- The paper introduces PROWL, a novel framework that integrates PAC-Bayesian methods to certify reward uncertainty in individualized treatment rule learning.
- It reformulates policy optimization into a cost-sensitive classification problem, leveraging finite-sample PAC-Bayes guarantees and optimal Bayesian updates.
- Empirical results on synthetic benchmarks and clinical data demonstrate PROWL’s robust performance, significantly reducing target and robust regret compared to traditional methods.
PAC-Bayesian Reward-Certified Outcome Weighted Learning: A Technical Synthesis
Motivation and Structural Contribution
The paper "PAC-Bayesian Reward-Certified Outcome Weighted Learning" (2604.01946) addresses a fundamental shortcoming in individualized treatment rule (ITR) learning, particularly in contexts where observed rewards are unreliable or optimistic surrogates for clinically meaningful latent utility. Conventional Outcome Weighted Learning (OWL) and related direct-learning approaches ignore policy-sensitive reward uncertainty, resulting in a pathological inflation of empirical value estimates and potential misallocation of treatments. This work rigorously integrates reward uncertainty—quantified through a one-sided certificate—directly into the learning objective.
The key theoretical innovation is the introduction of PROWL (PAC-Bayesian Reward-Certified Outcome Weighted Learning), which certifies a conservative reward lower bound and directly maximizes the expected value that can be guaranteed by observed data under a valid uncertainty certificate. This formulation is not merely an incremental modification but a structural extension: it converts robust ITR learning under reward uncertainty into an exact, split-free cost-sensitive classification regime, facilitating finite-sample PAC-Bayesian guarantees and general Bayes posterior computation.
Exact Certified Reduction and PAC-Bayes Bound
A pivotal result is the certified value representation via doubly robust-style scores and cost-sensitive weighted risks, yielding the identity:
$V_\underline{R}(d) = C^\sharp_\alpha - R_{01}^\alpha(d)$
where $V_\underline{R}(d)$ is the policy-dependent certified value, Cα♯ captures nuisance structure, and R01α(d) is the weighted misclassification risk. This reduction enables learning nuisance and policy parameters on the same sample (split-free), avoiding systematic efficiency loss associated with honest sample-splitting in classical doubly robust frameworks.
The generalization performance is captured through a PAC-Bayes lower bound:
$V^*(d_Q) \geq \hat{V}_\underline{R,n}(d_Q) - K_\varepsilon \left\{\frac{KL(Q\|\Pi_0) + \log(1/\delta)}{\eta n} + \frac{\eta}{8}\right\}$
for any posterior Q≪Π0, where V∗(dQ) is the expected latent utility, and the empirical certified value $\hat{V}_\underline{R,n}(d_Q)$ is unbiased for $V_\underline{R}(d_Q)$. Notably, the bound is strictly maximized by a general Bayes update:
$\hat{Q}_\eta(\theta) \propto \exp\left\{\frac{\eta n}{K_\varepsilon}\hat{V}_\underline{R,n}(d_\theta)\right\}\Pi_0(d\theta)$
This shifts the role of generalized Bayesian inference from heuristic to optimal under the PAC-Bayes criterion, with explicit temperature calibration via empirical bounds.
Efficient Surrogate Implementation
A Fisher-consistent certified hinge surrogate loss is developed:
$V_\underline{R}(d)$0
where $V_\underline{R}(d)$1 and $V_\underline{R}(d)$2 are derived from certified advantage scores. The practical posterior family induced by this surrogate enables efficient computation, with MAP and mean-rule deployment demonstrating empirical robustness. The automated learning-rate selection exploits empirical lower confidence bounds, ensuring optimal calibration without manual hyperparameter search.
