- The paper introduces domain-specific refinements, including content-aware cropping and anatomically-guided masking, to stabilize billion-parameter ViT training for radiology.
- Methodological advances such as low-resolution efficient pre-training and semantic-preserving regularization yield up to a +34.6 point accuracy improvement over prior protocols.
- The approach validates that scaling model size and tailored augmentations leads to state-of-the-art performance across unified 2D and 3D benchmarks in CT and MRI tasks.
Curia-2: Scaling Self-Supervised Learning for Multi-Modal Radiology Foundation Models
Introduction and Motivation
Curia-2 addresses the challenge of scaling self-supervised visual pre-training for radiology, aiming to deliver robust, general-purpose representation learning across computed tomography (CT) and magnetic resonance imaging (MRI) modalities. Existing foundation models in radiology, including both vision-only and vision-language approaches, have demonstrated the value of scale but are constrained by architectural, computational, and domain-specific limitations. The baseline Curia framework previously established high data and task scale for pre-training but inherited inefficiencies and instability from its adaptation of methods tailored for natural images. Curia-2 introduces several methodological refinements that enable stable training of billion-parameter Vision Transformers (ViTs) directly in the radiological domain, with particular emphasis on robust generalization to the clinically relevant 2D slice and 3D volumetric tasks.
Methodological Advancements
Curia-2 departs from standard natural image pipelines by revising data augmentation, loss functions, and training protocols to match the unique distributional properties of radiological data. The following core changes distinguish Curia-2:
- Low-Resolution Efficient Pre-training: Training is conducted at 256×256 resolution (matching optimal settings from DINOv2/v3), reducing compute cost per sample and facilitating deeper optimization. High-resolution ($512$) capabilities are re-introduced post hoc via positional embedding interpolation and targeted fine-tuning stages.
- Content-Aware Cropping: To counteract the prevalence of non-informative background in radiological images, Curia-2 implements a two-stage content screening—discarding background-dominated images and restricting cropping to ensure meaningful anatomical content. This contrast with random cropping from DINOv2 is pivotal for stability in low-resolution settings.
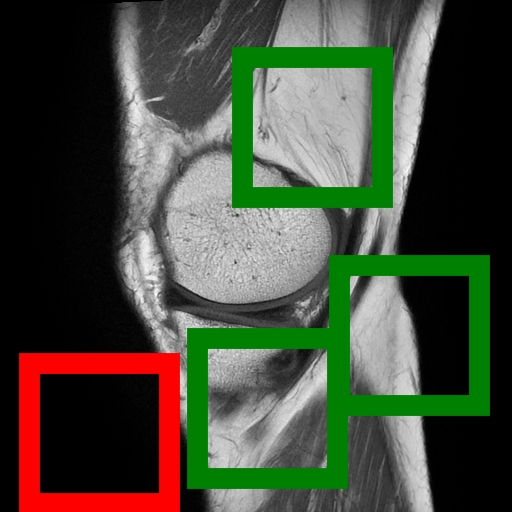

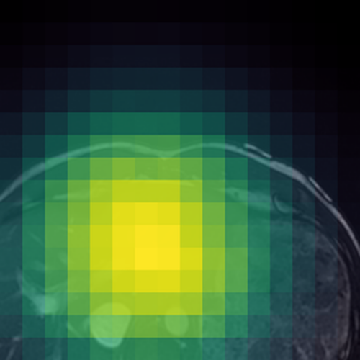
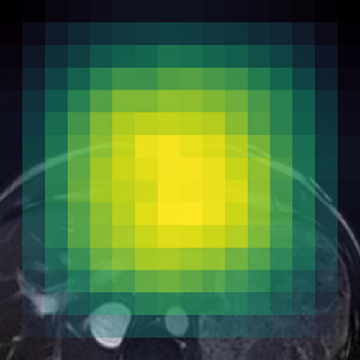

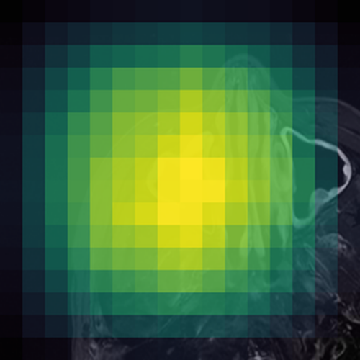
Figure 1: (Left) Valid (green) and filtered (red) crops clearly isolate informative image regions; (Right) Anatomically-guided masking (Gaussian prior) yields concentrated masks over anatomical ROIs compared to uniform blockwise masking.
