Do Emotions in Prompts Matter? Effects of Emotional Framing on Large Language Models
Abstract: Emotional tone is pervasive in human communication, yet its influence on LLM behaviour remains unclear. Here, we examine how first-person emotional framing in user-side queries affect LLM performance across six benchmark domains, including mathematical reasoning, medical question answering, reading comprehension, commonsense reasoning and social inference. Across models and tasks, static emotional prefixes usually produce only small changes in accuracy, suggesting that affective phrasing is typically a mild perturbation rather than a reliable general-purpose intervention. This stability is not uniform: effects are more variable in socially grounded tasks, where emotional context more plausibly interacts with interpersonal reasoning. Additional analyses show that stronger emotional wording induces only modest extra change, and that human-written prefixes reproduce the same qualitative pattern as LLM-generated ones. We then introduce EmotionRL, an adaptive emotional prompting framework that selects emotional framing adaptively for each query. Although no single emotion is consistently beneficial, adaptive selection yields more reliable gains than fixed emotional prompting. Together, these findings show that emotional tone is neither a dominant driver of LLM performance nor irrelevant noise, but a weak and input-dependent signal that can be exploited through adaptive control.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: if you tell an AI how you’re feeling before you ask it a question (for example, “I’m really angry about this!”), does that change how well it answers? The researchers tested this on many kinds of questions and also tried a smart way to pick the best “emotional tone” for each question.
What did the researchers want to find out?
They focused on five easy-to-understand questions:
- Do short, first-person emotional statements (like “I’m happy/sad/angry…”) in a user’s prompt change how accurately LLMs answer?
- Does making the emotion stronger (like “very” or “extremely”) make a bigger difference?
- Does it matter if a human writes the emotional sentence versus an AI writing it?
- Are some tasks more sensitive to emotional tone than others?
- Can we do better by choosing an emotion that fits each question instead of using the same emotion every time?
How did they test it?
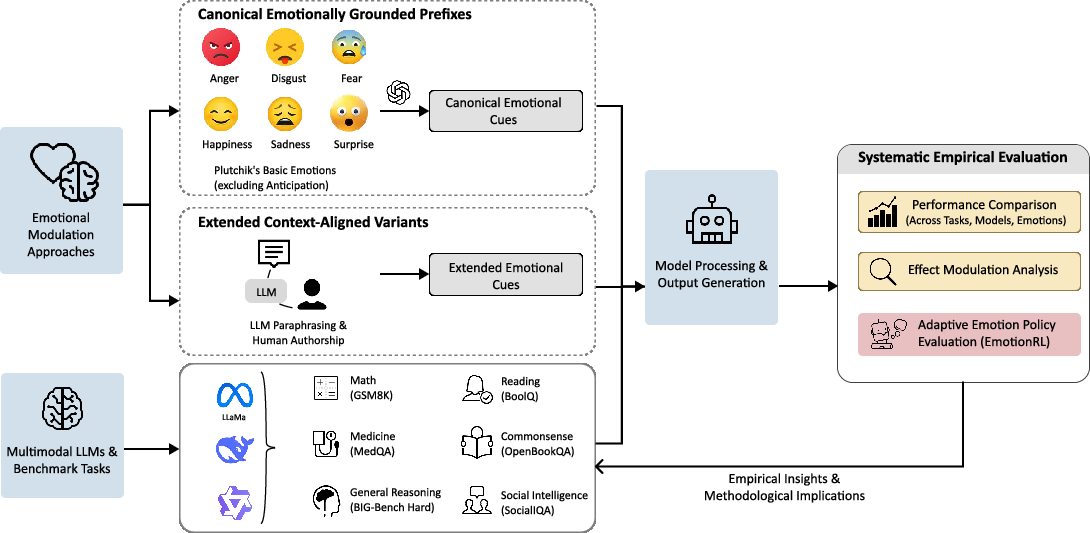
They used a simple idea: add one short emotional sentence before the exact same question, then see if the AI’s answer changes. They tried six basic emotions—happiness, surprise, fear, sadness, disgust, and anger—based on classic psychology models of emotion.
They checked performance on different kinds of tasks:
- Math word problems (GSM8K)
- Hard mixed reasoning puzzles (BIG-Bench Hard)
- Medical multiple-choice questions (MedQA)
- Reading comprehension (BoolQ)
- Everyday commonsense questions (OpenBookQA)
- Social situation reasoning (SocialIQA)
They ran these tests on several strong AI models, keeping everything else the same (same questions, same settings), and measured accuracy (how often the answer was correct).