Numerical Experiments: Empirical Highlights
Synthetic benchmarks (Figure 1, Figure 2, Figure 3, Figure 4) systematically contrast PROWL against classical methods (OWL, RWL, Q-learning, PolicyTree) across both policy-invariant and policy-sensitive uncertainty regimes. In benign scenarios with policy-invariant reward uncertainty (Scenario 1), PROWL achieves parity with top-performing baselines, showing no penalty for conservatism. In complex, clinically heterogeneous environments (Scenario 2), PROWL delivers uniformly lower target and robust regret as uncertainty increases, outperforming naive proxy optimizers and even baselines using plug-in conservative rewards. This demonstrates that PROWL's gains derive from principled policy-learning against certified lower bounds, not mere pessimistic reward substitution.
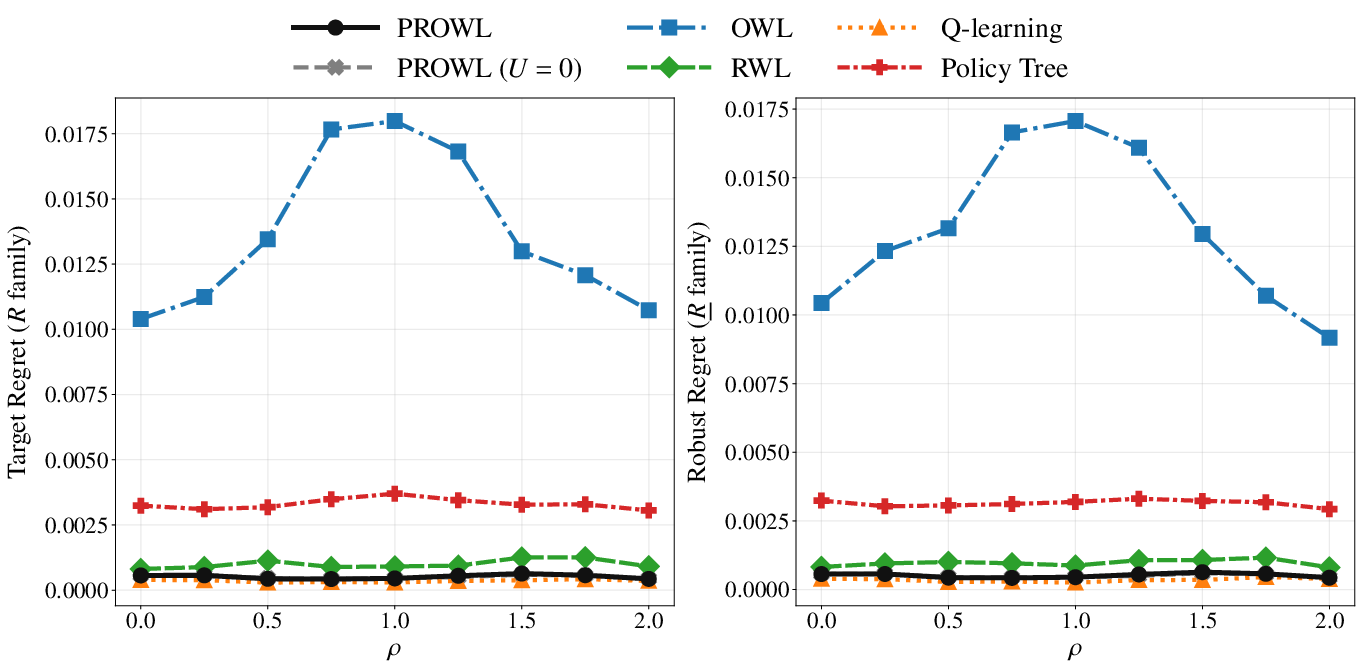
Figure 1: Performance comparison across varying uncertainty levels ($V_\underline{R}(d)$3) for Scenario 1, target and robust regret relative to $V_\underline{R}(d)$4-family baselines.
