- The paper demonstrates a novel bidirectional cycle-consistent training framework that enhances motion fidelity and temporal reversibility in video frame interpolation.
- It employs learnable directional tokens and curriculum learning to capture both short- and long-range temporal dependencies while enforcing cycle consistency.
- Empirical evaluations reveal state-of-the-art imaging quality and reduced motion drift, achieving these improvements with no additional inference latency.
Bidirectional Cycle-Consistent Training for Reversible Video Frame Interpolation
Introduction
The paper "Can Video Diffusion Models Predict Past Frames? Bidirectional Cycle Consistency for Reversible Interpolation" (2604.01700) addresses a fundamental limitation in current video diffusion models for frame interpolation: the lack of explicit temporal consistency, particularly reversibility under time inversion. Existing approaches, mainly based on unidirectional generative modeling, often lead to ambiguous or incoherent motion, especially for long-range interpolation tasks. The authors propose a bidirectional training framework with learnable directional conditioning, enforcing cycle-consistent supervision to regularize the learned motion manifold. This paradigm yields significant improvements in motion fidelity, temporal coherence, and inference efficiency for both short and long video sequences.
Theoretical Framework and Methodology
The central hypothesis is that physically plausible video generation should be reversible: a model capable of generating I1→IL should, with reversed endpoints, generate a temporally coherent IL→I1. The framework builds on a pre-trained long-video generative architecture based on Rectified Flow (e.g., FramePack or WAN2.1-Fun), and introduces the following components:
- Directional Conditioning via Tokens: The model appends a learnable directional token (forward/backward) to the text prompt embedding. This enables a unified backbone to condition on temporal orientation, unlike previous works requiring separate models or adapters.