They also ran special checks:
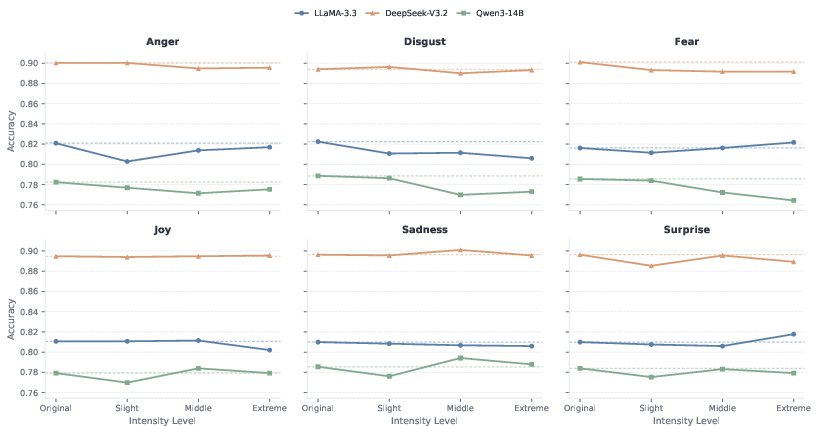
- Emotion intensity: Slight, very, and extremely emotional wording, to see if stronger emotion matters more.
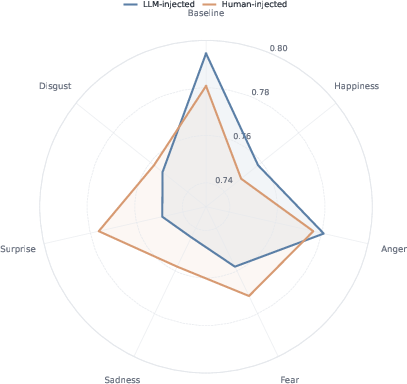
- Human vs. AI writers: Comparing emotional sentences written by people to ones written by an AI, to see if the source changes the effect.
- Adaptive selection (EmotionRL): A small “chooser” model learns which emotion works best for each question, then applies that one instead of using the same emotion for all questions.
Think of EmotionRL like a coach: before asking the big AI the question, the coach looks at the question and picks the emotion that previously worked best for similar questions.
What did they find?
Here are the main takeaways:
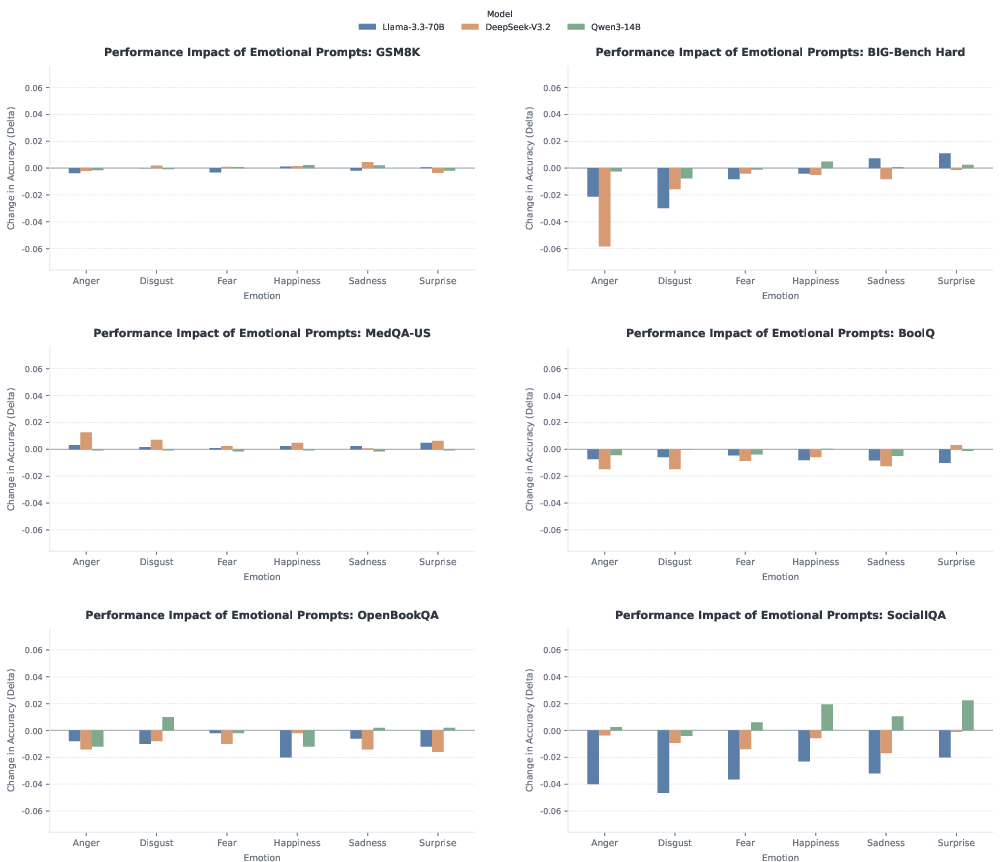
- Small overall impact from fixed emotions: Adding a short emotional sentence usually changes accuracy only a little. Most of the time, the AI performs about the same as with a neutral prompt.
