- The paper demonstrates that VLMs suffer from a two-hop process where late entity extraction bypasses early factual recall circuits inherent in LLM backbones.
- It employs attribution and activation patching to reveal that adapter-based VLMs can experience up to 43.9% degradation, while native multimodal models largely preserve recall.
- The study implies that enhanced multimodal pretraining or architectural redesign is crucial for aligning visual and textual representations to improve factual retrieval.
Mechanistic Analysis of Factual Recall Failures in Vision-LLMs
Introduction
"Too Late to Recall: Explaining the Two-Hop Problem in Multimodal Knowledge Retrieval" (2512.03276) provides a comprehensive mechanistic investigation into why state-of-the-art Vision-LLMs (VLMs) exhibit degraded factual recall compared to their LLM backbones. Through a combination of large-scale empirical benchmarking and interpretability experiments—including attribution patching, activation patching, and linear probing—the authors characterize VLM factual recall as a "two-hop" process, diagnostic of a critical architectural misalignment: VLMs must first recognize entities from visual data, often only achieving robust entity representation in deeper layers, which causes early factual recall circuits established by LLM pretraining to be bypassed. The study systematically deconstructs this failure mode and verifies hypotheses across multiple VLM architectures and scales.
The Two-Hop Problem: Early Entity Resolution as a Bottleneck
Entity-based factual recall in VLMs is fundamentally a two-hop computation: (1) the VLM must resolve which entity is present in the visual input, then (2) retrieve and deploy the LLM's factual knowledge about that entity. In VLM architectures with Adapter-based or Cross-Attention integration, the first hop—entity identification—often occurs too late in the computational graph. As a result, the early-layer multi-layer perceptrons (MLPs) in the LLM backbone, which are causally important for factual recall, are not engaged with a token representation of the entity, impairing subsequent retrieval of associated knowledge. In contrast, textual LLMs are provided subject tokens directly, allowing them to leverage early circuits for knowledge retrieval.
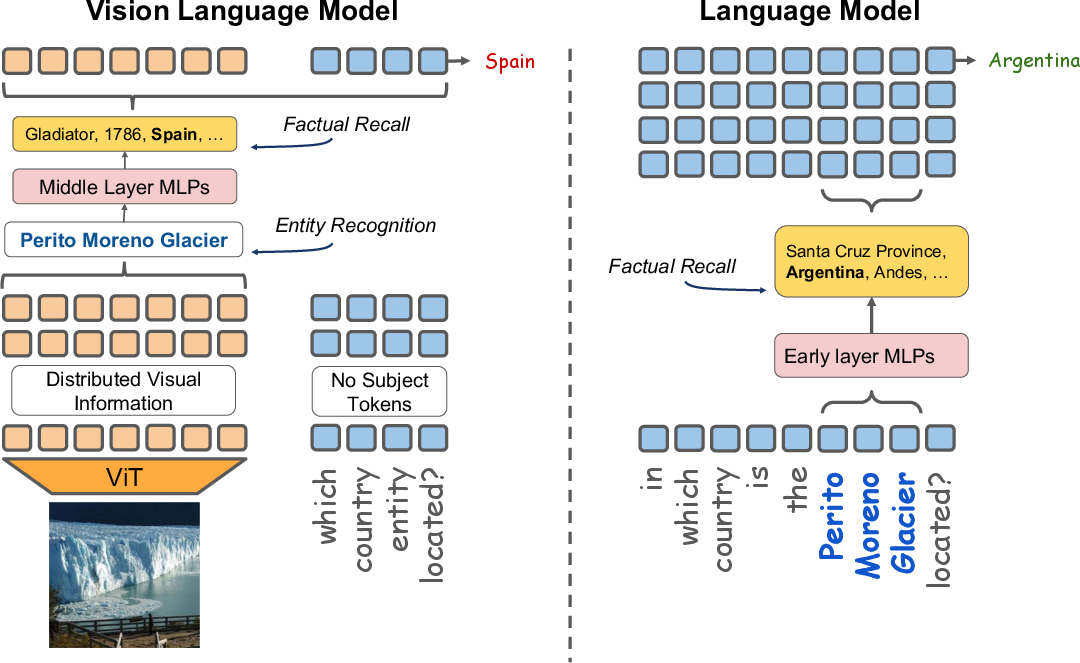
Figure 1: Illustration of the two-hop problem comparing VLM and LLM factual recall pathways.