- Cycle Consistent Training Objective: For each ground-truth video, both a forward and backward sample are constructed, and the model is jointly supervised to minimize reconstruction errors in both latent and pixel domains for both directions.
- Curriculum Learning for Temporal Horizons: Training initiates with short (37-frame) videos to stabilize short-range dynamics, progressively escalating to longer (73-frame) sequences to capture extended temporal dependencies. The cyclic constraints are only enforced during training—at inference, a single forward pass suffices.
This bidirectional design directly regularizes the learned velocity field, constraining the dynamics to a symmetric, invertible manifold. Consequently, trivial, low-dynamic or temporally drifting solutions are penalized.
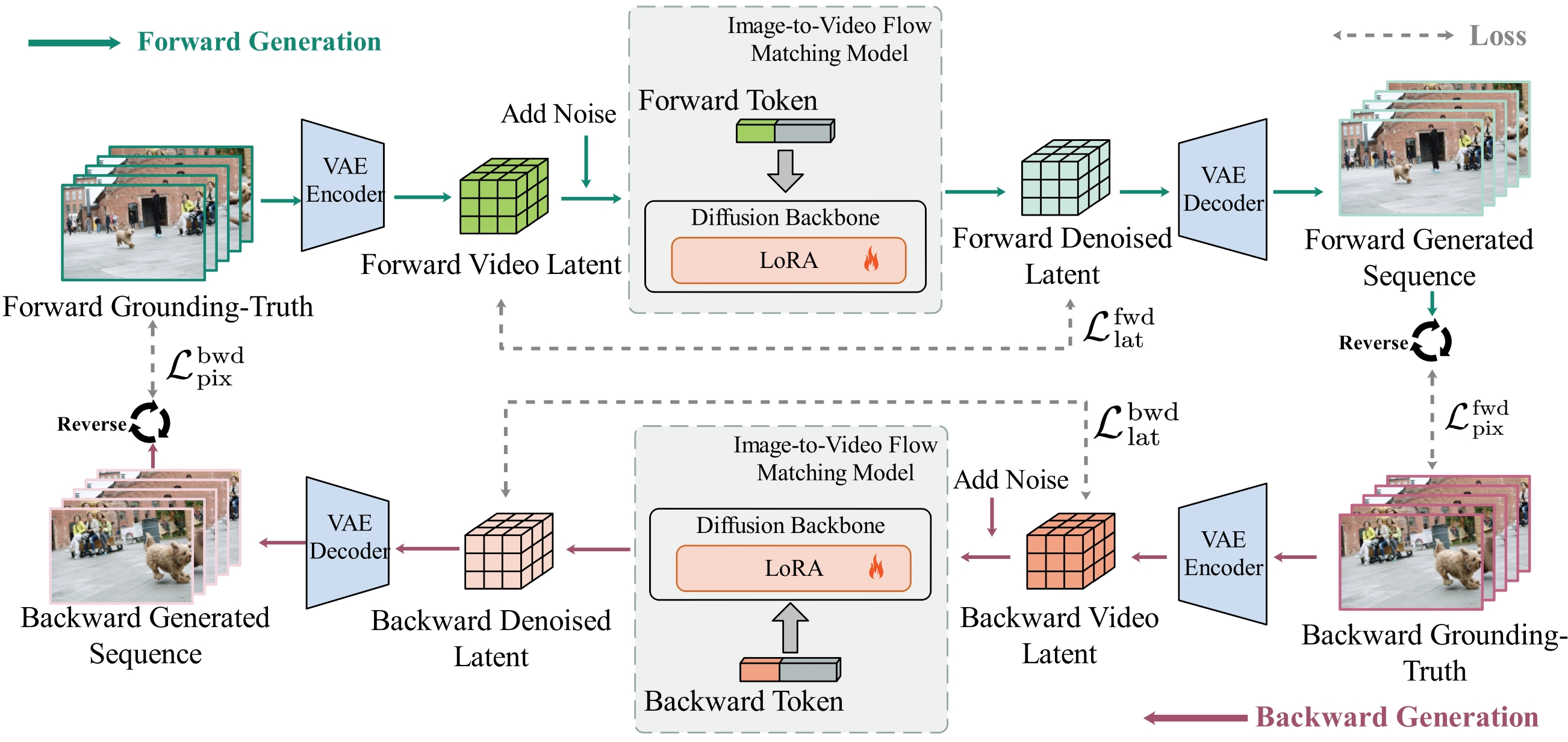
Figure 1: Schematic of bidirectional cycle-consistent framework, showing dual-direction interpolation setup with shared backbone and directional token conditioning.
Empirical Validation and Comparative Analysis
Quantitative Evaluation
Extensive benchmarking is performed on the VidGen-1M dataset with VBench and FVD metrics, on both 37-frame and 73-frame sequences. The proposed approach is compared with GI [generativeInbetweening], Wan2.1-Fun [wan], SFI [sfi], and FramePack [framepacking] baselines. Two instantiations are evaluated:
- Wan+Ours: Directional cycle-consistent training atop WAN2.1-Fun (1.3B params)
- FP+Ours: Directional cycle-consistent training atop FramePack (13B params)
In both short and long sequence regimes, the bidirectional models consistently outperform their respective backbones in imaging quality, motion smoothness, and flicker reduction, with state-of-the-art FVD and VBench scores. Notably, these improvements are achieved with no additional inference latency, unlike many time-reversal or refinement-based methods.
Qualitative Analysis