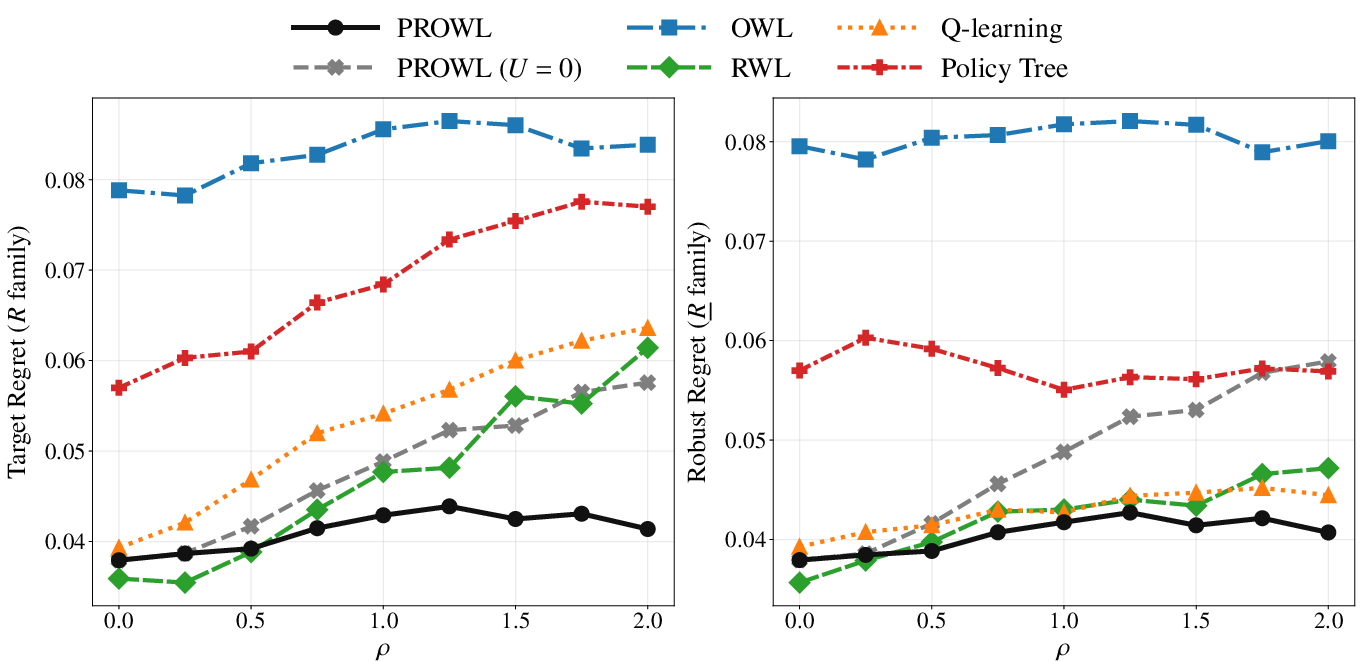
Figure 2: Scenario 2 performance across increasing $V_\underline{R}(d)$5, revealing substantial target and robust regret reduction under PROWL.
