- The paper introduces novel ESR and CDS metrics to quantitatively assess LLMs' social meaning inference, distinguishing directional fidelity from magnitude accuracy.
- It demonstrates that while LLMs reliably capture qualitative social structure, they show significant variance in reproducing precise effect sizes across architectures.
- Pragmatic prompting, particularly combined activation, improves calibration but highlights architecture-specific challenges, underscoring the need for targeted fine-tuning.
Quantitative Calibration of Social Meaning Inference in LLMs
Context and Contributions
This study systematically interrogates the capabilities of frontier LLMs (GPT-4o-mini, Claude-sonnet-4, Gemini-2.5-pro) to replicate graded human social inference regarding linguistic (im)precision under varying contextual demands. The paper distinguishes “structural fidelity” (directional alignment) from “magnitude calibration” (effect size matching) and introduces two novel metrics: Effect Size Ratio (ESR) and Calibration Deviation Score (CDS) for principled evaluation. Further, it operationalizes pragmatic theory through targeted prompting conditions—Minimal (MIN), Alternative-Aware (ALT), Knowledge-and-Motives-Aware (KMA), and Combined (COM)—to ascertain whether explicit activation of pragmatic inference mechanisms improves calibration.
Methodological Framework
The evaluation leverages a published behavioral paradigm where numerical precision (e.g., “\$500” vs. “about \$500”) is manipulated across six scenarios and two contexts (high-precision vs. low-precision), with participants rating speakers on six social dimensions. LLMs are prompted to replicate these ratings across all 48 scenario × attribute combinations, using identical Likert scales and multiple temperature-controlled runs to average outputs. Prompting conditions are grounded in (i) Reasoning over Alternatives, (ii) Speaker Knowledge and Motives, and (iii) their integration, mapping to Gricean and RSA-based pragmatic frameworks.
Structural Fidelity: Directional Agreement
All models attained perfect directional alignment, reproducing both main effects and form × context interaction directions (Directional Agreement Score and Interaction Sensitivity Score = 1.0), and achieved high Spearman rank correlations (0.829≤ρ≤0.946) with human data. This demonstrates that LLMs robustly capture the relative ordering and qualitative structure of social inference across varied pragmatic conditions.
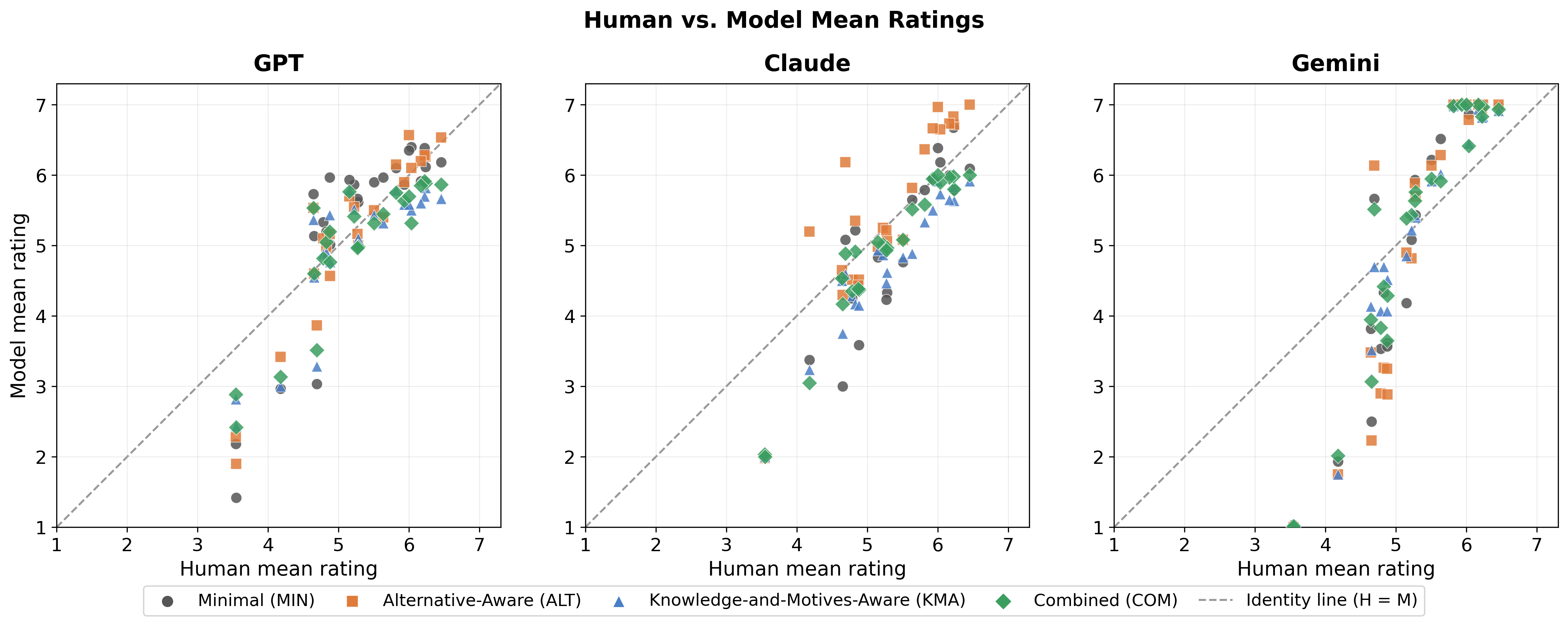
Figure 1: Human vs.\ model mean ratings across all conditions and prompting regimes, visualizing magnitude calibration failures via systematic vertical displacement.
