- The paper introduces explicit finite-sample, minimax-optimal excess risk bounds for non-monotonic losses in conformal risk control.
- The paper demonstrates that risk control deteriorates with increased grid resolution unless the calibration sample size scales appropriately.
- The paper empirically compares CRC-NM with alternative methods, highlighting improved stability and efficiency in both synthetic and real-world settings.
Introduction
This work rigorously analyzes Conformal Risk Control (CRC) procedures under violation of the loss monotonicity assumption, establishing distribution-free finite-sample guarantees for non-monotonic loss functions within conformal inference. CRC, an extension of conformal prediction, aims to select set-valued predictors controlling E[ℓ(Xn+1,Yn+1;λ^)]≤α for user-specified loss ℓ and target level α, by tuning over a parameter grid Λ. While classical CRC theory requires ℓ(⋅,⋅;λ) to be non-increasing in λ, practical losses—especially those balancing competing objectives such as coverage vs. efficiency in object detection or fairness metrics—often exhibit non-monotonicity. The primary contribution is explicit finite-sample, minimax-optimal excess risk bounds for such settings, leveraging concentration phenomena and empirical process analysis.
Failure Modes of CRC under Non-Monotone Losses
The paper first sharpens known counterexamples where CRC fails to guarantee risk control without monotonicity (2604.01502). The analysis demonstrates that when selecting λ^ from a discrete grid of size m using n samples, the excess risk above α scales as ℓ0, and risk control can fail if calibration sample size ℓ1 does not grow with grid resolution ℓ2. Specifically, with ℓ3, probability mass accumulates on riskier selections, and learned selection thresholds no longer guarantee the nominal target.
Main Theoretical Results: Minimax-Optimal Risk Bounds
The major technical result establishes a finite-sample upper bound for bounded, non-monotonic losses over a grid, showing that the excess risk incurred by data-dependent parameter selection is at most ℓ4 for universal ℓ5. This is achieved via uniform concentration inequalities (Hoeffding/Bernstein and their empirical variants, see appendix) and a union bound over candidate thresholds:
Theorem (informal): If ℓ6 is bounded and ℓ7 is a grid of ℓ8 candidate values, then for the conformal selector ℓ9,
α0
A matching minimax lower bound is proven, asserting that no selection procedure— irrespective of adaptivity or prior knowledge—can uniformly achieve smaller excess for all bounded, non-monotonic losses:
Proposition: There exists a distribution such that
α1
This scaling is fundamental: increasing grid granularity (larger α2) enhances discretization but exacerbates the statistical risk, and both phenomena must be balanced.
Exploiting Structure: Monotonicity, Lipschitz Losses, and Improved Rates
The authors elucidate a hierarchy of guarantees based on structural assumptions. For monotone losses (classical CRC-type settings), exact risk control at level α3 is retained, eliminating the statistical correction term. For globally Lipschitz losses under a margin condition, the excess risk decays exponentially in α4, controlled by the probability that selection using α5 or α6 samples might disagree. This stability-based perspective connects with broader algorithmic stability literature.
Empirical Comparisons: CRC-NM vs. Monotonization and Bootstrapped Stability
The work benchmarks CRC-NM (“non-monotonic” method, i.e., unaltered empirical risk with finite-sample correction α7) against various alternatives, including empirical monotonicity transforms and stability-based bootstrapping approaches (2604.01502).
Empirical risk selection is compared to two established “monotonization” strategies:
- Loss-monotonization replaces each loss by the worst-case value over α8—enforcing monotonicity per sample but usually resulting in highly conservative thresholds.
- Risk-monotonization enforces monotonicity on the aggregate empirical risk curve, selecting the minimal feasible threshold, but delivers only asymptotic guarantees.
Another approach, CRC-C, uses bootstrap-estimated selection-level corrections (stability-based).
In non-monotone synthetic multilabel settings, CRC-NM achieves precise risk control, while monotonization methods overinflate set sizes and risk; CRC-NM adjusts only by the minimax correction α9. In near-monotonic real-data experiments (ImageNet classification, COCO object detection), CRC-NM provides more stable and less conservative solutions than loss-monotonization and (when empirical variance is moderate/low) more reliable risk control than CRC-C.