- Anatomically-Guided Masking: Patch-level self-supervision uses a Gaussian-weighted prior over anatomical regions instead of the prior's default uniform distribution, focusing contrastive and reconstruction objectives on clinically relevant content and eliminating trivial signal from the empty background.
- Semantic-Preserving Regularization: The KoLeo batch-level uniformity regularizer is replaced with SigReg, which enforces isotropic feature geometry without unnaturally scattering anatomically similar structures. This benefits representation clustering in high-structural-homogeneity domains like radiological imaging.
- Scalable Infrastructure: Pre-training extends to 1.3B parameter ViTs (ViT-g), unprecedented in computational radiology FMs, powered by 130 TB, 228M instance diverse multi-modal scan collection and up to 9,680 A100 GPU-hours per run.
- CuriaBench-2D & 3D: The evaluation protocol unifies 19 diverse CT and MRI tasks into disjoint 2D and 3D tracks, allowing consistent benchmarking of both slice-based and volumetric FMs across anatomical, oncological, emergency, neurodegeneration, and other pathologies.
Empirical Evaluation and Scaling Insights
Ablation studies demonstrate that each architectural and augmentation modification confers substantial performance gains and eliminates catastrophic instability observed when naïvely transferring natural image protocols to low-resolution radiology SSL. Notably, the jump to content-aware cropping alone yields a +34.6 point raw performance improvement.
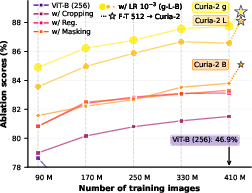
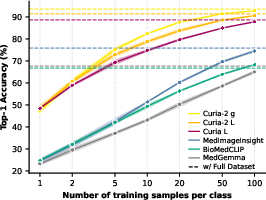
Figure 2: (a) Each methodological change drives a monotonic improvement in training stability and final test accuracy for radiology FMs; (b) Curia-2 g achieves rapid, data-efficient few-shot learning.
Scaling ViT backbone size provides consistent monotonic improvements across both 2D and 3D evaluation tracks. The transition from Curia-2 B (86M) to Curia-2 L (303M) to Curia-2 g (1.3B) is associated with accuracy improvements that solidify the benefit of compute- and parameter-scale in computational radiology, although the ViT-g scaling curve hints at unresolved optimization limitations for ultra-large models in this domain.
Feature Semantics and Cross-Modality Robustness
Curia-2 demonstrates strong semantic clustering across modalities and spatial contexts as visualized by patch-level cosine similarity maps. The model robustly identifies anatomically homologous regions between CT and MRI scans, including under geometric transformations and between organ systems.