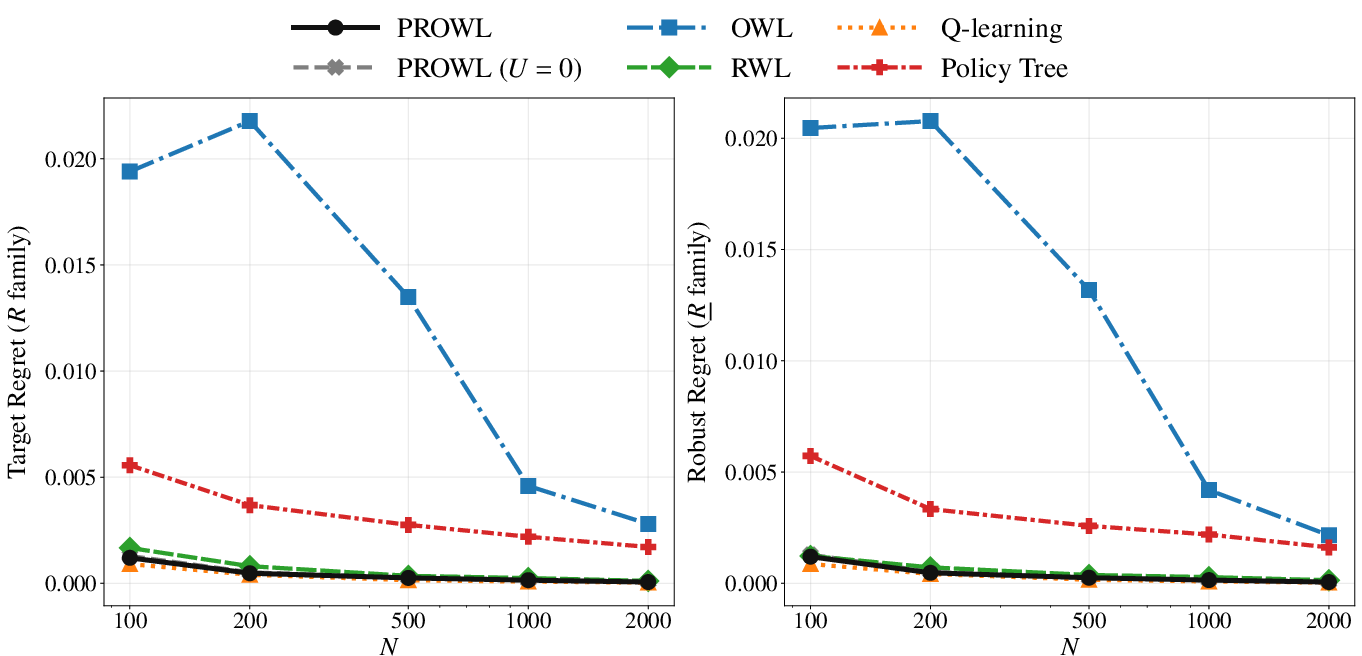
Figure 3: Target and robust regret decay with increasing sample size ($V_\underline{R}(d)$6) in Scenario 1; PROWL matches top baseline performance.
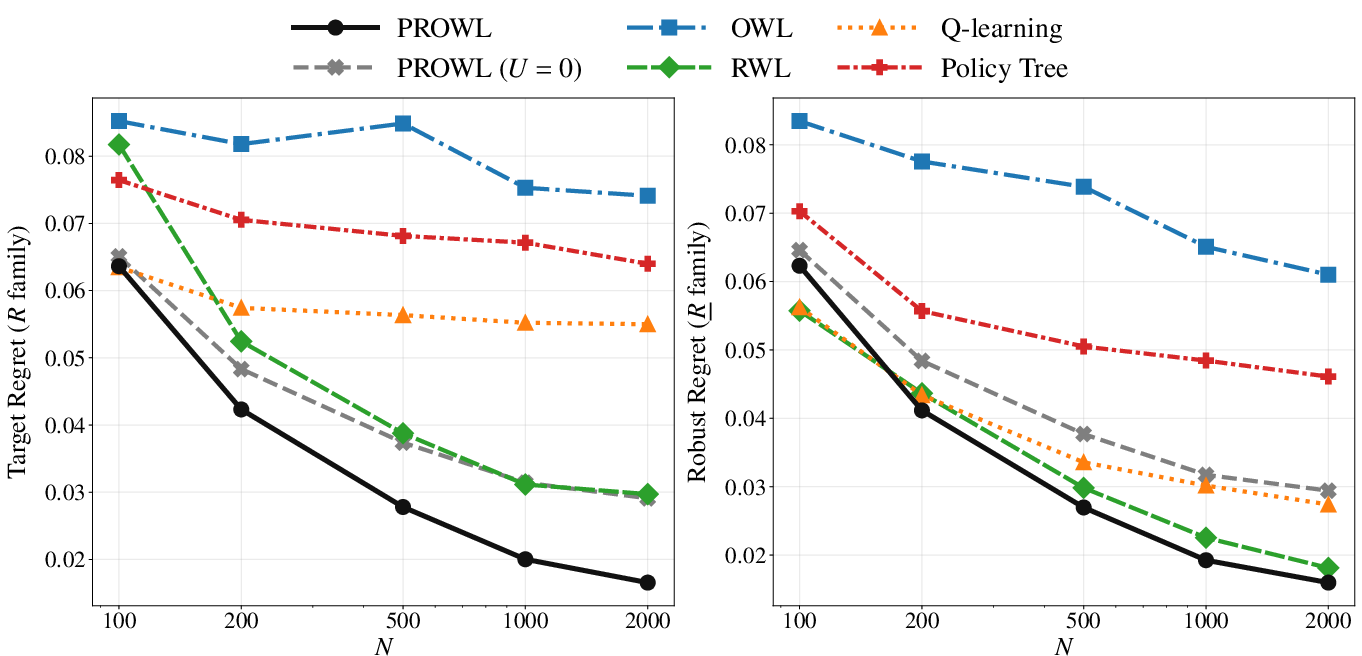
Figure 4: Scenario 2, sample size sweep, highlighting PROWL’s persistent dominance in regret minimization.