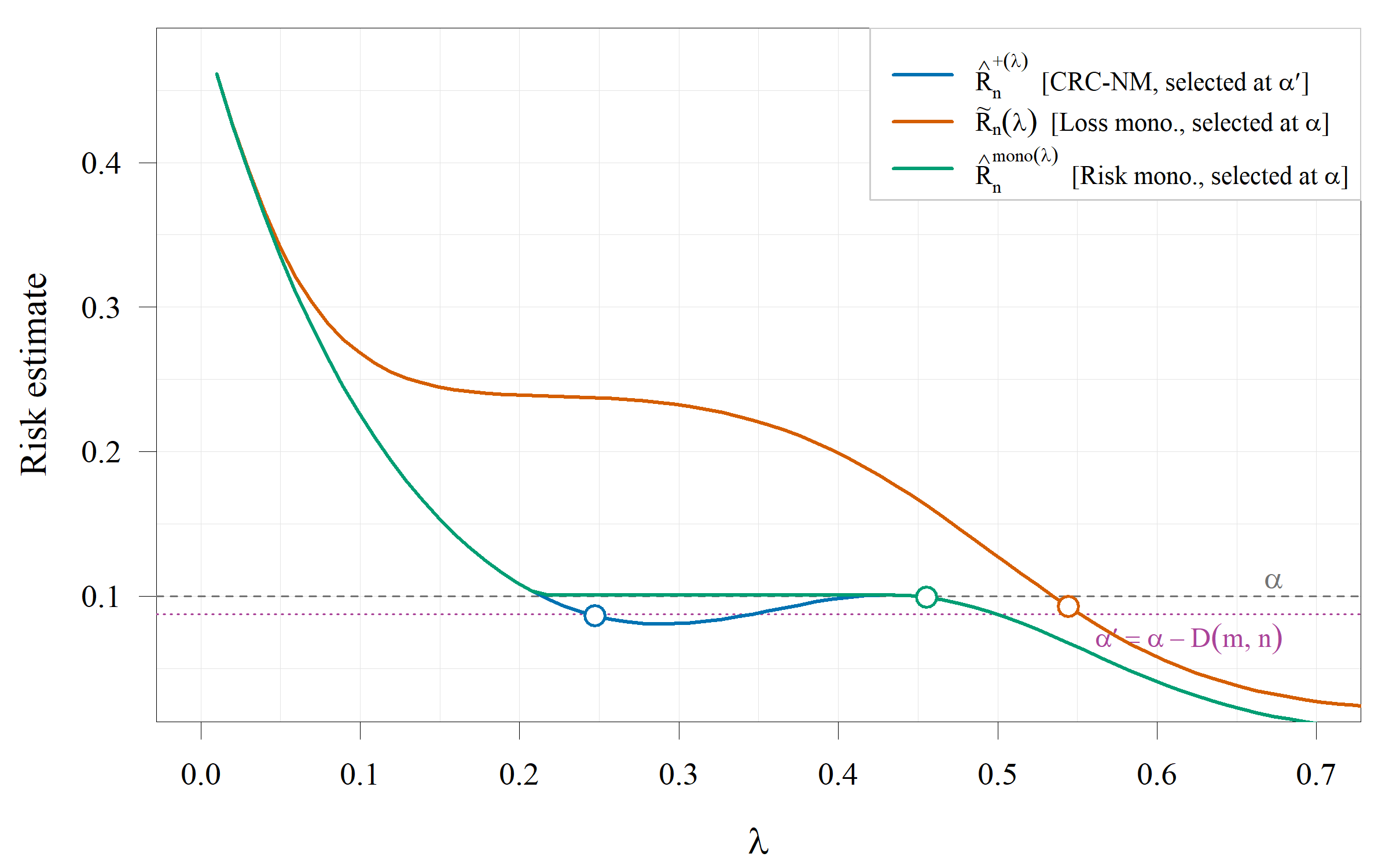
Figure 1: Empirical risk curves and selected thresholds under non-monotonic loss, contrasting achievable risk for CRC-NM, loss-monotonization, and risk-monotonization.