The qualitative differences are pronounced. Baseline models, especially under long-sequence generation, frequently exhibit motion drift, abrupt state transitions, or collapse to static frames. In contrast, the proposed bidirectional models generate fluid, reversible, and physically coherent trajectories, preserving boundary correspondence and controlling motion velocity. The model’s ability to generate authentic backward motion, rather than simply “flipping” direction, is demonstrated clearly.
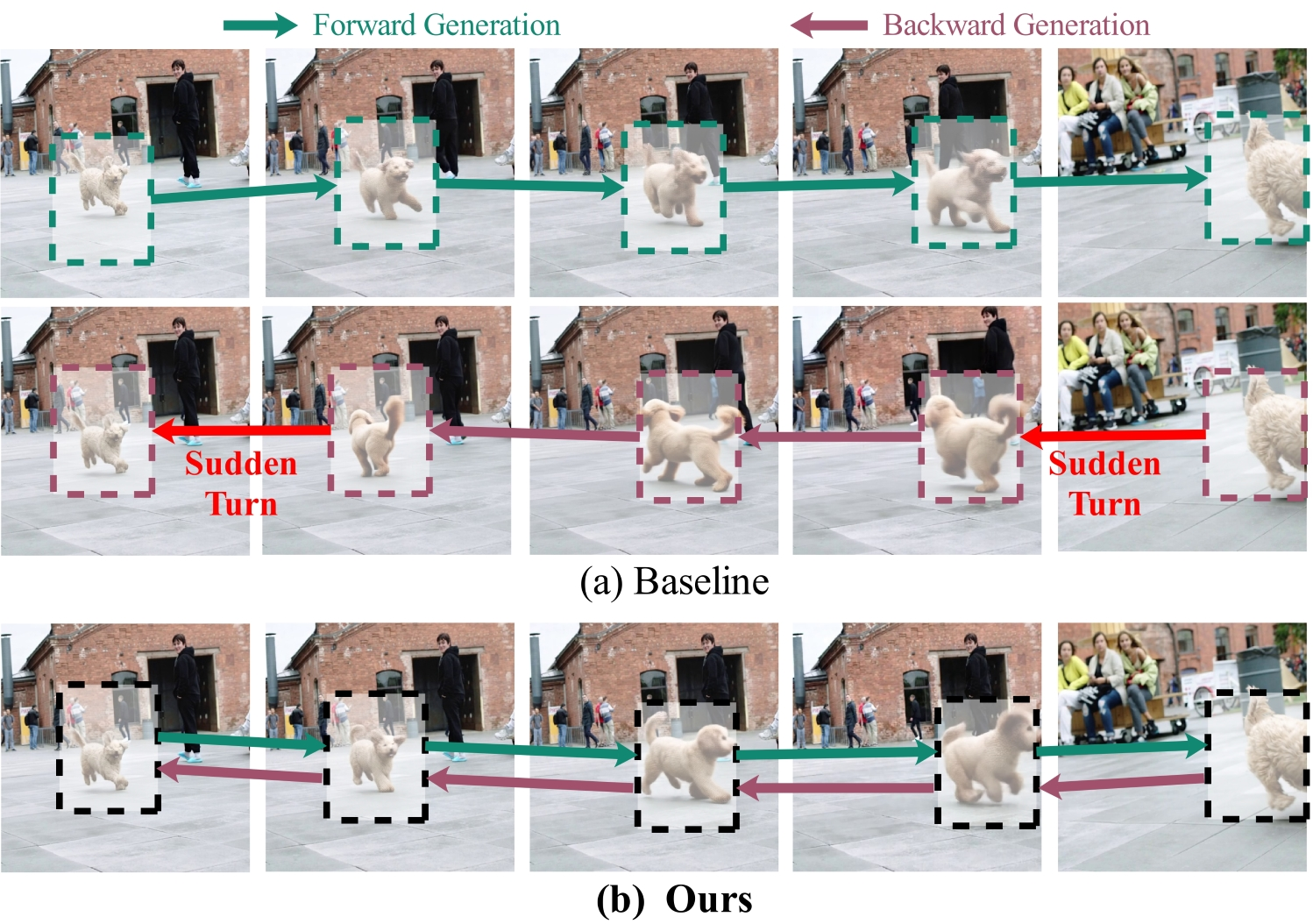
Figure 2: Forward vs. backward interpolation. Baseline fails to generate motion-reversed sequence; proposed method closes the temporal loop with true reverse dynamics.

Figure 3: Visual comparison—bidirectional model sustains smooth, coherent dynamics in both short (37f) and long (73f) sequences, correcting drift and motion artifacts in baselines.
Efficiency-Quality Tradeoff
Unlike past approaches that increase computation for each additional constraint, the unified token-based backbone adds no inference overhead. It achieves Pareto-superior quality–efficiency tradeoff compared to competitive baselines.
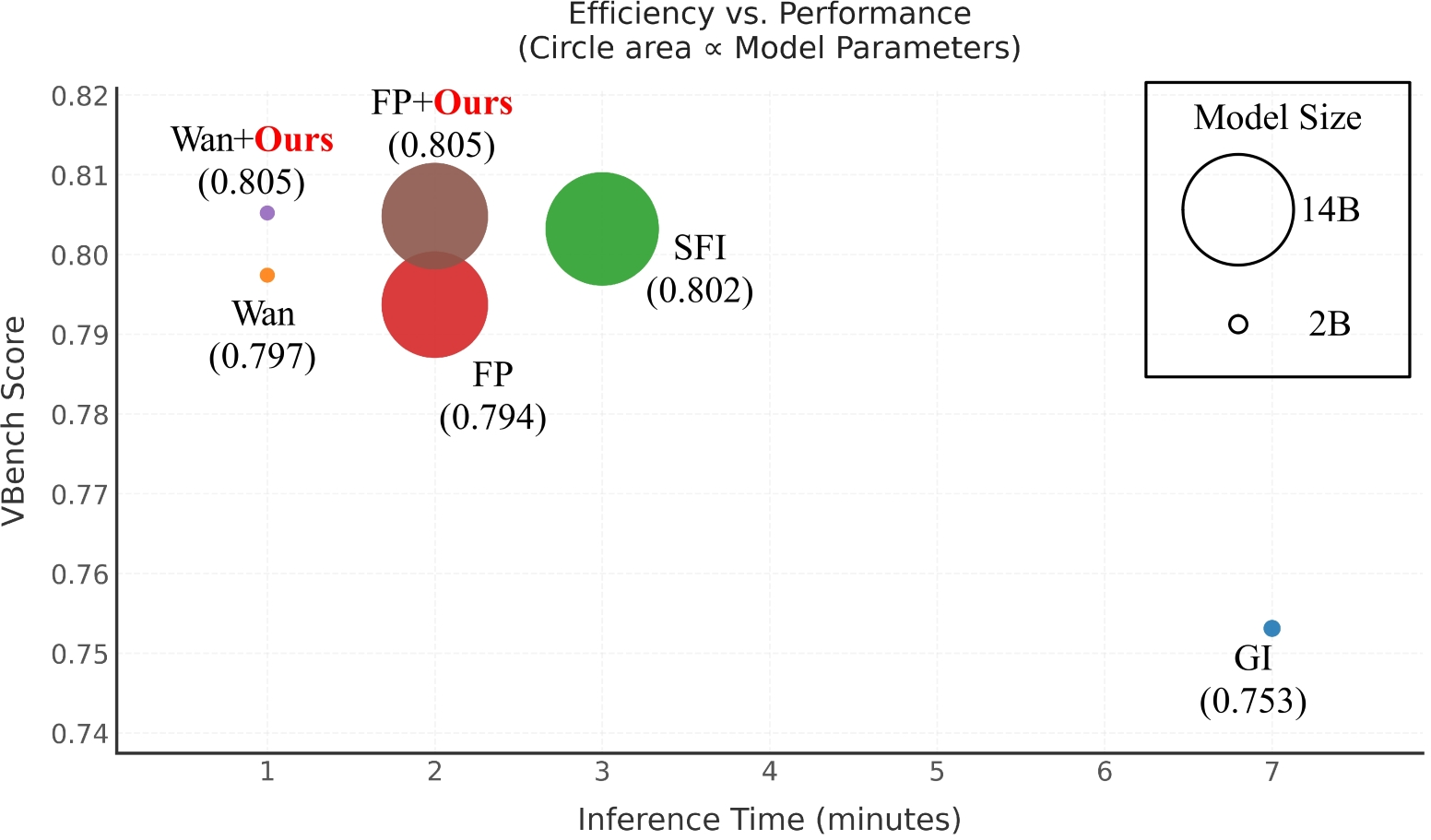
Figure 4: Inference speed vs. average VBench quality; bidirectional models match baseline compute but consistently dominate in overall score.
Ablation Studies
Component ablations reveal:
- Without reverse training: Drastic reduction in dynamic degree, systematic collapse to low-motion or static outputs.
- Without directional tokens: Temporal orientation ambiguity leads to local oscillations, dynamic attenuation.
- Mixed-length, non-curriculum training: Model fails to reconcile short- and long-horizon dynamics, reducing temporal coherence.
Only the full curriculum with bidirectional and token conditioning enables robust, high-dynamic motion generation.

Figure 5: Ablation—full model displays temporally smooth transition and dynamic realism; removal of cycle consistency or directionality causes abrupt or degenerate trajectories.
Practical and Theoretical Implications
