mechanisms resilient to context-driven rationality drift.