- Task differences: Emotion mattered more for social reasoning (SocialIQA), where understanding people’s feelings and intentions is part of the task. For math and medical questions, emotions had very small effects.
- Stronger wording doesn’t change much: Making the emotion “very” or “extremely” strong added only a small extra shift. No dramatic breakdowns or big boosts appeared.
- Human vs. AI-written emotional lines: Results were basically the same. It didn’t matter much who wrote the emotional sentence.
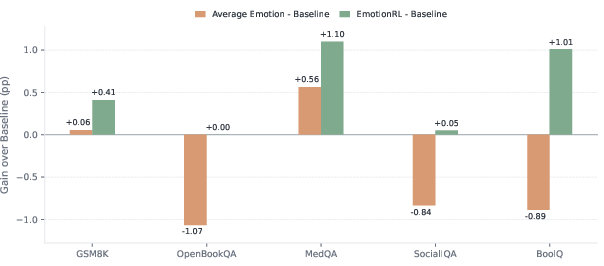
- Adaptive is better than fixed: While no single emotion consistently helped across all questions, the EmotionRL coach that picks an emotion per question gave more reliable improvements than using the same emotion every time.
In short: a fixed emotional tone is like a tiny nudge; it usually doesn’t move the needle much. But if you choose the emotion to match the question, you can squeeze out steadier gains.
Why does this matter?
- Real conversations are emotional, and people often talk to AI when they’re stressed, excited, or upset. It’s useful to know that short emotional phrasing in prompts usually doesn’t break the AI—or magically make it smarter.
- Emotion isn’t useless, though. When chosen carefully for each question, emotional framing can help a bit.
- For future systems, this suggests a better approach: don’t rely on one “emotional trick” for all prompts. Instead, adapt the style to the situation.
- The study focused on single-turn, accuracy-based tasks. Bigger effects might show up in longer chats, in sensitive support conversations (like health or counseling), or when the goal is empathy or safety rather than just getting the right answer.
Overall, the message is balanced and practical: emotions in prompts aren’t a magic switch, but they can be a small, helpful tool—especially when used thoughtfully and adaptively.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored based on the paper.
- External validity to real-world interactions:
- Multi-turn conversations and evolving affect over turns were not tested; effects of sustained, fluctuating, or strategically timed emotions remain unknown.
- Naturalistic user inputs often embed emotion within longer, messy text; the study uses short, clean, single-sentence prefixes, leaving generalization to realistic prompts unexamined.
- Cross-lingual, code-switched, and culturally specific emotional expressions were excluded; sensitivity to linguistic and cultural emotion markers is unknown.
- Task and modality scope:
- Only accuracy-based QA/reasoning tasks were evaluated; open-ended generation (summarization, creative writing, dialogue), coding, planning, and instruction-following tasks were not covered.
- Socially sensitive or safety-critical tasks (e.g., mental health, legal advice) and settings where style/empathy are primary metrics were not evaluated.
- Only English datasets were used; robustness to other languages and multilingual models remains an open question.
- Prompt design space:
- Emotion framing was limited to first-person user-side emotion directed at the assistant; alternative framings (e.g., emotion toward the topic/third parties, second-person or model-persona emotion, role-play) were not explored.
- Only six “basic” emotions were considered; mixed/ambivalent states, sarcasm/irony, contempt, guilt, shame, or continuous valence–arousal controls were not tested.
- Intensity manipulations were examined only on MedQA; whether intensity effects replicate across other tasks and models remains unknown.