The introduction of cycle-consistent bidirectional supervision provides a powerful self-regularization prior for sequence prediction in deep video diffusion models. This paradigm not only improves traceable controllability—enabling reversible and interpretable motion—but also fundamentally penalizes the drift and collapse issues endemic to unidirectional, long-horizon generative models.
On a practical level, the method scales efficiently to long video contexts, adapts to a variety of backbone architectures, and is agnostic to input prompt modality (e.g., text-guided scenarios). The approach directly supports applications requiring temporally robust and editable video synthesis: cinematic retiming, scientific motion analysis, interactive generative content, and more.
Theoretically, the enforced reversibility augments models with inductive biases matching physical symmetry constraints, opening avenues for further incorporation of explicit geometric or physical priors. Potential limitations exist when natural video exhibits irreversible processes; strict cycle constraints in these regimes may induce excessive smoothing or bias.
Future Directions
The integration of explicit geometric constraints or learned physical priors (beyond temporal symmetry) is a logical progression, particularly for domains such as stochastic video, inelastic deformation, or non-rigid dynamics. Extensions to higher frame-rate, variable-length, or multi-modal conditioning represent attractive directions. Finally, connecting bidirectional cycle-consistency with formal invertibility in conditional generative models is a significant open problem.
Conclusion
This work establishes that bidirectional cycle consistency, implemented via directional prompting and joint forward-backward supervision, provides substantial improvements in long-range video frame interpolation within diffusion frameworks. Cycle-consistent training yields state-of-the-art results in imaging quality and dynamic controllability across sequence lengths, with zero inference overhead. The framework is complementary to existing backbones and sets a paradigm for future research on temporally symmetric, physically faithful generative video models.