- The paper demonstrates that probability-weighted pointwise prompting and data-efficient finetuning yield high Spearman’s ρ and low RMSE in measuring latent constructs.
- It finds that LLM outputs exhibit distributional heaping and calibration issues, necessitating careful prompt design and confidence weighting.
- The study compares methodologies, revealing that properly calibrated LLMs can sometimes surpass traditional human pairwise annotations in reliability.
Measuring Scalar Constructs in Social Science with LLMs: An Expert Analysis
Introduction and Problem Setting
The paper "Measuring Scalar Constructs in Social Science with LLMs" (2509.03116) systematically investigates strategies for scoring continuous-valued (scalar) constructs in social science texts using LLMs. Many constructs such as sentiment intensity, emotionality, or the degree of rhetorical grandstanding are not categorically defined but exist on latent continua, motivating the need for scalar measurement. Traditional approaches include bag-of-words regression, latent variable models, and human annotation—either pointwise (absolute scoring) or pairwise (relative ranking). The rise of LLMs has enabled new, highly data-efficient approaches, but a significant open question concerns the reliability, calibration, and optimal extraction of scalar estimates from LLMs.
The study benchmarks four methodologies: unweighted pointwise prompting, aggregation of pairwise comparisons, token-probability-weighted pointwise scoring, and finetuning on labeled data. The empirical evaluation spans three political science datasets measuring constructs such as immigration-related fear, campaign ad negativity, and grandstanding in legislative speech. The focus is on the reliability of model-based scalar measurement, comparison to human references, and implications for computational social science.
Distributional and Calibration Pathologies in Zero-shot Pointwise LLM Scoring
A critical empirical finding is that, when prompted to assign pointwise scalar scores (e.g., 1–9) to social science texts, LLMs systematically deviate from the reference human-inferred distribution. LLMs exhibit strong "heaping" phenomena: their output distributions are bunched around a subset of possible outputs, influenced by both scale choice and model-specific tokenization biases. For example, Llama-3.3-70B models concentrate responses on extreme categories, and Qwen variants display right-skewed outputs. These deviations persist despite detailed prompts and are not resolved by simple output calibration.
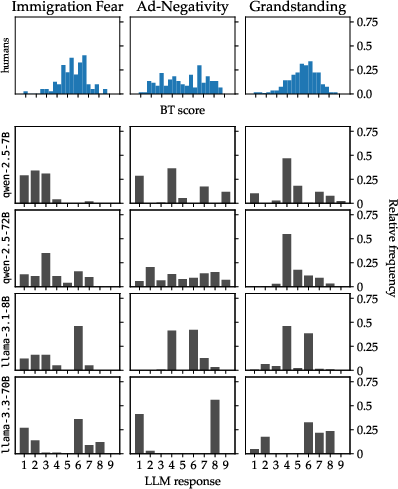
Figure 1: Distributions of LLM scores for scalar constructs display severe misalignment and idiosyncrasy across models, contrasting sharply with reference distributions derived from human pairwise judgments.
Crucially, even within the same model family, agreement about item-level scalar labeling (measured via Krippendorff's alpha) is often moderate at best. This inter-model variability compromises LLM-based construct validity in applied settings.
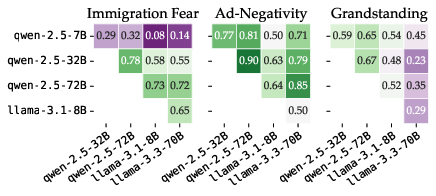
Figure 2: Inter-model agreement on pointwise scalar prediction remains low—even within model families and across datasets—highlighting issues of reliability and transferability in zero-shot prompting.
Further analysis demonstrates that LLMs' prediction confidences (the sum of relevant token probabilities) exhibit high entropy and are not consistent across model variants or prompting strategies. As a result, downstream statistics such as probability-weighted averages can still reflect original heaping or fail to adequately smooth and calibrate the predictions, especially for high-parameter models.