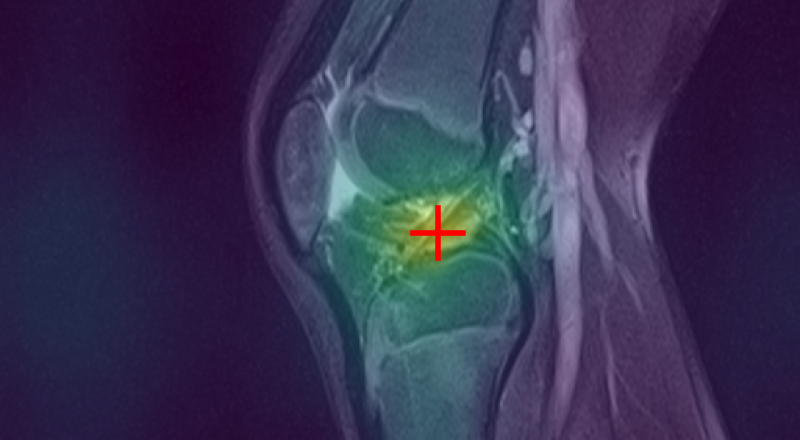
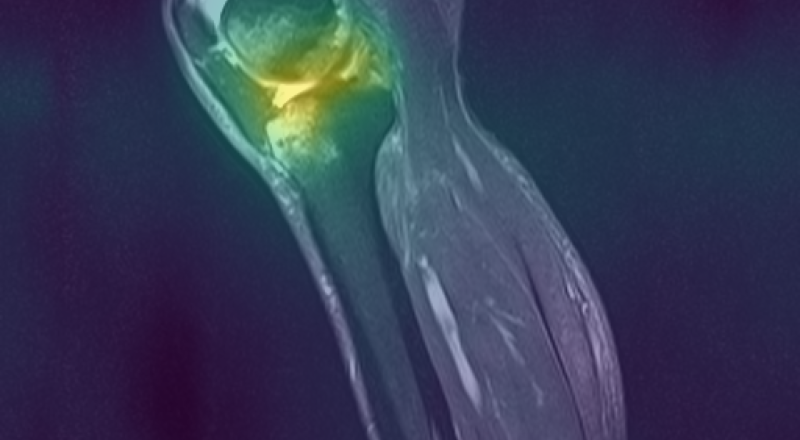
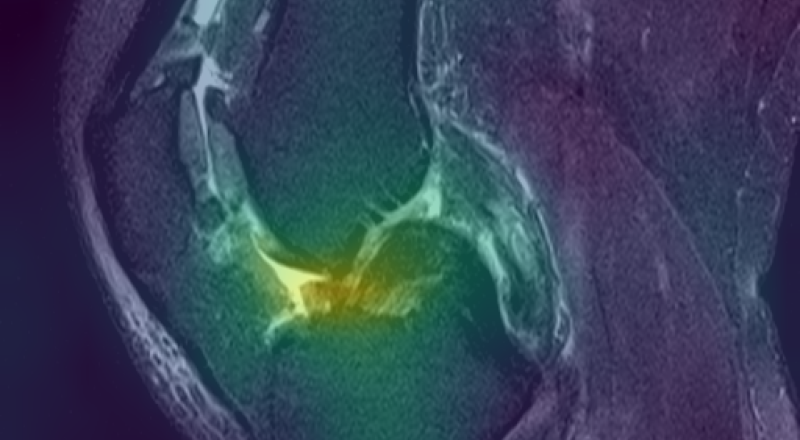
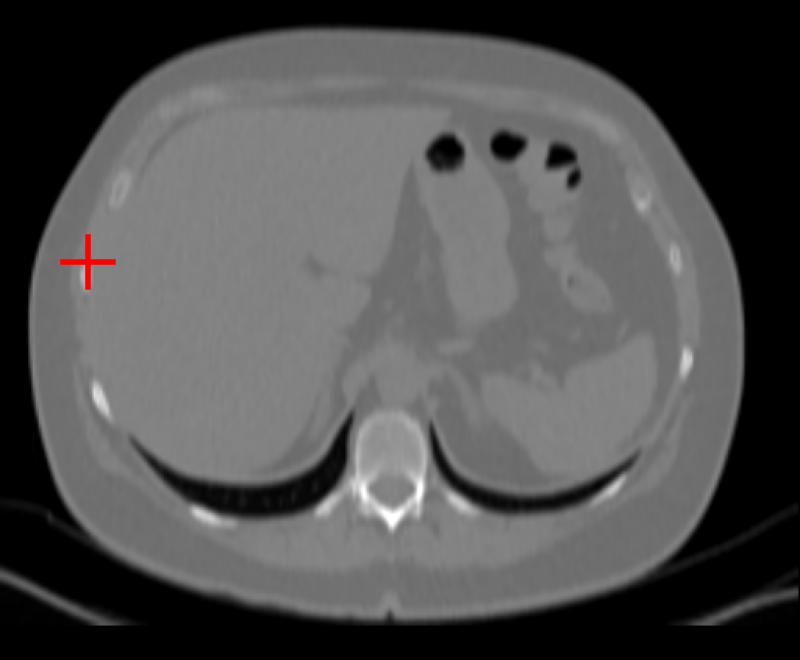
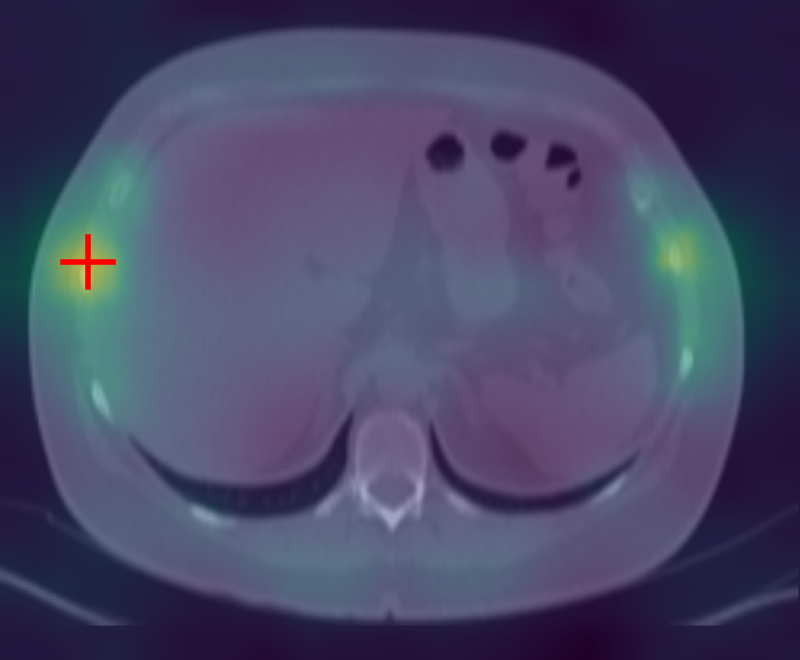
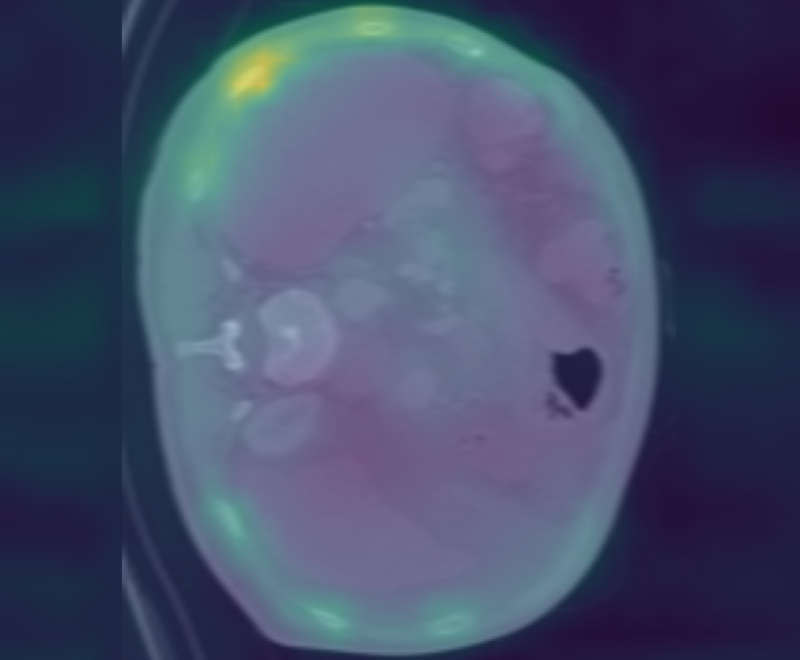