Actual Data Application: Composite Clinical Utility
Application to the ELAIA-1 AKI alert trial substantiates PROWL’s practical efficacy under moderate clinical preference uncertainty. Relative to blanket policies and classical adaptive learners, PROWL achieves highest certified value, lowest mortality risk, and optimal composite-free outcome with a moderate alert rate, strategically reallocating alerts away from high-risk non-teaching sites where proxy rewards are most optimistic (Figure 5, Figure 6):
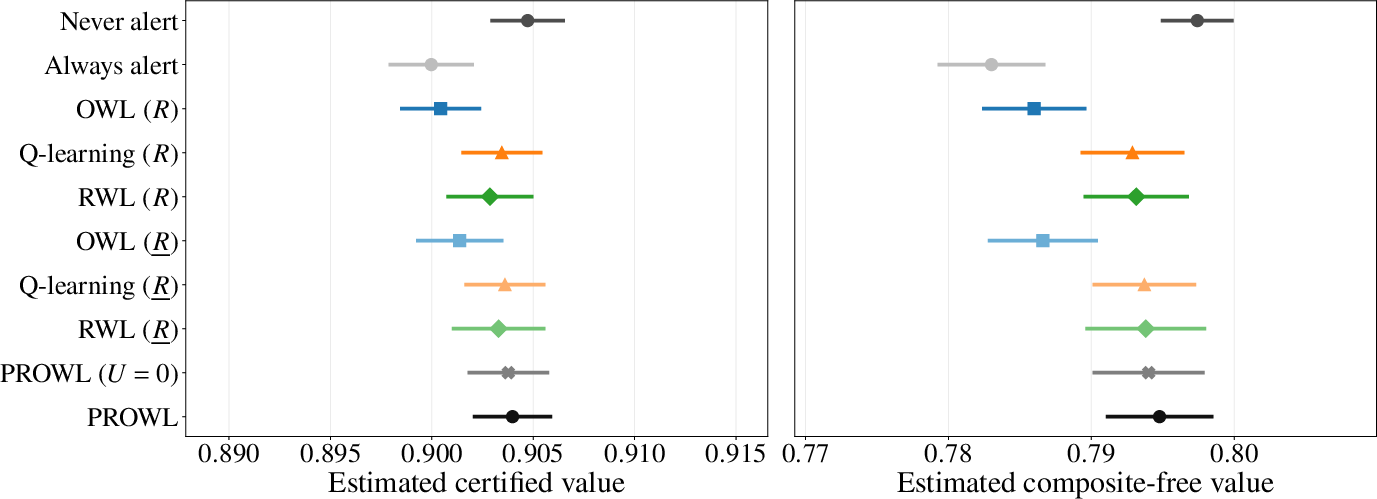
Figure 5: Point-range summary of method ordering on the certified and composite-free value in the ELAIA-1 AKI-alert trial.