- Position sensitivity was probed only on GSM8K; generalization of position effects (pre/intra/post) across other datasets and tasks is untested.
- Prefix length, multi-sentence emotion, and discourse-level emotion cues were not varied; scaling effects of emotional content length/complexity are unknown.
- Interaction with standard prompting strategies (e.g., chain-of-thought, “think step by step,” system-message priming, few-shot in-context examples) was not assessed.
- Model and decoding conditions:
- Evaluations were limited to three open-weight models; generalization to frontier proprietary models (e.g., GPT-4-class), smaller models, and other architectures remains unclear.
- All runs used deterministic decoding (temperature 0); how emotional framing interacts with stochastic sampling, beam search, or nucleus/top-k sampling is unknown.
- Effects across model sizes and RLHF alignment levels were not systematically analyzed; whether alignment training modulates emotion sensitivity is open.
- Metrics and behavioral outcomes beyond accuracy:
- No analysis of calibration (confidence/uncertainty), robustness, or error types; whether emotion shifts confidence or error patterns was not measured.
- Potential impacts on toxicity, politeness, refusal rates, guardrail adherence, or safety behaviors (especially with rude/negative prefixes) were not evaluated.
- Output style, empathy, helpfulness, and user-perceived quality were not measured; affect may change subjective quality even if accuracy is stable.
- Statistical rigor and reporting:
- Statistical significance, confidence intervals, and effect-size estimates were not reported; small deltas may be within noise.
- No item-level difficulty stratification or error analyses; whether “hard” vs “easy” items respond differently to emotion is unknown.
- Mechanisms and interpretability:
- No mechanistic or representational analysis was conducted; how emotion tokens influence attention, intermediate activations, or reasoning trajectories (especially with chain-of-thought) remains unexplored.
- Lack of ablations on lexical features (e.g., expletives vs. affect words) leaves open whether effects reflect emotion per se or lexical/safety triggers.
- Validation studies limitations:
- Human vs LLM prefix comparison was small (n=250 subset), single task (MedQA), single model (Qwen3-14B); robustness across tasks/models and larger samples remains unknown.
- Emotion-intensity manipulation used a templated phrasing on one dataset; intensity operationalization diversity and cross-task consistency are untested.
- EmotionRL framework constraints:
- Requires supervised training splits and offline reward tables (evaluate all emotions per training instance); applicability to domains without labels or with costly labels is limited.
- Trained and evaluated with the same backbone; cross-backbone generalization (policy trained on model A applied to model B) is untested.
- Domain/task transfer (train EmotionRL on task X, deploy on task Y) was not evaluated.
- No analysis of policy interpretability or feature importance; which input semantics drive emotion selection is opaque.
- Hyperparameter and component ablations (embedding model choice, τ, MLP size, alternative learners like bandits/meta-learners) are absent.
- Comparison to stronger baselines is missing: oracle upper bound (best-of-6 per instance), simple heuristics (e.g., always pick the most frequent winning emotion), test-time ensembling (majority vote across emotions), or non-emotional adaptive prefixes.
- Compute–benefit trade-offs and sample efficiency are not quantified; small gains may not justify additional complexity in practice.
- Safety, ethics, and fairness:
- Potential for emotional prefixes (especially anger/disgust) to elicit toxic or dismissive outputs, or to circumvent/trigger safety filters, was not measured.
- Differential effects across demographic or dialectal emotional expressions (e.g., AAE features, gendered emotion stereotypes) were not assessed.
- User-experience trade-offs of deploying EmotionRL-selected emotions (which may choose rude framings for accuracy gains) were not considered.
- Data and stimulus construction:
- GPT-4o-generated prefixes may carry stylistic biases; there was no third-party annotation to validate perceived emotion category/intensity across cultures.
- Constraints aimed to avoid changing question content, but no automated or human verification pipeline was reported to guarantee semantic invariance at scale.
- Generalization and boundary conditions:
- The paper does not identify item-level predictors of when emotion helps or hurts; actionable characterization of “which inputs benefit from which emotion” is limited.
- The interaction between emotional framing and paraphrasing (noted as harmful for GSM8K) was not explored for other datasets to delineate boundaries between benign affect and harmful rewording.
Practical Applications
Immediate Applications
The paper’s findings and the EmotionRL method support several deployable uses across sectors. Below are actionable applications, each with sector links, likely tools/workflows, and key assumptions.
