- The paper introduces a per-head, Fisher-weighted SVD that minimizes reconstruction loss while preserving key weights in low-precision VLMs.
- It employs local quantization-aware training with a fused kernel implementation to significantly reduce KV reconstruction overhead and decoding latency.
- Empirical results show 1.8x to 2.6x speedups on consumer GPUs and maintained or improved accuracy even under aggressive compression.
Weighted Low-Rank Approximation for Fast and Efficient Vision-LLM Execution
Introduction
The "WSVD: Weighted Low-Rank Approximation for Fast and Efficient Execution of Low-Precision Vision-LLMs" paper (2604.02570) addresses the performance bottlenecks endemic to modern vision-LLMs (VLMs) during inference, especially in autoregressive decoding. Standard approaches that utilize singular value decomposition (SVD) for parameter compression do not always yield real-world latency improvements, as the cost of reconstructing key and value matrices (KV) from low-rank latents during the decoding stage is substantial. WSVD introduces a per-head, importance-weighted, low-rank SVD framework augmented by local quantization-aware training and a system-level fused kernel implementation. This method is empirically validated to substantially decrease decoding latency while maintaining or in some cases surpassing original model accuracy, even under aggressive quantization and compression.
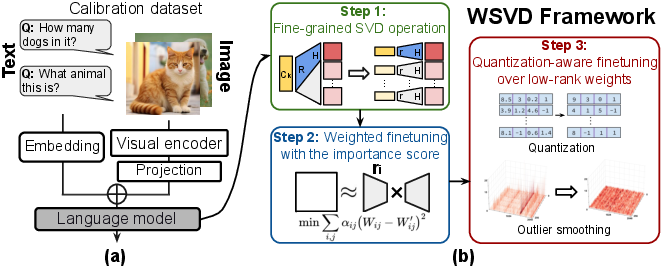
Figure 1: (a) General VLM architecture combining visual and textual tokens for generation tasks. (b) Overview of the WSVD framework integrating per-head SVD, weighted fine-tuning, and quantization.
Methodology
WSVD consists of three integrated technical advancements:
- Per-Head SVD Decomposition: Unlike approaches applying SVD on the full QKV projection matrices, WSVD factorizes each attention head's key and value projections independently. This fine granularity eliminates the need for reconstructing large shared KV matrices per token, reducing memory traffic and accelerating decoding, particularly for long contexts.
- Weighted SVD via Local Fisher Information: Recognizing that individual weight elements exhibit different sensitivity levels, WSVD incorporates Fisher information-based importance scores into SVD fine-tuning. The decomposition explicitly minimizes a Fisher-weighted reconstruction loss, ensuring that high-importance weights are preserved, thus mitigating accuracy degradation typically associated with aggressive low-rank truncation.
- Local Quantization-Aware Training (QAT): WSVD employs quantization on both latents and projection matrices, leveraging orthogonal channel rotations (e.g., Hadamard transformation) to redistribute and absorb activation/weight outliers. A local QAT procedure is applied to further adapt the low-rank factors, guided by Fisher importance, to the anticipated quantization noise, recovering most quantization-induced accuracy loss with minimal update cost.

Figure 2: (a) Layer-wise latency of VLM SA and FFN modules. (b) Regular (full-matrix) SVD approach and its KV reconstruction (left: shared latent). (c) Per-head SVD in WSVD: head-specific latent with independent reconstruction and greatly reduced overhead.
This architectural strategy is supported by system-level implementation optimizations: the reconstruction of per-head KV tiles is fused, via custom Triton kernels, directly into the Flash Decoding pipeline. Latent tiles are streamed into on-chip memory, operated on without redundant VRAM writes, and directly consumed in attention computation, eradicating the traditional bottleneck from intermediate tensor materialization.
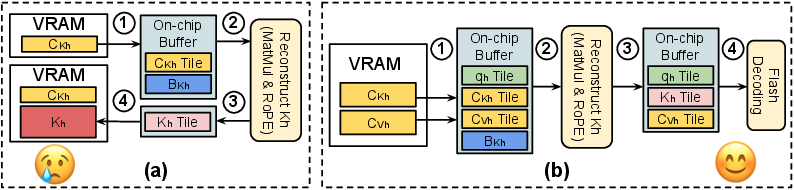
Figure 3: (a) Naive KV reconstruction requires full materialization and VRAM roundtrips. (b) WSVD’s fused kernel consumes per-head latents on-chip in a single pipeline, minimizing I/O and memory usage.
Results
Accuracy
Across multiple VLM architectures (LLaVA-v1.5 7B/13B/Next, SmolVLM, Qwen-VL, Molmo-7B-O), WSVD consistently matches or slightly outperforms both ASVD, SVD-LLM, QSVD, and more recent baselines at equivalent parameter and cache size ratios. Remarkably, at parameter ratio ρ1=70%, WSVD-noQ’s accuracy can exceed the FP16 baseline, providing evidence that fine-grained low-rank approximation may enhance robustness to hallucinations by denoising projections. Under quantization (W8A8 or W8A4), WSVD maintains only a modest drop (often <1% avg.) in task accuracy, outperforming QVLM, DuQuant, and QASVD using identical calibration procedures.
System Latency
Empirical system benchmarks on RTX 4090/5090/3060 reveal that WSVD achieves 1.8× to 2.6× speedups over mature Flash Decoding baselines for long-context decoding. Per-head SVD eliminates the full-matrix latent reconstruction and thus provides >14× speedup over low-rank approaches without this granularity. On consumer GPUs with constrained memory bandwidth, the efficiency gap over Flash Decoding further widens since memory I/O becomes dominant. WSVD’s QAT and headwise factorization translate rank and bit reductions directly into end-to-end acceleration.
Ablation and Analysis
- Local Weighted Finetuning: Explicitly optimizing decomposed factors with elementwise Fisher information significantly boosts post-SVD accuracy for a fixed compression ratio.
- QAT: Local adaptation during quantization systematically narrows the quantization gap, outperforming non-QAT variants in all evaluated settings.
- Scalability: Decoding efficiency gains increase with context length and batch size, as I/O savings from smaller KV caches become more material.
- Generalization: Identical compression calibrations show robust transfer across datasets (e.g., OCRBench, SEED-Bench, HRBench-4K), demonstrating WSVD’s dataset-agnostic applicability.
Practical and Theoretical Implications
WSVD establishes per-head, importance-aware SVD as a new standard for scalable VLM compression, compatible with advanced quantization and high-throughput inference. Practically, this enables real-time multimodal generation on consumer and edge hardware. By exposing the limitations of prior SVD paradigms in end-to-end latency—and providing an actionable, fused-kernel remedy, the paper reframes VLM compression as a full-stack synergy between algorithm, hardware, and memory pipeline. Theoretically, the combination of Fisher-weighted low-rank approximation and headwise factorization suggests new directions in structured matrix decomposition under quantization constraints, likely extensible to other classes of large generative models and custom accelerators.
Conclusion
WSVD demonstrates that per-head, Fisher-weighted SVD—combined with efficient local quantization-aware retraining and a system-level fused decoding kernel—yields substantial improvements in VLM execution efficiency with minimal or no impact on accuracy. The WSVD framework is widely applicable, generalizing across architectures and datasets, and fundamentally advances the deployment feasibility of large multimodal models in latency- and memory-bound environments.