- The paper introduces a novel superpatch-based MAE architecture for 3D CT imaging that significantly reduces computational cost while retaining anatomical context.
- It employs a dual-masking transformer block (MATB) achieving high reconstruction fidelity (PSNR 27.75 dB) and robust downstream classification (AUROC 0.9633).
- The model demonstrates label efficiency by reaching competitive performance with only 10% of labeled data, underscoring its practical value in medical imaging.
NEMESIS: Noise-Suppressed Efficient MAE with Enhanced Superpatch Integration Strategy
Introduction and Motivation
This work introduces NEMESIS, a self-supervised learning (SSL) framework for volumetric Computed Tomography (CT) that targets the principal bottlenecks of 3D medical image pretraining: the computational cost of full-volume transformers and the inability of traditional masking schemes to cope with the pronounced anisotropy of CT data. Contemporary paradigms such as SuPreM and VoCo, while advancing the field, fail to jointly address these obstacles. NEMESIS proposes a superpatch-based masked autoencoder (MAE) pipeline, combined with anatomical inductive biases via specialized transformer modules, yielding superior downstream and computational properties.
Architecture Overview
The fundamental innovation of NEMESIS is the superpatch-based MAE, which divides the input CT volume into local 1283 superpatches, feeding them through a cascade of custom modules for efficient and noise-resilient representation learning.
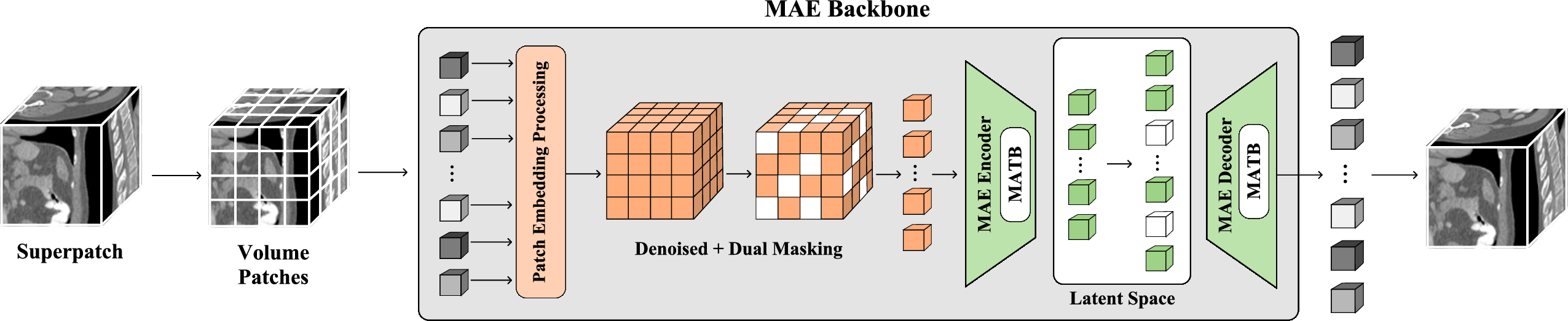
Figure 1: The overall architecture of the NEMESIS backbone, employing superpatch extraction, patch embedding, dual-masking, and MATB-based encoder-decoder modules for anatomical feature learning.
To ensure computational tractability and maintain context granularity, the algorithm first extracts non-overlapping superpatches, then further subdivides them into standardized 163 subpatches. This strategy, visualized in the pretraining pipeline, underlies both the memory efficiency and the discriminative prowess of the representations.
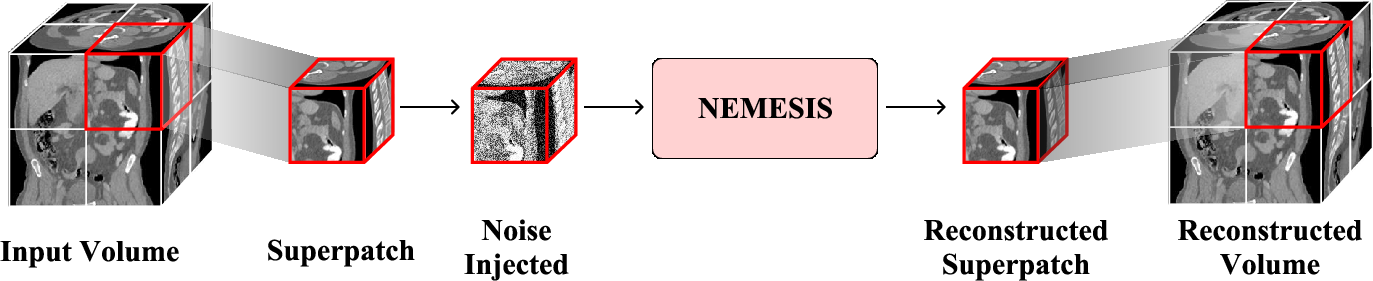
Figure 2: The superpatch-based pretraining pipeline. Random 1283 superpatches are sampled and processed independently to maximize memory efficiency and capture anatomical variety.
Patch embedding leverages a dual-pathway module that fuses linear-projected features with context-enriched representations, gated by a learnable parameter α. The contextual pathway is augmented with NEMESIS Tokens (NT), which serve as learnable anchors for enhanced cross-patch aggregation.