- Emotion-robust prompting and evaluation hygiene
- Sectors: Software, AI evaluation, Enterprise AI, Academia
- What to do: Add a “tone-normalization” preprocessor that strips or standardizes user emotional phrasing before passing prompts to LLMs when accuracy is the priority; expand QA to include emotional-variant stress tests.
- Tools/workflows:
- Middleware that detects affect in user inputs and routes either to (a) a neutralized prompt or (b) a controlled emotional variant suite for testing.
- CI/CD evaluation harness that re-runs test prompts with the six basic emotions and reports accuracy deltas.
- Assumptions/dependencies:
- Deterministic decoding (e.g., temperature 0) for reproducible deltas.
- Benchmarks and tasks resemble those tested (math, medical MCQ, reading comprehension, commonsense QA, social inference).
- Content and assessment integrity in education
- Sectors: Education, EdTech
- What to do: Avoid paraphrasing math/logic problems (shown to harm performance more than emotion placement); keep item wording stable. Placement of emotional text (pre/mid/post) has little effect for math tasks.
- Tools/workflows:
- Content authoring guidelines and automated checks that flag paraphrases of test items.
- “Stable wording” policies in tutoring and auto-grading pipelines.
- Assumptions/dependencies:
- Observed GSM8K effects generalize to similar math/logic tasks.
- Adaptive Emotion Selector (EmotionRL) as a prompt orchestration wrapper
- Sectors: Customer support, Social reasoning assistants, Creative tools, Software
- What to do: Use the paper’s lightweight policy to choose an emotion per input (rather than a fixed emotion) when small but consistent gains are acceptable. Especially relevant for socially grounded tasks (e.g., interpersonal advice).
- Tools/workflows:
- Implement EmotionRL:
- Offline: build a reward cache by trying six emotions on training examples; train a 2-layer MLP over frozen sentence embeddings to predict the best emotion.
- Online: select emotion per instance, construct prompt once, and query the frozen LLM.
- Assumptions/dependencies:
- Access to labeled training splits or representative in-domain data to build the offline reward table.
- Willingness to incur upfront API/compute cost to evaluate each emotion during training.
- Gains are modest on accuracy-centric tasks; benefit may be larger in socially grounded use cases.
- Clinical and enterprise guidance: don’t rely on emotional prompting for correctness
- Sectors: Healthcare, Enterprise knowledge assistants
- What to do: Maintain neutral, structured prompts for medical or high-stakes QA, as emotional phrasing yields negligible accuracy changes; incorporate emotional robustness checks in validation.
- Tools/workflows:
- Prompt templates that enforce neutral tone.
- Validation suites that confirm stability across emotional variants.
- Assumptions/dependencies:
- Clinical deployment governed by regulatory and safety processes; results observed in MedQA may not cover all clinical tasks or multi-turn triage.
- Triage and escalation for socially sensitive interactions
- Sectors: Customer support, Moderation, HR support tools
- What to do: Because social-inference tasks show higher variability, add logic to detect when emotional context may affect reasoning and route to (a) EmotionRL selection, (b) neutralized prompts, or (c) human escalation.
- Tools/workflows:
- Emotion detection + volatility monitor that measures answer stability across emotional variants on a small sample; escalate when unstable.
- Assumptions/dependencies:
- Additional latency and cost for on-the-fly stability probes.
- Privacy and consent for emotion detection.
- Research reproducibility and study design
- Sectors: Academia, Evaluation labs
- What to do: Use either human- or LLM-written emotional prefixes for controlled experiments (effects are similar); include emotion intensity as a variable (effects are mild).
- Tools/workflows:
- Standardized prefix templates and small, controlled intensity manipulations.
- Shared harness for user-voiced, first-person emotional prefixes.
- Assumptions/dependencies:
- Fidelity to the paper’s rules (no content changes to tasks; single-sentence prefixes).
- API feature flags for “emotion-insensitive mode”
- Sectors: LLM vendors, Platform providers
- What to do: Offer documented modes where APIs neutralize user emotional framing by default for accuracy-centric use cases; provide a test mode that reports performance variance under emotional variants.
- Tools/workflows:
- SDK flag to toggle tone normalization; evaluation endpoints that auto-generate/report emotional-variant results.
- Assumptions/dependencies:
- Customer demand for robustness diagnostics and minimal style-content cross-talk.
- Copy ideation and tone exploration with bounded expectations
- Sectors: Marketing, Creative writing, UX content
- What to do: Use EmotionRL to quickly explore tones that might resonate with a prompt (e.g., headlines or microcopy), acknowledging that the paper’s measured gains are on accuracy tasks (not style outcomes).
