- The paper introduces a trajectory-free quadratic loss that efficiently learns interaction and external potentials from unlabeled snapshot data.
- It leverages both parametric and neural network methods to bypass trajectory recovery and directly optimize the self-test loss, ensuring robust performance even with coarse time discretizations.
- Key theoretical guarantees, including convergence error rates and condition number controls, validate the method's practical applicability to real-world particle systems.
Learning Interacting Particle Systems from Unlabeled Data: A Technical Analysis
This paper formulates and solves the inverse problem of learning interaction and external potentials in stochastic interacting particle systems from unlabeled snapshot data. The absence of trajectory or particle label information imposes substantial statistical and computational challenges. Formally, the system is a finite set of N particles in Rd evolving via an Itô SDE governed by unknown interaction potential Φ and external potential V, with standard Brownian noise:
dXti=−N1j=i∑∇Φ(Xti−Xtj)dt−∇V(Xti)dt+σdWti,
Of primary interest is the case where only sequences of unordered ensembles (snapshots D={Xtℓπ,m}) are observed at discrete times, with particle identities obfuscated due to unknown permutations πt.
Classical approaches (MLE, energy-based, likelihood maximization, Bayesian inverse SDE, and OT-based methods) rely on labeled trajectories or accurate matching between adjacent snapshots. These methods either perform poorly for large observation intervals due to significant label ambiguity or are computationally prohibitive. Distributional-matching or mean-field approaches further break down unless N is prohibitively large, and direct trajectory recovery via optimal assignment is highly inaccurate or ill-posed under strong diffusion and non-trivial dynamics.
Trajectory-Free Quadratic Self-Test Loss: Construction and Properties
The central technical contribution is a trajectory-free, quadratic-in-the-potentials loss function, constructed by exploiting the empirical measure's exact weak stochastic PDE, bypassing the need for individual particle trajectories. Specifically, following Itô's chain rule, the empirical distribution of the particles,
μtN(x)=N1i=1∑NδXti(x),
evolves according to a closed-form weak-form stochastic PDE involving linear functionals of the unknown potentials V, Rd0. Testing this PDE against Rd1 and integrating over data instantiations yields a quadratic loss that can be minimized over any function class Rd2. The structure of the resulting objective is:
Rd3
where:
- Rd4: dissipative quadratic form in gradients,
- Rd5: diffusion/Laplacian correction,
- Rd6: energy exchange term, computable per snapshot.
Crucially, no velocity or trajectory estimates are required (in contrast to MLE or drift regression methods).

Figure 1: Workflow of both estimation algorithms using the self-test loss; the left path is least squares regression with basis expansion, the right path is neural-network-based, both leveraging the quadratic self-test loss.
Key Properties:
- Exact for any finite Rd7, not a mean-field or infinite-Rd8 approximation,
- Quadratic and convex in the parameters when potentials are linearly parameterized,
- Well-posed minimization, with Frechet derivative zero at the true potentials (up to a vanishing martingale term),
- Robust to coarse time discretizations; supports both parametric and nonparametric architectures.
Algorithms: Parametric and Neural Network Implementations
Two estimator classes are described:
- Parametric Least Squares Regression: Potentials are expanded in basis sets (e.g., polynomials, RBFs). The loss remains quadratic, reducing to regularized normal equations; computational complexity is dominated by basis cross-terms and pairwise interactions. Regularization via Tikhonov (ridge) and careful selection of the penalty is mandatory due to poor conditioning in the interaction block, particularly for large Rd9.
- Neural Network Regression: Potentials are parameterized via deep Φ0-smooth architectures (e.g., MLPs with Softplus). All derivatives (notably Laplacians) are supplied by automatic differentiation. Batching and stochastic optimization allow scaling to high-dimensional and non-radial settings. Unlike basis approaches, the NN method does not require prior knowledge of the system's structure.
Both methods bypass all explicit trajectory recovery steps, such as optimal transport or Sinkhorn matching, and do not require finite-difference velocity estimates that plague MLE approaches.
Theoretical Guarantees: Convergence and Error Rates
Rigorous non-asymptotic error analysis is provided for the parametric estimator:
- With Φ1 samples and observation step Φ2, the estimator achieves
Φ3
with Φ4 (Riemann quadrature) or Φ5 (trapezoidal rule), validating the theoretically minimal statistical rates in the absence of labels.
- Coercivity and identifiability are guaranteed under broad conditions (weak cross-correlations, finite basis moments, exchangeability). Conditioning degrades with Φ6 (interaction block condition number scaling as Φ7, see Figure 2).
For large (but finite) Φ8, the quadratic form's condition number is dominated by the interaction block, but the method remains statistically efficient. The nonparametric (NN) estimator is empirically validated but left for future theoretical treatment.
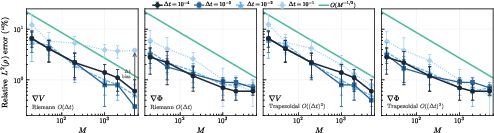
Figure 3: Φ9-scaling of estimator error under different time integration schemes, illustrating V0 statistical error and discretization bias scaling as V1 or V2.