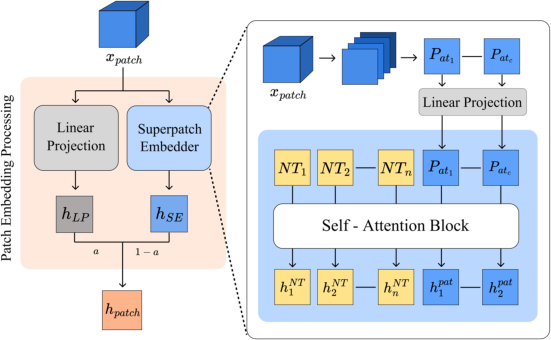
Figure 3: Architecture of the 3D Adaptive Patch Embedding module, integrating a linear projection and a superpatch-embedder with NEMESIS Tokens.
The Masked Anatomical Transformer Block (MATB) constitutes the core architectural novelty. It introduces dual-masking at both plane-wise and axis-wise levels, allowing parallel attention streams to jointly capture intra-patch and inter-patch dependencies that reflect the natural anisotropy of CT data.
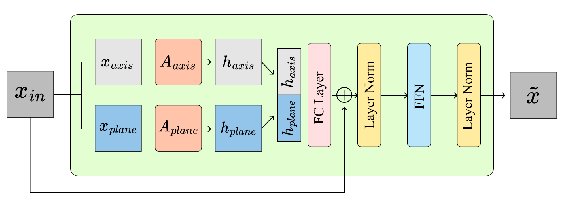
Figure 4: The MATB, featuring parallel axis-wise and plane-wise attention, fuses anatomical context across 3D dimensions.
Training Paradigm
NEMESIS employs a masked reconstruction pretext task with Gaussian noise augmentation for robust SSL. During each iteration, the model reconstructs clean superpatches from masked and noise-corrupted inputs, optimizing the mean squared error over hidden regions. This design enforces the learning of high-level anatomical abstractions that generalize across labeling policies and anatomical variances.
Experimental Results
Downstream Organ-Presence Classification
Evaluation is conducted on the BTCV multi-organ classification benchmark. The NEMESIS backbone, frozen and followed by a linear probe, achieves AUROC 0.9633 and macro F1 of 0.753, outperforming the fully fine-tuned SuPreM (AUROC 0.9493, F1 0.678) and VoCo (AUROC 0.9387, F1 0.701) backbones. Notably, fine-tuned NEMESIS surpasses the strong supervised ResNet3D-50 baseline (AUROC 0.9702 vs. 0.9720, F1 0.791 vs. 0.782), verifying that the representations learned via superpatch MAE with MATB are both robust and superior even for downstream supervised adaptation.
Label Efficiency
NEMESIS demonstrates marked label efficiency; with only 10% of labels, the frozen backbone with a linear probe achieves an AUROC of 0.9075, a margin that approaches full-supervision performance for competing methods. This is a direct consequence of the superpatch and dual-masking strategies, which enable global and local context integration even with minimal annotation.
Computational Advantages
A critical motivation for NEMESIS is the drastic reduction in computational complexity. The superpatch regime reduces GFLOPs per forward pass from 985.8 (full-volume VAE) to 31.0, corresponding to a 32× improvement without loss of reconstruction quality (PSNR 27.75 dB).
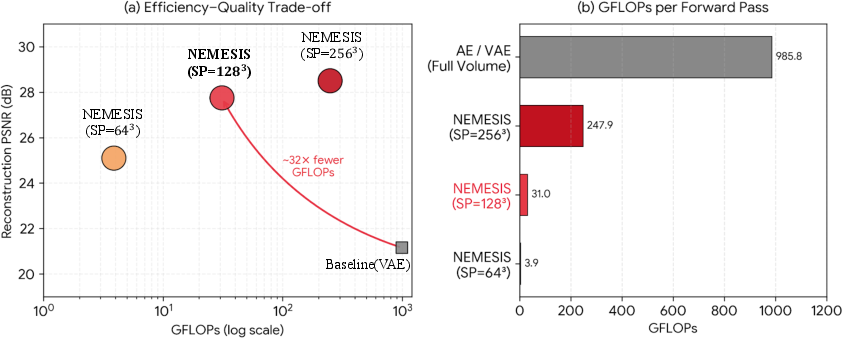
Figure 5: NEMESIS achieves a 32× reduction in GFLOPs relative to a VAE baseline, maintaining high reconstruction fidelity.
Ablations and Hyperparameter Sensitivity
Ablation studies confirm that the MATB's plane-wise attention dominates axis-wise schemes (PSNR increase from 24.87 to 27.75 dB), reflecting the anatomical organization within CT data. Optimal results are attained with a masking ratio of 0.75 and an embedding dimension of 768.
Theoretical and Practical Implications
By integrating dual-masking via MATB and aggregating context with NEMESIS Tokens, the proposed architecture internalizes spatial dependencies inherent to 3D anatomical imaging. This induces a strong inductive bias tailored to medical data, in contrast to isotropic or 2D-centric approaches. In practice, NEMESIS establishes a scalable paradigm for 3D SSL, enabling high-throughput training with limited clinical labels and standard GPU memory. The label-efficient regime is especially pertinent in real-world settings where annotation costs dominate.
On a theoretical front, the MATB demonstrates how explicit modeling of spatial anisotropy in transformers can enhance volumetric SSL. This opens several lines for subsequent work, including transferability to non-abdominal CT domains, interpretability analysis of dual-masking attention, and expansion to dense prediction tasks (segmentation).
Conclusion
NEMESIS advances the state of 3D medical SSL by introducing a memory- and annotation-efficient MAE framework featuring superpatch decomposition and dual-masked anatomical transformers. It achieves higher linear-probe and fine-tuned scores on BTCV organ classification than prior SOTA methods and supervised CNNs, all while offering substantial reductions in computational cost. The design principles—local superpatch processing, context-aggregating tokenization, and directionally-biased attention—constitute a robust foundation for future research in volumetric SSL and transformer-based anatomical modeling.