- The paper introduces a reduction of costly third-order contraction terms to a matrix-free, second-order structure using log-determinant identities.
- It leverages stochastic Hutchinson trace estimation and Krylov methods to achieve near-linear complexity in high-dimensional, sparse polynomial settings.
- Empirical results confirm near machine-precision accuracy and scalable performance, enabling practical integration of affine-invariant optimization techniques.
Scalable Affine Normal Directions via Log-Determinant Geometry in Sparse Polynomial Optimization
Overview
This paper introduces a computational framework for evaluating affine normal directions, an affine-invariant geometric construct relevant to optimization, using a log-determinant geometric representation. The main technical advance is a reduction of the classical third-order contraction term—previously the main computational bottleneck—to a second-order structure, thereby enabling scalable, matrix-free evaluation in high-dimensional and sparse polynomial optimization settings. The authors rigorously analyze the cost and approximation properties of the approach, demonstrate near machine-precision agreement with explicit autodifferentiation-based formulas, and empirically establish near-linear complexity in both ambient dimension and polynomial sparsity.
Log-Determinant Reduction of the Affine Normal
Affine normal directions arise from affine differential geometry and provide descent directions for optimization that are affine-invariant, in contrast to Euclidean gradient or Newton directions which capture only second-order local curvature. The classical representation involves third-order derivatives and costly tensor contractions, which is prohibitive in high dimensions. The central mathematical result is the identification:
fpqfpqi=∂ilogdetHT,
where HT is the tangent Hessian block, fpq its inverse, and fpqi the third derivative tensor. This log-determinant identity (see Lemma 2) enables the replacement of explicit third-order contractions with matrix-free, second-order operator evaluations—specifically, gradients of the log-determinant of HT.
Implication: Affine normal computation is thus reorganized around Hessian–vector products, tangent space projections, Krylov subspace linear solves, and stochastic trace estimation, rather than explicit formation of large derivative tensors.
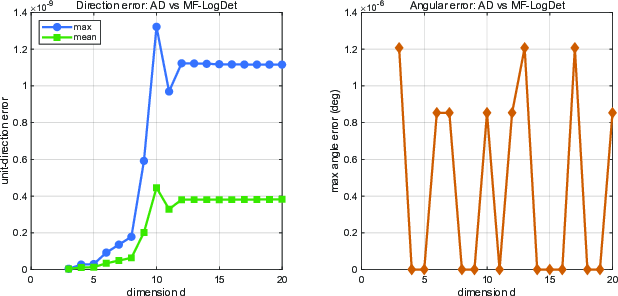
Figure 1: Accuracy of MF-LogDet relative to the original AD-based affine normal computation. The normalized direction error remains around 10−9, resolving computational bottlenecks associated with third-order terms.
Matrix-Free Methods for High-Dimensional Sparse Polynomial Objectives
For polynomial objectives, all derivatives remain within the same monomial family, and the structure of sparsity can be exploited for computational efficiency. The authors develop explicit matrix-free computational kernels for:
- Gradient and Hessian evaluation via sparse monomial contractions.
- Efficient computation of Hessian–vector products (Prop. 3).
- Evaluation of directional third-order contractions for required trace and log-determinant computations (Prop. 4).
This enables the affine normal direction at a point x to be computed via:
- Construction of an orthonormal tangent basis T to the level set.
- Assembly of the tangent Hessian operator HT=T⊤∇2f(x)T.
- Matrix-free estimation of ∇tlogdetHT through stochastic Hutchinson trace estimation, requiring only Hessian–vector and third-order directional evaluations.
- Solution of a shifted tangent linear system via Krylov methods.
These steps can all be parallelized and executed efficiently on modern hardware.
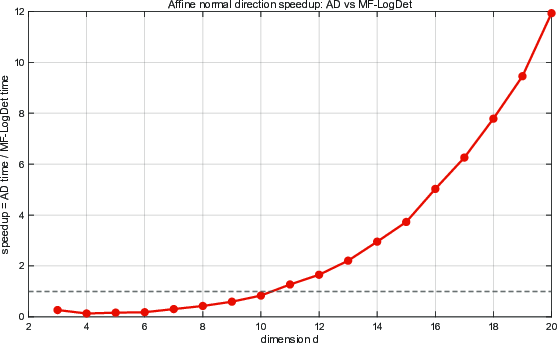
Figure 2: Speedup of affine normal computation across dimensions, defined by HT0; substantial gains manifest once dimensionality increases beyond moderate values.