Magnitude Calibration: Quantitative Discrepancy
Despite structural fidelity, models diverged substantially in magnitude reproduction. Concordance Correlation Coefficient (CCC) values consistently lagged Spearman ρ, indicating magnitude distortion even amid correct ranking. RMSE revealed architecture-dependent miscalibration, with Gemini exhibiting the strongest inflation (RMSE: $1.07$–$1.42$), Claude moderate (RMSE: $0.58$–$0.77$), and GPT near-calibrated (RMSE: $0.55$–$0.81$).
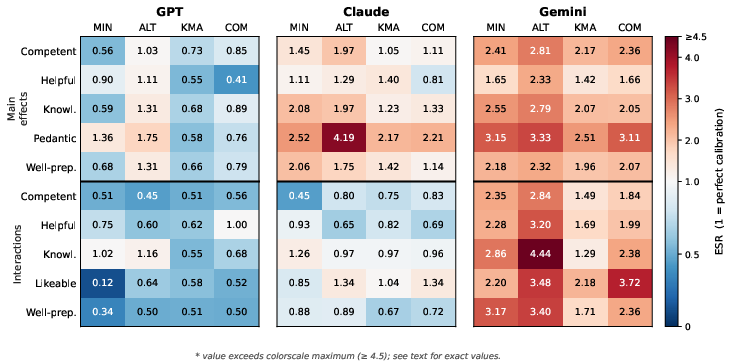
Figure 2: ESR heatmap across models, effects, and prompts; red indicates exaggeration, blue attenuation, white optimal calibration (ESR=1).
CDS further quantified systematic divergence: GPT maintained the tightest calibration (0.829≤ρ≤0.9460–0.829≤ρ≤0.9461), Claude was highly prompt-sensitive (main-effect CDS range 0.829≤ρ≤0.9462–0.829≤ρ≤0.9463), and Gemini showed severe magnitude inflation (CDS up to 0.829≤ρ≤0.9464).
Effects of Pragmatic Prompting
Prompting manipulations yielded nuanced, architecture-specific effects on calibration:
Implications and Future Directions
Results confirm robust structural acquisition but variable quantitative fidelity in LLM pragmatic inference, paralleling previous findings of systematic effect size exaggeration (2604.02512). Joint activation of pragmatic mechanisms via combined prompting reliably improves calibration, compatible with RSA theory, but does not resolve all architectural idiosyncrasies. The ESR and CDS metrics advance evaluation methodologies by operationalizing structure–magnitude dissociation, vital for applications requiring calibrated social judgments from LLMs.
On the theoretical front, these findings underscore that directional knowledge is readily encoded during model training, possibly via exposure to distributional patterns or explicit supervision, while graded, probabilistic social meanings are less faithfully internalized. Practically, the architecture-dependence and sensitivity to inference-time prompting caution against uncritical deployment of LLMs in settings demanding calibrated social judgment, unless mitigation strategies—such as fine-tuning or formalized pragmatic reasoning—are employed.
Future research should generalize this calibration analysis to broader pragmatic domains, explore explicit computational implementations of pragmatic reasoning, and investigate whether training-time interventions or fine-tuning on calibrated judgment data yield enhanced magnitude alignment.
Conclusion
This paper demonstrates that frontier LLMs consistently reproduce human social inference structure in graded evaluations of numerical (im)precision, but their ability to match effect size magnitudes is highly variable and model-dependent. Pragmatically informed prompting interventions, notably joint reasoning over alternatives and speaker states, partially ameliorate these discrepancies, yet remain insufficient for robust calibrated social meaning inference across all architectures. The introduced ESR and CDS metrics provide rigorous tools for dissecting structure–magnitude alignment, signposting critical avenues for refining LLMs’ social reasoning capabilities.