- The paper introduces an activation-aware, closed-form low-rank compression framework that optimally compresses both static model weights and dynamic KV caches.
- It leverages a single eigen-decomposition and a dynamic rank allocation strategy to efficiently explore the trade-off between compression ratio and reconstruction error.
- Empirical evaluations show significant improvements in inference speed, memory reduction, and numerical stability over existing SVD-based compression methods.
Swift-SVD: Theoretical Optimality Meets Practical Efficiency in Low-Rank LLM Compression
Introduction and Motivation
LLMs present serious deployment bottlenecks related to the memory and bandwidth constraints of both static model parameters and dynamic Key-Value (KV) caches. This dual challenge is acute during large-scale auto-regressive inference, where model weights must reside in memory and the dynamic KV cache, which grows with sequence length, further exacerbates hardware pressure. SVD-based low-rank compression is attractive because it is training-free and compatible with prevalent hardware, but practical schemes are often fundamentally suboptimal in either their formulation or their implementation. Swift-SVD addresses these trade-offs, offering an activation-aware, closed-form low-rank compression framework that provides the theoretical optimum, efficient computation, and numerical stability—key requirements for practical large-scale compression.
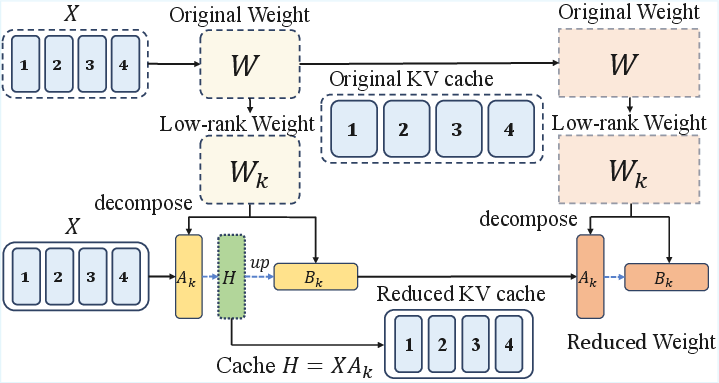
Figure 1: Swift-SVD compresses both static model weights and dynamic KV caches, directly reducing the memory footprint by leveraging efficient matrix factorization.
Methodology
Optimal Activation-Aware Low-Rank Decomposition
Swift-SVD redefines the low-rank approximation problem by minimizing the data-dependent Frobenius norm ∣∣XW−XWk∣∣F, where compression loss is measured with respect to the actual distribution of input activations. The authors derive a closed-form spectral solution: for a given set of activations X and a weight matrix W, the optimal compressed weight for rank k is Wk∗=WVkVkT, where Vk contains the top-k right singular vectors of the output Y=XW. The associated minimal loss is determined by the sum of the trailing singular values, leveraging the classic Eckart-Young-Mirsky theorem for optimality.
Crucially, Swift-SVD bypasses repeated SVDs and Cholesky/QR factorizations. Instead, it incrementally aggregates the empirical covariance matrix YTY over batched activations and performs a single eigen-decomposition to recover all optimal low-rank projections for a layer. This mechanism provides the entire Pareto frontier between compression ratio and reconstruction error in one computational pass.
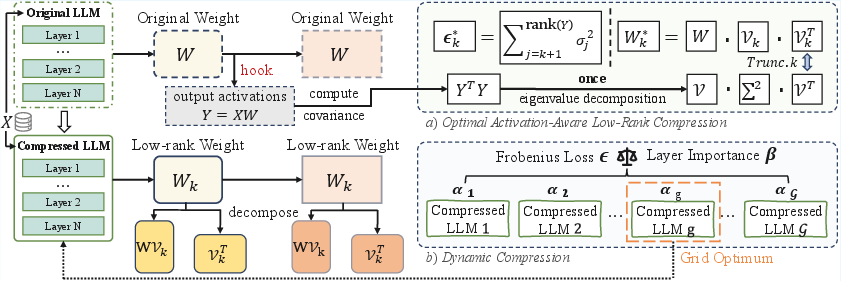
Figure 2: Overview of Swift-SVD: (a) Covariance accumulation and closed-form eigen-decomposition; (b) Search over dynamic compression schemes using precomputed loss spectra and layer importance.