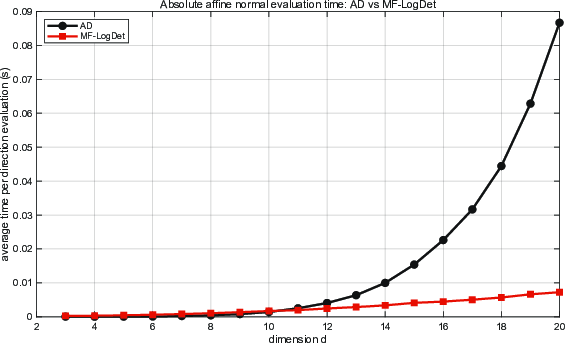
Figure 3: Average runtime per affine normal evaluation for AD and MF-LogDet as a function of the dimension HT1. While AD is competitive in very low dimensions, its runtime grows much more rapidly.
Stochastic Trace Estimation and Complexity Analysis
The computation of the log-determinant gradient is accomplished by stochastic Hutchinson trace estimation—approximating HT2 via randomized Rademacher probe averages. Each probe involves a tangent linear system solve and a third-order directional evaluation, both implemented with matrix-free kernels.
Theoretical analysis (Theorem 7) yields:
- Overall Complexity: HT3, where HT4 is the probe count, HT5 the Krylov iterations, HT6 the number of monomials, and HT7 the average support size. For bounded HT8 and HT9, this yields linear complexity fpq0 in ambient dimension.
- Error Analysis: Stability theorems rigorously bound the propagation of errors from stochastic trace estimation and inexact Krylov solves through to the normalized affine normal direction (Corollaries 8 and 9).
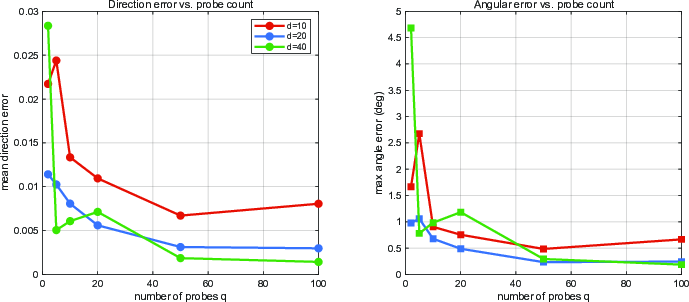
Figure 4: Effect of the Hutchinson probe count fpq1 on affine normal accuracy. Increasing fpq2 yields a monotonic improvement in the normalized direction error, aligning with the variance bounds of the estimator.
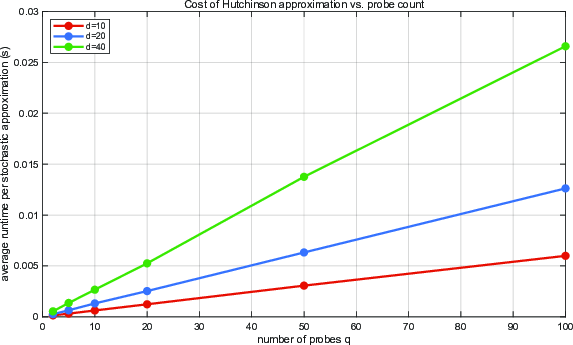
Figure 5: Runtime of the stochastic trace approximation as a function of fpq3 matches the theoretical linear cost model, confirming anticipated scalability properties.
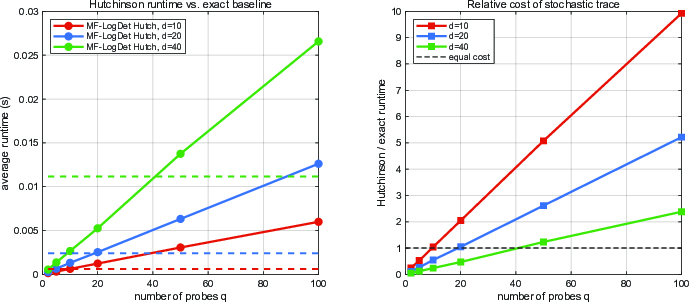
Figure 6: Runtime comparison between stochastic Hutchinson trace approximation and exact evaluation; substantial runtime reductions for the stochastic variant at moderate probe counts and high dimension.
Numerical Experiments
Extensive experiments address four principal questions:
- Agreement with Explicit AD Formulas: MF-LogDet achieves fpq4 normalized directional error against AD-based affine normal computation, confirming its exactness.
- Stochastic Trace Accuracy-Cost Tradeoffs: With moderate probe counts (fpq5–fpq6), normalized direction errors are well below fpq7 even in large-scale problems; runtime scales linearly in fpq8 and large savings over exact evaluation materialize at high fpq9 and moderate fpqi0.
- Scaling in Dimension: For polynomial sparse quartics with fpqi1 and bounded fpqi2, empirical fits give runtime exponent near unity (1.01), matching theoretical predictions.
- Scaling in Sparsity: At fixed dimension, scaling with structural sparsity parameter fpqi3 yields observed exponent fpqi4, robustly supporting linearity.
