- The paper demonstrates that integrating multimodal inputs in a conversational AI, MuDoC, significantly improves learning outcomes compared to text-only alternatives.
- It employs a randomized controlled trial, quantitative assessments, and cognitive load analysis to isolate the effects of conversationality and visual aids.
- The study highlights implications for AI-augmented education, emphasizing a careful balance of cognitive load to support effective learning.
Impact of Multimodal and Conversational AI on Learning Outcomes and Experience
The investigated paper presents a rigorous randomized controlled study on the effect of multimodal and conversational AI systems on short-term learning outcomes and subjective experience in biology education, specifically the topic of meiosis. The research design isolates the contributions of both conversational AI and multimodality by comparing three systems: (1) MuDoC, a document-grounded conversational AI generating interleaved text-and-image responses; (2) TexDoC, a text-only version of MuDoC; and (3) DocSearch, a classical semantic search tool. The study quantitatively and qualitatively evaluates how these systems mediate student learning, cognitive engagement, and perceived usability, interpreted through the lens of Cognitive Load Theory (CLT).
System Design and Architecture
MuDoC is built on a Next-Gen Multimodal LLM (MLLM), gpt-4.1, leveraging function-calling and multimodal input capabilities. Document preprocessing includes segmentation using advanced layout parsers (HURIDOCS), extraction of both semantic text and figure data, dense and sparse indexing with dual encoders (OpenAI and SigLIP), and multi-step summarization for text blocks and images. Images and their descriptions are embedded in the context window for downstream conversational reasoning.
The generation protocol utilizes the ReAct loop (Reason-and-Act), guiding the LM through iterative cycles of reflective reasoning and discrete actions: Initial Search, Content Search, Confirm Intent, and Final Response. This facilitates context-aware retrieval, adaptive clarification, and grounded synthesis of responses with explicit in-text citations and HTML-based image embedding.
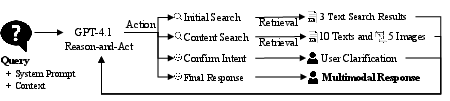
Figure 1: Architecture of MuDoC's ReAct-based conversational loop with multimodal search and generative actions.
TexDoC ablates all image-based capabilities, preserving the core pipeline otherwise. DocSearch exposes only the retrieval backend through semantic search and does not maintain dialogue state or synthesize explanatory responses. The comparative architecture enables attribution of specific effects to conversationality and multimodality.
Experimental Methodology
Participants (N=124), all biology-major adults from the U.S. recruited via Prolific, undertook a standard learning session involving a pre-test, a 15-minute video introduction to meiosis, an interactive session with the assigned AI system, a post-test focused on visual learning objectives, and a Likert-scale survey probing learning experience. System logging recorded detailed behavior and engagement metrics across all interventions.
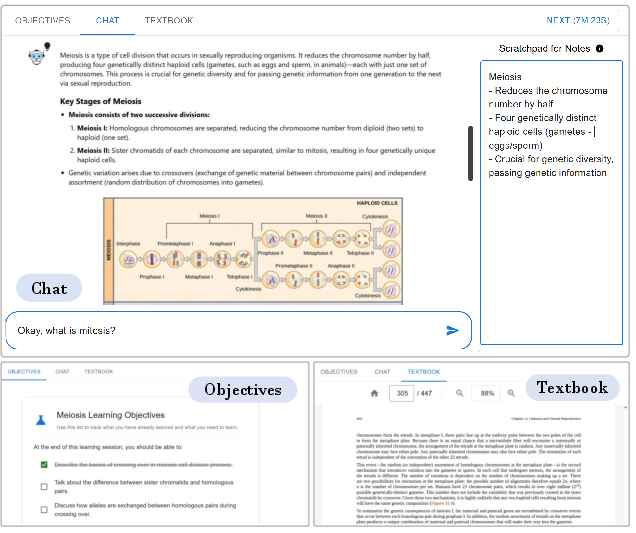
Figure 2: Example user interface for self-learning: chat, objectives, document viewer, and notepad.
Quantitative Results and Cognitive Load Interpretation
Learning Outcomes
Statistical analysis reveals that MuDoC users achieve significantly higher post-test scores than TexDoC (Δ = 0.69, p = .01, moderate effect size), while the difference between MuDoC and DocSearch approaches but does not reach statistical significance. Pre-test scores were balanced, confirming validity. Users with MuDoC spent slightly less time in the system, made fewer queries and note edits, but engaged more thoroughly with high-quality visuals interleaved in responses.
Learning Experience
On subjective measures, both MuDoC and TexDoC outperform DocSearch on usability, engagement, and perceived helpfulness, with no significant differences between the conversational systems. However, only MuDoC is rated as significantly more thought-provoking ("makes me think") than the non-conversational baseline, suggesting a unique cognitive impact of grounded multimodality.
