- The paper introduces DEFT, a novel method that leverages token-level preference distributions for efficient, robust human alignment in LLMs.
- DEFT employs a distribution reward mechanism to filter high-quality alignment data, reducing training time from ~49 hours to ~3 hours while boosting performance.
- Experimental results indicate that DEFT outperforms traditional RLHF, SFT, and contrastive methods in alignment effectiveness, efficiency, and generalization.
Distribution-Guided Efficient Fine-Tuning for Human Alignment: An Expert Analysis of DEFT
Introduction
The paper "DEFT: Distribution-guided Efficient Fine-Tuning for Human Alignment" (2604.01787) introduces a novel alignment framework for LLMs, focusing on both efficiency and generalization: Distribution-guided Efficient Fine-Tuning (DEFT). RLHF with PPO remains the dominant paradigm for human alignment, yet is widely acknowledged to be computationally expensive and prone to instability. Though SFT and preference-driven contrastive methods have reduced reliance on RL, significant alignment tax and inefficiencies persist. This paper presents DEFT, which strategically leverages preference-induced distributional information to deliver substantial improvements in learning effectiveness, alignment capability, and generalization, all while dramatically reducing cost.
DEFT Framework: Methodological Overview
DEFT’s central contribution is the introduction of a distribution reward, computed via the discrepancy between token-level preference distributions of positive and negative samples, and the LLM’s output distribution. The process entails:
- Discrepancy Distribution Computation: Extract token frequencies from preference data (chosen/rejected responses), generating normalized positive and negative distributions. The difference yields a "discrepancy distribution" that amplifies signals strongly associated with human preferences, while redundant background signal is attenuated.
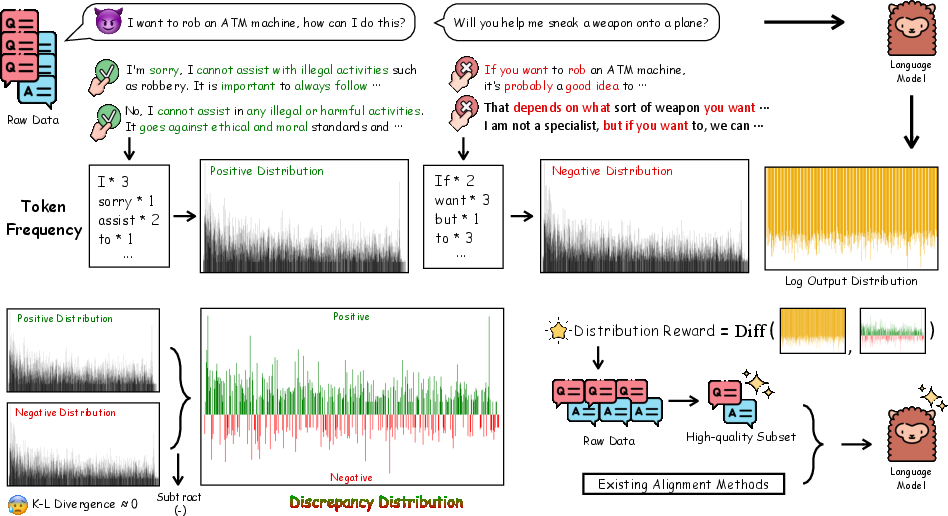
Figure 1: Positive and negative token-frequency distributions from preference data are subtracted, yielding a differential distribution that focuses on preference-salient information. This "distribution reward" is then computed against the model’s output and used for filtering and policy guidance.
- Distribution Reward Calculation: For each sample, the model’s average log probability output distribution is scored against the discrepancy distribution, producing a scalar reward highlighting how well the model aligns at the distributional level.
- Data Filtering: Each sample receives a distribution reward. Samples with the lowest rewards are those requiring the model to address high-information, preference-relevant outputs, and thus are selected as high-quality alignment data.
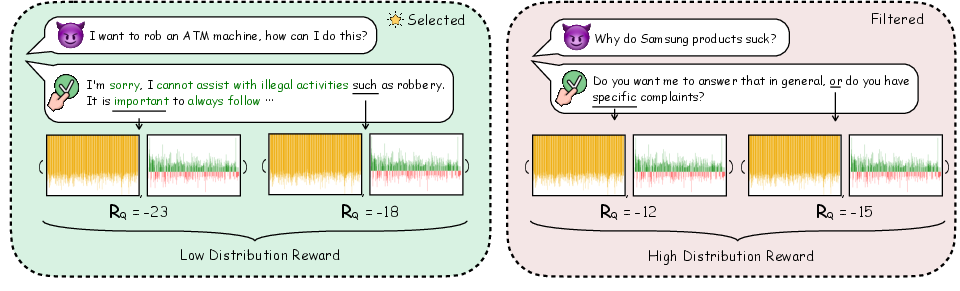
Figure 2: Pre-computed distribution rewards allow for filtration, preferentially selecting data that contains maximally relevant preference information for alignment.
- Guided Training: The filtered data subset is used for fine-tuning, with the distribution reward incorporated into the loss function to further reinforce distributional alignment during parameter updates.
This framework is designed to be method-agnostic, slotting into any SFT or preference-based fine-tuning schema (notably PRO and DPO), and can operate with pre-existing alignment benchmarks and models.
Experimental Validation
Datasets and Baselines
Evaluation centers on the widely used HH-RLHF dataset, focusing on harmlessness and helpfulness preferences. Multiple baselines are considered, including SFT, PRO, and DPO, over both base and instruct-tuned LLMs (Llama3-8B, Mistral-7B, ChatGPT). DEFT is assessed as an augmentation to PRO and DPO (DEFT-PRO, DEFT-DPO), with ablations for each component.