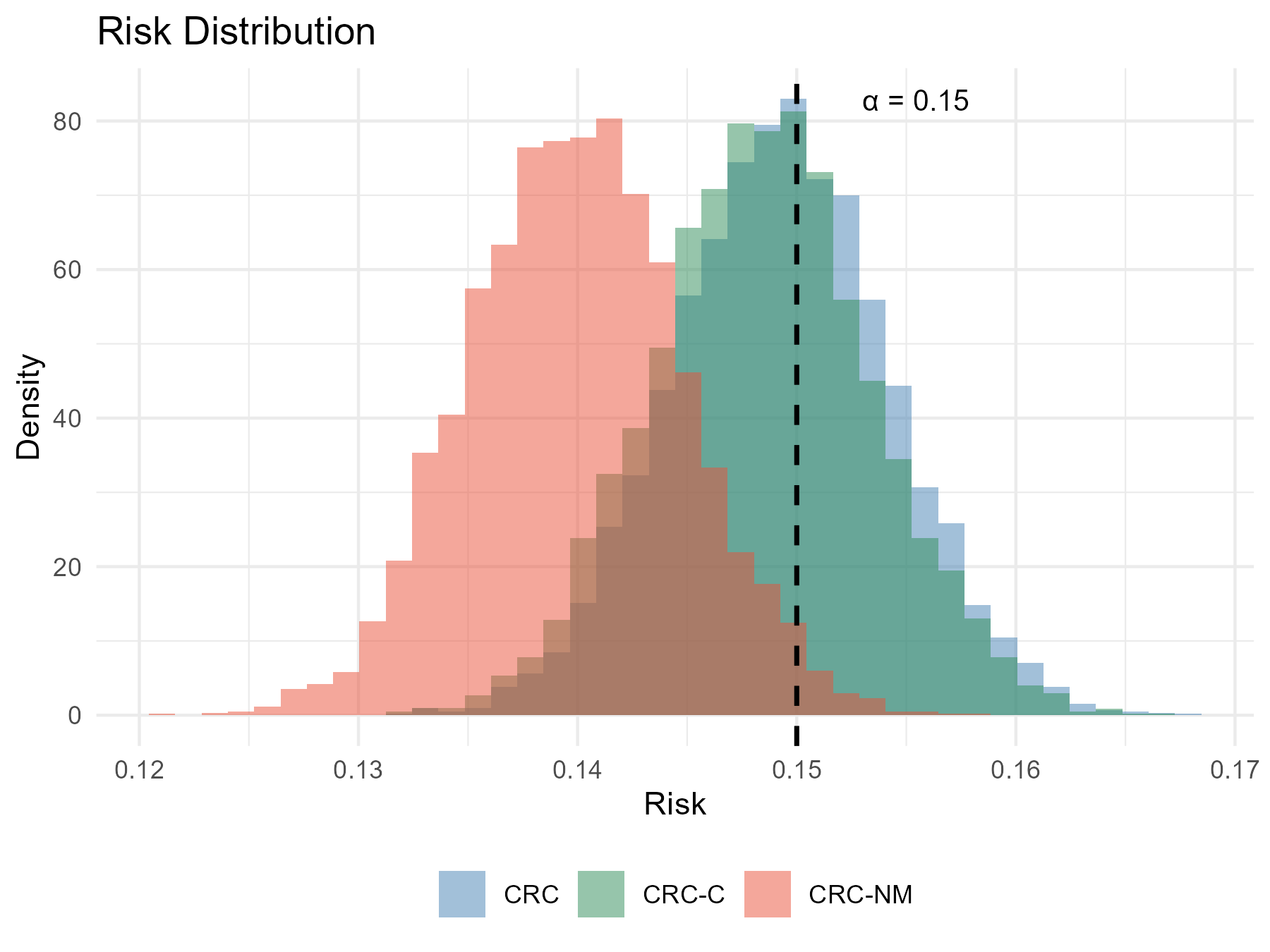
Figure 2: Distribution of empirical risks for ResNet-18 over ImageNet calibration-test splits showing that CRC-NM and CRC-C both control risk, with CRC-NM incurring a slightly larger explicit correction.