The figure exemplifies this contrast: a VLM must first infer "Perito Moreno Glacier" from an image, with the entity representation materializing in late layers, bypassing early MLPs; whereas the LLM receives the entity textually, activating early factual recall mechanisms and yielding the correct answer.
Empirical Benchmarking of Factual Recall
The authors curate a rigorous factual recall benchmark—15,000 entity-centric multimodal questions with images sourced from WIT, question templates crafted for a controlled comparison, and careful filtering to exclude NER errors. Fourteen VLMs, spanning Adapter, Native, and Cross-Attention architectures and sizes from 7B to 124B parameters, are evaluated directly against their LLM backbones.
Key results:
- 11/14 VLMs show measurable factual recall degradation compared to their LLMs.
- Adapter-based models (e.g., LLaVA-1.5-7B: -36.7%, LLaVA-MORE-8B: -43.9%) perform dramatically worse on factual recall.
- Native VLMs—pretrained with multimodal objectives—preserve factual recall (Gemma-3-12B-it: 0.0% degradation, Gemini-2.0-Flash: -4.5%).
- Exception: Qwen2.5-VL-72B-it, extensively multimodal-trained, outperforms its backbone (+8.2%), supporting the hypothesis that sufficient multimodal pretraining can enable early alignment.
These findings invalidate a simple parameter-scaling mitigation: even very large Adapter-based models degrade, while modality-native or massively multimodal-finetuned models can retain or improve factual recall.
Mechanistic Attribution of Factual Knowledge Circuits
Attribution Patching: Quantifying Causal Relevance
Attribution patching unveils the subnetworks in LLMs and VLMs critical for factual recall by systematically corrupting input embeddings and analyzing the KL divergence of the output distributions with and without patching. Gradient × Delta is computed per (layer, branch), establishing where and how information about the entity propagates.
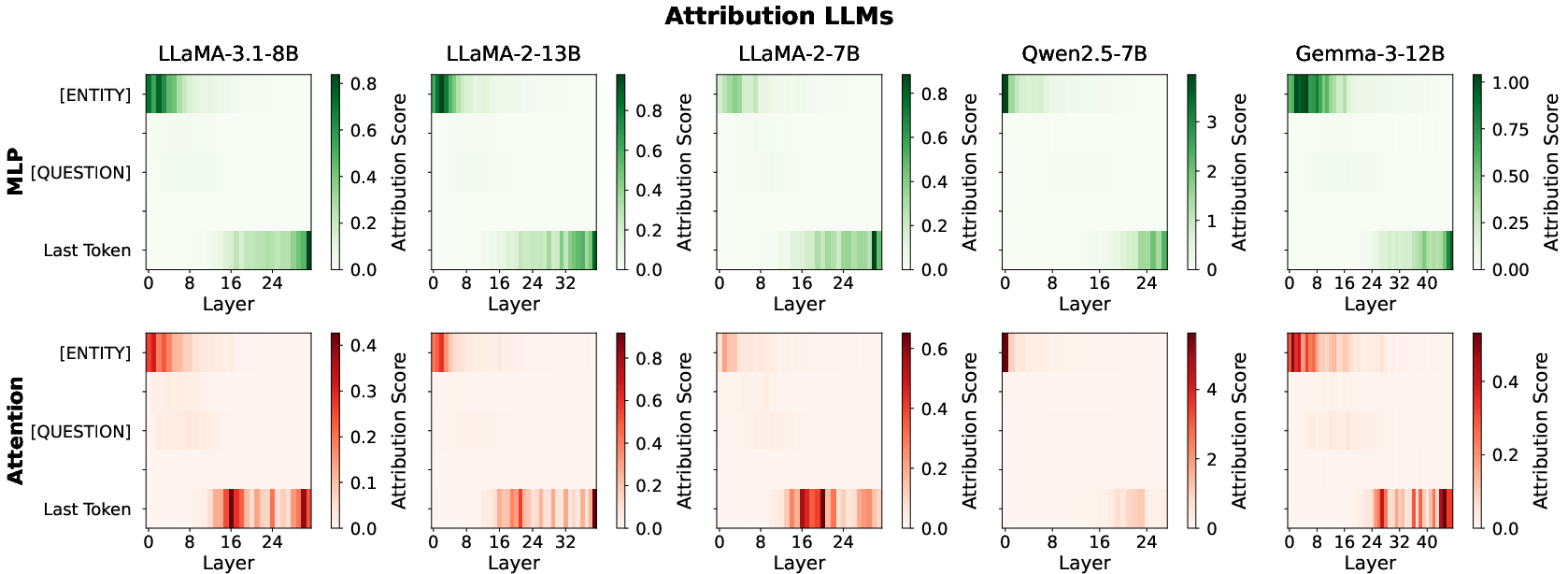
Figure 2: Causal attribution heatmap for MLP/Attention sublayers in LLM backbones; early-layer MLPs at entity-token positions dominate.