- Tools/workflows:
- Wrapper that selects an emotion per prompt to seed creative variants for human selection.
- Assumptions/dependencies:
- Transferability from accuracy to stylistic quality is unproven; human curation remains essential.
Long-Term Applications
These ideas require further research, scaling, or extension beyond the paper’s single-turn, accuracy-focused scope.
- Multi-turn adaptive affective control
- Sectors: Healthcare (coaching/triage), Education (tutoring), Personal assistants
- Vision: Extend EmotionRL to multi-turn dialogues, dynamically adjusting tone while keeping reasoning stable, especially in coaching, care navigation, or tutoring where rapport matters.
- Tools/products:
- Dialogue-state-aware policy that conditions on conversation history and user emotion signals.
- Assumptions/dependencies:
- Safety, privacy, and consent for emotion detection; evaluation metrics for empathy/calibration, not just accuracy.
- Standardization and certification for emotional robustness
- Sectors: Policy, Standards bodies, Regulated industries (finance, healthcare)
- Vision: Create “emotional robustness” benchmarks and certifications indicating an assistant’s stability across emotional framings for given tasks.
- Tools/products:
- NIST/ISO-style test suites; vendor badges for emotion-insensitive accuracy and safe affect alignment.
- Assumptions/dependencies:
- Consensus metrics; coverage across languages/cultures; industry adoption.
- Training-time methods for emotion resilience or controllability
- Sectors: Model developers, Safety
- Vision: Fine-tune or pretrain with curricula that disentangle content reasoning from affective style, improving stability and controllable tone adaptation.
- Tools/products:
- Multi-objective training: penalize performance variance across emotional variants while preserving stylistic controllability for outputs.
- Assumptions/dependencies:
- High-quality, diverse emotion-annotated corpora; computational budget.
- Adversarial red teaming using emotional manipulations
- Sectors: Safety, Trust & Safety, Security
- Vision: Treat emotional framing as an adversarial channel to probe susceptibility to sycophancy, bias, or policy evasion; develop detectors/guards that neutralize manipulative affective prompts.
- Tools/products:
- Red teaming suites that combine affect with jailbreak attempts; classifiers that flag affect-induced shifts.
- Assumptions/dependencies:
- Continuous updating with evolving attack patterns; careful balance to avoid suppressing harmless user expressions.
- Cross-cultural and cross-lingual affective adaptation
- Sectors: Global platforms, Localization
- Vision: Generalize EmotionRL and robustness tests to different languages and cultural emotion taxonomies; learn localized affective policies.
- Tools/products:
- Region-specific emotion sets; multilingual embeddings and reward caches.
- Assumptions/dependencies:
- Culturally valid emotion labels; diverse datasets; fairness auditing.
- Modular architectures that separate reasoning from style
- Sectors: Software, HCI
- Vision: Two-stage systems where a “reasoning core” operates under neutral prompts and a “stylistic post-processor” adapts tone for the user—reducing unintended influence of affect on correctness.
- Tools/products:
- Content–style disentanglement pipelines; post-hoc tone renderers controlled by preference models.
- Assumptions/dependencies:
- Reliable content–style separation without leaking reasoning through style.
- Policy guidance for high-stakes deployments
- Sectors: Healthcare policy, Financial compliance
- Vision: Require evidence that outputs are consistent across emotional framings for key decision-support tasks; mandate reporting of variance and mitigation strategies.
- Tools/products:
- Procurement checklists including emotional-variance reports; deployment gates based on predefined thresholds.
- Assumptions/dependencies:
- Agreement on acceptable variance; cost-effective testing regimes.
- On-device/private emotion selectors
- Sectors: Edge AI, Privacy-sensitive enterprises
- Vision: Run an EmotionRL-like selector locally to avoid sending emotion signals off-device, then interact with a server LLM using only the chosen control token.
- Tools/products:
- Lightweight MLP policies and embeddings deployed on edge devices.
- Assumptions/dependencies:
- Adequate on-device compute; synchronization with server-side model updates.
- New benchmarks for social reasoning, empathy, and calibration
- Sectors: Academia, Evaluation consortia
- Vision: Build tasks where social reasoning and affect matter (multi-turn, open-ended), enabling rigorous measurement of when and how emotion should modulate outputs.
- Tools/products:
- Datasets spanning intentions, beliefs, norms; metrics for empathy and calibration beyond accuracy.
