- The paper introduces FormalMATH, a benchmark using a human-in-the-loop autoformalization pipeline to evaluate LLMs with 5,560 formally verified math problems.
- The methodology employs multi-LLM semantic verification and negation-based disproof, achieving a 72.09% preservation rate for validated entries.
- Evaluation reveals current provers show domain bias with peak success at 16.46%, highlighting the need for enhanced formal reasoning techniques.
Introduction
The paper introduces FormalMATH, a benchmark designed to evaluate the formal mathematical reasoning capabilities of LLMs using Lean4 formalizations. It addresses key limitations in existing benchmarks—such as narrow scope and dataset size—by including 5,560 formally verified problems spanning various mathematical domains. A novel human-in-the-loop autoformalization pipeline is employed, integrating specialized LLMs to reduce manual annotation costs significantly.
Benchmark Design and Methodology
Dataset Composition
FormalMATH consists of a diverse set of 5,560 problems validated using a robust human-in-the-loop pipeline. This approach combines autoformalization from LLMs, multi-LLM semantic verification, and negation-based disproof filtering (Figure 1).
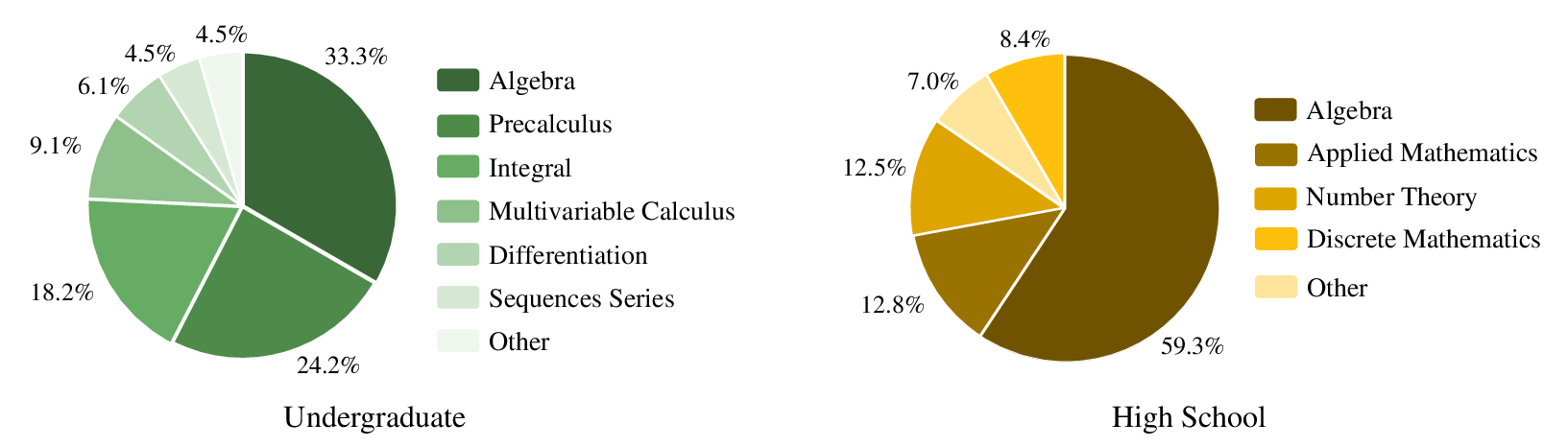
Figure 1: The distribution of mathematical domains in our FormalMATH-Lite dataset.
The benchmark includes problems across algebra, calculus, number theory, discrete mathematics, and applied mathematics, catering to varying difficulty levels from high-school Olympiad to undergraduate-level problems.
The pipeline is designed to minimize expert validation requirements by integrating:
- Multi-LLM autoformalization for generating formal statements.
- Semantic verification leveraging general-purpose LLMs to ensure alignment with original problem semantics.
- Negation-based disproof using LLM provers to filter out unprovable statements.
This strategy reduces annotation cost while maintaining a preservation rate of 72.09% for verified entries (Figure 2).