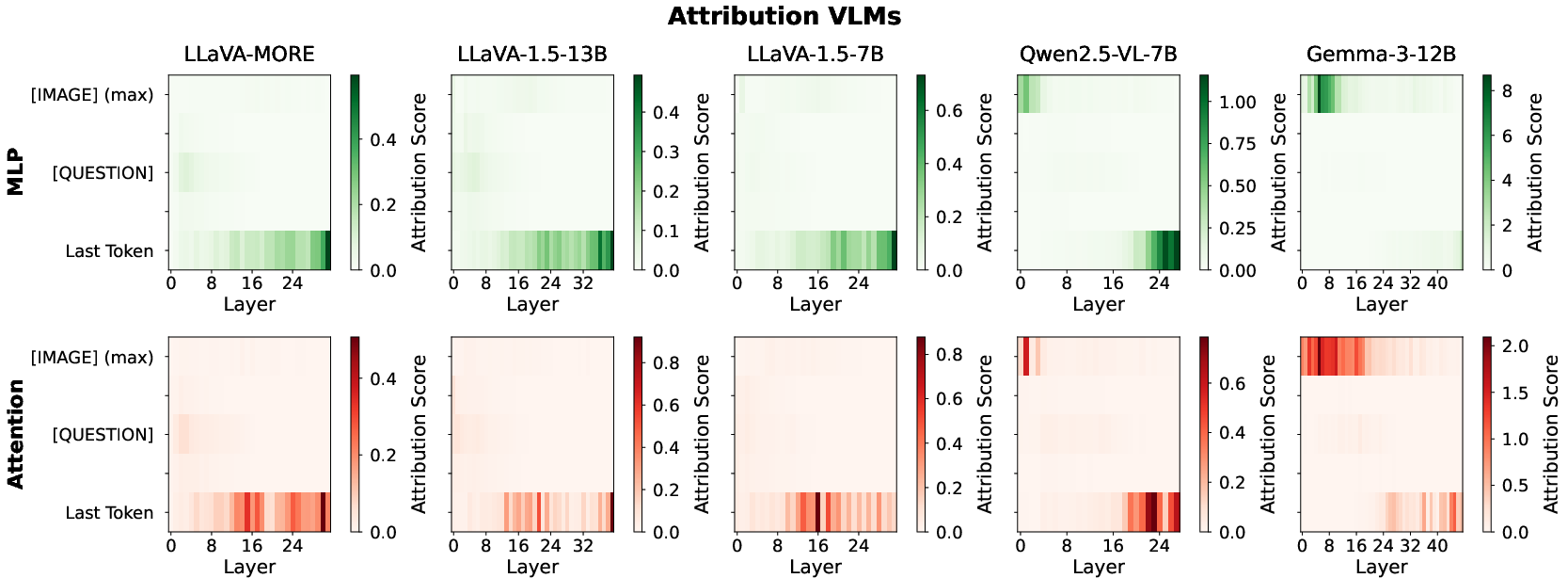
Figure 3: Attribution heatmap in VLMs; Adapter-based models shift causal reliance away from early MLPs, in contrast to LLMs.
Results demonstrate that in LLMs, early MLPs over entity-token positions are maximally causal for factual recall. By contrast, degraded Adapter-based VLMs lack attribution in these sublayers, instead activating only deeper sites, whereas Native VLMs (Gemma-3-12B, Qwen2.5-VL-7B) maintain the dual-site pattern, matching their LLM backbones.
Activation Patching: Restoring Degraded Factual Recall
The authors further execute activation patching, transplanting entity-token MLP outputs from the LLM into the VLM at early backbone layers. This directly tests whether bypassed early-layer circuits are sufficient for factual retrieval if correctly stimulated.
