- The paper introduces a Mechanistic Perturbation Diagnostics framework that quantifies and localizes LLM failures caused by meaning-preserving perturbations.
- It shows that minor paraphrasing, especially in numerical formats, induces high flip rates and early divergence in logit behavior across various LLMs.
- Results categorize failures into localized, distributed, and entangled types, offering actionable insights for targeted repair and risk assessment.
Mechanistic Dissection of LLM Fragility to Meaning-Preserving Perturbations
Overview and Motivation
"Fragile Reasoning: A Mechanistic Analysis of LLM Sensitivity to Meaning-Preserving Perturbations" (2604.01639) presents a rigorous mechanistic study on the robustness of open-weight instruction-tuned LLMs—Mistral-7B, Llama-3-8B, and Qwen2.5-7B—on the GSM8K mathematical reasoning benchmark. The central premise is that high LLM accuracy on reasoning tasks can mask pronounced brittleness: surface-level, meaning-equivalent paraphrases (character name substitutions, numerical format changes) induce substantial answer variability, undermining claims of stable, generalizable reasoning.
The study introduces the Mechanistic Perturbation Diagnostics (MPD) framework, integrating logit lens analysis, activation patching, component ablation, and the Cascading Amplification Index (CAI). This pipeline not only quantifies failure rates, but localizes failure origins, dissects responsibility across network components, and formalizes mechanistic failure taxonomies with actionable predictive validity.
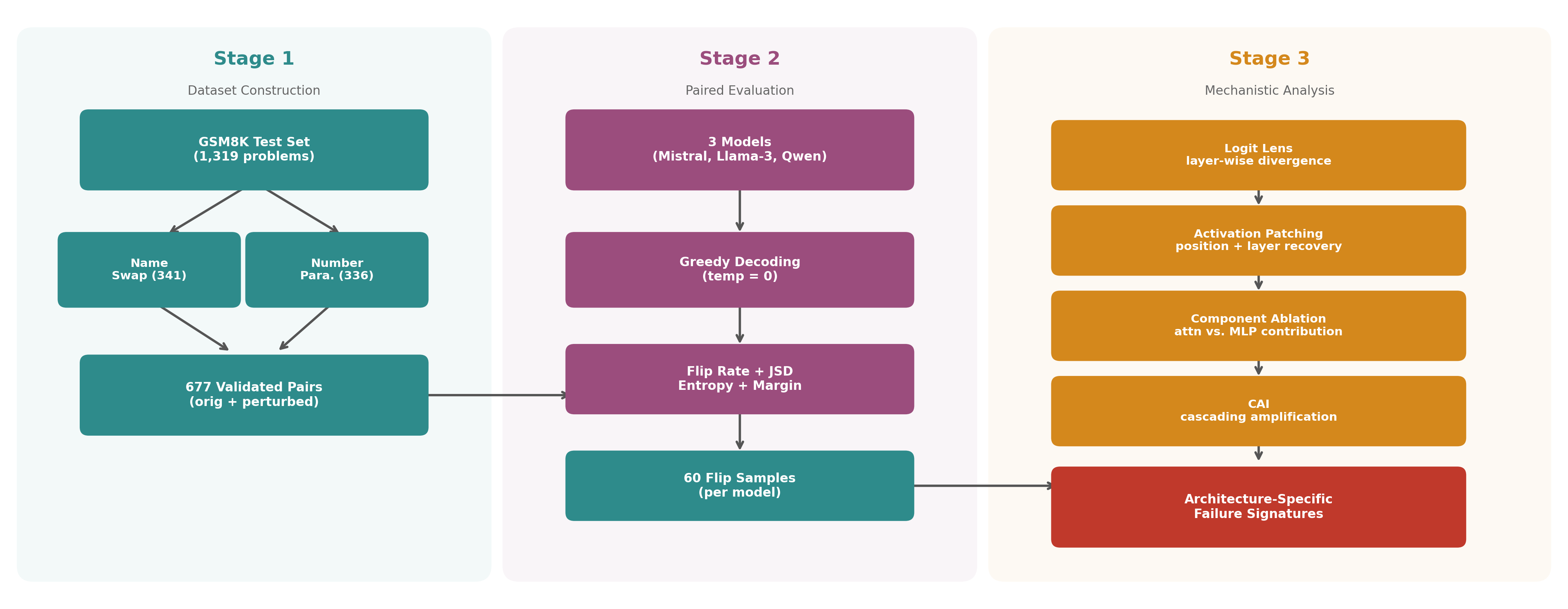
Figure 1: MPD framework overview, illustrating dataset construction, robustness evaluation, and mechanistic diagnostic steps.