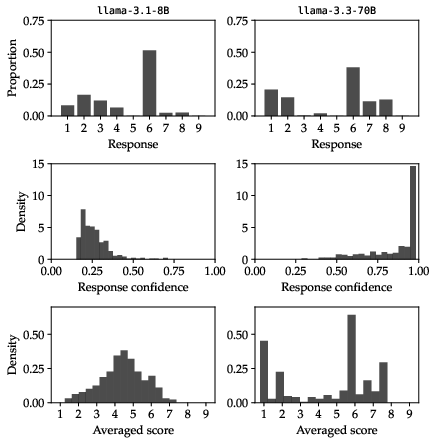
Figure 3: Modal responses, prediction confidences, and probability-weighted averages for pointwise scoring highlight that model size and variant significantly affect the degree of output concentration and smoothing.
Methodological Alternatives: Pairwise Comparison and Finetuning
The paper evaluates pairwise comparison as a measurement alternative, implemented by prompting LLMs to choose between two texts with respect to the intensity of a given construct. Aggregating results via the Bradley-Terry model yields latent item scores, mimicking best practice in human annotation. This approach, however, incurs quadratic cost in the number of items, and its benefit for LLM annotation is shown to be context-dependent.

Figure 4: Illustration of the pairwise comparison protocol, in which models or annotators express relative judgments between item pairs.
An additional approach involves finetuning smaller, open-source models (e.g., DeBERTa-v3-large, ModernBERT-large) via reward modeling or regression, using limited annotated data. Reward modeling leverages pairwise preference data with negative log-likelihood on Bradley-Terry-induced probability, making fine-tuned models efficient at inference.
Comparative Empirics: Strong Results, Contradictions, and Recommendations
A comprehensive suite of experiments assesses pointwise prompting, pairwise comparison, and finetuning across all datasets, measuring both ranking (Spearman's ρ) and error magnitude (RMSE) against reference human BT scores.
Key findings include:
- Token-probability-weighted pointwise scores consistently match or surpass pairwise comparison when using few-shot prompting, particularly with larger LLMs.
- 5-shot prompting with random exemplars yields substantial performance gains, especially for smaller models and more complex constructs.
- Pairwise prompting does not outperform pointwise token-probability weighting in the LLM setting, a finding that contradicts robust advantages of pairwise over pointwise annotation when using humans.
In terms of empirical results, top-performing LLMs (e.g., Qwen-2.5-72B for Negativity and Immigration Fear, Llama-3.3-70B for Grandstanding) achieve test set pairwise classification accuracy up to 0.81, Spearman’s ρ up to 0.92, and RMSE values as low as 0.13 (normalized scale). These values indicate very high model–reference correspondence, comparable or superior to inter-annotator agreement in the source data.
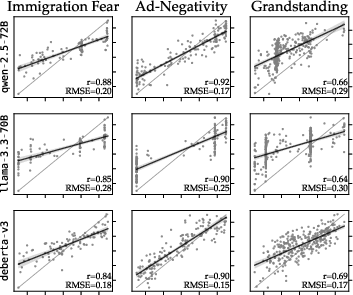
Figure 5: Scatterplots of model-predicted versus ground-truth BT scores show that both error magnitude and rank correlation must be considered in scoring model selection; models with high ρ can still display high RMSE due to prediction heaping.
The analysis demonstrates that correlation metrics alone are insufficient: models with similar rank correlation can differ substantially in error variance and distributional coverage, as highlighted by RMSE.
An additional critical finding is that finetuning even relatively small models with as few as 1,000 annotated pairs can equal or outperform few-shot-prompted billion-parameter LLMs, especially for variance reduction and robust recovery of distances between items. Regression-based finetuning, in contrast to reward modeling, is less data-efficient and yields less stable performance, especially in small data regimes.