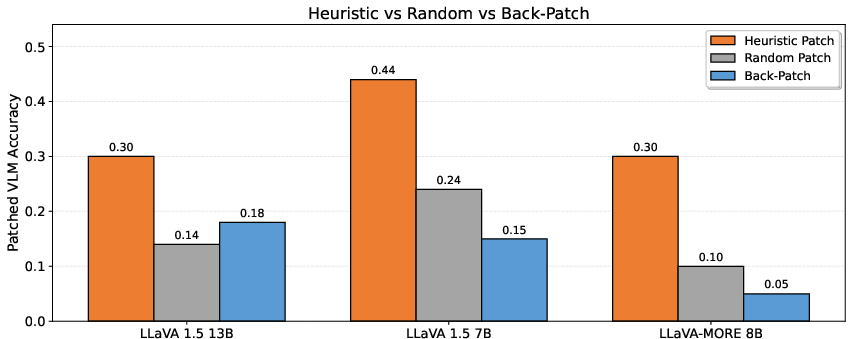
Figure 4: Performance recovery in LLaVA-derived VLMs via MLP activation patching; up to 35% of the factual gap closed.
Heuristic patching closes ~35% of the factual recall gap—substantially more than random or back-patching baselines—functionally validating the causal bottleneck at early MLP sites.
Representation Probing: Layerwise Emergence of Entity Knowledge
Layerwise linear probes are trained on residual streams to decode the entity class from representations at each transformer layer for five models. This identifies where in the backbone robust visual entity representations arise.
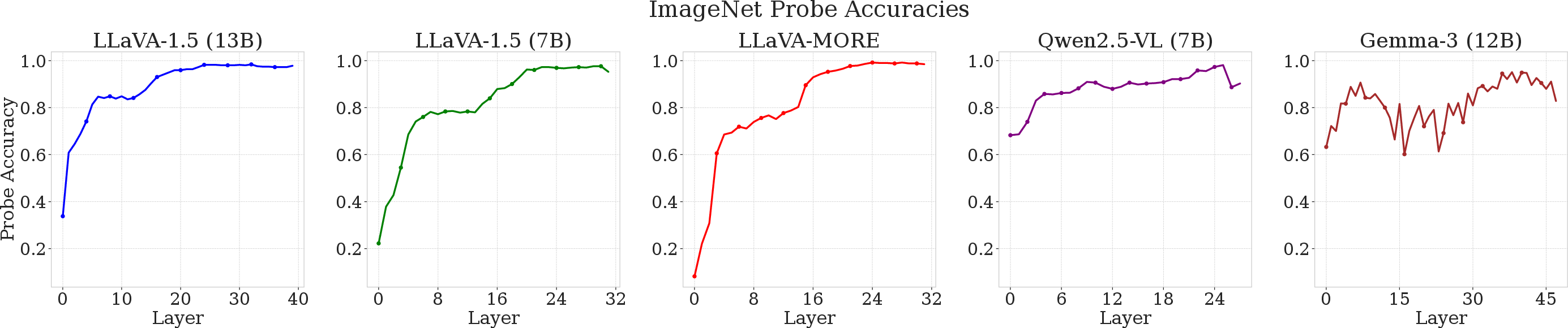
Figure 5: Linear probe accuracy for entity prediction as a function of backbone depth; delayed emergence in LLaVA-style models, immediate in Native and highly multimodal-finetuned models.
- LLaVA-style models only achieve high probe accuracy mid-to-late in the backbone, confirming late entity representation.
- Native (Gemma-3-12B) and Qwen2.5-VL-7B show high probe accuracy even in early layers, consistent with their preserved recall.
These results directly map empirical degradation to representational emergence, mechanistically substantiating the two-hop bottleneck.
Dataset Design and Validation
The benchmark's construction pipeline ensures that factual recall assessment is not confounded by recognition failures. Images are paired with entity names and question templates, and models must demonstrate successful entity recognition prior to factual evaluation.
