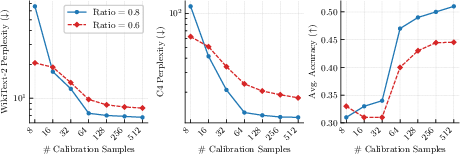
- The paper demonstrates that integrating anchored and adaptive SVD with block-level joint refinement significantly enhances LLM compression performance.
- It introduces a novel two-stage approach that minimizes output drift from distributional shifts, ensuring lower MSE and robust downstream accuracy.
- Empirical results on LLaMA and Qwen models show that AA-SVD outperforms traditional SVD methods by achieving superior perplexity and accuracy at high compression ratios.
AA-SVD: Anchored and Adaptive SVD for LLM Compression
Introduction and Motivation
The rapid proliferation of large-scale pretrained LLMs has exacerbated their computational and memory demands, making resource-efficient deployment an immediate research priority. While structured pruning, quantization, and low-rank factorization have each contributed to this goal, post-training SVD-based factorization methods are attractive for their deployment practicality and accelerator efficiency. However, classical SVD-based approaches typically ignore the compound distributional shifts induced by upstream compression, and either anchor exclusively on original or shifted activations. This leads to error accumulation and degraded downstream fidelity, especially at aggressive compression ratios.
Methodological Contributions
AA-SVD proposes a principled two-stage framework for block-structured transformer compression, synthesizing the benefits of activation-aware and shift-aware objectives, and introducing block-level joint refinement.
Anchored and Adaptive Compression Objective
Unlike input-agnostic (Eckart–Young–Mirsky, ∥W−W′∥F2) or input-aware (∥WY−W′Y∥F2) SVD approaches, AA-SVD minimizes the distance between original outputs and the outputs of the compressed operator acting on post-compression-activation distributions:
rank(W′)=kmin∥WY−W′Y′∥F2
where Y are reference activations and Y′ are activations from the (partially) compressed upstream model. The solution is provided in closed form, only requiring the relevant cross-covariances:
W′⋆=SVDk(WYY′⊤(Y′Y′⊤)−1L)L−1
where L is a Cholesky/EVD decomposition of Y′Y′⊤.
This blends the advantages of preserving original-model fidelity while explicitly mitigating the drift induced by sequential compression.
Block-Level Joint Optimization
AA-SVD accounts for error interactions among linear submodules within a transformer block by introducing post-layerwise block-local refinement:
- After initializing linear layers with the above SVD solution, all low-rank factors in a block (and local normalization/bias) are further optimized to minimize the MSE between original and compressed block outputs on contemporaneously compressed activations.
- This approach allows within-block error compensation and substantially suppresses output drift as shown empirically.
Empirical Results
AA-SVD is benchmarked on LLaMA and Qwen model families (across 1B–13B parameters), evaluated on both standard language modeling datasets (WikiText2, PTB, C4) and a suite of zero-shot commonsense reasoning tasks.
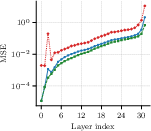
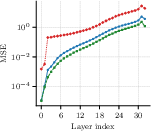
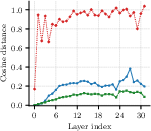
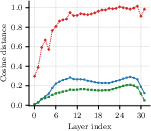
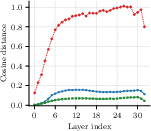
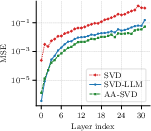
Figure 2: Layerwise MSE for output projection (O-proj) shows joint block-level AA-SVD keeps per-layer distortion and drift lower, mitigating error compounding through depth.
- Ablation: Without block-level refinement, input-agnostic or shift-aware SVD collapses at moderate ratios. With block-level joint optimization, AA-SVD's initialization becomes critical for final quality, affirming the benefit of the anchored + adaptive objective.
- Comparison to structured pruning: AA-SVD with the Dobi-style remapping consistently delivers lower perplexity and higher accuracy at fixed parameter/memory budgets compared to SliceGPT, LLM-Pruner, and Bonsai, especially at high compression.
Practical and Theoretical Implications
The study identifies two critical insights for post-training LLM compression:
- Compound error sensitivity: Layerwise SVD is insufficient; interacting compression errors must be jointly accounted for at block granularity.
- Distribution-shift anchoring: Assigning the anchoring reference to original outputs while projecting compressed activations addresses both functional fidelity and the reality of test-time input distributions after compression.
These design choices result in models that:
- Remain performant at aggressive compression ratios where all baselines fail.
- Maintain efficient inference compatibility (FLOPs, KV-cache) and can be composed with quantization.
- Are robust to modest calibration sizes, crucial for fast or data-limited deployment pipelines.
Future Directions
AA-SVD exposes several promising directions:
- Adaptive rank/capacity allocation: Block-local optimization complicates naive per-layer sensitivity analysis. Developing globally optimal, refinement-aware capacity allocation strategies can further improve pareto efficiency.
- Hybrid pipelines: SVD, quantization, and structured pruning target mostly orthogonal redundancy; joint pipelines with block-level objectives may unlock more aggressive yet robust model compression.
- Theoretical bounds: Quantifying error compensation and drift for block-level refinement under various architectural regimes warrants further analysis.
Conclusion
AA-SVD delivers a robust, practical SVD-based compression protocol for large pretrained transformers that substantially outperforms state-of-the-art baselines at a range of compression ratios, especially in aggressive regimes. Its key innovation is block-level joint refinement initialized by an anchored and adaptive SVD solution, bridging the gap between distributional faithfulness and end-task utility. These results establish the block-wise, calibration-efficient, post-training paradigm as a scalable strategy for efficient, high-fidelity LLM deployment.