Experimental Protocol
Dataset and Perturbation Construction
A curated dataset of 677 paired problems from GSM8K is constructed, each containing both the canonical instance and a meaning-preserving variant. Two perturbation classes are evaluated:
- Name substitution: Systematic replacement of all character names.
- Number format paraphrasing: Systematic restatement of numeric quantities (e.g., “$5”→“5 dollars”).
Both procedures are strictly controlled to avoid ambiguity or semantic drift.
Model Evaluation
Inference is conducted via greedy decoding with fixed output delimiters. “Flip” events are strictly defined as correct prediction on the original, incorrect on the perturbed form (not the reverse), ensuring unidirectional measurement of robustness decline.
Main Numerical Results
Empirical results underline pronounced fragility:
| Model |
Flip Rate (%) |
Name (%) |
Number (%) |
| Mistral-7B |
45.1 |
27.3 |
63.1 |
| Llama-3-8B |
33.5 |
23.5 |
43.8 |
| Qwen2.5-7B |
28.8 |
18.2 |
39.6 |
Number paraphrasing is consistently more disruptive than name substitutions, with Mistral-7B displaying the highest sensitivity.
Mechanistic Analysis
Logit Lens Divergence
Logit lens projections are used to identify the earliest layer at which model predictions diverge between original and perturbed variants. Flipped samples consistently manifest earlier divergence than stable ones (all $p < 0.05$):
- Mistral-7B: Flips diverge at layer 9.1 (vs. 11.6)
- Llama-3-8B: 13.0 (vs. 14.7)
- Qwen2.5-7B: 17.2 (vs. 19.5)
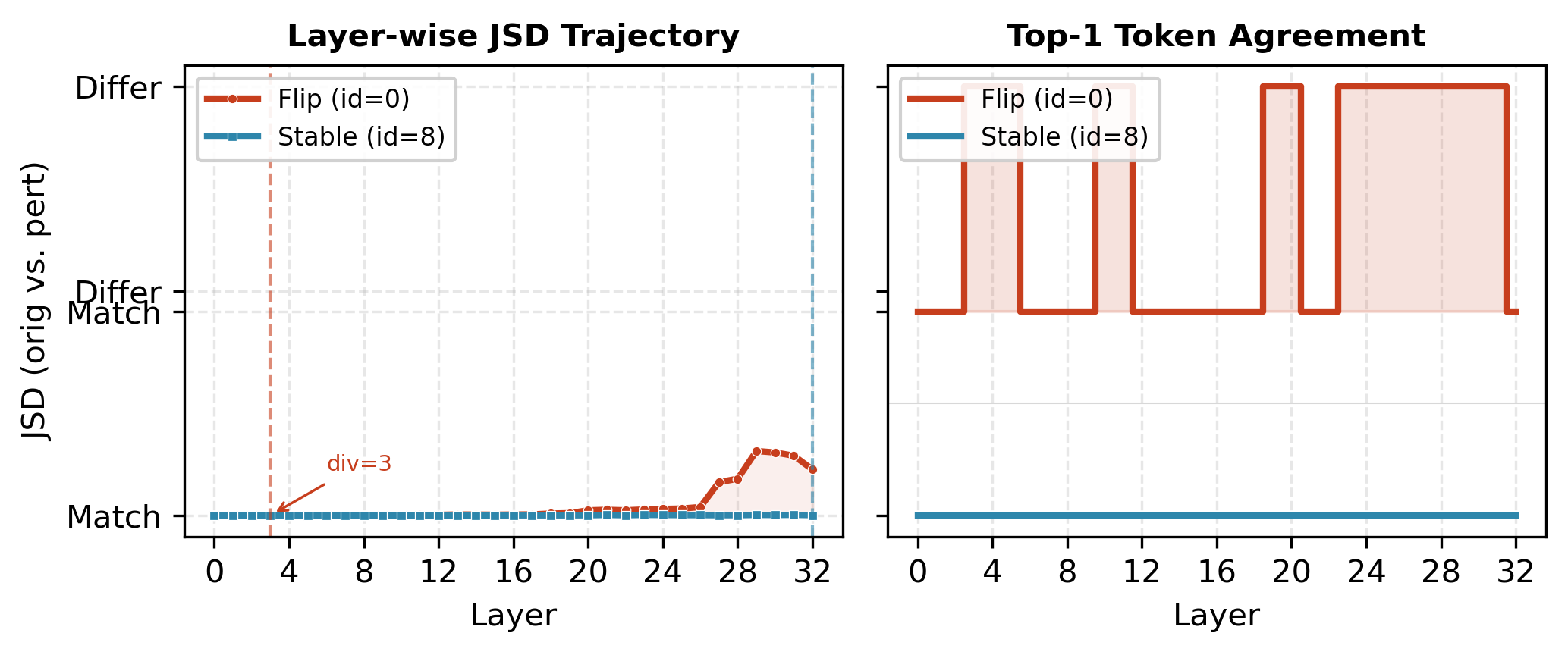
Figure 2: Logit lens on Mistral-7B; flipped sample shows early sharp JSD ascent, stable sample remains flat.