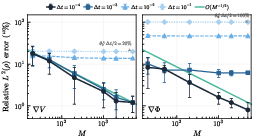
Figure 4: Convergence for discrete-time models. The estimator error is limited by intrinsic model bias V3 when the simulation and observation steps coincide.
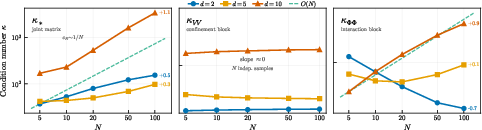
Figure 2: Scaling of condition numbers of the normal matrix for increasing V4. The conditioning is worse for V5 than V6, matching theory.
Empirical Results: Superiority in the Unlabeled Setting
The new self-test approach is systematically benchmarked against multiple baselines:
- Labeled MLE: Ideal but unimplementable in the unlabeled regime; achieves lowest error for infinitesimal V7 due to perfect label information.
- Sinkhorn MLE: Recovers pseudo-labels by OT-based assignment; label mismatches rapidly accumulate for large V8 or under strong diffusion, severely degrading estimation performance and rendering computation prohibitively expensive.
- Self-Test (LSE and NN): Achieves lower or comparable errors as soon as V9, outperforming both labeled and Sinkhorn MLE as dXti=−N1j=i∑∇Φ(Xti−Xtj)dt−∇V(Xti)dt+σdWti,0 increases, remaining robust even at very coarse observation intervals (Table 1, Figure 5).
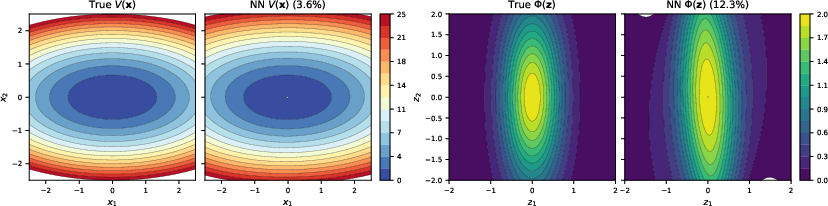
Figure 5: Non-radial potential recovery (dXti=−N1j=i∑∇Φ(Xti−Xtj)dt−∇V(Xti)dt+σdWti,1); the self-test NN achieves low relative gradient error.
Additional experiments recover challenging non-radial, ill-conditioned, and singular potentials, where only the self-test NN is universally applicable. Performance does not degrade catastrophically on models that violate technical regularity assumptions (Figures 6, 7), showing strong empirical robustness.
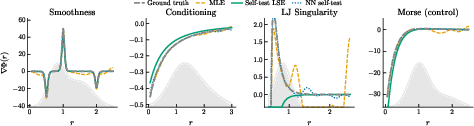
Figure 6: Estimation of interaction gradients for sharply varying or singular potentials; the self-test NN and parametric methods provide accurate recovery without labels.
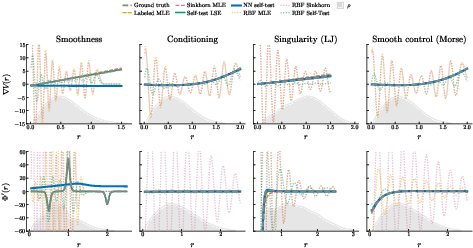
Figure 7: Recovery performance on various radial test potentials, including those with large gradient magnitudes or lack of smoothness, confirming estimation reliability.
Implications, Limitations, and Outlook
Practical Implications:
- Enables robust and scalable inference of interaction laws from population snapshots in physical, biological, and social systems—the typical empirical context where trajectories are unavailable.
- Avoids the computational and statistical pitfalls of label and velocity recovery.
- Demonstrated robustness to measurement gaps and high-dimensionality, enabling application to real-world experimental and observational datasets.
Theoretical Implications:
- Establishes that trajectory/label recovery is not required for consistent potential learning with finite dXti=−N1j=i∑∇Φ(Xti−Xtj)dt−∇V(Xti)dt+σdWti,2, providing sharp error bounds matching known rates for labeled data up to constant multiplicative bias.
- The loss structure and self-testing test families could be adapted for related inverse problems with empirical measure observations.
Limitations and Future Work:
- Current framework assumes homogeneity; the extension to multi-species particle systems without type labels remains an open problem (will require fundamentally new ideas, e.g., for type-coupled weak-PDEs).
- Singular potentials with strong short-range divergences necessitate further analysis and possibly adaptive regularization.
- Neural network estimator theory (rates, landscape geometry, implicit regularization) remains undeveloped and is a crucial future direction.
- Sharp minimax lower bounds for the unlabeled setting to formally quantify the statistical cost of the missing label/trajectory information would close a core theoretical gap.
Conclusion
The trajectory-free self-test quadratic loss for interacting particle systems resolves a fundamental limitation in the scientific learning of stochastic dynamics from unlabeled data. It delivers efficient, theoretically justified, and empirically robust parameter recovery under challenging real-world conditions, with broad immediate applications in experimental and computational sciences.
Reference: "Learning interacting particle systems from unlabeled data" (2604.02581)