- The paper introduces ChomskyBench, a benchmark that rigorously tests LLMs' reasoning across all levels of the Chomsky hierarchy.
- It employs tasks from regular to recursively enumerable languages, measuring accuracy and efficiency with deterministic verifiers.
- Findings reveal steep performance drops at higher complexity levels, highlighting the need for hybrid neuro-symbolic approaches.
Introduction and Motivation
The assessment of LLMs in software engineering has traditionally relied on benchmarks that emphasize functional code correctness or natural language-to-code translation. However, these benchmarks are agnostic to the underlying computational complexity of formal language reasoning and do not systematically probe the inherent limitations of the models with respect to automata-theoretic constraints. The work "Evaluating the Formal Reasoning Capabilities of LLMs through Chomsky Hierarchy" introduces ChomskyBench, a detailed benchmark explicitly designed to analyze LLM reasoning across the full Chomsky Hierarchy—spanning regular, context-free (deterministic and non-deterministic), context-sensitive, and recursively enumerable languages. This essay provides an expert summary and technical analysis of the study, its main results, and its implications for future research in LLM formal reasoning.
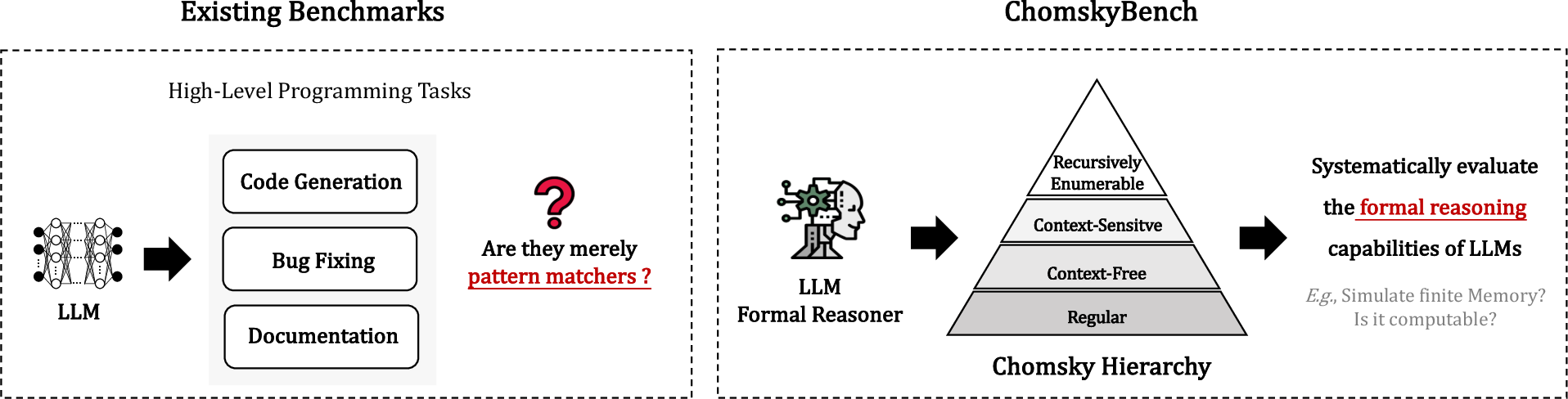
Figure 1: A conceptual comparison between existing benchmarks and the new ChomskyBench, emphasizing process-level evaluation and coverage of formal language complexity.
ChomskyBench: Framework and Construction
Theoretical Foundation and Benchmark Structure
ChomskyBench is grounded in the classical Chomsky Hierarchy, a stratified classification of formal languages based on recognized computational complexity. The benchmark defines task suites for each hierarchy level:
- Regular (Type-3): Pattern recognition with finite-state automata.
- Context-Free (Type-2: DCF/NCF): Recursion and nesting competence with (non-)deterministic PDAs.
- Context-Sensitive (Type-1): Multi-counter and dependency tracking via linear-bounded automata.
- Recursively Enumerable (Type-0): Turing-complete algorithmic trace generation and simulation.
Each category is populated by both recognition (membership testing) and generation (example synthesis) problems, emphasizing structural minimalism and verifiable trace outputs. Algorithmic rigor is maintained by deterministic symbolic verifiers that validate not only final states but full process traces.