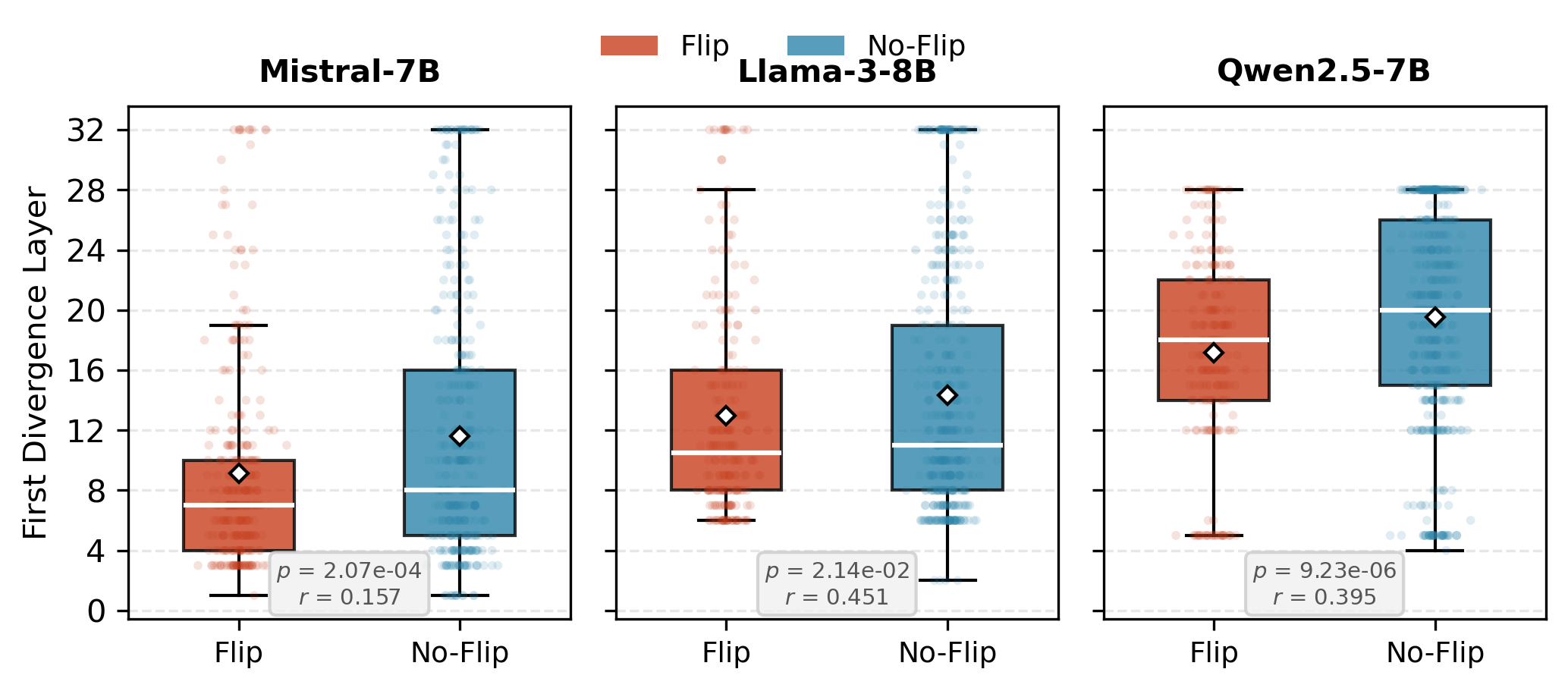
Figure 3: Distribution of first divergence layers confirms systematic early split for flipped samples.