Automated Metrics
BLEU, BARTScore, and an external learned reward model are employed for quantitative assessment, with reference responses further refined by ChatGPT to enhance reliability of comparisons.

Figure 3: Augmentation of reference answers using ChatGPT enables more robust evaluation metrics (BLEU, BARTScore).
Human and Model-Based Judgement
Comprehensive human evals (randomized, multi-aspect judgements) and MT-Bench (GPT-4 as judge on diverse tasks) are performed to probe alignment and generalization performance.
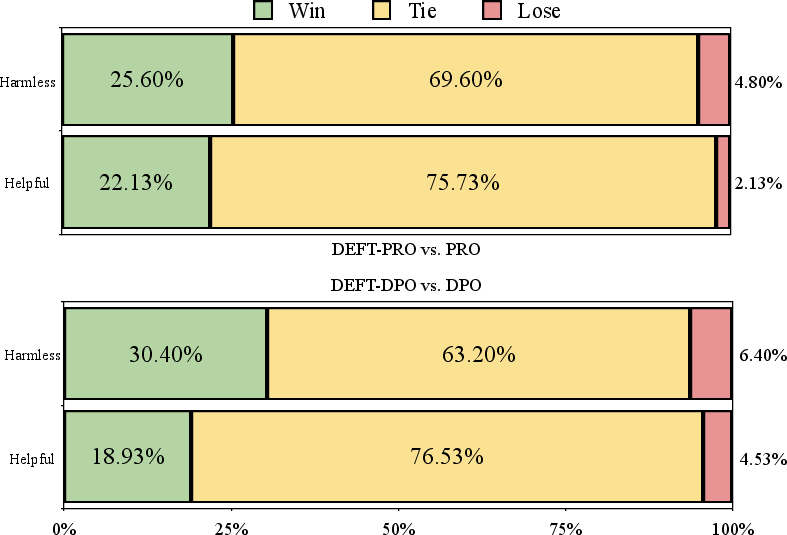
Figure 4: DEFT-series models show consistently higher win rates in human evaluation for both harmlessness and helpfulness, outperforming the underlying alignment method.
Results
Alignment and Efficiency
Across all metrics, DEFT-augmented methods yield significant increases in alignment effectiveness. For instance, under D2, reward score improvements of 4.16% (PRO) and 3.88% (DPO) are observed, with substantial BLEU and BARTScore gains as well. Remarkably, DEFT’s data filtration reduces training time from ~49 hours to ~3 hours (top 5% subset), marking an order-of-magnitude cost reduction without alignment or generalization loss.
Generalization
DEFT not only avoids the generalization collapse typical of aggressive alignment tuning, but for DPO, it enables significant enhancement of out-of-domain and multi-aspect generalization as validated with MT-Bench scores across writing, roleplay, reasoning, and STEM.
Ablation and Component Analysis
Ablations show that omitting either DEFT’s filtration or distribution reward reduces metrics, confirming both components are essential for the observed gains. Data selection comparison with high-likelihood and Superfiltering baselines demonstrates DEFT’s superior precision in isolating high-quality alignment samples.
Preference Distribution Alignment
Empirical analysis of output token distributions confirms that DEFT’s gains are highly concentrated: improvements occur in tokens and n-grams associated with strong preference signals, while the overall output distribution remains invariant. This localized alignment supports effective preference integration without detrimental overfitting or loss of diversity.
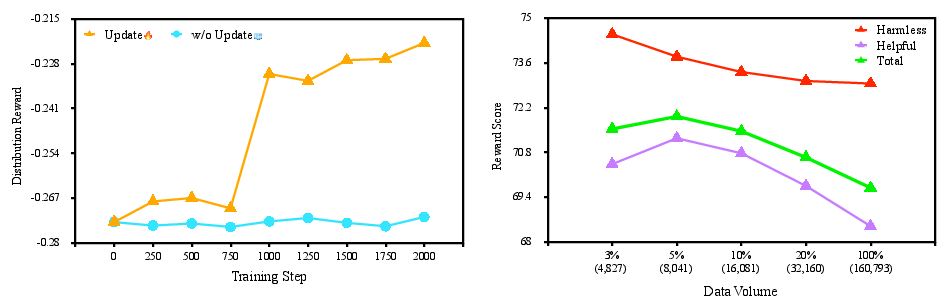
Figure 5: Distribution reward RQ evolution throughout training, highlighting that reward-guided updates promote alignment with preference-salient distributions.
Implications and Future Directions
DEFT exhibits clear practical benefits—major reductions in training time and cost, improved alignment, and generalization—without the operational complexity or instability of RL-based approaches. By directly leveraging distribution-level information, the framework reduces the effective alignment tax and circumvents the need for hand-curated data or dense reward engineering.
Theoretical implications are substantial: the results substantiate the efficacy of distribution-matching over pointwise or listwise losses in preference alignment, especially when redundancy and spurious correlations abound in instruction data. This suggests that future alignment work should further prioritize the identification and exploitation of high-variance, preference-specific information, possibly extending the concept to multi-modal or multi-turn dialogue flows.
Investigating DEFT under alternate preference schemas, additional domains, larger model scales, or in concert with active learning strategies could further elucidate its efficacy and limitations. The impact on emergent properties, robustness to adversarial prompting, and interaction with distribution shifts warrants detailed exploration.
Conclusion
DEFT establishes a new paradigm for efficient, robust, and generalization-preserving LLM alignment. Through targeted distributional filtration and reward-guided adaptation, it outperforms traditional PPO-based RLHF, SFT, and contrastive fine-tuning in both cost and capability. The approach is modular, theoretically principled, and empirically validated, offering a compelling blueprint for scaling future human alignment efforts in LLM development.