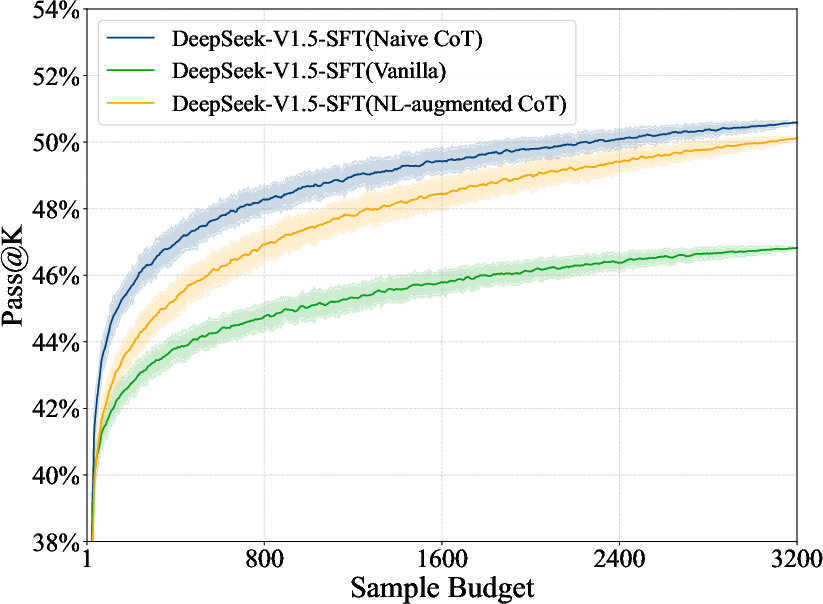
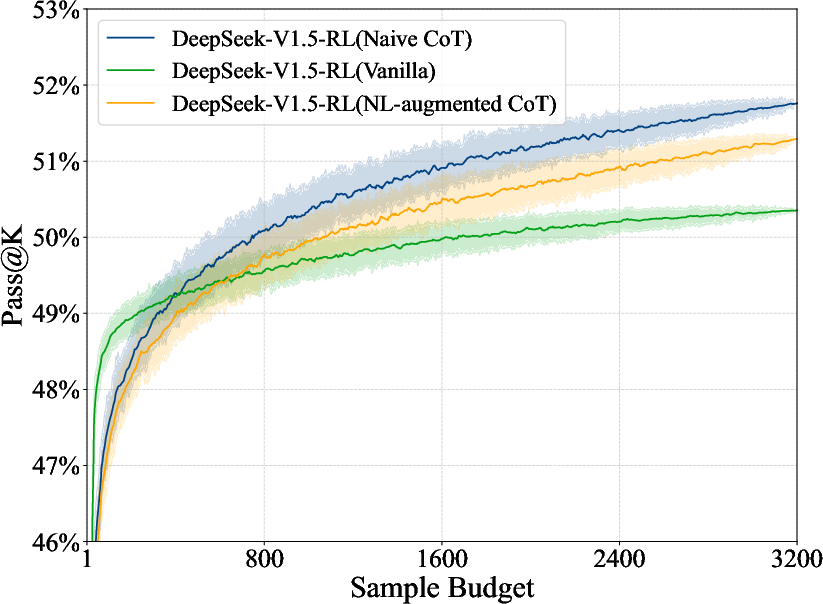
Figure 2: DeepSeek-V1.5-SFT.
Evaluation of Existing Provers
The paper scrutinizes state-of-the-art theorem provers using FormalMATH, revealing significant limitations. Current models achieve only moderate success rates, with the best-performing Kimina-Prover achieving a success rate of 16.46% under practical sampling budgets (Table 1).
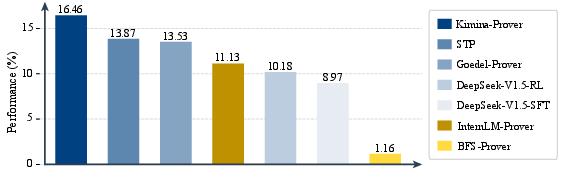

Figure 3: Performance of current provers on FormalMATH.
Analyses indicate prominent domain biases, where models excel in algebra but underperform in calculus, highlighting generalizability issues (Figures 3 and 4).