Activation Patching
Activation patching quantifies the extent to which failures are localized and can be reversed by restoring hidden activations at specific positions/layers.
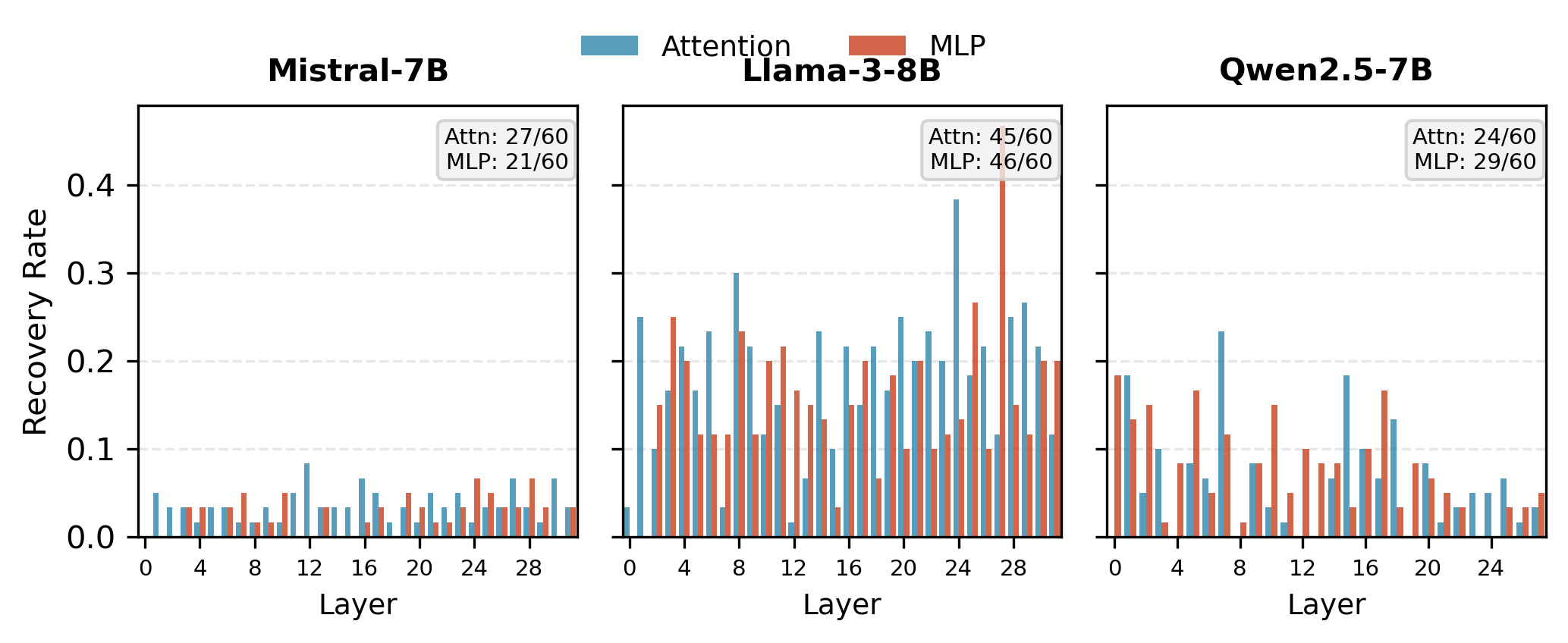
Component Ablation
Component ablation dissects causal contributions (attention vs. MLP sublayers):
Cascading Amplification Index (CAI)
CAI quantifies how local divergence amplifies (or attenuates) through the network. Flipped samples exhibit higher CAI across all models, with CAI outperforming first divergence layer as a predictor (AUC up to 0.679).