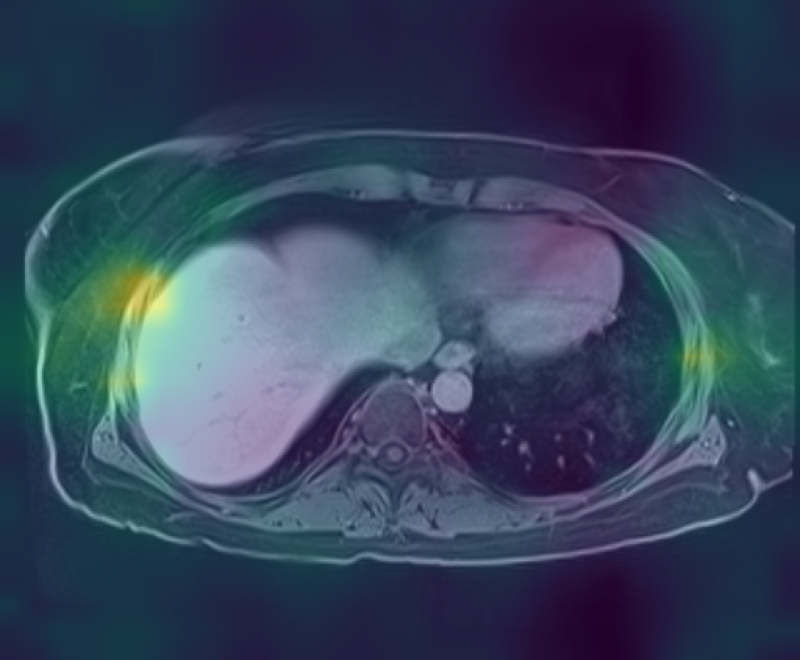
Figure 3: Curia-2 g produces sharp, cross-modality semantic correspondences between query patches and anatomically relevant ROIs, highlighting its generalizable dense feature geometry.