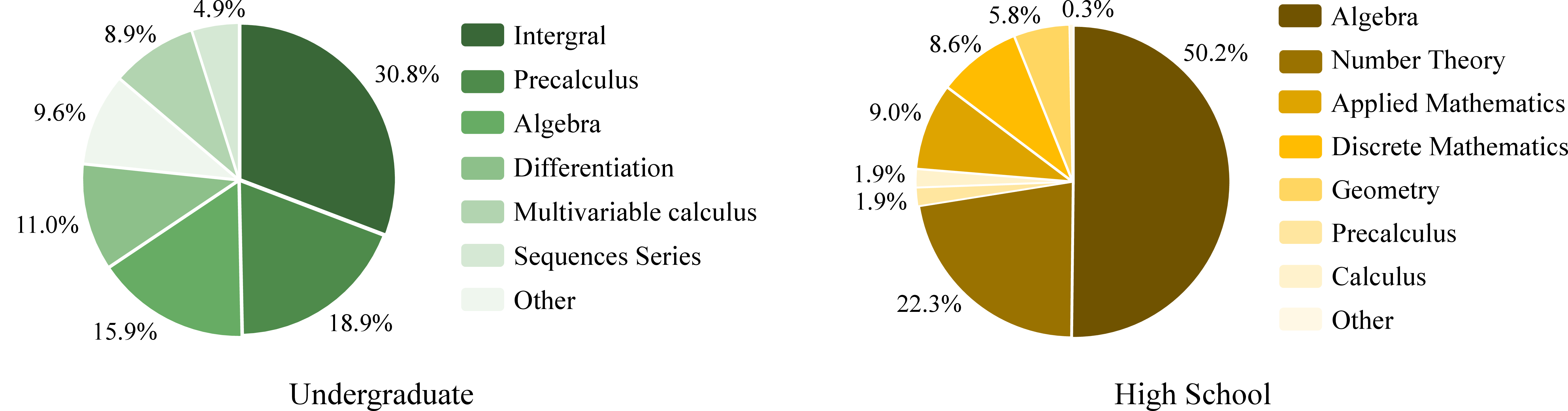
Figure 4: The distribution of mathematical domains in the full set of FormalMATH.
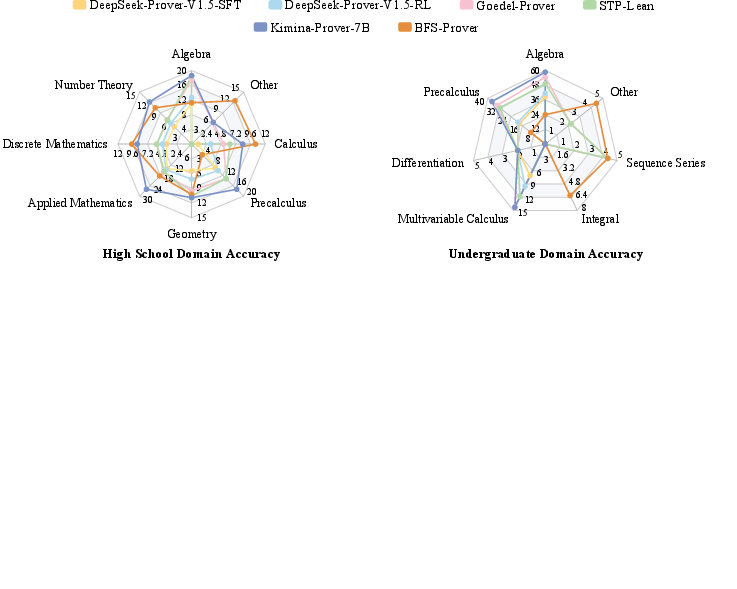
Figure 5: Breakdown of accuracy by mathematical domain within FormalMATH.
Moreover, an inverse relationship is observed between natural-language solution guidance and proof success, suggesting that such guidance may introduce ambiguity rather than clarity in formal reasoning contexts.
Test-Time Compute Scaling
A subset, FormalMATH-Lite, is used to examine the impact of test-time compute scaling, revealing minimal performance improvements despite substantial increases in sampling budgets (Figure 6).