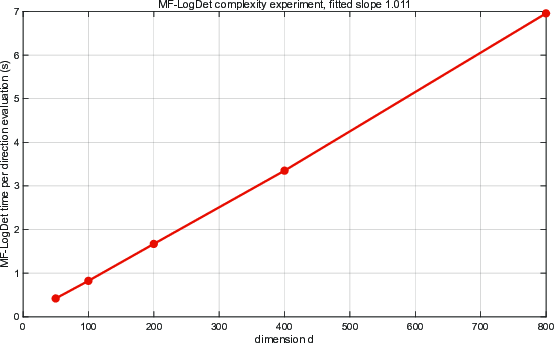
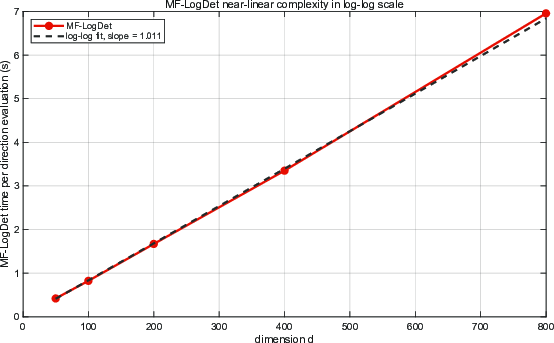
Figure 7: Average runtime per MF-LogDet affine normal evaluation as a function of the dimension fpqi5; log-log fitting confirms linear scaling.
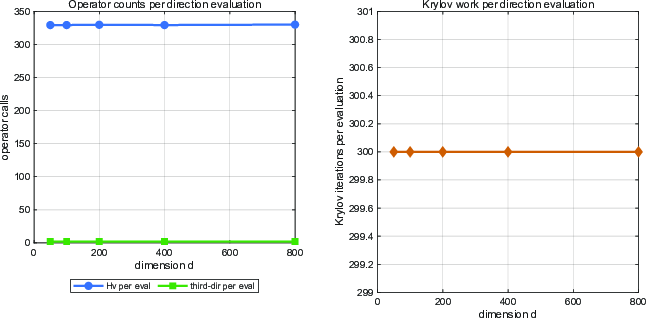
Figure 8: Operator counts per MF-LogDet affine normal evaluation remain essentially constant as fpqi6 increases, confirming operator-level stability.
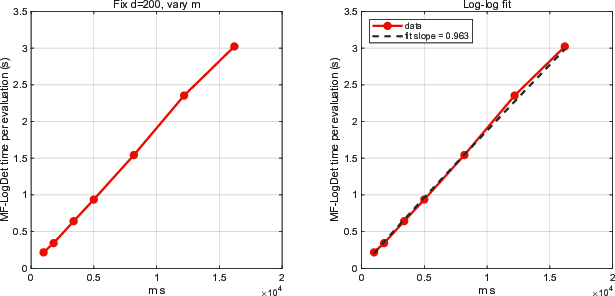
Figure 9: Runtime of one MF-LogDet affine normal evaluation versus the sparsity scale fpqi7; log-log fit slope approximately fpqi8 supports near-linear scaling in sparsity.
Implications, Limitations, and Future Directions
The approach renders practical, for the first time, the computation of affine normal directions in high-dimensional settings, especially for structured objectives with polynomial and sparse structure. By leveraging algebraic closure of monomial derivatives and matrix-free computational primitives, the method aligns the per-iteration complexity with that of matrix-free Newton or natural gradient approaches, with an additional (controlled) stochastic trace cost.
Practical implications include:
- Viable integration of affine-invariant optimization algorithms into large-scale, structure-exploiting applications in machine learning, computational geometry, and physical systems inference.
- Enabling of further theoretical analysis of affine-invariant methods in high dimensions, given the new class of tractable computational primitives.
Limitations: The main regimen of scalability is for sparse polynomial objectives; extension to more general function classes or to settings with less exploitable algebraic structure remains open. Per-iteration cost may exceed that of Newton-CG if the stochastic trace budget fpqi9 is large or the problem is poorly conditioned.
Future Directions:
- Development and analysis of preconditioners for tangent linear systems tailored to polynomial sparsity or block-structure.
- Deployment of the MF-LogDet framework in large-scale machine learning pipelines (e.g., deep learning or kernel machines with polynomial kernels).
- Extension to non-polynomial but structured objectives, such as trigonometric polynomials or functions on manifolds via coordinate charts.
- GPU and distributed implementations to further exploit operator-level parallelism.
Conclusion
This work resolves the computational challenge of evaluating affine normal directions in high-dimensional, sparse polynomial optimization. By establishing an exact second-order reduction via log-determinant geometry and developing a matrix-free, stochastic trace-based computational framework, the authors demonstrate both theoretical validity and practical scalability, verified by detailed numerical experiments. These contributions establish new connections between affine differential geometry, log-determinant curvature, and scalable structured optimization, paving the way for practical deployment of affine-invariant algorithms in large-scale settings.