Dynamic Rank Allocation
Model layers have non-uniform compressibility due to heterogeneous parameter and activation statistics. Uniform rank allocation underutilizes redundancy, while approaches using only reconstruction loss or only layer importance are brittle. The authors propose a joint allocation strategy, parametrized by a hyperparameter α that weights the influence of local Frobenius loss versus global layer importance scores. These importance scores are min-max normalized, and candidate rank allocations are generated by grid search over α. Lightweight validation identifies the configuration that offers minimal end-to-end degradation. Notably, unrestricted dynamic allocation without a preserved ratio X0 rapidly degrades performance by overcompressing critical modules; imposing a minimum preserved rank stabilizes compression and prevents catastrophic errors.
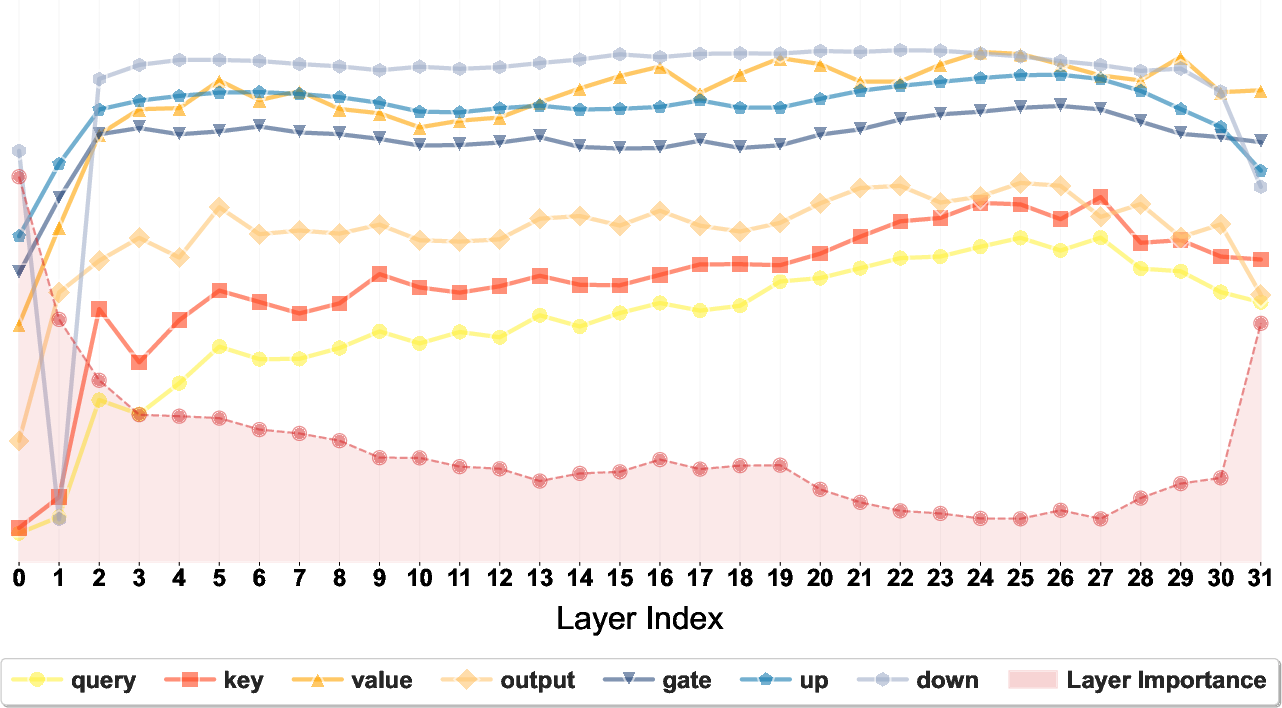
Figure 3: Layer-wise normalized effective rank (NER) and importance in Mistral-7B on C4; high negative correlation demonstrates the need for hybrid allocation strategies.
Empirical Evaluation
Swift-SVD is systematically benchmarked against FWSVD, ASVD, SVD-LLM variants, and Dobi-SVD across LLaMA, LLaMA2, OPT, Mistral, and Qwen3 models on language modeling (WikiText-2, C4, Alpaca) and zero-shot QA tasks. Swift-SVD consistently achieves lower perplexity and higher accuracy than baselines, especially under high compression ratios (e.g., 0.4), where prior dynamic allocation methods (Dobi-SVD) often hurt performance compared to uniform allocation. The approach is robust across model architectures and data domains and delivers consistent improvements via dynamic allocation (Swift-SVD*) over uniform schemes.