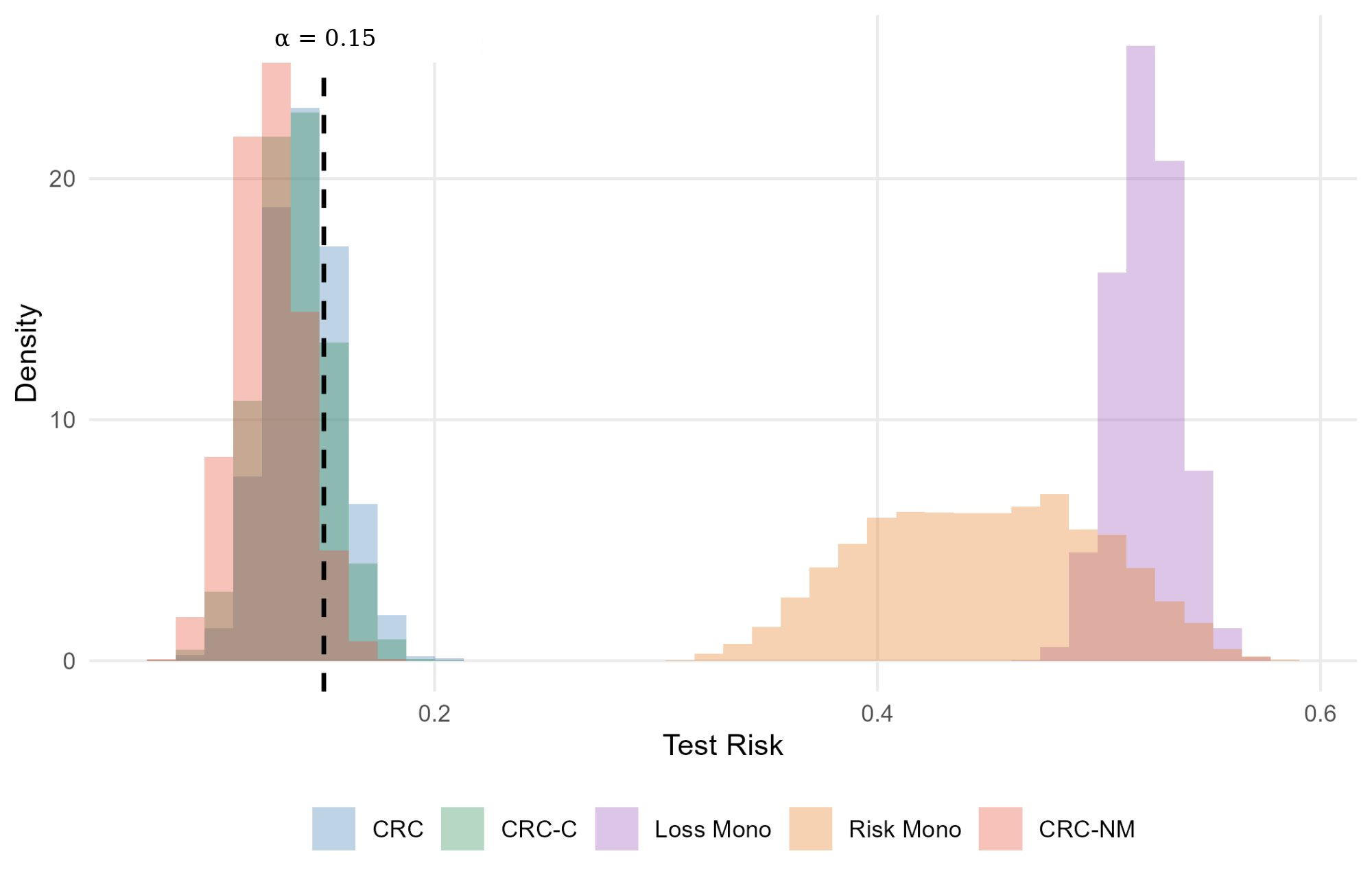
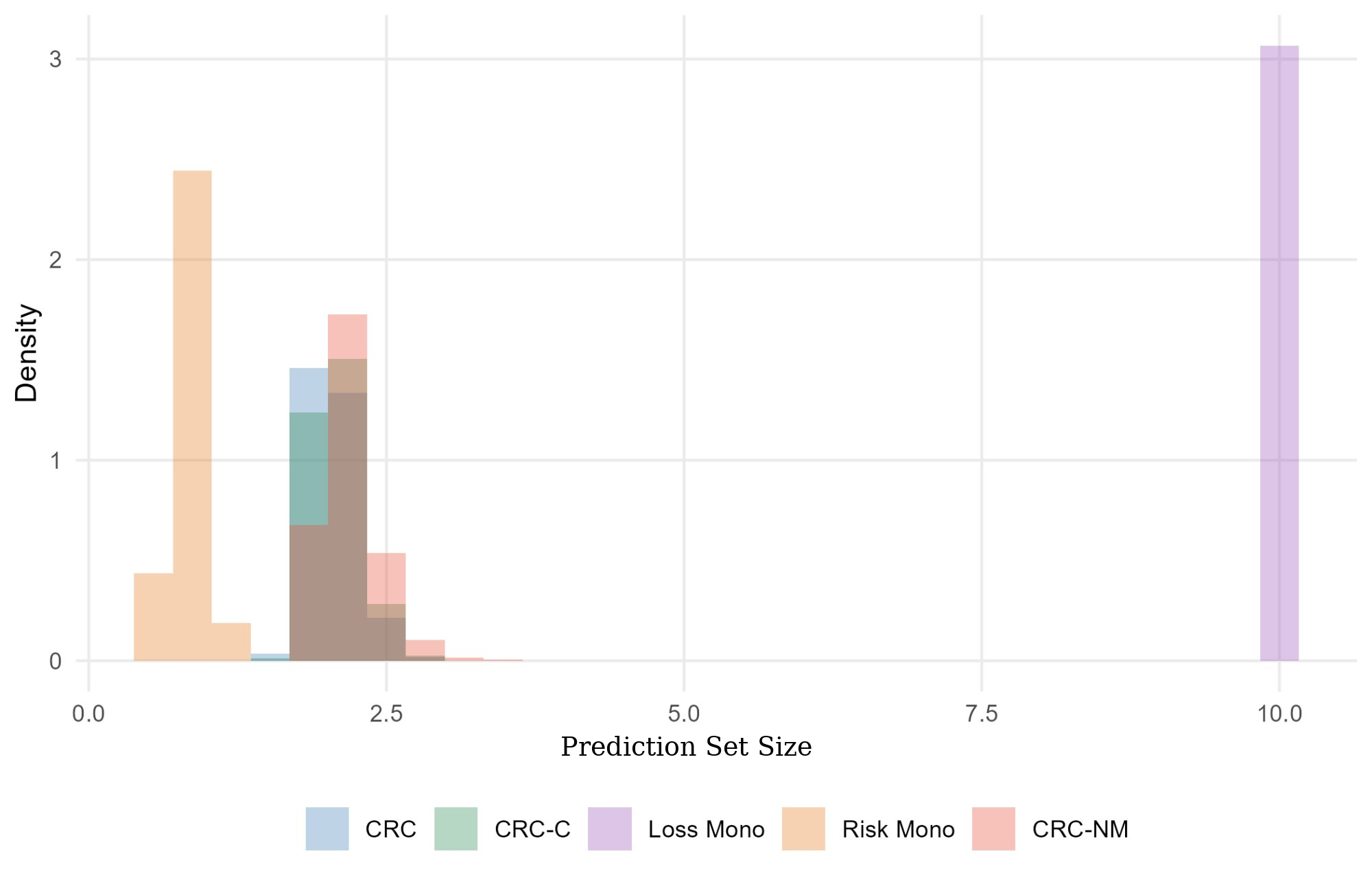
Figure 3: Synthetic multilabel classification experiment showing CRC-NM maintains tight risk control under oscillatory, non-monotonic loss landscapes, compared to other methods.