These results confirm that the new masking and regularization strategies effectively encode anatomical priors at all representational levels, improving both interpretability and downstream clinical applicability.
Curia-2 establishes a new state-of-the-art on both 2D and 3D CuriaBench tracks, outperforming notable radiology FMs such as MedImageInsight, BioMedCLIP, MedGemma, Merlin, and Pillar-0. The improvement is consistent across domains, with Curia-2 g exhibiting especially strong generalization in anatomical and musculoskeletal tasks and competitive results even in vision-language-dominated findings detection.
- 2D Track: Curia-2 L and Curia-2 g achieve top average accuracy (88.5%), outpacing previous FMs and displaying rapid convergence and high few-shot utility.
- 3D Track: Curia-2 L leads with 88.6% average, with the 1.3B ViT-g variant excelling particularly on anatomical discrimination and neuroimaging benchmarks.
Notably, while domain-specific language supervision traditionally grants an edge in findings detection tasks, Curia-2's vision-only paradigm remains competitive, achieving an 80.2% AUC compared to Pillar-0's 82.4%.
Practical and Theoretical Implications
Curia-2 validates that self-supervised scaled ViTs, when meticulously adapted to radiology-specific spatial and semantic priors, yield stable training regimes, semantically coherent representations, and robust generalization, both within-modality (CT/MRI) and across previously challenging 3D volumetric tasks. The sustained benefit of parameter scaling up to 1.3B parameters, given appropriately tuned augmentation and regularization, contradicts earlier findings of plateauing returns in large medical vision models, but scaling saturation is approached, suggesting the need for further innovation in architectural and optimization techniques for ultra-large-scale foundational radiology models.
From a practical standpoint, Curia-2's open-sourcing and rigorously benchmarked task suite will likely drive standardization and accelerate the development of general-purpose, data-efficient, and clinically translatable AI systems in radiology. Its results raise foundational questions about the relative value of vision-only versus multi-modal (vision-language) supervision, especially as dataset size and model capacity increase.
Future Directions
Curia-2 outlines several axes for ongoing improvement, including leveraging even larger image sets, scaling batch size and training duration, and incorporating post-training strategies such as Gram anchoring (as in DINOv3) to further enhance representation quality and transferability. Addressing the observed diminishing returns at the 1B+ parameter scale will require deeper study into the architectural and optimization bottlenecks unique to the radiology domain. Furthermore, harmonized benchmarks such as CuriaBench and public release of model weights will be instrumental in enabling objective progress measurement and community-wide adoption.
Conclusion
Curia-2 establishes new standards for self-supervised pre-training in multi-modal computational radiology, demonstrating the value of domain-specific augmentation, tailored regularization, and scalable infrastructure for stable, high-capacity FM training. The results position Curia-2 as a general-purpose vision backbone for both slice-based and volumetric radiological applications, narrowing the gap with vision-LLMs on complex clinical tasks and opening the field to further advances in data- and parameter-scale frontier exploration.