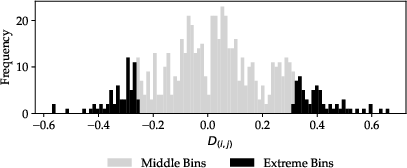
Figure 6: (Not shown here) Distributional comparison of disagreements between LLM-predicted rankings and human-induced latent scale differences indicates the specific nature and direction of errors.
Furthermore, when presented with pairs where LLM and human-based rankings disagree, blind human re-annotation tends more often to substantiate the LLM-induced ranking than to agree with the original BT outcome. This raises critical questions about which annotation paradigm should be considered ground truth.
Data Efficiency and Model Selection
The results regarding label efficiency are nontrivial: among DeBERTa-v3-large, Llama-3.1-8B, and ModernBERT-large, competitive performance is achieved with O(103) pairwise annotations. This finding is highly actionable for social science researchers managing annotation budgets.
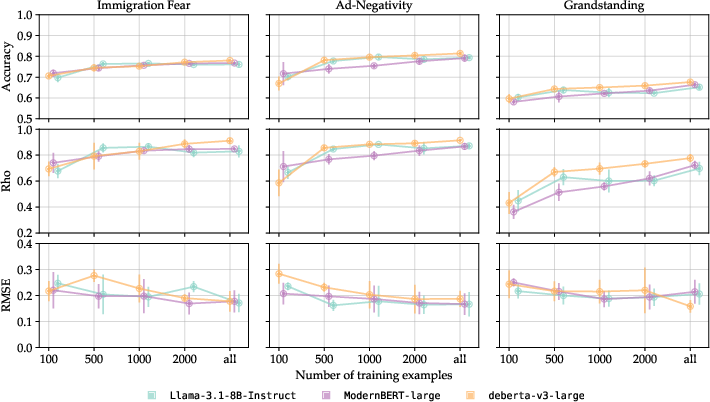
Figure 7: Classification and scoring performance as a function of training set size reveal rapid convergence, with diminishing returns beyond approximately 2,000 training examples.
Practical and Theoretical Implications
The findings have direct implications for computational social science and methodology. The fact that LLMs' pointwise outputs are distributionally idiosyncratic and poorly calibrated, subject to both prompt phrasing and model architecture, necessitates probability weighting and test-time calibration to recover reliable scalar measurements. Simple modal scoring, or reliance on zero-shot outputs, cannot be recommended.
The lack of clear benefit from pairwise prompting, in contrast to the superiority of pairwise annotation with humans, delimits the transferability of standard psychometric annotation paradigms to LLMs. Model selection for scalar construct measurement should jointly consider ranking and error metrics, as agreement in item order does not ensure fidelity in estimated construct distances or distributional form.
For practitioners, pairwise or regression-based model finetuning provides a robust, compute-efficient alternative when labeled data is obtainable. Given the result that small models can close the gap to much larger prompted LLMs, investment in domain-specific annotation is strongly justified.
Fundamentally, the results suggest that while LLMs can replicate or even surpass human annotator reliability in scalar construct measurement tasks, the operational protocol has substantial effects. There is also non-trivial evidence that LLMs, when probability-weighted, may better capture collective intuition about construct intensity than the aggregate of sparse human pairwise annotations—a claim requiring further investigation but with profound implications for standards of ground truth.
Conclusion
This study demonstrates that, for practical and theoretical measurement of scalar constructs with LLMs in the social sciences, probability-weighted pointwise prompting in a few-shot setting and data-efficient finetuning are the methods of choice. Pairwise comparisons, while robust for human annotation, do not confer consistent benefits when applied to LLMs in the prompting regime. Critically, error analyses and comparison to human ground truth indicate that current LLMs—appropriately queried and calibrated—are ready for challenging social measurement tasks, but careful attention must be paid to prompt design, model selection, calibration strategy, and ground-truth reference construction.
The methodological insights of this paper point to new directions in scalable, reproducible measurement of latent constructs, raise foundational questions about annotation epistemology, and offer robust recommendations for applied researchers in computational social science and beyond.