Computational and Inference Efficiency
The method provides substantial computational advantages. Since the full spectrum of rank-loss tradeoffs is computed in one eigen-decomposition per layer, Swift-SVD compresses models 3–70x faster than SVD-LLM and Dobi-SVD. Inference time and memory usage are drastically reduced; compressed weights and reduced KV-cache activations directly lower the HBM footprint, and throughput grows sublinearly as the compression ratio is tightened.
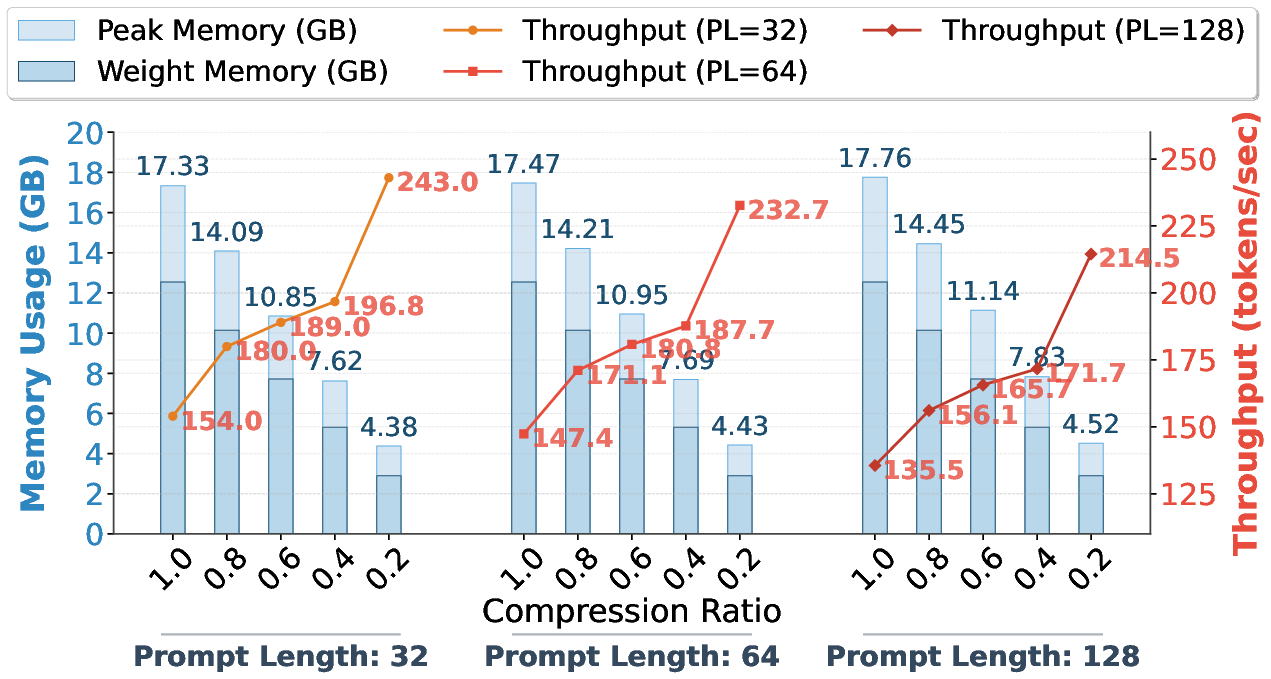
Figure 4: Tokens-per-second throughput and memory utilization under batch size 16 and sequence length 1024 are significantly improved due to aggressive low-rank approximation.
Numerical Stability
Benchmarks on random matrices show that SVD-LLM and Dobi-SVD, despite offering theoretical guarantees, suffer from non-trivial reconstruction errors due to numerical instability. Swift-SVD matches the theoretical minimum loss to machine precision across all tested matrix sizes, confirming its stability and robustness in practical deployment scenarios.
Spectral Analysis and Layer Importance
Singular value distributions for key and value matrices demonstrate extreme spectral gaps, invalidating strategies that rely solely on Frobenius norm minimization for rank allocation (as such heuristics systematically over-compress layers with smaller singular values). Effective rank is shown to be negatively correlated with layer importance, and optimal dynamic allocation must treat both sources of evidence.
