- The paper demonstrates the effective adaptation of causal LLMs into bidirectional encoders by combining MNTP and contrastive objectives.
- It employs weight merging to mitigate catastrophic forgetting, preserving foundational capabilities across multiple modalities.
- The work establishes an open-source pipeline that unifies generative and embedding paradigms, achieving state-of-the-art results on multimodal benchmarks.
BidirLM: Adaptation and Composition of Causal LLMs into Omnimodal Bidirectional Encoders
Introduction and Motivation
Bidirectional encoders have been fundamental to modern language understanding, but causal LLMs—owing to their generative dominance—have accrued extensive domain and modality-specific pretraining. “BidirLM: From Text to Omnimodal Bidirectional Encoders by Adapting and Composing Causal LLMs” (2604.02045) systematically addresses the challenge of repurposing causal, decoder-only LLMs into efficient, generalizable, and composable bidirectional encoders, spanning text, vision, and audio. This work targets three fundamental gaps observed in prior adaptation efforts: the absence of principled objective selection, catastrophic forgetting when decoupled from the original pretraining data, and inflexibility in leveraging specialized causal models.
Methodology: Architectural Adaptation and Training Objectives
The authors evaluate and ablate adaptation trajectories for both Gemma3 and Qwen3 families, formalizing five adaptation variants by toggling causal vs. bidirectional attention and explicit adaptation objectives—standard causal (Base), naive bidirectional (Bi+Base), bidirectional with masked next-token prediction (Bi+MNTP), bidirectional with contrastive training (Bi+Contrastive), and an MNTP-then-contrastive pipeline (Bi+MNTP+Contrastive). The MNTP objective, in particular, is demonstrated as essential for unlocking strong generalization in full fine-tuning and establishing the bidirectional context window crucial for robust representation (Figure 1).
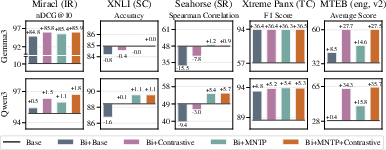
Figure 1: Absolute downstream performance changes introduced by individual adaptation strategies and objectives, with exact gains and losses annotated.
MNTP and contrastive objectives are shown to be complementary. Contrastive-only training sharply increases zero-shot embedding quality, but at the expense of fine-tuning transfer (XNLI, Seahorse), which is largely restored by a preliminary MNTP phase.
Scaling Adaptation: Catastrophic Forgetting and Model Merging
Scaling bidirectional adaptation with out-of-domain or open datasets induces catastrophic forgetting, particularly for base model capabilities outside the adaptation data distribution. As adaptation runs progress—the authors evaluate runs with up to 30B tokens—performance on original-code and multilingual domains degrades (Figure 2).
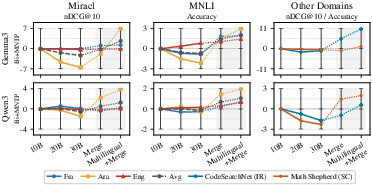
Figure 2: Model performance drift due to extended adaptation, with highlight on mitigation from merging strategies and multi-domain mixtures.
To address this, the authors employ linear weight interpolation (“model soups”), merging adapted checkpoints with their respective base models. A 50% merging ratio (Figure 3) is empirically robust, yielding effective retention of bidirectionality and foundational knowledge.
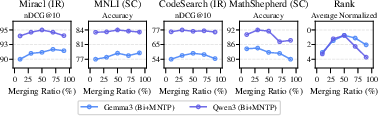
Figure 3: Task performance and overall ranking as a function of linear merging ratio between base and adapted weights.
Further, supplementing the adaptation corpus with as little as 20-30% multi-domain data (multilingual, code, math) achieves strong preservation, with a merged checkpoint at this mixture outperforming both naive and pure English-adapted versions (Figure 4).