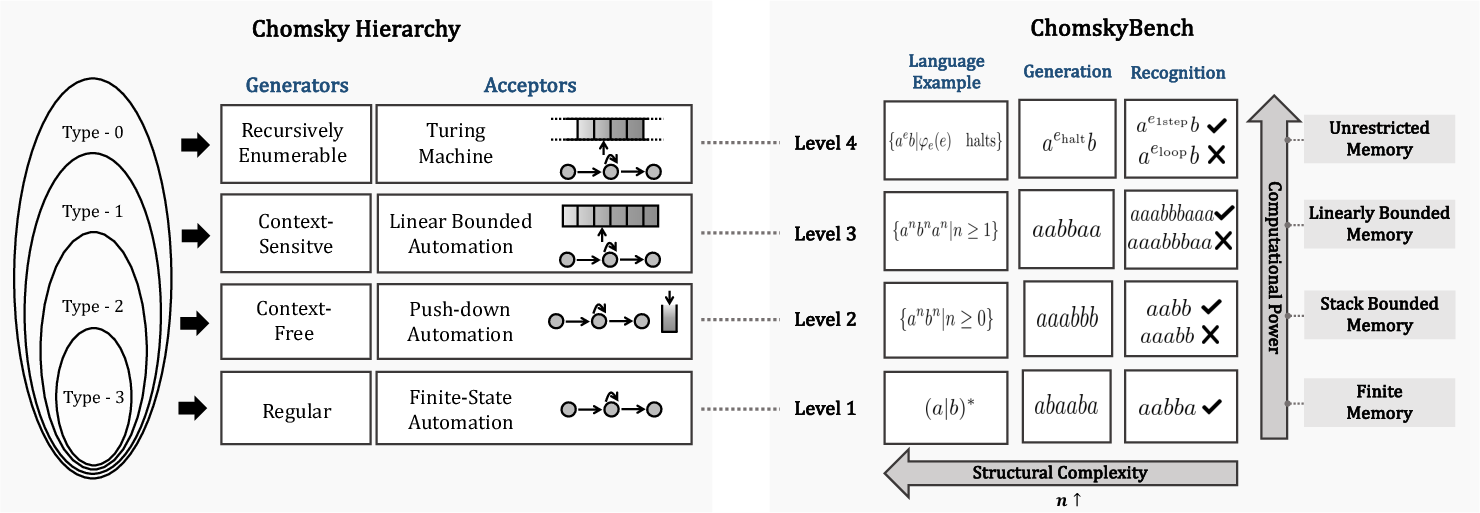
Figure 2: The Chomsky Hierarchy and ChomskyBench mapping, organized with representative automata models and language examples at each complexity level.
Benchmark Design and Dataset
ChomskyBench consists of 115 distinct tasks, predominantly designed by domain experts to minimize pretraining contamination. Rigorous adversarial validation ensures correctness, combining programmatic test generation and independent formal verifiers. The construction protocol leverages parametrized difficulty scaling (e.g., string length, recursion depth) to stress-test LLMs as a function of input complexity.
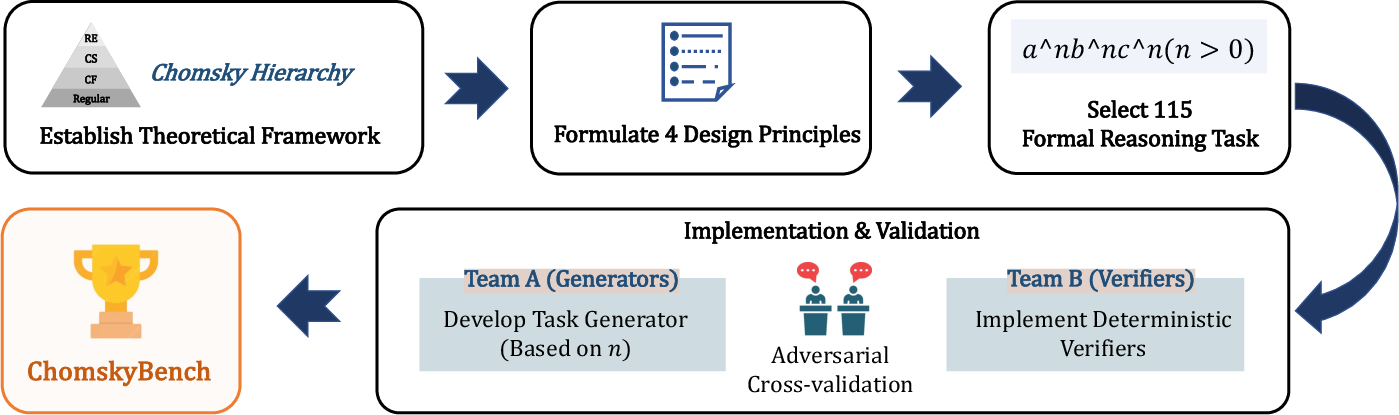
Figure 3: Automated pipeline for ChomskyBench data generation and symbolic verification.