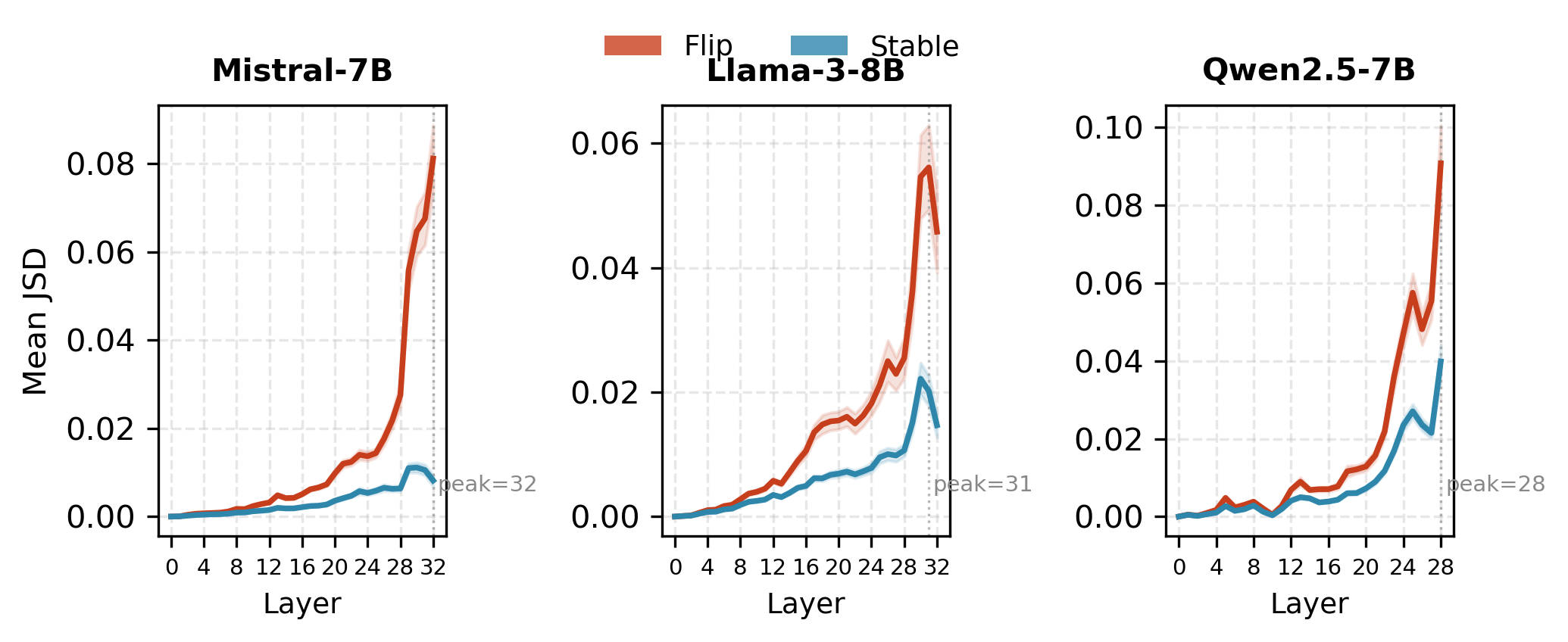
Figure 6: Flipped samples show monotonic divergence amplification through depth; stable samples show attenuation/self-correction.
Mechanistic Failure Taxonomy
The synergy of these analyses motivates a three-class mechanistic taxonomy:
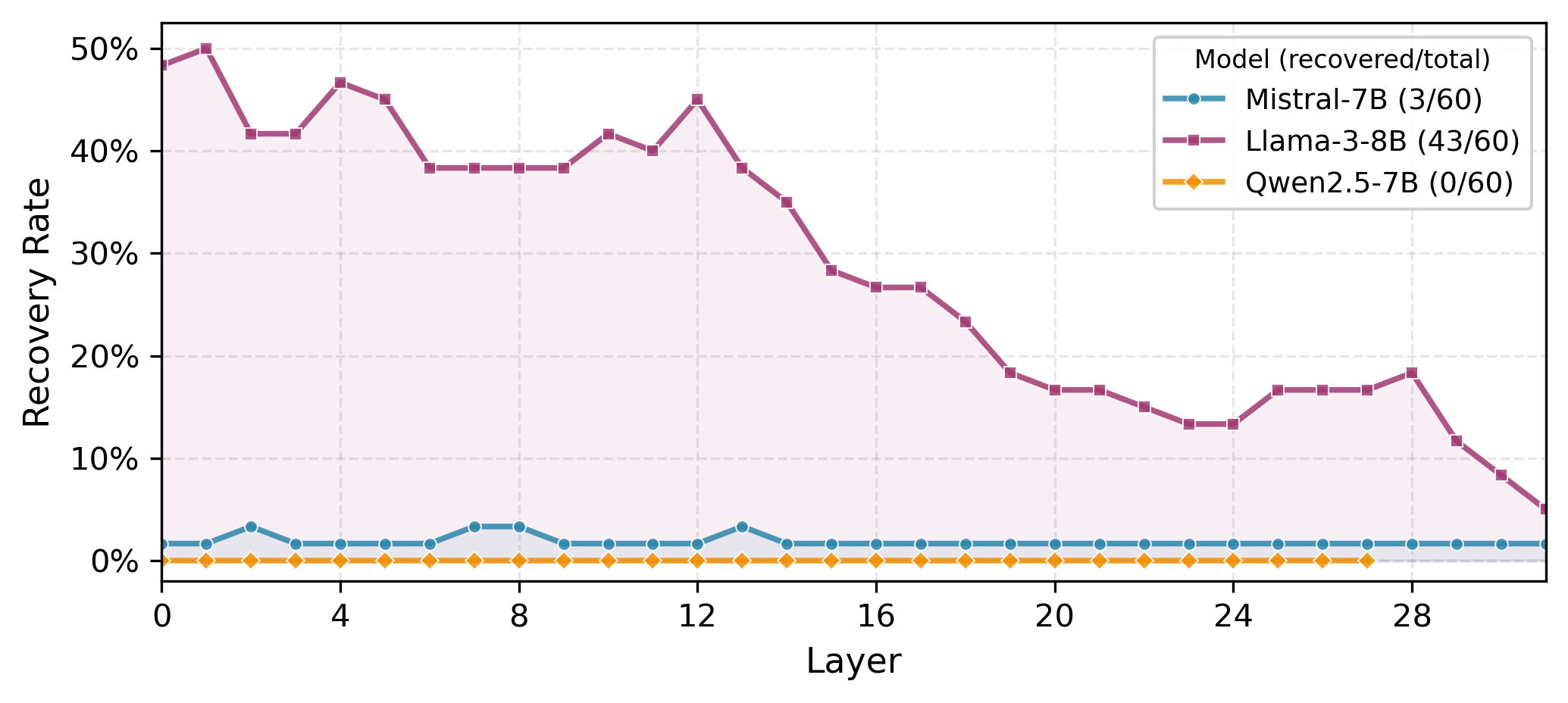
- Localized (Llama-3-8B): Moderate flip rate; failures recoverable with patching/fine-tuning concentrated at specific layers. Causal information bottlenecked.
- Distributed (Mistral-7B): High flip rate; failures propagate through redundant attention pathways with low patching/steering effectiveness.
- Entangled (Qwen2.5-7B): Low flip rate; failures entangled across layers and subcomponents, not recoverable by patching, with MLP dominance.
The taxonomy is validated by targeted repair experiments:
- Llama-3-8B: Layer fine-tuning or steering recovers 12.2% of localized failures.
- Qwen2.5-7B: Only 7.2% recovery attainable.
- Mistral-7B: Only 5.2% recovery.
ROME-style MLP editing (rank-one) for Qwen2.5-7B can induce regression, emphasizing the non-local nature of “entangled” failures.
Theoretical and Practical Implications
The findings demonstrate that LLMs’ apparent mathematical competence is highly brittle to surface form, and that failure phenomenology is not uniform but architecture-dependent. For model developers and interpretability researchers:
- Failures are generally not monolithic: LLMs “reason incorrectly” for fundamentally different mechanistic reasons.
- Localized errors enable effective targeted repair; distributed/entangled errors do not.
- CAI is a practical, model-agnostic diagnostic for triaging failure mode severity, outperforming naive first-divergence heuristics.
From a practical deployment perspective, these results call for caution before adopting LLMs for scenarios requiring invariance to phrasing, especially in math and safety-critical domains.
Future Directions
Key open research directions include:
- Scaling studies: Do these mechanistic taxonomies hold for 30B+ parameter models?
- Extensibility: How do these failure signatures manifest on other benchmarks (e.g., commonsense, legal, medical reasoning)?
- Intervention composition: Can recovery rates for distributed/entangled failures be improved via multi-layer or cross-component interventions?
- Generalization: Is failure taxonomy predictive of robustness under true out-of-distribution distributional shift?
Conclusion
This work delivers a comprehensive mechanistic framework for diagnosing LLM reasoning fragility under meaning-preserving perturbations. It reveals that high surface-level accuracy does not guarantee robustness to trivial rephrasings, outlines the architectural dependence of internal failure modes, and validates a taxonomy correlated with repairability. This pipeline provides actionable probing and repair tools for both model analysis and deployment risk assessment. The work sets a foundational standard for future robustness and interpretability studies in transformer LLMs.