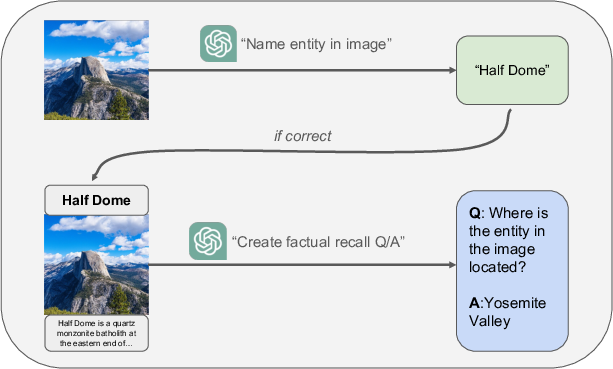
Figure 6: Dataset construction pipeline ensuring reliable, entity-anchored factual recall evaluation in a multimodal setting.
A case-study of filtered samples shows random error distribution, with no systematic bias.
Quantifying Projector Misalignment
The authors confirm prior findings that MLP-based visual projectors in Adapter-style VLMs produce output embeddings nearly orthogonal to token embeddings in the backbone LLM.
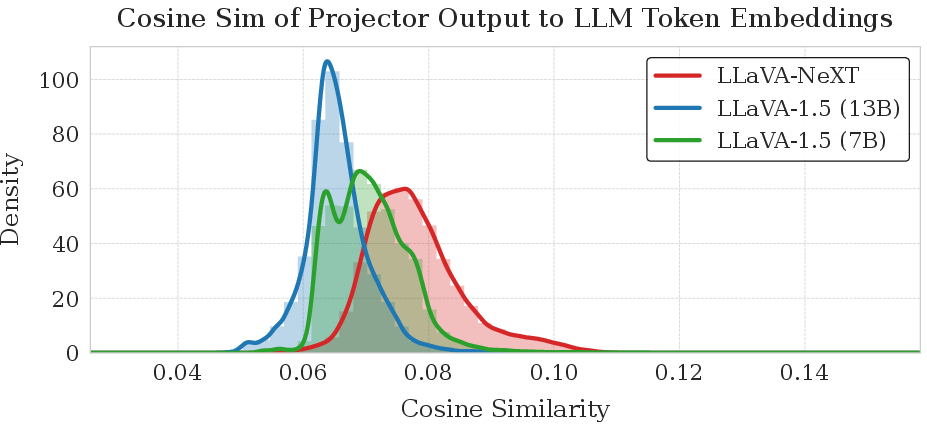
Figure 7: Distribution of cosine similarity between visual projector outputs and LLM token embeddings; peaked at near-zero, indicating strong misalignment.
This represents a fundamental architectural disconnect, explaining why Adapter-projected visual information cannot stimulate early factual recall circuits.
Prompt-Based Mitigation: Chain-of-Thought Reasoning
Chain-of-thought (CoT) prompting is evaluated as an inference-time mitigation. By instructing models to reason via an intermediate textual step describing the image, VLMs are induced to produce entity-token representations, thereby enabling factual knowledge retrieval circuits in the LLM backbone.
- CoT prompting yields model-dependent gains, closing up to the full factual recall gap in Pixtral-12B, Pixtral-Large-124B (Adapter), and Gemini-2.0-Flash (Native).
- In some VLMs, notably robust ones, CoT eliminates residual factual recall deficits entirely.
Implications and Future Directions
These results underscore that successful multimodal alignment is not simply about representational compatibility or brute-force scaling, but about integrating visual representations into the functional circuits established by LLM pretraining. The observed failure mode is not remediable by generic fine-tuning; it requires structural solutions that deliver early, entity-level alignment between modalities.
Practical Implications
- Adapter-based plug-and-play VLMs without sufficient multimodal pretraining are fundamentally limited in factual grounding; this impacts their trustworthiness in sensitive real-world settings.
- Chain-of-thought prompting is a partial, inference-time fix but is inefficient and unreliable across the board.
Theoretical Perspective
- The study situates VLM mechanistic analysis within the broader literature on multi-hop reasoning and factual recall in LLMs, extending insights from unimodal circuits to the multimodal case.
- Future research should focus on data-efficient adapter designs and multimodal pretraining strategies that induce early token-space alignment, or fundamentally new architectures.
Conclusion
This work provides a mechanistic diagnosis and causal evidence for factual recall degradation in most vision-LLMs, tracing the issue to late emergence of robust entity representations and bypassed factual circuits in the backbone. Only VLMs with native multimodal training or extremely extensive multimodal fine-tuning escape this bottleneck. Systematic interpretability, intervention experiments, and layerwise probing together delineate a clear research agenda for improving reliable multimodal knowledge retrieval, with implications for the design of the next generation of VLM architectures and benchmarks.