Figure 4: Performance across data mix ratios for multi-domain inclusion during adaptation, with optimal retention at modest mixture ratios.
BidirLM and the Open-Source Frontier
Scaling the preferred biphasic adaptation recipe to larger models, the authors realize the BidirLM family: Gemma3 (270M, 1B), Qwen3 (0.6B, 1.7B), and the omnimodal BidirLM-Omni-2.5B (text, vision, audio). These models, without proprietary data or distillation, establish new Pareto frontiers for both fine-tuned and zero-shot embedding benchmarks (Figure 5).
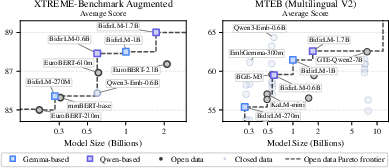
Figure 5: Average benchmark performance for BidirLM family models versus open-source alternatives, highlighting the new Pareto frontier.
Notably, the same architecture supports strong fine-tuning and embedding use cases—contradicting the conventional dichotomy between BERT-style and embedding-only architectures.
Composing Domain and Modal Specialists via Weight Merging
The composability of adapted encoders is demonstrated through post-hoc specialization. By linear merging with domain-specific causal specialists—e.g., Qwen3Guard-Gen for safety moderation, Qwen3-VL for vision, Qwen3-ASR for audio—the authors efficiently transfer task competence in a training-free fashion.
Domain-specialized encoders via merging outperform both the specialist and vanilla adapted models, with immediate sample-efficient fine-tuning convergence and superior OOD generalization (Figure 6).

Figure 6: Test split performance during domain specialization on safety benchmarks, demonstrating both peak and rapid adaptation by merged models.
For modalities, merging—even without pre-existing modality overlap—yields strong vision and audio adaptation with only a short warm-up phase during fine-tuning (Figure 7).
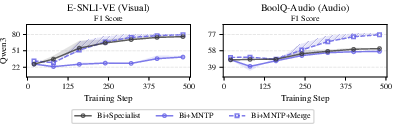
Figure 7: F1 score evolution on visual and audio benchmarks, highlighting large gains and rapid adaptation via merging with multimodal specialists.
Omnimodal Model Construction and Evaluation
Integrating these insights, BidirLM-Omni-2.5B is constructed by merging three Qwen3-1.7B specialists (ASR, VL, Bi+MNTP) and inheriting their heads. Contrastive training on an aligned multimodal corpus yields state-of-the-art results—surpassing Nemotron-Omni and several unimodal/bi-modal larger baselines on MTEB, MIEB, and MAEB (Figure 8).

Figure 8: BidirLM-Omni establishes a new Pareto frontier for omnimodal models across multilingual text, image, and audio benchmarks.
Weight-space Analysis
Layer-wise cosine similarities confirm linear connectivity and minimal destructive interference (Figure 9, Figure 10), supporting the theoretical plausibility of linear weight merging even for models specializing in non-overlapping modalities.
Implications and Future Directions
This work demonstrates that a single, model-agnostic, open-source pipeline can efficiently re-purpose, scale, and specialize causal LLMs as strong bidirectional encoders for both unimodal and multimodal settings. Key implications include:
- Composable adaptation: New domain and modality capabilities can be attached post-hoc via computationally free merging, eliminating the necessity for repeated full pipeline training.
- Efficient catastrophic forgetting mitigation: Requiring neither proprietary pretraining data nor heavy regularization, weight merging and modest corpus augmentation suffice to achieve output-competitive performance with strong knowledge retention.
- Unified model economies: Strong performance in both embedding and fine-tuning regimes obviates current needs for specialized architectures.
For future research, comprehensive ablation of contrastive training data composition, adaptation regularization (including distillation), and transfer to non-transformer causal architectures (e.g., state-space models) are highlighted as priorities.
Conclusion
BidirLM (2604.02045) provides a technically robust, composable, and efficient framework for adapting and expanding the causal LLM ecosystem into high-performing bidirectional encoders. Through principled ablation, open-source corpus deployment, and innovative use of model merging, it both unites and extends the strengths of generative and encoding paradigms, paving a straightforward path for future large-scale, omnimodal, and domain-specialist model composition in open-source research.