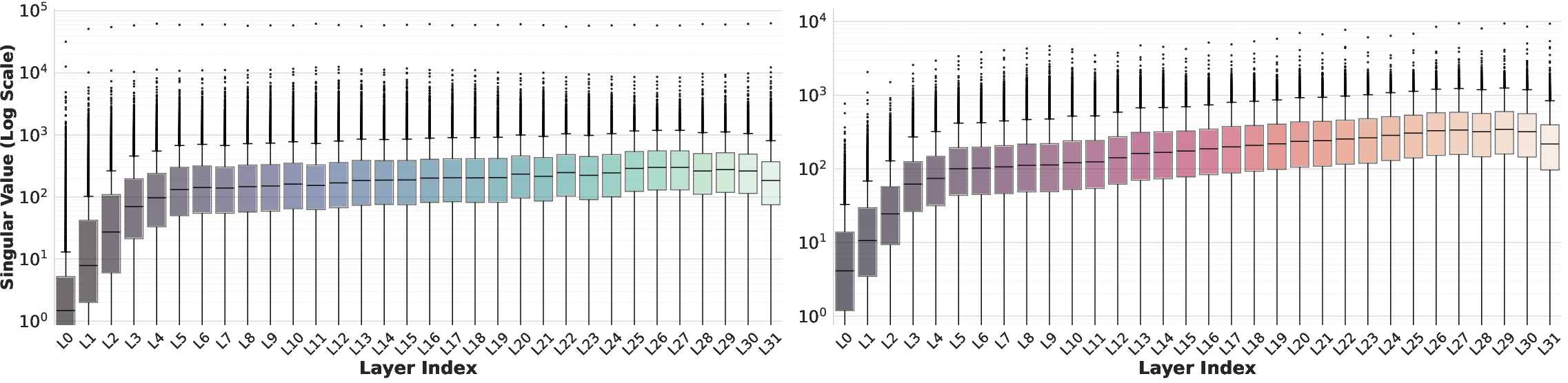
Figure 5: Key and Value matrices in LLaMA-7B show extreme singular value disparities, motivating careful joint loss/importance-based allocation.
Ablation and Hyperparameter Analysis
Unconstrained allocations based on only one metric (e.g., only importance or only local Frobenius loss) or too low a preserved ratio X1 destabilize the model. Applying a moderate fixed preserved ratio (e.g., X2) yields the best trade-off between aggressive redundancy exploitation and representational fidelity at critical layers. Ablations confirm that joint allocation with grid search over X3 outperforms all alternatives.
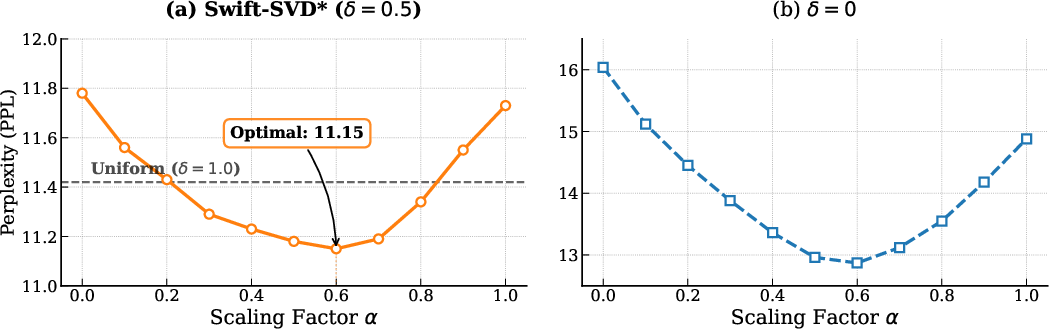
Figure 6: Both the scaling factor X4 and preserved ratio X5 induce non-monotonic, U-shaped performance (PPL) curves, pointing to the necessity of careful hyperparameter selection.
Implications and Future Directions
Swift-SVD unifies the theoretical guarantees of optimal SVD-based matrix approximation with empirical activation statistics, offering an efficient, robust and extensible solution for post-training LLM compression. The method is hardware-friendly, requires neither retraining nor surrogate gradient tuning, and generalizes to non-uniform and hybrid quantized settings. The tight connection between effective rank and layer importance demonstrated here has broad implications for future designs of dynamic, data-driven compression schemes. Future research may extend activation-aware compression to sequence-length-adaptive schemes, compositional compression regimes (e.g., integrating pruning and quantization with low-rank projections), and further exploit multi-modal activation statistics for even fine-grained per-task personalization.
Conclusion
Swift-SVD offers a practical and mathematically well-grounded solution to LLM compression, combining activation-aware closed-form SVD with a dynamic, importance- and loss-aware allocation strategy. The method simultaneously achieves optimal compression, high computational and inference efficiency, and robustness, significantly outperforming competitive SVD-based baselines in empirical evaluations, while also providing new insights into the interaction of spectral properties, intrinsic redundancy, and functional importance across model layers.
(2604.01609)