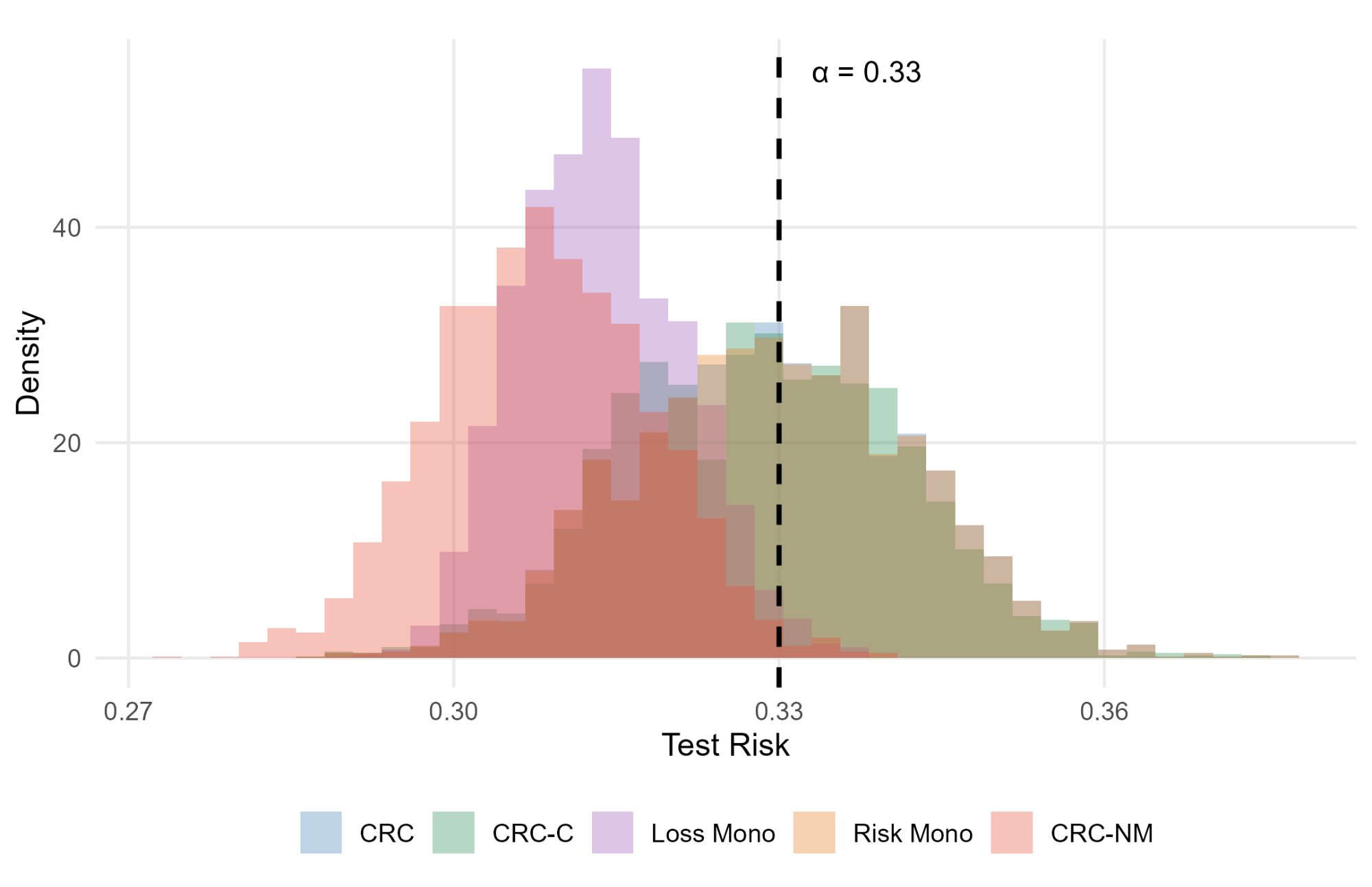
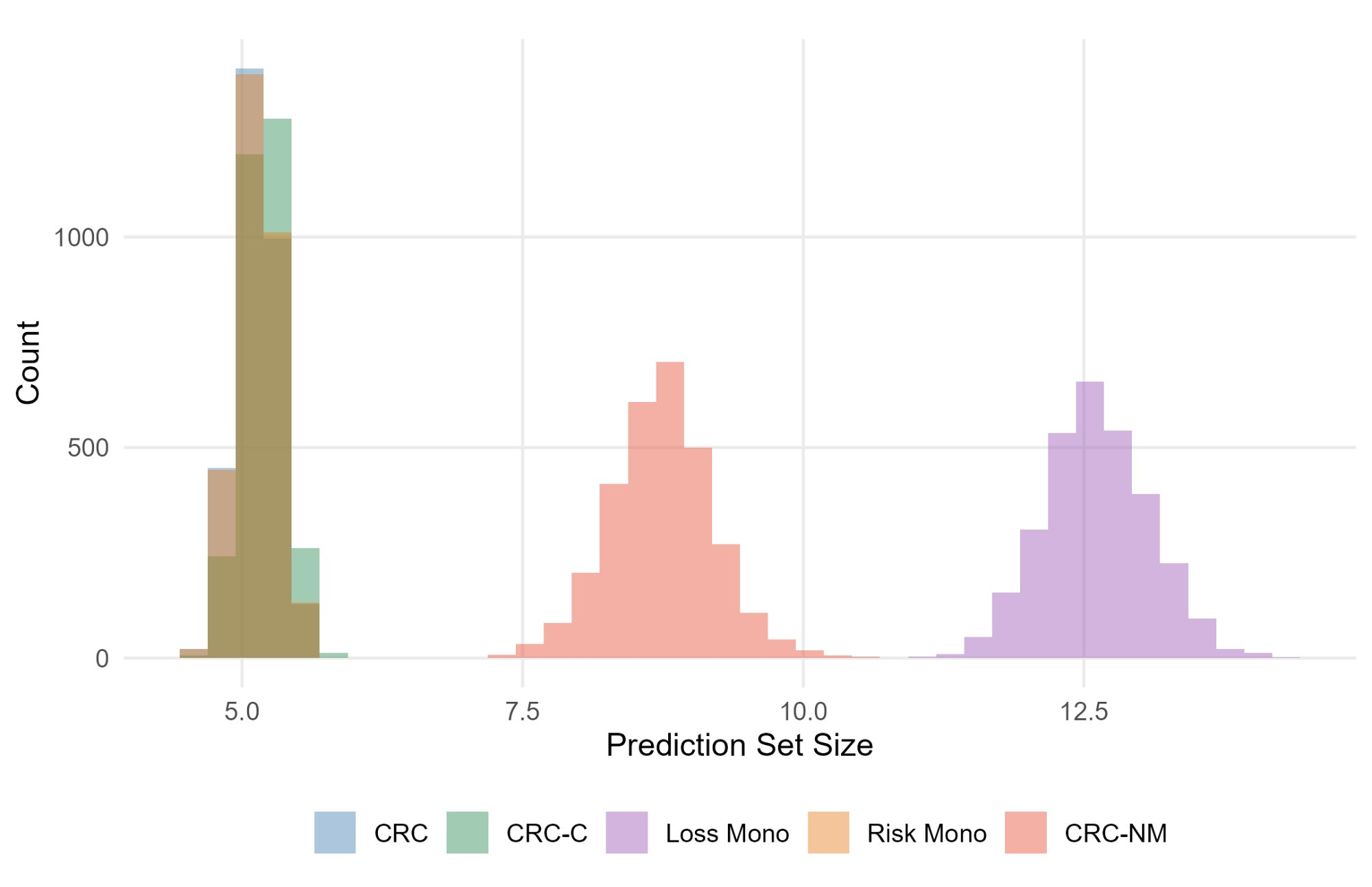
Figure 4: COCO object detection experiment: (left) test risk distributions showing CRC-NM's conservative but reliable control; (right) corresponding prediction-set size distributions highlighting efficiency.
Extensions: Distributional Shift and Importance Weighting
The framework is generalized to non-i.i.d. test settings (covariate and more general distribution shift), by importance weighting the empirical risk for candidate parameters. If the test likelihood ratio Λ0 is bounded, the excess risk incurs a linear penalty in its upper bound Λ1, but the Λ2 rate is preserved.
Practical and Theoretical Implications
- Practical Control: For bounded non-monotonic losses, risk control at target level Λ3 is feasible and theoretically valid even without monotonicity, given sufficient calibration data relative to grid size.
- Model Selection Perspective: Parameter tuning in non-monotone CRC reframes as a statistical model selection problem; the derived minimax rate is fundamental, not specific to any single selection rule.
- Methodological Guidance: Loss or risk monotonization is structurally conservative or only asymptotically valid; direct finite-sample corrections as in CRC-NM yield adaptive and reliable calibration with interpretably quantified excess risk.
- Scalability: Since excess risk increases only logarithmically with grid size, substantial flexibility exists for grid design, especially as sample sizes increase.
- Extension to Distribution Shift: The method is robust to moderate covariate shift, leveraging importance-weighted CRC.
Conclusion
This work establishes that conformal risk control can ensure rigorous expectation-level risk bounds when the loss is non-monotonic and the parameter grid is finite. The minimax lower bounds and explicit excess risk corrections quantify both the opportunity and limitation of non-monotonic CRC compared to monotonic settings. These findings have direct implications for deployment of risk-controlling sets in vision, medicine, and any high-valued domains employing discrete or thresholded policies, paving the way for further research into continuous parameter settings and heavy-tailed losses (2604.01502).