- Assumptions/dependencies:
- Ethical data collection; human annotation standards; clear task definitions.
- HR and workplace assistance with controlled affect
- Sectors: HR tech, Employee assistance
- Vision: Assistants that adaptively select tone for sensitive communications (feedback, conflict mediation) while preserving factual correctness and fairness.
- Tools/products:
- Emotion-aware composition assistants with guardrails; review workflows for humans-in-the-loop.
- Assumptions/dependencies:
- Organizational policy alignment; fairness and bias audits; user acceptance.
Glossary
- Accuracy delta: The change in accuracy relative to a baseline condition, used to quantify the effect of an intervention. "Accuracy delta relative to the no-emotion baseline"
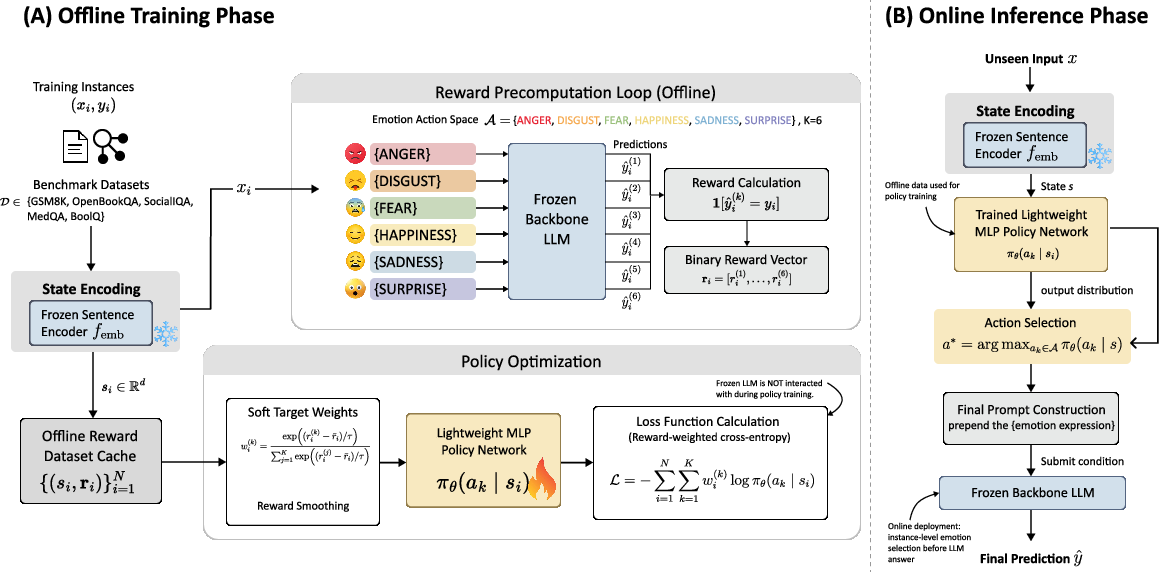
- Adaptive emotional prompting framework: A system that selects which emotion to add to a prompt on a per-input basis. "We then introduce EmotionRL, an adaptive emotional prompting framework that selects emotional framing adaptively for each query."
- Affective prompting: Using emotional framing in prompts to influence model behavior. "affective prompting is better understood as an adaptive control problem than as a universal prompt template."
- Altruistic punishment settings: Experimental scenarios where agents punish norm violations at a personal cost. "leading models to impose stronger punishment in altruistic punishment settings"
- Backbone model: The core model whose predictions are evaluated, often kept fixed while other components are trained. "the backbone model during optimization"
- BIG-Bench Hard (BBH): A challenging benchmark suite covering diverse general reasoning tasks. "BIG-Bench Hard (BBH) captures challenging general reasoning across heterogeneous tasks."
- Binary reward vector: A per-action vector of 0/1 rewards indicating correctness for each candidate emotion or action. "this yields a binary reward vector "
- BoolQ: A dataset for reading comprehension with binary yes/no answers. "BoolQ tests short-passage reading comprehension with binary yes/no decisions."