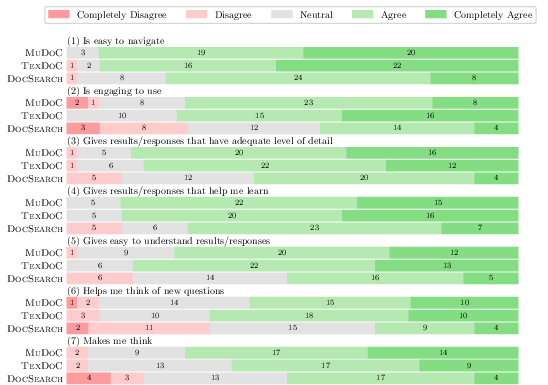
Figure 3: Survey results tracking perceived learning experience across systems (higher is better).
Cognitive Load Theory Analysis
Applying CLT, the data suggest:
- Conversationality reduces extraneous cognitive load: Both MuDoC and TexDoC facilitate context maintenance and eliminate the fragmentation of traditional search and reading.
- Multimodality (text+images) increases germane load: Only MuDoC, by integrating relevant visuals resolved into the conversational flow, maintains elevated germane load, supporting deeper sensemaking and durable learning.
- Risk of fluency effect/overconfidence: TexDoC, despite high engagement ratings, does not improve learning outcomes, demonstrating a disconnect where reduced extraneous load is misattributed as genuine mastery—a fluency illusion that is well-documented in other learning science research [oppenheimer_secret_2008].
Qualitative Insights
Free-response data reinforces the quantitative findings: MuDoC is most valued for integrated visual explanations and simplified, grounded summaries. TexDoC’s lack of visual aids is repeatedly cited as a limitation, and DocSearch is described as efficient but "not intelligent". Cognitive overload and system latency are minor concerns in MuDoC, likely reflecting the increased student activity in integrating two modalities and the complexity of response generation.
Theoretical and Practical Implications
This work delivers clear evidence that multimodal LLM-based conversational systems—when grounded in domain documents and equipped for intelligent retrieval and synthesis—yield measurable improvements in short-term STEM learning outcomes over purely textual conversational AI. The study exposes the inadequacy of subjective engagement metrics as proxies for learning in text-only conversational settings and demonstrates the need to balance extraneous and germane cognitive load for robust instructional design.
Practically, the MuDoC pipeline serves as a reference model for AI-augmented textbooks in visually dense domains. The findings argue strongly for integrating multimodal retrieval and grounded generation capabilities in future educational AI systems, not simply conversational wrappers around text.
From a theoretical perspective, these results highlight the obligation for future work to measure both learning experience and objective outcomes, and to be attentive to the risk of AI-driven fluency effects or overreliance [zhai_effects_2024, fan_beware_2024, lehmann_ai_2024]. The data also suggest that enhanced retrieval and generative grounding of visuals (e.g., via adaptive diagram generation or augmented reality integration) represent promising avenues.
Relation to Prior Work and Future Developments
The study builds upon earlier demonstrations that conversational AI can improve engagement [kakar_jill_2024, goel_jill_2018], but uniquely quantifies the additive benefit of multimodality on actual learning. Related work in medical and mathematical domains corroborates the advantages of multimodal systems for engagement but often fails to isolate or evaluate learning transfer [bland_enhancing_2025, chen_interactive_2025]. This paper's experimental rigor advances the state of empirical research on MLLMs in education.
The challenge of grounding, source attribution, and minimizing hallucinations remains ongoing. Improvements in retrieval-augmented generation for multimodal content [karpukhin_dense_2020, nakano_webgpt_2022], better cognitive load measurement instrumentation [korbach_measurement_2017], and techniques for introducing productive friction or metacognitive scaffolding [singh2025enhancing] are likely directions for system enhancement and evaluation frameworks.
Conclusion
This research provides robust evidence that multimodal, document-grounded conversational AI significantly improves STEM learning outcomes and experience by mediating a favorable balance of cognitive load. Conversationality alone is insufficient and may induce illusions of learning if not combined with mechanisms that target germane load, such as adaptive, interleaved visuals. These results have direct implications for AI-enabled curriculum design, the deployment of MLLMs in educational platforms, and the evaluation strategies employed in education technology research. Future developments should focus on advancing retrieval and multimodal generation, refining measurement of cognitive effects, and extending these insights across disciplines and learner demographics.
References
- "Impact of Multimodal and Conversational AI on Learning Outcomes and Experience" (2604.02221)
- See also "Enhancing Medical Student Engagement Through Cinematic Clinical Narratives" [bland_enhancing_2025], "Interactive Sketchpad: A Multimodal Tutoring System" [chen_interactive_2025], "Do AI Chatbots Improve Students Learning Outcomes? Evidence from a Meta-Analysis" [wu_ai_2024], "Beware of metacognitive laziness: Effects of generative artificial intelligence on learning motivation, processes, and performance" [fan_beware_2024], and "The effects of over-reliance on AI dialogue systems on students' cognitive abilities: a systematic review" [zhai_effects_2024].