Figure 4: Concrete example of a recognition/generation instance within ChomskyBench.
Experimental Methodology
Model Selection and Evaluation Protocol
The empirical study evaluates 12 contemporary LLMs—spanning open and closed-source variants, model sizes from 30B to 1T parameters, and both generalist and code-specialized architectures. The evaluation avoids fine-tuning or prior exposure, instead using zero-shot prompting with structured system instructions and deterministic hyperparameters for primary runs. Both pass/fail accuracy and partial Pass Ratio (PR) metrics are employed, requiring exact correctness across multi-part questions for full credit.
Research Questions
- RQ1: Stratification of LLM performance across Chomsky levels.
- RQ2: Sensitivity of reasoning performance to input complexity parameters.
- RQ3: Comparative efficiency, contrasting LLM inference time versus classic algorithmic baseline.
- RQ4: Efficacy and limits of test-time scaling strategies (multi-sample inference, extended reasoning).
- RQ5: Failure analysis, distinguishing specification understanding from execution errors.
Key Results and Analysis
Hierarchical Capability Stratification
Quantitative results demonstrate strict stratification: as language complexity increases, all evaluated LLMs suffer rapid and monotonic accuracy loss. No model achieves more than 0.278 overall accuracy (e.g., o3 model) even at the top of the field. A pronounced ‘performance cliff’ manifests between context-free and context-sensitive tasks: performance collapses at context-sensitive and recursively enumerable levels even for the largest and most architecturally advanced models.
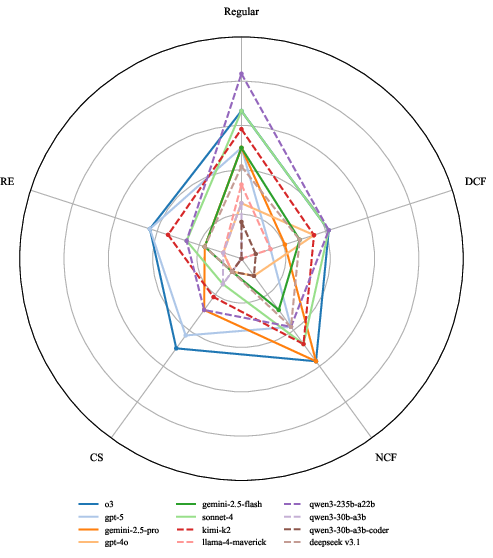
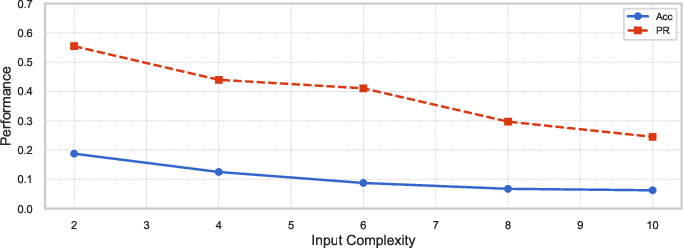
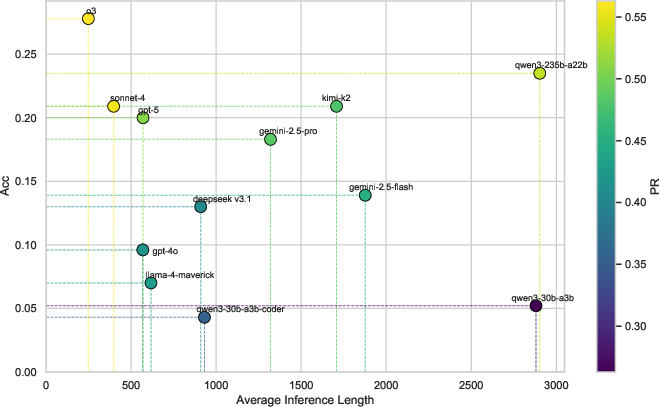
Figure 5: Comparative performance (radar plot) for SOTA LLMs across all Chomsky Hierarchy levels.