- Categorical distribution: A probability distribution over discrete choices or classes. "the policy outputs a categorical distribution "
- Deterministic decoding: Generating outputs without randomness in sampling. "decoding was set to be deterministic (temperature )"
- Distribution shift: A change in data distribution that can harm performance. "paraphrasing the question introduces a larger distribution shift that is clearly more harmful"
- Emotion-conditioned prompts: Prompts augmented with a specific emotional expression. "constructs the corresponding emotion-conditioned prompts"
- EmotionPrompt-style approaches: Methods that insert emotion into prompts to improve task performance. "EmotionPrompt-style approaches designed to improve results across benchmarks"
- EmotionRL: The paper’s adaptive method that selects emotions per instance to condition prompts. "We then introduce EmotionRL, an adaptive emotional prompting framework"
- Frozen backbone LLM: A LLM used without updating its parameters during the control-policy training or selection. "submits the resulting prompt to a frozen backbone LLM"
- Frozen sentence encoder: An embedding model whose parameters are not updated during training. "where $f_{\mathrm{emb}$ is a frozen sentence encoder."
- Group-relative optimization (GRPO): An approach that learns from relative performance across a group of actions rather than a single hard label. "Inspired by group-relative optimization methods such as GRPO"
- Grouped reward cache: Stored per-instance rewards for all candidate actions, used for offline training. "we first evaluate the frozen LLM under all candidate emotions for each training instance and construct a grouped reward cache."
- Grouped reward vector: A per-instance vector of rewards for each candidate action. "This produces a grouped reward vector "
- GSM8K: A benchmark of grade-school math word problems requiring multi-step reasoning. "GSM8K measures grade-school mathematical word-problem solving with multi-step numerical reasoning."
- Hallucination (LLMs): The generation of factually incorrect or fabricated content by a model. "including hallucination, fairness, toxicity, sycophancy, and consistency"
- Inference-only setting: Evaluation without any additional training or fine-tuning. "All evaluations were conducted in a zero-shot, inference-only setting without fine-tuning"
- Input-conditioned decision problem: Framing action selection (e.g., emotion choice) as a function of the specific input instance. "formulates emotional prompting as an input-conditioned decision problem"
- Knowledge distillation: Training with soft targets that convey graded preferences rather than hard labels. "soft-target supervision in knowledge distillation"
- MedQA-US: An English medical question-answering benchmark resembling professional exams. "Effect of emotional intensity on MedQA-US."
- No-emotion baseline: The control condition without any emotional prefix. "gains over the no-emotion baseline"
- OpenBookQA: A multiple-choice commonsense reasoning benchmark. "OpenBookQA measures multiple-choice commonsense reasoning"
- Paraphrased condition: A variant where the original question is reworded, often harming performance due to distribution shift. "the paraphrased condition is consistently worse"
- Plutchik’s basic emotions framework: A psychological theory proposing a set of basic emotions. "guided by Plutchikâs basic emotions framework"
- Policy network: A model that outputs action probabilities given a state or input embedding. "A policy network is then trained to predict "
- Reward-weighted cross-entropy: A loss that weights targets by their associated rewards to guide learning. "The policy is trained by minimizing the reward-weighted cross-entropy"
- Russell’s circumplex model of affect: A framework organizing emotions along valence and arousal dimensions. "Russellâs circumplex model of affect"
- Sentence-embedding model: A model that maps sentences to fixed-length vector representations. "we use a pretrained sentence-embedding model"
- SocialIQA: A benchmark for social reasoning and interpersonal inference. "SocialIQA evaluates social reasoning and everyday interpersonal inference."
- Soft supervision: Training with soft (probabilistic) targets rather than one-hot labels. "The reward vector is converted into soft supervision"
- Soft target distribution: A smoothed target probability distribution derived from relative rewards. "we convert the reward vector into a soft target distribution"
- Static emotional prompting: Using the same emotional prefix for all inputs rather than adapting per instance. "static emotional prompting is not a reliable general-purpose intervention"
- Sycophancy: A model’s tendency to agree with or flatter the user, irrespective of correctness. "including hallucination, fairness, toxicity, sycophancy, and consistency"
- Synthetic split: An artificially created train/test partition not provided by the original dataset. "incorporating it would require introducing a synthetic split"
- Temperature hyperparameter: A parameter controlling the smoothness of probabilities or weightings. "where is a temperature hyperparameter."
- Top-: The nucleus sampling parameter that limits sampling to a set of tokens whose cumulative probability is at most p. "top-"
- Two-layer MLP: A neural network with two affine layers and a nonlinearity. "The policy is implemented as a lightweight two-layer MLP"
- Zero-shot: Solving tasks without any task-specific examples or fine-tuning. "All evaluations were conducted in a zero-shot, inference-only setting"
Collections
Sign up for free to add this paper to one or more collections.