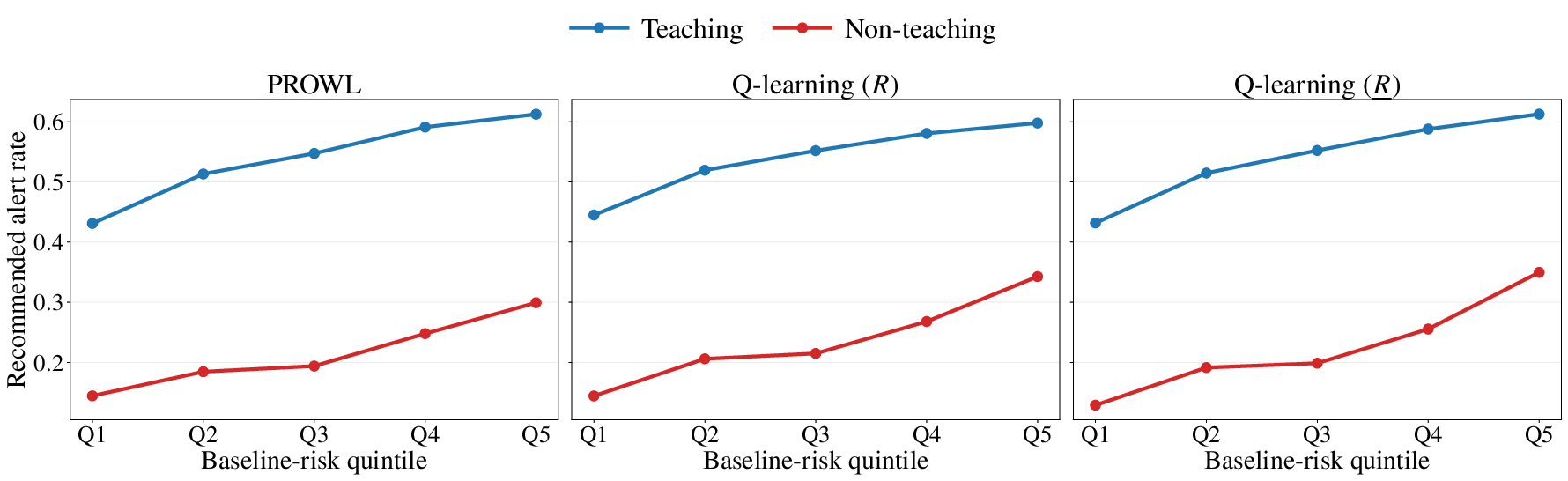
Figure 6: Learned alert allocation shows PROWL’s conservative behavior in non-teaching hospitals and high-risk quintiles, compared to Q-learning baselines.
PROWL demonstrates that reward-certification does not forcibly suppress intervention but re-optimizes allocation in zones of maximal reward uncertainty, consistent with robust personalized medicine.
Theoretical and Practical Implications
By elevating reward certification from a post-hoc adjustment to a structural component of policy optimization, PROWL offers verifiable safety guarantees in settings with optimistic, delayed, or composite surrogate rewards. Integrating PAC-Bayes theory into outcome weighted learning provides a robust foundation for treatment regime deployment where documented utility is as critical as empirical performance.
The methodology is particularly suitable for individualized medicine, health policy, and high-stakes decision-making in domains with ambiguous outcome quantification. Theoretical extensions are motivated by deterministic rule analysis, certificate learning under data dependence, and policy-independent reward uncertainty regimes. Applied development may include extension to dynamic treatment strategies, non-linear ambiguous objectives, and robust multi-stage policies.
Conclusion
PROWL delivers a principled, mathematically certified approach to individualized policy learning under reward uncertainty, bridging causal inference, PAC-Bayesian generalization theory, and generalized Bayesian updating. It achieves competitive or superior empirical performance, avoids undue pessimism, and facilitates split-free joint learning of nuisance and policy parameters. This framework significantly enhances reliability and interpretability for deploying data-driven treatment rules in clinical and socio-economic domains.