Complexity Scaling and Deductive Failure
Systematic variation of input complexity (e.g., string length, recursion depth) reveals a sharp inverse correlation with LLM accuracy. Notably, increasing the length of reasoning traces does not compensate for this deterioration—longer outputs often stem from low-quality, repetitive reasoning, not deeper or more successful computational traces.
Efficiency Barriers
A fundamental discrepancy in efficiency is observed. Symbolic programs solve formal language tasks in <0.001 seconds with perfect accuracy, whereas LLMs require seconds to minutes per instance and remain unreliable. Increasing sample size (test-time scaling/majority voting) provides consistent, but ultimately insufficient, performance gains: doubling sample size yields ∼0.05 accuracy improvement, with no observed hard ceiling. However, achieving practical reliability (>90% accuracy) extrapolates to a computationally prohibitive regime (N > 10,000 samples per task) and necessitates oracle verifiers, which is unrealistic for unstructured tasks.
Breakdown of Failure Modes
LLMs consistently understand automata specifications and requisite formats (terminology usage and template adherence), but fail at stepwise execution: transition rules, state tracking, recursion over extended traces, and multi-counter dependencies. Failure taxonomy includes state tracking collapse, recursion depth overflow, and inability to synchronize independent tokens in context-sensitive languages.
Implications and Theoretical Significance
The findings signal immediate practical and theoretical implications:
- Software Engineering: LLMs are currently reliable only for regular and simple context-free applications (e.g., lexing, simple parsing). For tasks entailing context-sensitive dependencies (e.g., semantic analysis, variable scoping, protocol verification) or Turing-complete reasoning, LLMs are not suitable as standalone engines and must be paired with symbolic tools.
- Architectural Research: The absence of hard capability ceilings with increased sampling indicates that current models are limited by process inefficiency, not absolute representational capacity. However, qualitative limits inherent to Transformer architectures—such as finite precision analogies to finite automata—are reflected in practical inference failures.
- Hybrid Approaches: These results reinforce the need for hybrid neuro-symbolic architectures or explicit memory/counter augmentations to bridge the gap in formal reasoning expressivity.
- Benchmarking and Risk Assessment: ChomskyBench emerges as an indispensable tool for risk-assessed LLM deployment in engineering workflows—quantifying hazard boundaries posed by brittle formal reasoning.
Future Directions
Several next steps are proposed:
- Architectural innovation focused on introducing external memory, explicit stack/counter mechanisms, or symbolic components to LLMs—re-engineering architectures for robust recursion and stateful computation.
- Integration with formal verification: Developing workflows wherein LLMs serve as heuristic suggesters but delegate correctness assurances to deterministic, symbolic engines, especially at higher Chomsky levels.
- Expanding process-trace benchmarks that isolate deeper forms of long-range and non-deterministic reasoning across both discrete and continuous domains.
Conclusion
This work establishes ChomskyBench as a paradigm-shifting diagnostic benchmark, exposing the computational boundaries of LLMs with respect to formal reasoning. The empirical stratification across the Chomsky Hierarchy, the pronounced drop-off in handling context-sensitive and recursively enumerable languages, and the futility of brute-force inference scaling all clarify that practical LLM deployments must be bounded by rigorous risk management and supported by symbolic verification. The study provides an actionable framework for both scientific critique of current LLM architectures and principled integration of LLMs into complex, correctness-critical software engineering pipelines. Further progress will require fundamental advances in neuro-symbolic reasoning and architectural design (2604.02709).