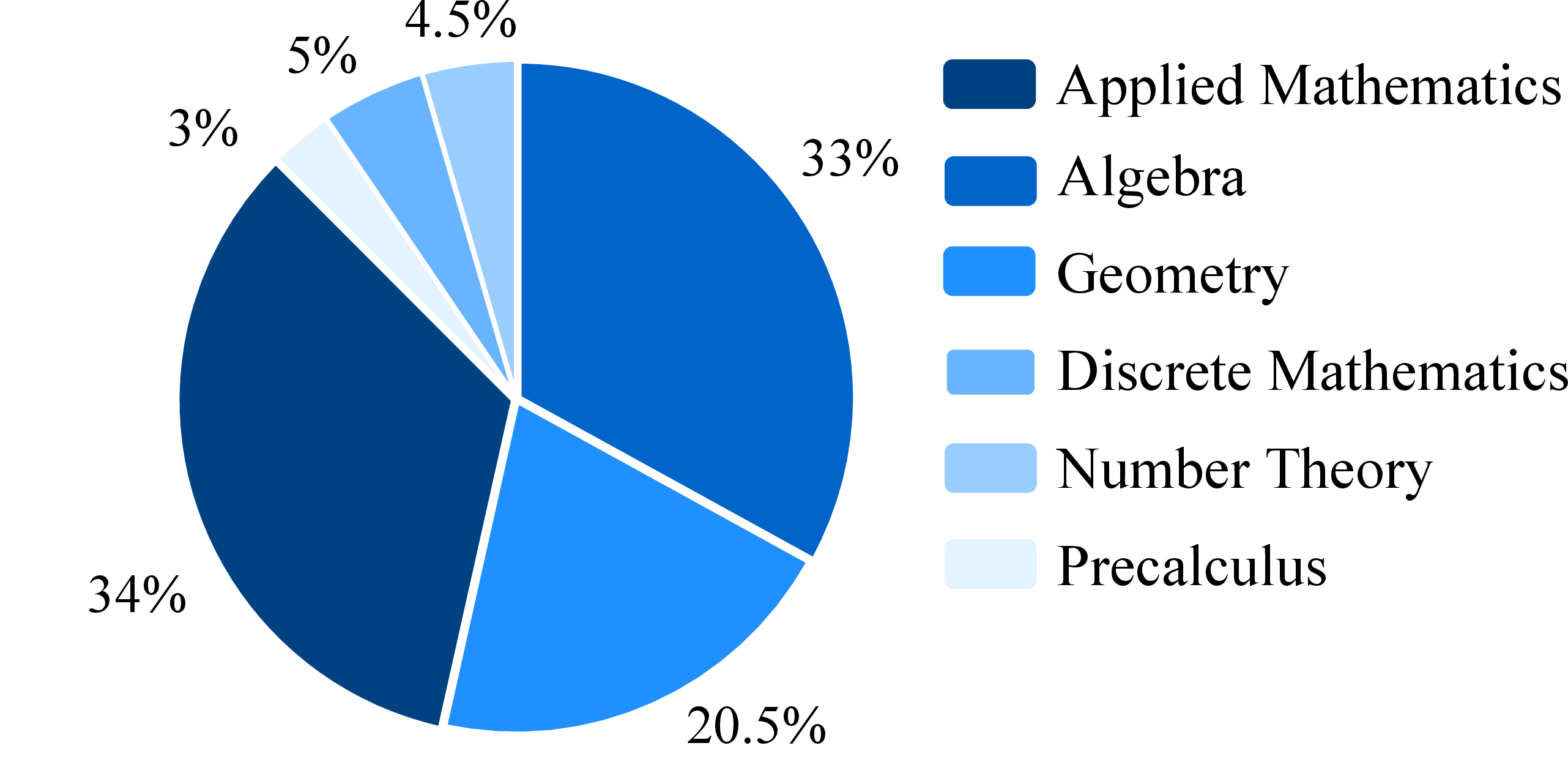
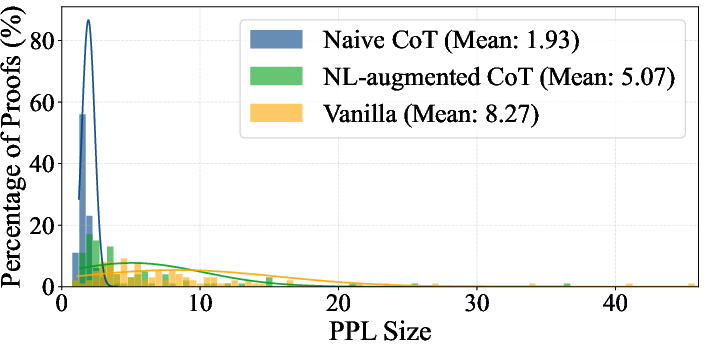
Figure 6: Training Domains of Goedel-Prover.
Implications and Future Directions
FormalMATH establishes a benchmark poised to advance research in formal mathematical reasoning. The insights gathered emphasize the need for improving cross-domain generalizability and reason automation in theorem proving. Future research could explore strategies for enhancing LLM provers, such as intrinsic rewards and computation-efficient reasoning approaches.
Conclusion
FormalMATH provides a comprehensive framework for evaluating LLM theorem-proving capabilities across a broader spectrum of mathematical domains. Despite achieving a high preservation rate, it challenges current models, presenting essential areas for future research and innovation in formal reasoning capabilities.